
Maison >Java >javaDidacticiel >Analyse des scénarios d'utilisation des verrous Java au travail
Analyse des scénarios d'utilisation des verrous Java au travail

- PHPzavant
- 2023-04-28 15:34:141127parcourir
1. synchronisé
synchronisé est un verrou exclusif réentrant. Il a une fonction similaire au verrou ReentrantLock et peut être utilisé presque partout où le verrouillage synchronisé est utilisé. présente les principales différences suivantes :
ReentrantLock a des fonctions plus riches, telles que la fourniture de Condition, une API de verrouillage qui peut être interrompue et peut répondre à des scénarios complexes de verrouillage + file d'attente, etc.
ReentrantLock peut être divisé en verrous équitables et injustes les verrous et les verrous synchronisés sont tous deux des verrous injustes ; - Les postures d'utilisation des deux sont également différentes. ReentrantLock doit déclarer qu'il dispose d'API pour verrouiller et libérer les verrous, tandis que le bloc de code synchronisé effectue automatiquement l'opération de verrouillage et de libération. libérer le verrou et synchroniser est plus pratique à utiliser.
- synchronized et ReentrantLock ont des fonctions similaires, nous prendrons donc synchronisé comme exemple.
1.1. Initialisation des ressources partagées
Dans un système distribué, nous aimons verrouiller certaines ressources de configuration mortes dans la mémoire JVM au démarrage du projet, afin que lors de la demande de ces ressources de configuration partagées, elles puissent les obtenir directement de la mémoire au lieu de l'obtenir de la base de données à chaque fois, ce qui réduit le temps perdu.
Généralement, ces ressources partagées incluent : la configuration des processus métier morts + la configuration des règles métier mortes.
Les étapes d'initialisation des ressources partagées sont généralement : démarrer le projet -> déclencher l'action d'initialisation -> récupérer les données de la base de données dans un seul thread -> la mémoire JVM.
Lorsque le projet démarre, afin d'éviter que les ressources partagées ne soient chargées plusieurs fois, nous ajoutons souvent des verrous exclusifs, de sorte qu'une fois qu'un thread a terminé le chargement des ressources partagées, un autre thread peut continuer à se charger à ce moment-là, nous pouvons choisir. le verrou exclusif synchronisé ou ReentrantLock, nous avons pris synchronisé comme exemple et avons écrit le code fictif comme suit :
// 共享资源
private static final Map<String, String> SHARED_MAP = Maps.newConcurrentMap();
// 有无初始化完成的标志位
private static boolean loaded = false;
/**
* 初始化共享资源
*/
@PostConstruct
public void init(){
if(loaded){
return;
}
synchronized (this){
// 再次 check
if(loaded){
return;
}
log.info("SynchronizedDemo init begin");
// 从数据库中捞取数据,组装成 SHARED_MAP 的数据格式
loaded = true;
log.info("SynchronizedDemo init end");
}
}Je ne sais pas si vous avez trouvé l'annotation @PostConstruct à partir du code ci-dessus. La fonction de l'annotation @PostConstruct est. pour exécuter l'annotation @PostConstruct lorsque le conteneur Spring est initialisé. La méthode marquée avec l'annotation signifie que la méthode init affichée dans l'image ci-dessus est déclenchée au démarrage du conteneur Spring.
Vous pouvez télécharger le code de démonstration, rechercher le fichier de démarrage DemoApplication, cliquer avec le bouton droit sur Exécuter sur le fichier DemoApplication pour démarrer l'intégralité du projet Spring Boot et placer un point d'arrêt sur la méthode init pour déboguer.
Nous utilisons synchronisé dans le code pour garantir qu'un seul thread peut effectuer l'opération d'initialisation des ressources partagées en même temps, et nous ajoutons un indicateur d'achèvement du chargement des ressources partagées (chargé) pour déterminer si le chargement est terminé s'il est chargé. , puis les autres threads de chargement reviennent directement.
Si vous remplacez synchronisé par ReentrantLock, l'implémentation est la même, mais vous devez utiliser explicitement l'API de ReentrantLock pour verrouiller et libérer le verrou. Une chose à noter lors de l'utilisation de ReentrantLock est que nous devons verrouiller le bloc de méthode try. , et dans final, relâchez le verrou dans le bloc de méthode pour garantir que même si une exception se produit après le verrouillage dans try, le verrou peut être libéré correctement dans final.
Certains étudiants peuvent se demander : ne pouvons-nous pas utiliser ConcurrentHashMap directement ? Pourquoi devons-nous le verrouiller ? Il est vrai que ConcurrentHashMap est thread-safe, mais il ne peut garantir la sécurité des threads que lors des opérations de données internes de Map. Il ne peut pas garantir que dans des situations multithreads, l'ensemble de l'action d'interrogation de la base de données et d'assemblage des données n'est exécuté qu'une seule fois. L'ajout de verrous synchronisés concerne l'ensemble de l'opération, garantissant que l'ensemble de l'opération n'est exécuté qu'une seule fois.
2. CountDownLatch
2.1. Scénario
1 : Xiao Ming a acheté un produit sur Taobao et a estimé qu'il n'était pas bon, il a donc retourné le produit (le produit n'a pas encore été expédié, seul l'argent est remboursé). appelez cela un remboursement de produit unique, lorsqu'un remboursement de produit unique est exécuté dans le système en arrière-plan, la consommation de temps globale est de 30 millisecondes.
2 : Sur Double 11, Xiao Ming a acheté 40 produits sur Taobao et a généré la même commande (en fait, plusieurs commandes peuvent être générées, pour la commodité de la description, nous les appelons une seule. Le lendemain, Xiao Ming a trouvé 30 produits). . C'était un achat impulsif et je dois retourner les 30 articles ensemble.
2.2. Mise en œuvre
À l'heure actuelle, le backend n'a pour fonction que de rembourser des produits uniques, et n'a pas pour fonction de rembourser des lots de produits (le retour de 30 produits en même temps est appelé un lot afin de le faire rapidement). implémentant cette fonction, l'étudiant A a suivi ce plan : La boucle for appelle 30 fois l'interface de remboursement d'un seul produit. Lors du test d'environnement QA, il a été constaté que si 30 produits devaient être remboursés, cela prendrait : 30 * 30 = 900. millisecondes. Plus une autre logique, le remboursement prendrait près d'une seconde pour sélectionner 30 produits, ce qui prend en fait beaucoup de temps. À cette époque, le camarade de classe A a soulevé cette question et espérait que tout le monde pourrait contribuer à optimiser la consommation de temps de l'ensemble de la scène. .
同学 B 当时就提出,你可以使用线程池进行执行呀,把任务都提交到线程池里面去,假如机器的 CPU 是 4 核的,最多同时能有 4 个单商品退款可以同时执行,同学 A 觉得很有道理,于是准备修改方案,为了便于理解,我们把两个方案都画出来,对比一下:
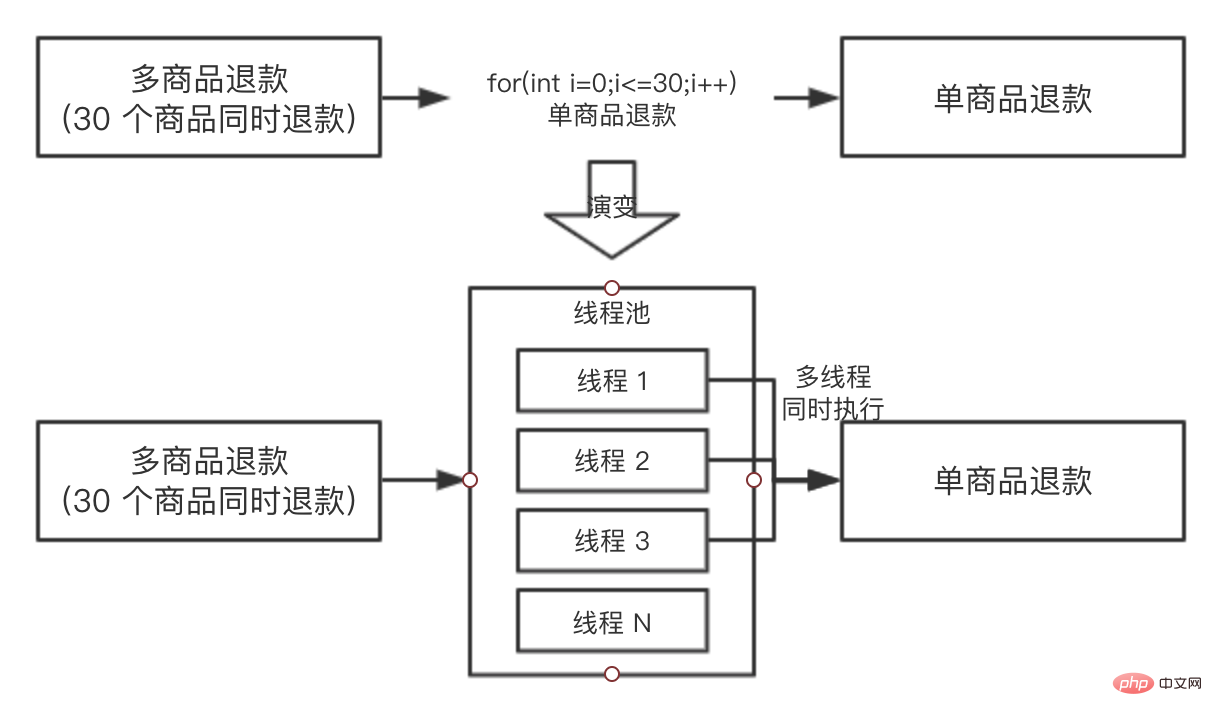
同学 A 于是就按照演变的方案去写代码了,过了一天,抛出了一个问题:向线程池提交了 30 个任务后,主线程如何等待 30 个任务都执行完成呢?因为主线程需要收集 30 个子任务的执行情况,并汇总返回给前端。
大家可以先不往下看,自己先思考一下,我们前几章说的那种锁可以帮助解决这个问题?
CountDownLatch 可以的,CountDownLatch 具有这种功能,让主线程去等待子任务全部执行完成之后才继续执行。
此时还有一个关键,我们需要知道子线程执行的结果,所以我们用 Runnable 作为线程任务就不行了,因为 Runnable 是没有返回值的,我们需要选择 Callable 作为任务。
我们写了一个 demo,首先我们来看一下单个商品退款的代码:
// 单商品退款,耗时 30 毫秒,退款成功返回 true,失败返回 false
@Slf4j
public class RefundDemo {
/**
* 根据商品 ID 进行退款
* @param itemId
* @return
*/
public boolean refundByItem(Long itemId) {
try {
// 线程沉睡 30 毫秒,模拟单个商品退款过程
Thread.sleep(30);
log.info("refund success,itemId is {}", itemId);
return true;
} catch (Exception e) {
log.error("refundByItemError,itemId is {}", itemId);
return false;
}
}
}接着我们看下 30 个商品的批量退款,代码如下:
@Slf4j
public class BatchRefundDemo {
// 定义线程池
public static final ExecutorService EXECUTOR_SERVICE =
new ThreadPoolExecutor(10, 10, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(20));
@Test
public void batchRefund() throws InterruptedException {
// state 初始化为 30
CountDownLatch countDownLatch = new CountDownLatch(30);
RefundDemo refundDemo = new RefundDemo();
// 准备 30 个商品
List<Long> items = Lists.newArrayListWithCapacity(30);
for (int i = 0; i < 30; i++) {
items.add(Long.valueOf(i+""));
}
// 准备开始批量退款
List<Future> futures = Lists.newArrayListWithCapacity(30);
for (Long item : items) {
// 使用 Callable,因为我们需要等到返回值
Future<Boolean> future = EXECUTOR_SERVICE.submit(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
boolean result = refundDemo.refundByItem(item);
// 每个子线程都会执行 countDown,使 state -1 ,但只有最后一个才能真的唤醒主线程
countDownLatch.countDown();
return result;
}
});
// 收集批量退款的结果
futures.add(future);
}
log.info("30 个商品已经在退款中");
// 使主线程阻塞,一直等待 30 个商品都退款完成,才能继续执行
countDownLatch.await();
log.info("30 个商品已经退款完成");
// 拿到所有结果进行分析
List<Boolean> result = futures.stream().map(fu-> {
try {
// get 的超时时间设置的是 1 毫秒,是为了说明此时所有的子线程都已经执行完成了
return (Boolean) fu.get(1,TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
return false;
}).collect(Collectors.toList());
// 打印结果统计
long success = result.stream().filter(r->r.equals(true)).count();
log.info("执行结果成功{},失败{}",success,result.size()-success);
}
}上述代码只是大概的底层思路,真实的项目会在此思路之上加上请求分组,超时打断等等优化措施。
我们来看一下执行的结果:
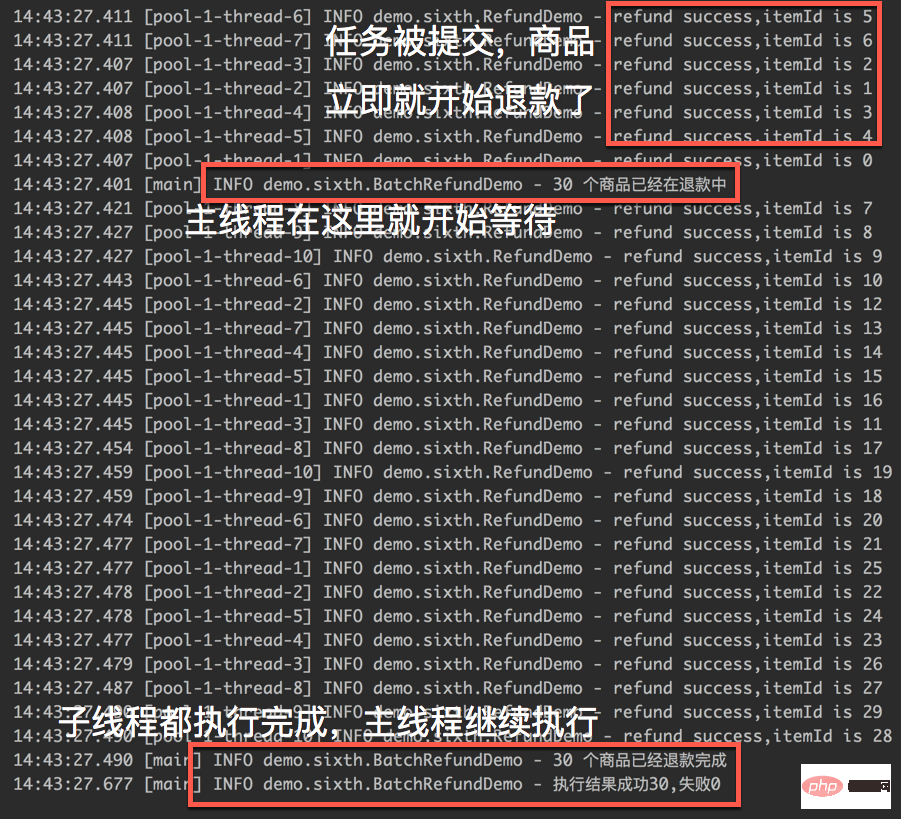
从执行的截图中,我们可以明显的看到 CountDownLatch 已经发挥出了作用,主线程会一直等到 30 个商品的退款结果之后才会继续执行。
接着我们做了一个不严谨的实验(把以上代码执行很多次,求耗时平均值),通过以上代码,30 个商品退款完成之后,整体耗时大概在 200 毫秒左右。
而通过 for 循环单商品进行退款,大概耗时在 1 秒左右,前后性能相差 5 倍左右,for 循环退款的代码如下:
long begin1 = System.currentTimeMillis();
for (Long item : items) {
refundDemo.refundByItem(item);
}
log.info("for 循环单个退款耗时{}",System.currentTimeMillis()-begin1);性能的巨大提升是线程池 + 锁两者结合的功劳。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment les assertions Java peuvent-elles améliorer la qualité du code et prévenir les erreurs ?
- La déclaration de chaînes comme « finales » en Java affecte-t-elle les comparaisons « == » ?
- Manipulation de chaînes en Java
- Comment mettre à jour en permanence JLabel avec les résultats d'une tâche de longue durée ?
- Comment convertir int[] en Integer[] pour l'utiliser comme clés de carte en Java ?