
Maison >Périphériques technologiques >IA >La pratique d'application de l'informatique confidentielle dans le domaine de l'IA Big Data
La pratique d'application de l'informatique confidentielle dans le domaine de l'IA Big Data

- 王林avant
- 2023-04-28 15:13:061638parcourir
01 Le contexte et la situation actuelle de l'informatique privée
1. 🎜## 🎜🎜#
L'informatique confidentielle est désormais devenue une nécessité. D’une part, les exigences des utilisateurs individuels en matière de confidentialité personnelle et de sécurité des informations sont devenues plus fortes. D'un autre côté, un grand nombre de lois et de réglementations liées à la confidentialité et à la sécurité ont été publiées, telles que le RGPD de l'Union européenne, le CCPA des États-Unis et les lois et politiques nationales sur la protection des informations personnelles sont progressivement passées de souples à strictes. , principalement reflété dans les droits et intérêts, la portée de la mise en œuvre et la force, etc. En prenant comme exemple le RGPD, depuis son entrée en vigueur en 2018, plus de 1 000 cas ont été signalés, avec une amende totale de plus de 11 milliards, et l'amende la plus élevée dépasse 5 milliards (Amazon).

 # 🎜🎜#2. La situation actuelle de l'informatique confidentielle
# 🎜🎜#2. La situation actuelle de l'informatique confidentielle
Dans ce contexte, la sécurité des données est passée d'optionnelle à facultatif est devenu un incontournable. Cela a conduit un grand nombre d'entreprises, d'investissements, de startups et de praticiens à investir dans l'écosystème technologique de sécurité et de confidentialité, et le cercle universitaire a mené de nombreuses explorations prospectives en réponse aux besoins de l'industrie. Ces facteurs ont contribué au développement vigoureux des technologies et des écosystèmes de sécurité et de confidentialité au cours des dernières années, parmi lesquels des technologies telles que la confidentialité différentielle, les environnements d'exécution fiables, le cryptage homomorphe, le calcul multipartite sécurisé et l'apprentissage fédéré ont toutes fait de grands progrès. Gartner est également optimiste quant au développement de ce domaine, estimant qu'il s'agira d'un marché valant des dizaines, voire des centaines de milliards dans le futur.
 02
02
Big Data AI + informatique de confidentialité1. 🎜 #
Retour dans le contexte de l'IA Big Data, d'un point de vue macro de l'industrie, les cadres et technologies Big Data ont été commercialisés et popularisés à grande échelle. Nous utilisons peut-être la technologie du Big Data en permanence, mais nous ne pensons pas que les programmes et la formation de modèles s'exécutent sur un cluster de serveurs composé de milliers, voire de dizaines de milliers de nœuds et de données à grande échelle. Ces dernières années, deux nouvelles tendances sont apparues dans l'orientation du développement de ce domaine : l'une est l'amélioration de la facilité d'utilisation et l'autre est l'affinement des orientations d'application. Le premier a considérablement abaissé le seuil d’utilisation de la technologie du Big Data, tandis que le second continue d’apporter de nouvelles solutions aux besoins et problèmes émergents, tels que les lacs de données.Du point de vue de la combinaison avec le framework IA, le big data et l'écologie de l'IA sont désormais étroitement intégrés. Car pour les modèles d'IA, plus la quantité de données est grande et plus la qualité est élevée, meilleur est l'effet d'entraînement du modèle, donc les deux domaines du big data et de l'IA seront naturellement combinés.
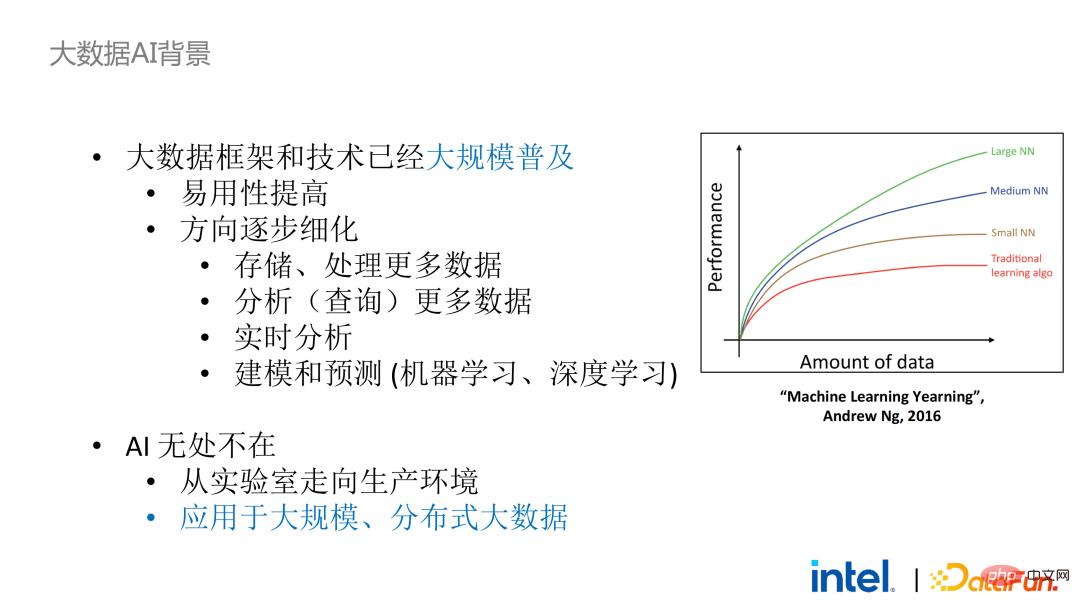 # 🎜🎜#Cependant, malgré cela, intégrer des frameworks Big Data et des frameworks IA n'est pas facile. Dans le processus de développement d'applications, d'acquisition de données, de nettoyage, d'analyse et de déploiement, de nombreux frameworks Big Data et IA seront impliqués. Si vous devez garantir la sécurité et la confidentialité des données dans les processus clés, de nombreux liens et cadres seront impliqués, notamment différentes technologies de sécurité, technologies de chiffrement et technologies de gestion des clés, ce qui augmentera considérablement le coût de transformation et de migration.
# 🎜🎜#Cependant, malgré cela, intégrer des frameworks Big Data et des frameworks IA n'est pas facile. Dans le processus de développement d'applications, d'acquisition de données, de nettoyage, d'analyse et de déploiement, de nombreux frameworks Big Data et IA seront impliqués. Si vous devez garantir la sécurité et la confidentialité des données dans les processus clés, de nombreux liens et cadres seront impliqués, notamment différentes technologies de sécurité, technologies de chiffrement et technologies de gestion des clés, ce qui augmentera considérablement le coût de transformation et de migration.
2. Big Data AI + Privacy Computing
Il y a deux ans, au cours du processus de communication avec les clients liés au Big Data et aux applications d'IA dans l'industrie, nous avons collecté quelques points faibles des utilisateurs. Outre les problèmes généraux de performances, la première préoccupation de la plupart des clients concerne les problèmes de compatibilité. Par exemple, certains clients disposent déjà de clusters comportant des milliers, voire des dizaines de milliers de nœuds. S'ils doivent traiter en toute sécurité certains modules ou liens et appliquer une technologie informatique de confidentialité pour réaliser des fonctions de protection de la confidentialité, ils devront peut-être apporter des modifications aux applications existantes. , ou même introduire des cadres ou des infrastructures complètement nouveaux. Ces impacts sont les principaux problèmes que les clients doivent prendre en compte. Deuxièmement, les clients prendront en compte l'impact de l'échelle des données sur la technologie de sécurité et espèrent que les nouveaux cadres et technologies introduits pourront prendre en charge le calcul de données à grande échelle et offrir une efficacité informatique élevée. Enfin, les clients examineront si la technologie d’apprentissage fédéré peut résoudre le problème des îlots de données.

Sur la base des besoins des clients obtenus lors de l'enquête, nous avons lancé la solution BigDL PPML , Son objectif principal est de permettre aux solutions Big Data et IA conventionnelles et standard de fonctionner dans un environnement sûr pour assurez-vous qu'il est sécurisé de bout en bout . À cette fin, le processus informatique doit être protégé par SGX (hardware-level TEE). Parallèlement, il faut s'assurer que le stockage et le réseau sont cryptés, et l'ensemble du lien doit être attesté à distance (également appelé signature à distance) pour garantir la confidentialité et l'intégrité du calcul.
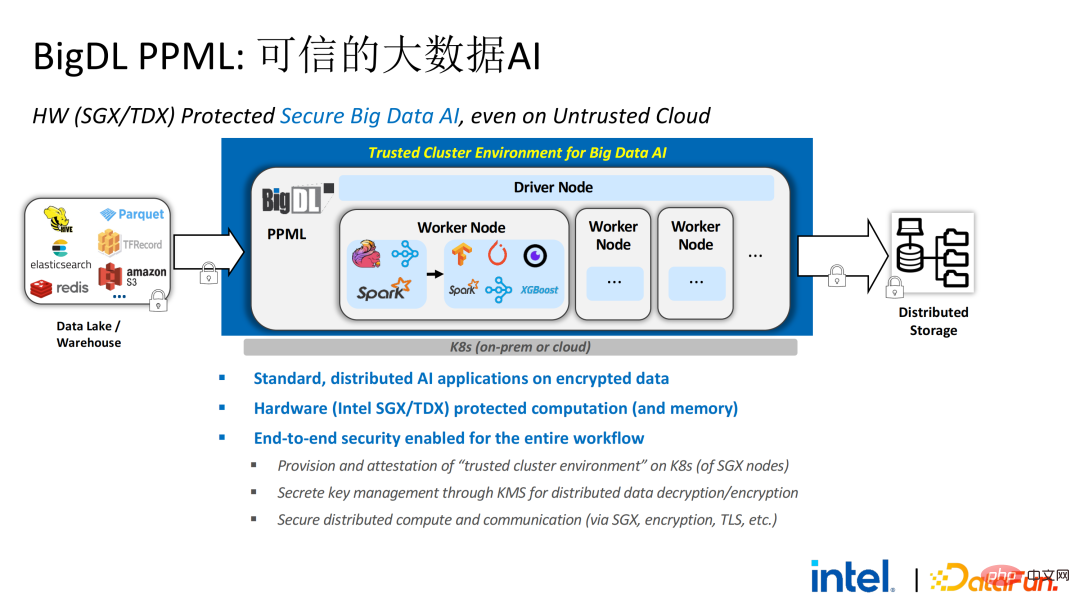
Ensuite, nous prenons Apache Spark, un framework big data couramment utilisé, comme exemple pour développer la nécessité de cette solution . Apache Spark est un framework informatique distribué couramment utilisé dans le domaine de l'IA Big Data. Il possède déjà de nombreuses fonctions liées à la sécurité. Par exemple, le réseau peut être crypté et authentifié, et la communication et le RPC sont principalement protégés par TLS et AES. implique que le stockage aléatoire local est également protégé par AES ; cependant, il existe des problèmes majeurs de calcul, car même la dernière version de Spark ne peut effectuer que des calculs en texte brut. Si l'environnement informatique ou le nœud est compromis, une grande quantité de données sensibles peut être obtenue. La technologie SGX est une technologie d'environnement informatique fiable qui combine des logiciels et du matériel avec un processeur Intel comme installation sous-jacente. niveau Environnement d'exécution fiable
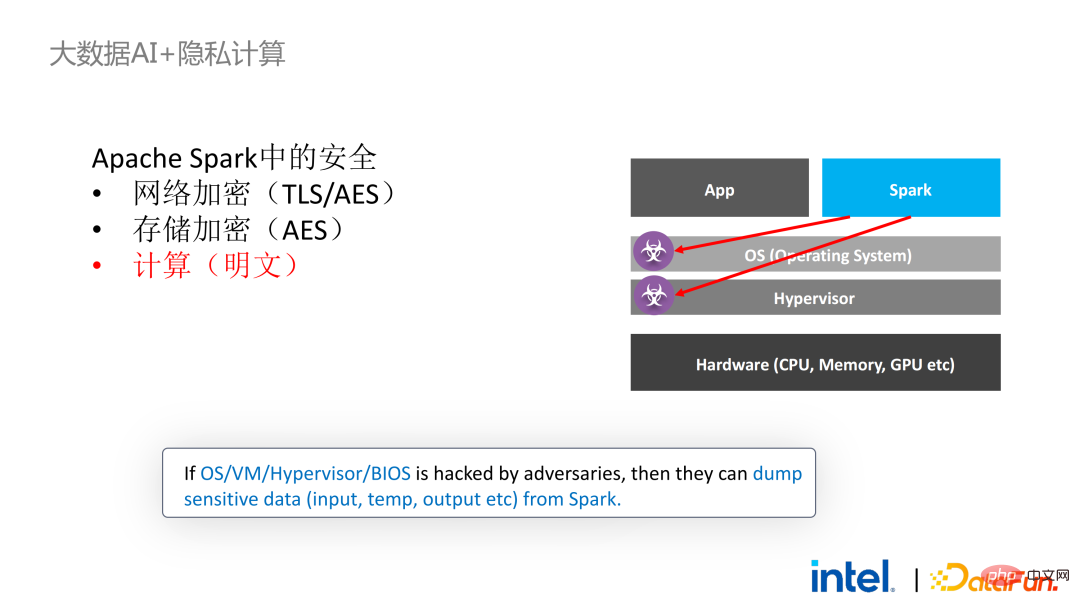 Surface d'attaque relativement petite : même si une partie du système a été compromise, tant que le processeur est sécurisé, la sécurité de l'ensemble du programme peut être assurée
Surface d'attaque relativement petite : même si une partie du système a été compromise, tant que le processeur est sécurisé, la sécurité de l'ensemble du programme peut être assurée
L'impact sur les performances est petit Une enclave suffisamment grande (maximum 1 To)
-
- Retour au scénario d'application Apache Spark mentionné précédemment :
- La gauche le côté est le cas là où l'environnement informatique n'est pas protégé, même si un stockage crypté est utilisé, tant qu'il est attaqué pendant la phase de calcul du texte en clair, il y aura un risque de fuite de données. À droite, quelques tentatives de la communauté Spark pour extraire une clé ; étapes liées à SparkSQL et réécrivez-le avec SGX SDK Une partie de la logique peut non seulement maximiser les performances, mais également minimiser la surface d'attaque. Cependant, les inconvénients de cette méthode sont également évidents, à savoir que le coût de développement est trop élevé et que le coût est trop élevé. Reconstruire la logique de base de SparkSQL nécessite une compréhension claire de Spark ; en même temps, le code ne peut pas être réutilisé dans d'autres projets ;
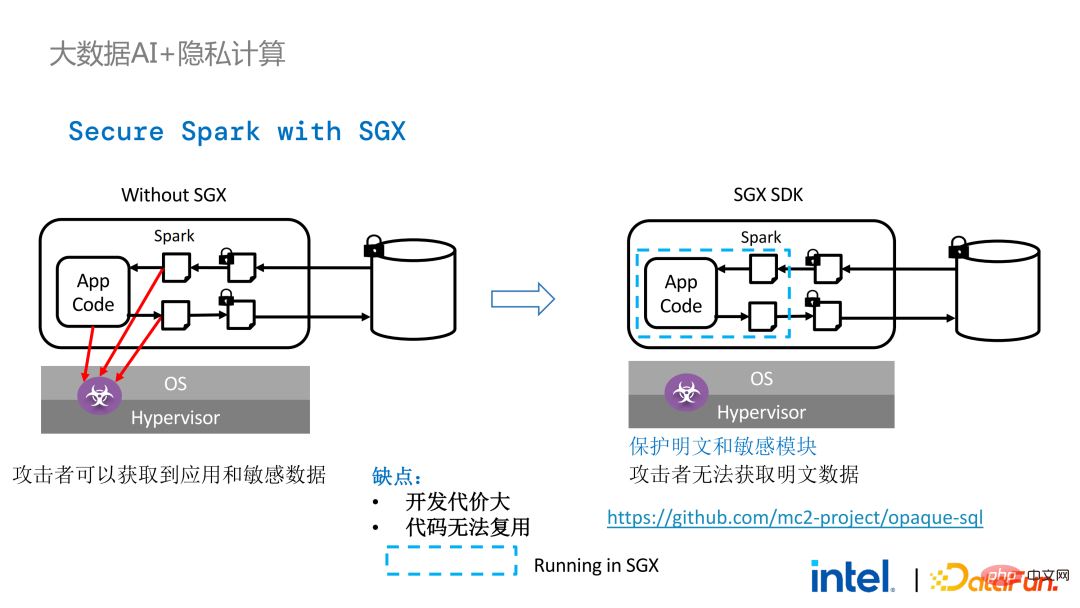
Afin de remédier aux insuffisances évoquées ci-dessus, # 🎜🎜#Nous avons utilisé la solution LibOS En bref, grâce à la couche intermédiaire de LibOS, nous réduisons la difficulté de développement et de migration, et convertissons les appels d'API système en une forme reconnaissable par le SDK SGX. , réalisant ainsi une migration transparente de routine des applications. Les solutions LibOS courantes incluent Occlum d'Ant Group, Gramine d'Intel et la solution sgx-lkl d'Imperial College. Les LibOS ci-dessus ont tous leurs propres caractéristiques et avantages, et ils résolvent les problèmes de facilité d'utilisation et de portabilité de SGX de différentes manières.
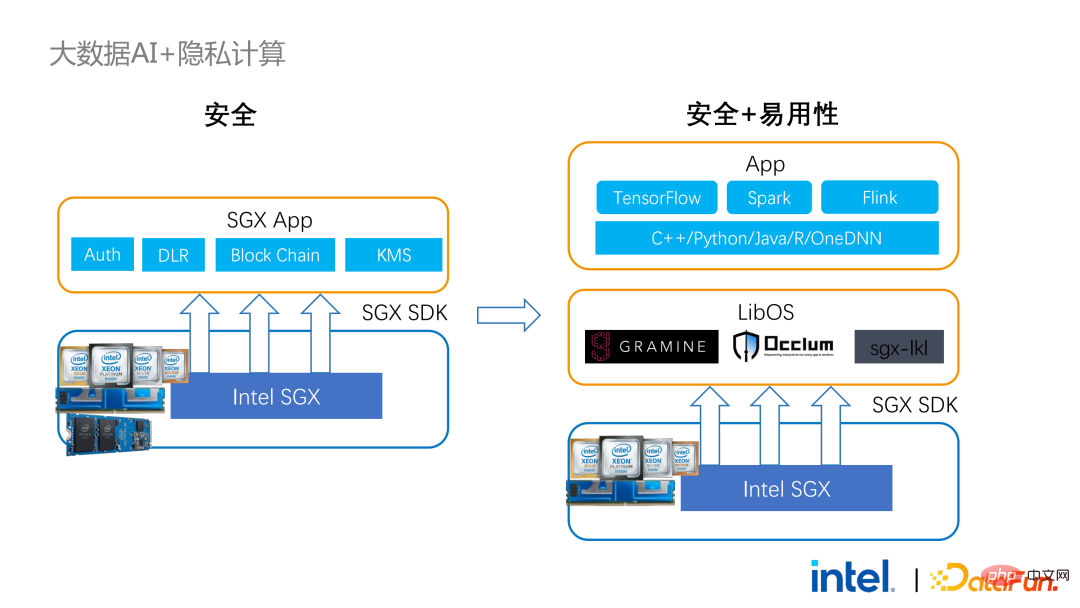
# 🎜🎜#Avec LibOS, vous n'avez plus besoin de réécrire la logique de base dans Spark. Au lieu de cela, vous pouvez mettre l'intégralité de Spark dans SGX via LibOS sans modifier Spark et les applications existantes.
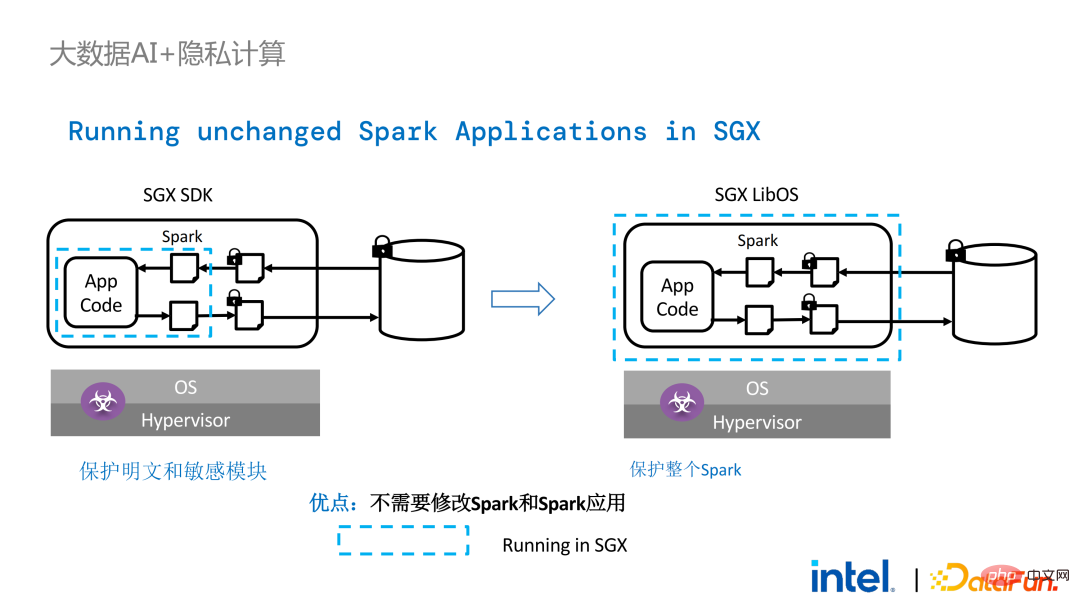
Cependant, par rapport aux applications autonomes, les problèmes de sécurité dans les applications distribuées sont également plus complexes. Les attaquants peuvent compromettre certains nœuds d'exploitation ou s'entendre avec les nœuds de gestion des ressources pour remplacer l'environnement SGX par un environnement d'exploitation malveillant. De cette manière, des clés et des données cryptées peuvent être obtenues illégalement et, à terme, des données privées peuvent être divulguées.
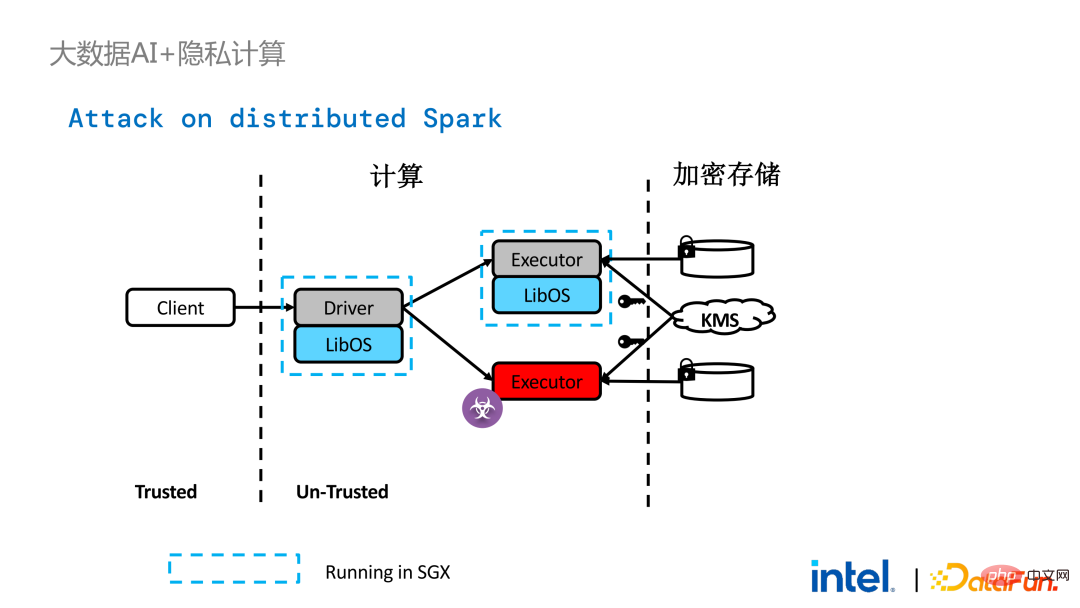
technologie d'attestation à distance doit être appliqué . Pour faire simple, les applications exécutées dans SGX peuvent fournir des certificats ou des certificats, et les certificats ou certificats ne peuvent pas être falsifiés. Le certificat peut vérifier si l'application s'exécute dans SGX, si l'application a été falsifiée et si la plateforme répond aux normes de sécurité.
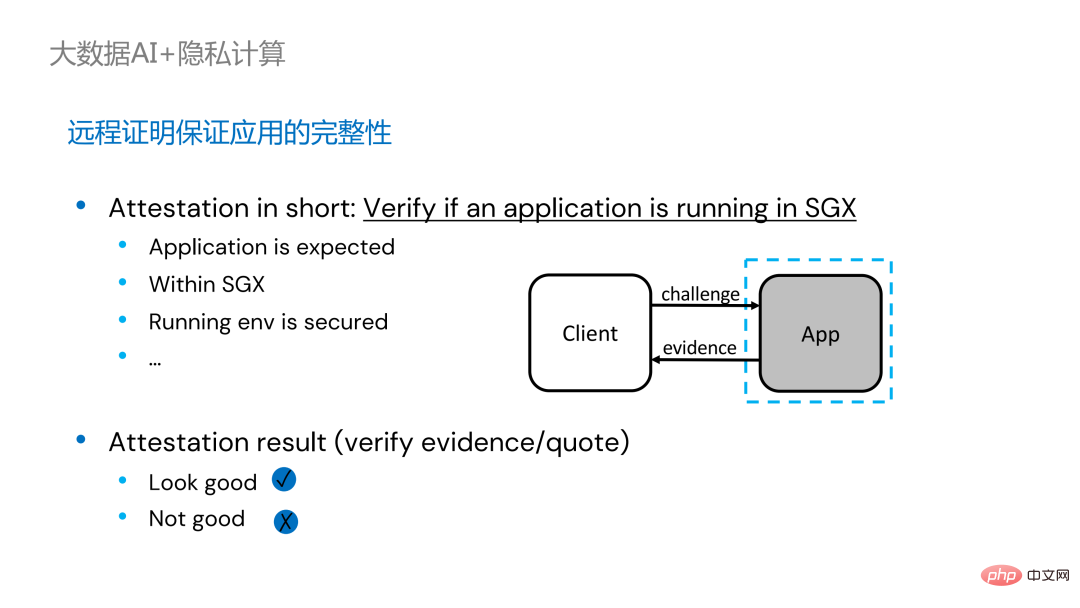
. Sur la gauche se trouve une solution relativement complète mais considérablement modifiée. Les côtés conducteur et exécuteur effectuent une certification à distance l'un de l'autre, ce qui nécessite un certain degré de modification de Spark. Une autre solution consiste à mettre en œuvre une certification à distance centralisée via un serveur de certification à distance tiers et à utiliser un certificat immuable pour empêcher les modules contrôlés par des attaquants d'obtenir des données. La deuxième option ne nécessite pas de modification de l'application, mais nécessite uniquement la modification d'une petite partie du script de démarrage.
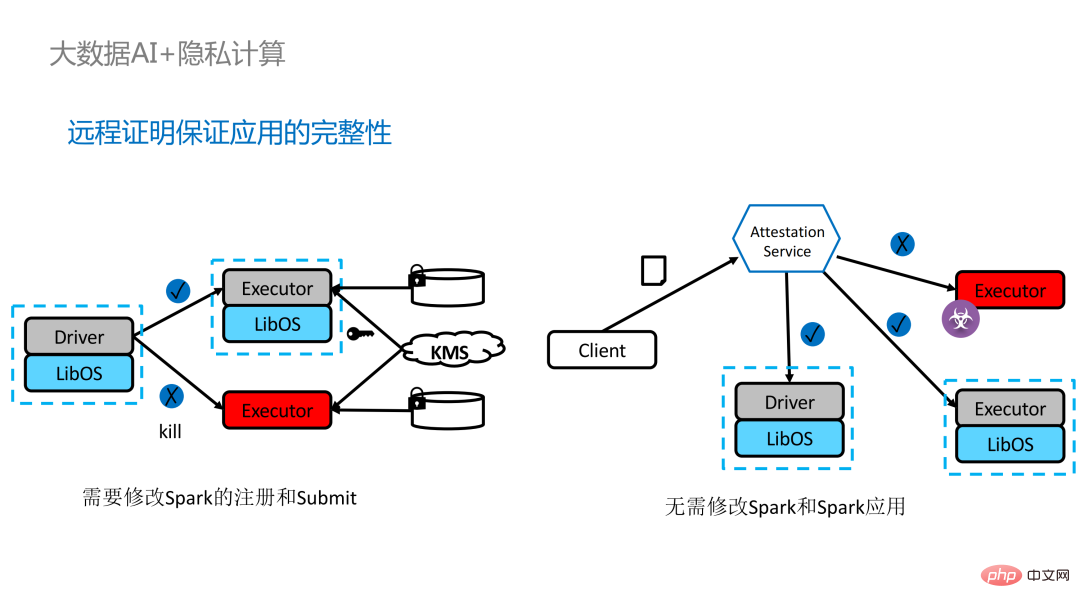 Bien que LibOS puisse permettre à Spark de s'exécuter dans SGX, il est difficile de exécuter Spark dans SGX L'adaptation de LibOS et SGX nécessite encore une certaine quantité de main d'œuvre et de temps.
Bien que LibOS puisse permettre à Spark de s'exécuter dans SGX, il est difficile de exécuter Spark dans SGX L'adaptation de LibOS et SGX nécessite encore une certaine quantité de main d'œuvre et de temps.
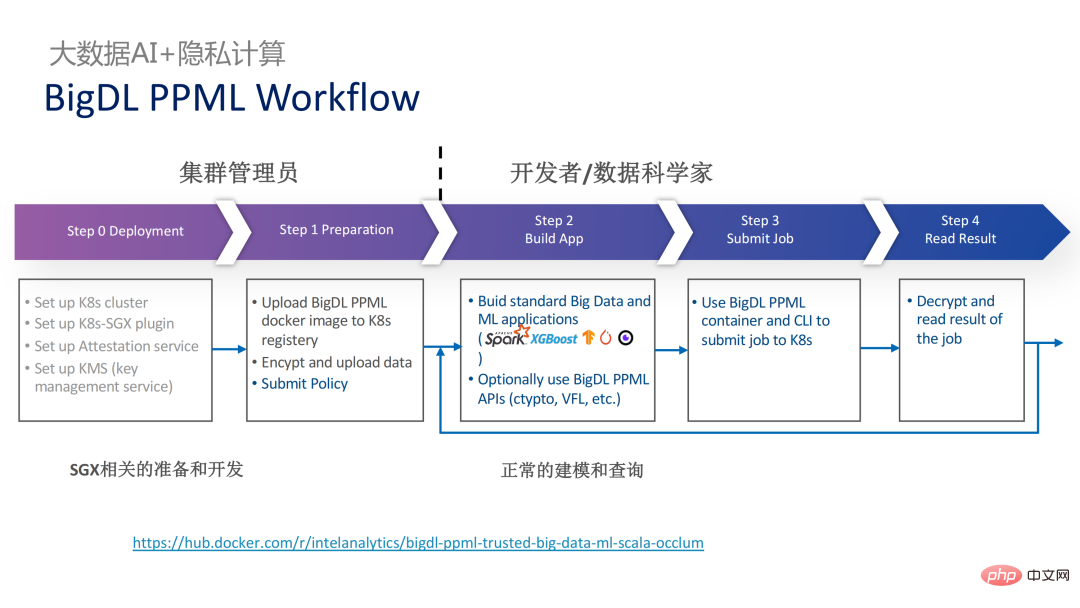
, dans laquelle de nombreuses étapes peuvent être automatisées et une migration transparente peut être réalisée, réduisant considérablement les coûts de migration.
Du point de vue du flux de travail, cette solution présente un autre avantage, c'est-à-dire que les data scientists ne peuvent pas percevoir les changements sous-jacents. Seuls les administrateurs de cluster doivent participer au déploiement et à la préparation de SGX, et les data scientists peuvent procéder normalement au travail de modélisation et de requête. ignorent complètement que l’environnement sous-jacent a changé. Cela peut bien résoudre les problèmes de compatibilité et de migration des applications existantes, et n’entravera pas le travail quotidien des data scientists et des développeurs.
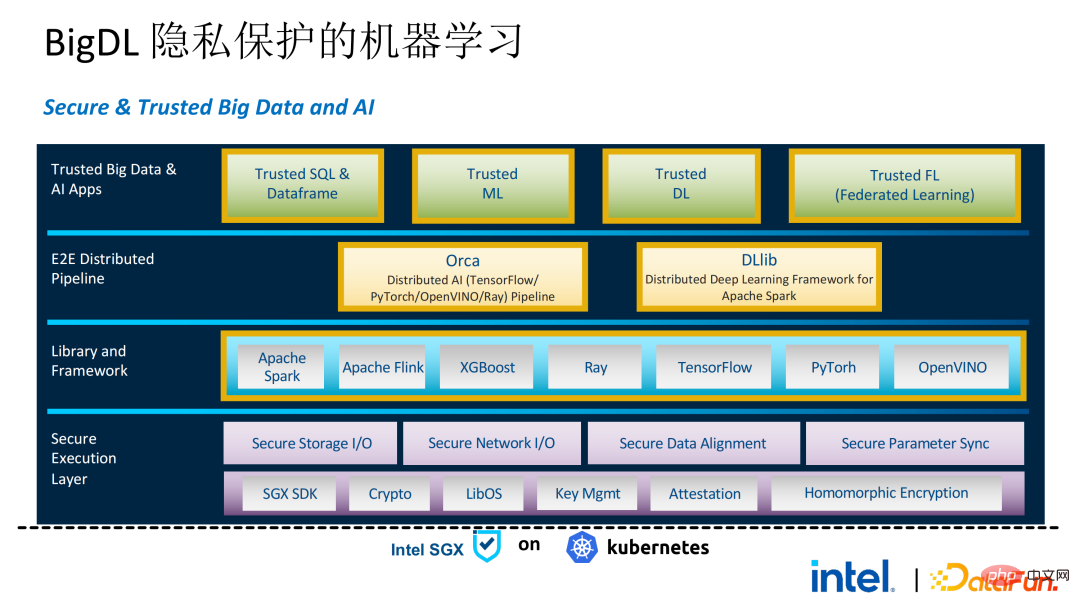
Ce qui suit est une image complète de l'ensemble de la solution PPML. Afin de répondre aux différents besoins des clients, les fonctions prises en charge par PPML ont été continuellement étendues au cours des deux dernières années. Par exemple, dans la bibliothèque et le framework de couche intermédiaire, les frameworks informatiques couramment utilisés tels que Spark, Flink et Ray sont tous pris en charge en même temps, PPML prend également en charge les fonctions d'apprentissage automatique, d'apprentissage profond et d'apprentissage fédéré et est équipé de prise en charge du stockage crypté et du cryptage homomorphe, garantissant une sécurité complète des liens de bout en bout.
03 Application Practice
Voici quelques cas pratiques d'application client, dont le plus célèbre est le Concours Tianchi de l'année dernière. Lors d'un sous-concours l'année dernière, les participants espéraient que le processus de formation et d'inférence de modèle pourrait être complètement protégé par SGX. Grâce à la fonction Flink fournie par PPML et combinée avec le projet LibOS d'Ant Group, Occlum, la formation et l'inférence de modèle pourraient être rendues invisibles. au niveau des applications. Au final, plus de 4 000 équipes ont participé à l'ensemble de la compétition et des centaines de serveurs ont été utilisés, prouvant que PPML peut prendre en charge une utilisation commerciale à grande échelle et, dans l'ensemble, les opérateurs n'ont pas perçu de grands changements.

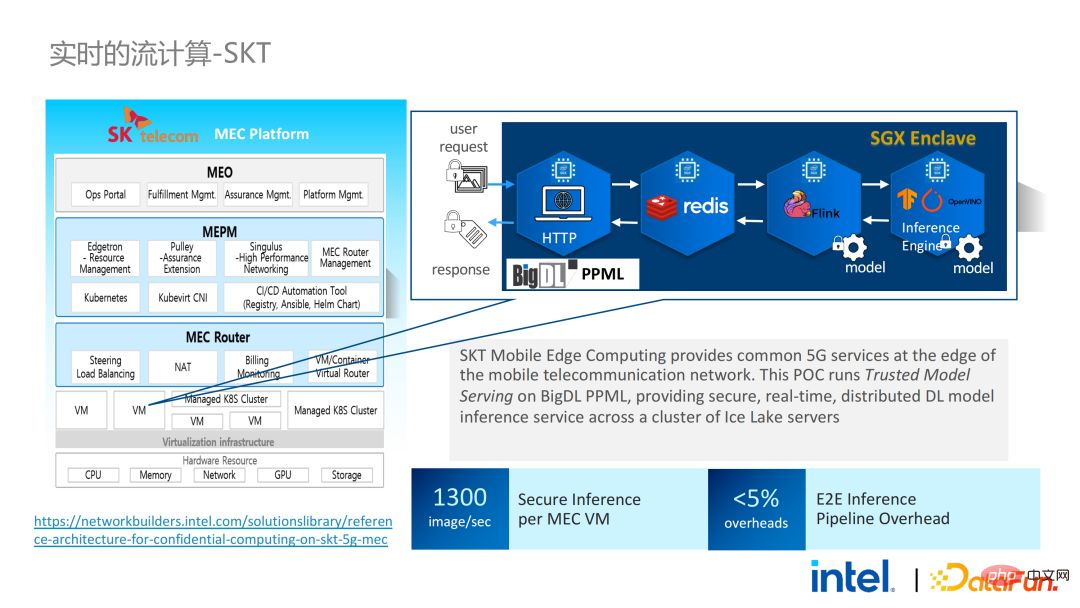
En septembre-octobre de la même année, Korea Telecom espérait créer un environnement d'inférence de modèle en temps réel sécurisé de bout en bout basé sur BigDL et Flink. Leurs exigences en matière de performances étaient même. plus rigoureux. Après l'expérience de Tianchi, la solution d'inférence de modèle en temps réel de BigDL basée sur Flink et SGX est devenue plus mature. La perte de performances de bout en bout est inférieure à 5 % et le débit a également répondu aux besoins de base de Korea Telecom.
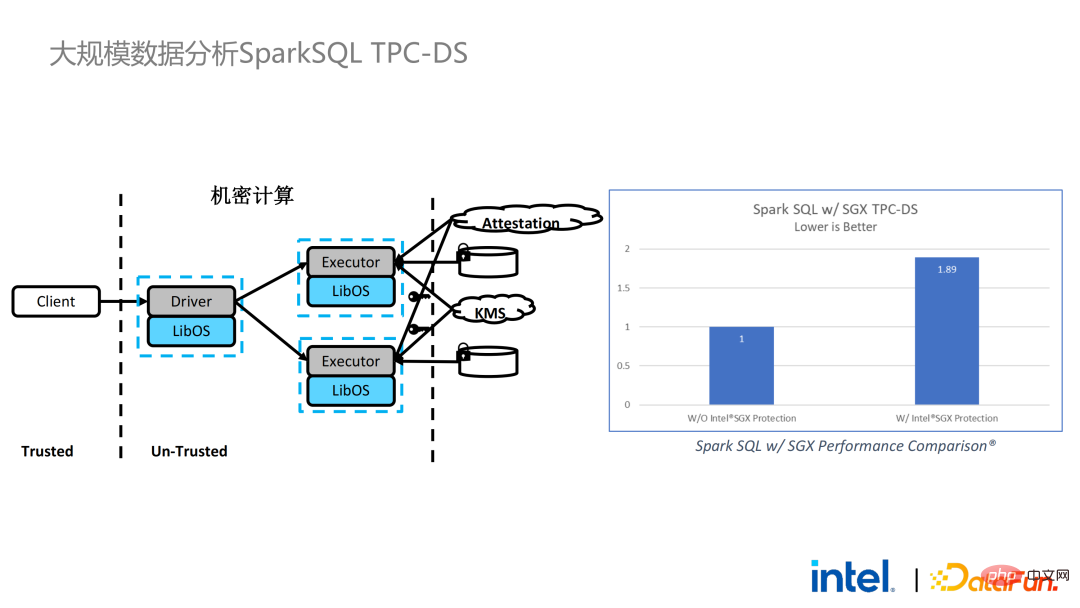
Nous avons également effectué des tests de performances Spark. En conclusion, même si les données de test atteignent des centaines de Go, il n'y a aucun problème d'évolutivité et de performances lorsque la solution PPML exécute Spark. En fonction des besoins du client, nous avons spécifiquement sélectionné TPC-DS, une application gourmande en E/S qui n'est pas conviviale pour SGX. TPC-DS est une norme de référence SQL couramment utilisée. Elle a des exigences d'E/S et de calcul relativement élevées. Lorsque la quantité de données est importante, des E/S de disque, de mémoire et de réseau à grande échelle se produisent. En tant que TEE au niveau matériel, les données entrant et sortant de SGX doivent être déchiffrées et chiffrées, de sorte que le coût de lecture et d'écriture des données sera supérieur à celui des données non-SGX. Après un test TPC-DS complet, la perte totale de bout en bout était de 2 fois supérieure, répondant ainsi aux attentes des clients. Grâce au benchmark TPC-DS, nous avons prouvé que même dans le pire des cas, nous pouvons garantir que la perte de bout en bout est réduite à une plage acceptable (1,8).
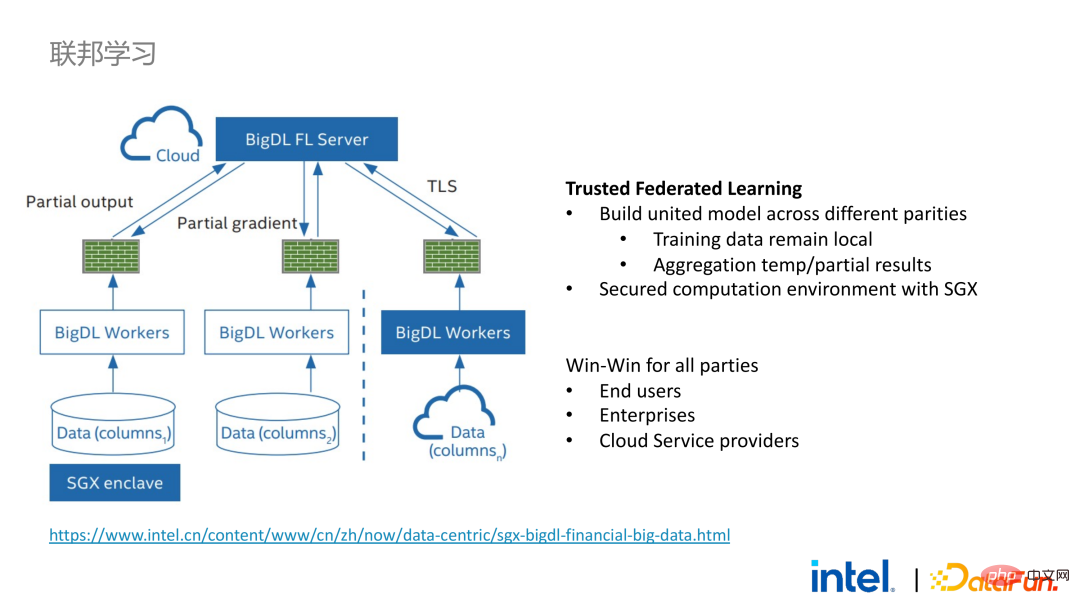
Après avoir réalisé la migration transparente des applications Big Data, nous avons également essayé l'apprentissage fédéré avec certains clients. Étant donné que SGX fournit un environnement sécurisé, il peut résoudre les problèmes de sécurité des serveurs et des données locales les plus critiques dans le processus d'apprentissage fédéré. Il existe une grande différence entre la solution d'apprentissage fédéré fournie par BigDL et la solution générale, c'est-à-dire que l'ensemble de la solution est essentiellement une solution d'apprentissage fédéré pour les données à grande échelle. Parmi eux, la charge de travail et la taille des données de chaque travailleur sont relativement importantes, et chaque travailleur équivaut à un petit cluster. Nous avons vérifié la faisabilité et l'efficacité de cette solution auprès de certains clients.
04 Résumé et perspectives
Comme mentionné ci-dessus, après deux ans chez le client , Grâce à une communication et une coopération approfondies, nous avons découvert plusieurs problèmes liés à l'informatique confidentielle et à l'IA Big Data. Ces problèmes peuvent être résolus grâce à des technologies de sécurité telles que SGX. Parmi eux, LibOS peut résoudre les problèmes de compatibilité, SGX peut résoudre les problèmes d'environnement de sécurité et de performances ; la prise en charge de Spark ou Flink peut résoudre les problèmes de Big Data et de migration ; BigDL PPML est une solution informatique de confidentialité unique qui intègre les services ci-dessus. L’écologie de SGX et TEE se développe actuellement rapidement. Dans un avenir prévisible, TEE sera considérablement amélioré en termes de facilité d'utilisation, de sécurité et de performances. Par exemple, le TDX de nouvelle génération d'Intel peut directement fournir une prise en charge du système d'exploitation, ce qui peut résoudre fondamentalement les problèmes de compatibilité des applications open source. prise en charge des conteneurs confidentiels pour garantir la sécurité des conteneurs et réduire considérablement le coût de migration des applications. Du point de vue de la sécurité, des travaux tels que le micro-noyau sembleront également renforcer davantage la sécurité de l'écosystème TEE. Du point de vue de l'évolutivité, Intel et la communauté promeuvent également la prise en charge des accélérateurs et des périphériques IO, en les intégrant dans le domaine de confiance afin de réduire la surcharge de performances du flux de données.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI