
Maison >Périphériques technologiques >IA >Lecture à vitesse véritable quantique : dépassant la limite du GPT-4 qui ne peut comprendre que 50 pages de texte à la fois, de nouvelles recherches s'étendent à des millions de jetons
Lecture à vitesse véritable quantique : dépassant la limite du GPT-4 qui ne peut comprendre que 50 pages de texte à la fois, de nouvelles recherches s'étendent à des millions de jetons

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-28 10:37:241092parcourir
Il y a plus d'un mois, le GPT-4 d'OpenAI est sorti. En plus de diverses excellentes démonstrations visuelles, il implémente également une mise à jour importante : il peut gérer des jetons de contexte d'une longueur de 8 Ko par défaut, mais peuvent atteindre 32 Ko (environ 50 pages de texte). Cela signifie que lorsque nous posons des questions à GPT-4, nous pouvons saisir un texte beaucoup plus long qu'auparavant. Cela élargit considérablement les scénarios d'application de GPT-4 et permet de mieux gérer les longues conversations, les textes longs ainsi que la recherche et l'analyse de fichiers.
Cependant, ce record a été rapidement battu : CoLT5 de Google Research a étendu la longueur du jeton de contexte que le modèle peut gérer à 64k.
Une telle avancée n'est pas facile, car ces modèles utilisant l'architecture Transformer sont tous confrontés à un problème : le traitement de documents longs par Transformer est très coûteux en termes de calcul, car le coût d'attention augmente quadratiquement avec la longueur d'entrée, ce qui rend les grands modèles de plus en plus difficiles. à appliquer aux entrées plus longues.
Malgré cela, les chercheurs continuent de faire des percées dans cette direction. Il y a quelques jours, une étude de la pile technologique open source d'IA conversationnelle DeepPavlov et d'autres institutions a montré que : En utilisant une architecture appelée Recurrent Memory Transformer (RMT), ils peuvent augmenter la longueur de contexte effective du modèle BERT à 2 millions. token (selon la méthode de calcul d'OpenAI, environ équivalent à 3200 pages de texte), tout en conservant une précision de récupération de mémoire élevée (Remarque : Recurrent Memory Transformer est une méthode proposée par Aydar Bulatov et al. dans un article à NeurIPS 2022) . La nouvelle méthode permet le stockage et le traitement d'informations locales et globales, ainsi que le flux d'informations entre les segments de la séquence d'entrée grâce à l'utilisation de la récurrence.

L'auteur a déclaré qu'en utilisant le mécanisme de mémoire simple basé sur des jetons introduit par Bulatov et al dans l'article "Recurrent Memory Transformer", ils peuvent combiner RMT avec un modèle de Transformer pré-entraîné comme BERT. , Un seul GPU Nvidia GTX 1080Ti peut effectuer des opérations de pleine attention et de précision sur des séquences de plus d'un million de jetons.

Adresse papier : https://arxiv.org/pdf/2304.11062.pdf
Cependant, certaines personnes ont rappelé qu'il ne s'agissait pas d'un véritable "déjeuner gratuit", comme mentionné ci-dessus L'amélioration du papier s'obtient en échange d'un « temps de raisonnement plus long + une diminution substantielle de la qualité ». Ce n’est donc pas encore une révolution, mais cela pourrait devenir la base du prochain paradigme (les jetons peuvent être infiniment longs).
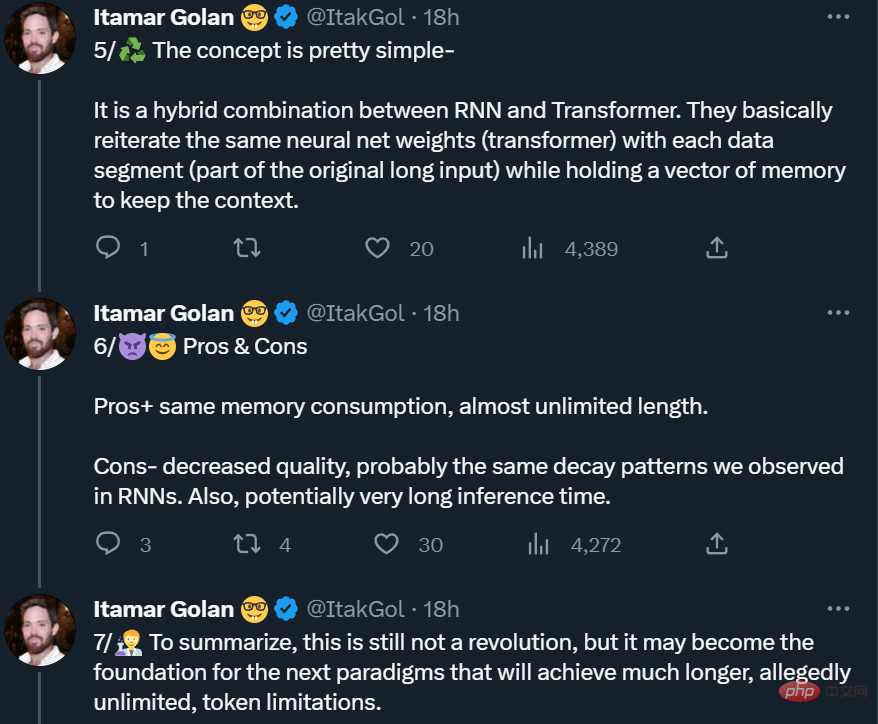
Recurrent Memory Transformer
Cette étude adopte la méthode Recurrent Memory Transformer (RMT) proposée par Bulatov et al en 2022, et la transforme en une méthode plug-and-play. montré dans la figure ci-dessous :
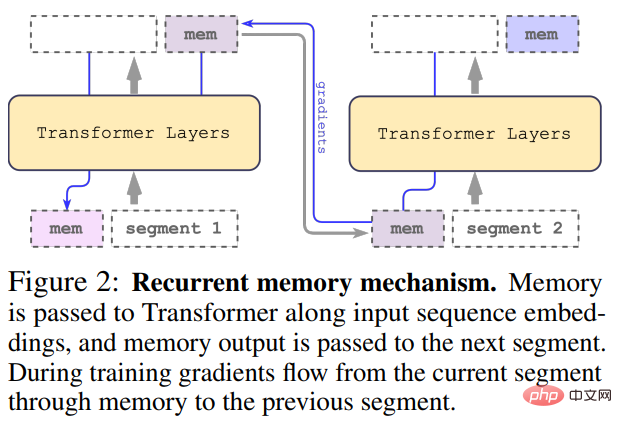
L'entrée longue est divisée en plusieurs segments et le vecteur mémoire est ajouté au premier segment avant l'intégration et traité avec le jeton de segment. Pour les modèles de codeur pur comme BERT, la mémoire n'est ajoutée qu'une seule fois au début du segment, contrairement à (Bulatov et al., 2022), où le modèle de décodeur pur divise la mémoire en parties de lecture et d'écriture. Pour le pas de temps τ et le segment
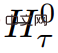
, la boucle s'exécute comme suit :

où, N est le nombre de couches de Transformer. Après propagation vers l'avant,
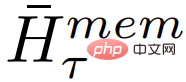
contient le jeton mémoire mis à jour du segment τ.
Les segments de la séquence d'entrée sont traités dans l'ordre. Pour activer les connexions en boucle, l'étude transmet la sortie des jetons de mémoire du segment actuel à l'entrée du segment suivant :
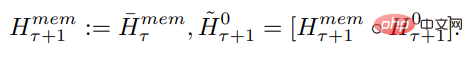
La mémoire et les boucles dans RMT sont basées uniquement sur des jetons de mémoire globaux. Cela permet au Transformer de base de rester inchangé, ce qui rend les capacités d'amélioration de la mémoire de RMT compatibles avec n'importe quel modèle de Transformer.
Efficacité informatique
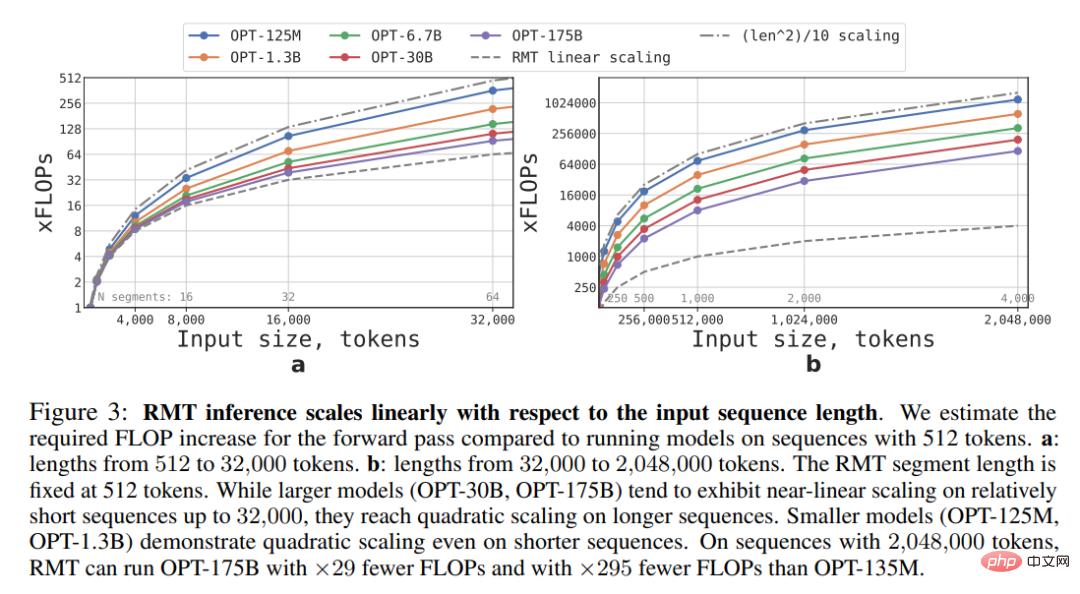
Cette étude estime les FLOP requis pour les modèles RMT et Transformer de différentes tailles et longueurs de séquence.
Comme le montre la figure 3 ci-dessous, si la longueur du segment est fixe, RMT peut évoluer linéairement pour n'importe quelle taille de modèle. Cette étude réalise une mise à l'échelle linéaire en divisant la séquence d'entrée en segments et en calculant la matrice d'attention complète uniquement dans les limites des segments.
En raison de la grande complexité informatique de la couche FFN, les modèles de transformateur plus grands ont tendance à présenter une mise à l'échelle quadratique plus lente avec la longueur de la séquence. Cependant, pour les très longues séquences supérieures à 32 000, elles reviennent à une expansion quadratique. Pour les séquences comportant plus d'un segment (> 512 dans cette étude), le RMT nécessite moins de FLOP que les modèles acycliques et peut réduire le nombre de FLOP jusqu'à 295 fois. RMT offre une réduction relative plus importante du FLOP pour les modèles plus petits, mais la réduction de 29x du FLOP pour le modèle OPT-175B est significative en termes absolus.
Tâche de mémoire
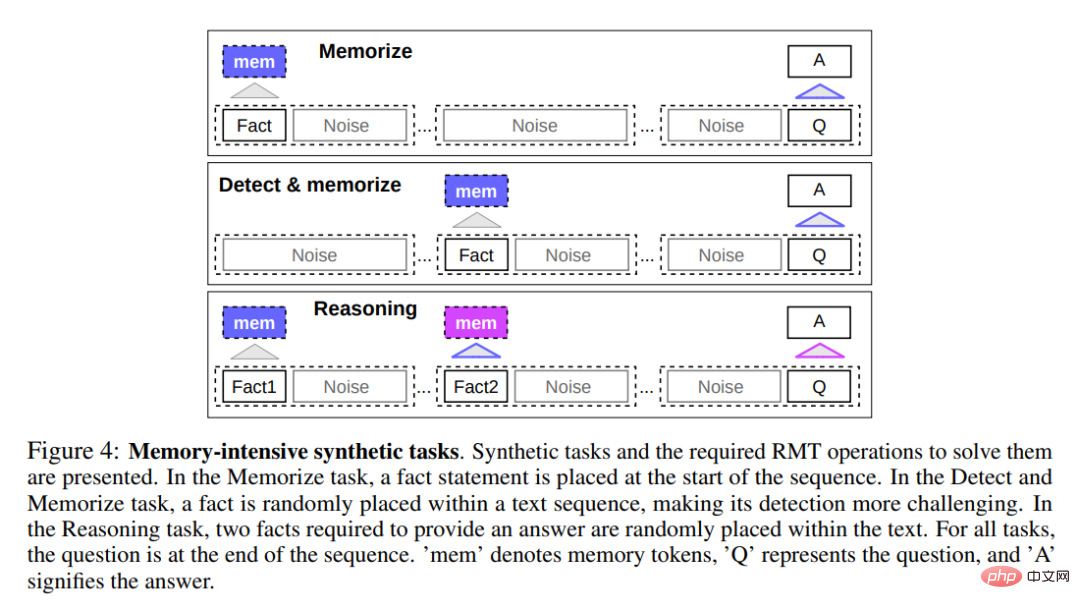
Pour tester les capacités de mémoire, l'étude a construit des ensembles de données synthétiques qui nécessitaient la mémorisation de faits simples et d'un raisonnement de base. La saisie d'une tâche consiste en un ou plusieurs faits et une question à laquelle on ne peut répondre qu'en utilisant tous les faits. Pour augmenter la difficulté de la tâche, l'étude a également ajouté un texte en langage naturel sans rapport avec la question ou la réponse pour agir comme du bruit. Le modèle a donc été chargé de séparer les faits du texte non pertinent et d'utiliser les faits pour répondre à la question.

Mémoire factuelle
La première tâche consistait à examiner la capacité du RMT à écrire et à stocker des informations en mémoire pendant de longues périodes, comme le montre le haut de la figure 4 ci-dessous. Dans le cas le plus simple, les faits ont tendance à se trouver au début de la contribution et les questions à la fin. La quantité de texte non pertinent entre les questions et les réponses augmente progressivement jusqu'au point où l'intégralité de l'entrée ne rentre plus dans une seule entrée de modèle.

Détection et mémoire des faits
La détection des faits augmente la difficulté de la tâche en déplaçant un fait vers une position aléatoire dans l'entrée, comme indiqué au milieu de la figure 4 ci-dessus. Cela nécessite que le modèle distingue d'abord le fait du texte non pertinent, écrive le fait en mémoire, puis l'utilise pour répondre à la question finale.
Utiliser des faits mémorisés pour raisonner
Une autre opération de mémoire consiste à utiliser des faits mémorisés et le contexte actuel pour raisonner. Pour évaluer cette fonctionnalité, les chercheurs ont utilisé une tâche plus complexe dans laquelle deux faits ont été générés et placés dans une séquence d'entrée, comme le montre le bas de la figure 4 ci-dessus. La question posée à la fin de la séquence est décrite de telle manière que des faits arbitraires doivent être utilisés pour répondre correctement à la question.

Résultats expérimentaux
Les chercheurs ont utilisé 4 à 8 GPU NVIDIA 1080ti pour entraîner et évaluer le modèle. Pour les séquences plus longues, ils ont utilisé un seul NVIDIA A100 de 40 Go pour accélérer l'évaluation.
Cours d'apprentissage
Les chercheurs ont observé que l'utilisation du plan de formation peut améliorer considérablement la précision et la stabilité de la solution. Initialement, RMT est formé sur une version plus courte de la tâche et augmente la durée de la tâche en ajoutant un autre segment à mesure que la formation converge. Le processus d'apprentissage du cours se poursuit jusqu'à ce que la longueur de saisie requise soit atteinte.
Dans l'expérience, les chercheurs ont d'abord commencé avec une séquence adaptée à un seul segment. La taille réelle du segment est de 499, mais en raison des 3 jetons spéciaux de BERT et des 10 espaces réservés de mémoire retenus à partir de l'entrée du modèle, la taille est de 512. Ils notent qu'après une formation sur une tâche plus courte, le RMT est plus facile à résoudre des versions plus longues de la tâche, grâce au fait qu'il utilise moins d'étapes de formation pour converger vers une solution parfaite.
Capacité d'extrapolation
Quelle est la capacité de généralisation du RMT à différentes longueurs de séquence ? Pour répondre à cette question, les chercheurs ont évalué des modèles entraînés sur différents nombres de segments pour résoudre des tâches plus longues, comme le montre la figure 5 ci-dessous.
Ils ont observé que les modèles ont tendance à être plus performants sur des tâches plus courtes, à la seule exception étant la tâche d'inférence à segment unique, qui devient difficile à résoudre une fois que le modèle est entraîné sur des séquences plus longues. Une explication possible est que, puisque la taille de la tâche dépasse un segment, le modèle « ne s'attend plus » à des problèmes dans le premier segment, ce qui entraîne une diminution de la qualité.
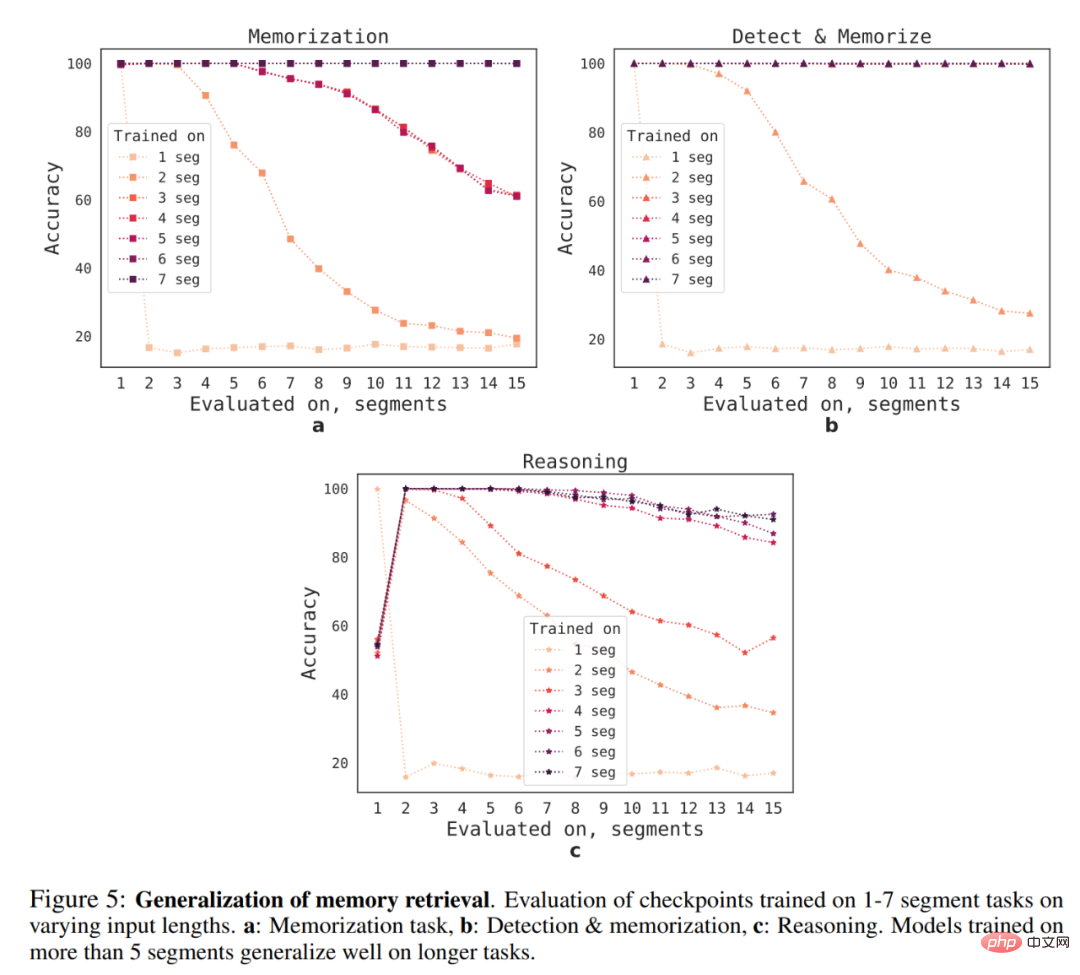
Fait intéressant, la capacité du RMT à généraliser à des séquences plus longues apparaît également à mesure que le nombre de segments d’entraînement augmente. Après un entraînement sur 5 segments ou plus, le RMT peut généraliser presque parfaitement à des tâches deux fois plus longues.
Pour tester les limites de la généralisation, les chercheurs ont augmenté la taille de la tâche de vérification à 4 096 segments ou 2 043 904 jetons (comme le montre la figure 1 ci-dessus). Les tâches de détection et de mémoire sont les plus simples et les tâches d'inférence sont les plus complexes.
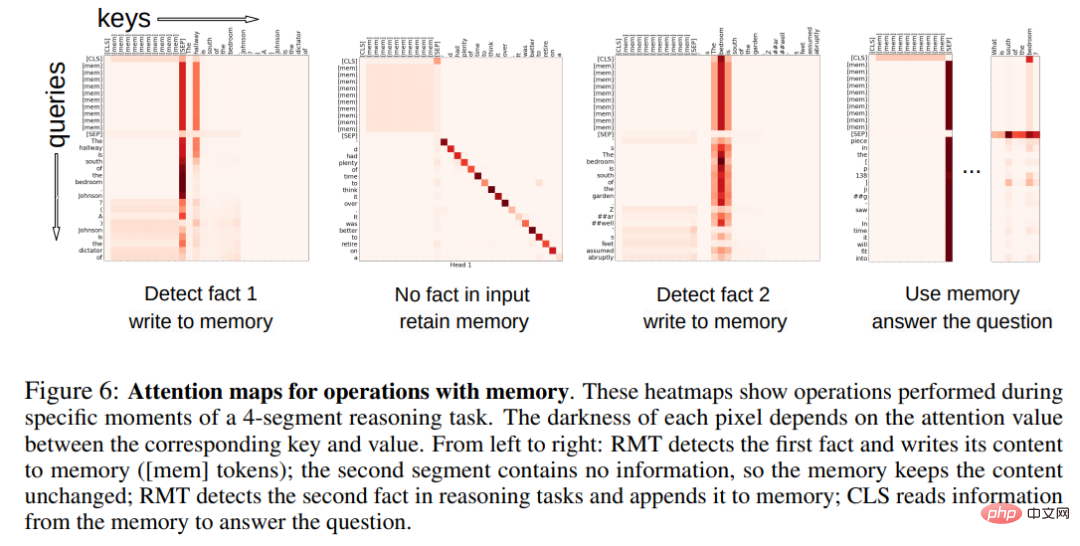
Modèle d'attention des opérations de mémoire
Dans la figure 6 ci-dessous, en examinant l'attention RMT sur des segments spécifiques, le chercheur a observé que les opérations de mémoire correspondent à des modèles d'attention spécifiques. De plus, les performances d'extrapolation élevées sur des séquences extrêmement longues dans la section 5.2 démontrent l'efficacité des opérations de mémoire apprises, même lorsqu'elles sont utilisées des milliers de fois.
Veuillez vous référer à l'article original pour plus de détails techniques et expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI