
Maison >Périphériques technologiques >IA >Google optimise le modèle de diffusion. Les téléphones mobiles Samsung exécutent Stable Diffusion et produisent des images en 12 secondes.
Google optimise le modèle de diffusion. Les téléphones mobiles Samsung exécutent Stable Diffusion et produisent des images en 12 secondes.

- 王林avant
- 2023-04-28 08:19:141060parcourir
Stable Diffusion est aussi connu dans le domaine de la génération d'images que ChatGPT dans le grand modèle de conversation. Il est capable de créer des images réalistes de n’importe quel texte saisi en quelques dizaines de secondes. Étant donné que Stable Diffusion comporte plus d'un milliard de paramètres et que les ressources de calcul et de mémoire de l'appareil sont limitées, ce modèle est principalement exécuté dans le cloud.
Sans une conception et une mise en œuvre minutieuses, l'exécution de ces modèles sur des appareils peut entraîner une latence accrue en raison du processus de débruitage itératif et d'une consommation excessive de mémoire.
Comment exécuter Stable Diffusion sur l'appareil a suscité l'intérêt de tous les chercheurs. Auparavant, un chercheur a développé une application qui utilise Stable Diffusion pour générer des images sur l'iPhone 14 Pro en seulement une minute et utilise environ 2 Go de mémoire d'application.
Apple a également apporté quelques optimisations à cela auparavant. Ils peuvent générer une image avec une résolution de 512x512 en une demi-minute sur iPhone, iPad, Mac et autres appareils. Qualcomm suit de près, exécutant Stable Diffusion v1.5 sur les téléphones Android, générant des images avec une résolution de 512 x 512 en moins de 15 secondes.
Récemment, dans un article "La vitesse est tout ce dont vous avez besoin : accélération sur appareil de modèles de diffusion à grande échelle via des optimisations GPU-Aware" publié par Google, ils ont implémenté Stable Diffusion 1.4 fonctionnant sur un appareil piloté par GPU, atteignant Performances de latence d'inférence SOTA (sur Samsung S23 Ultra, il ne faut que 11,5 secondes pour générer une image 512 × 512 en 20 itérations). De plus, cette étude n’est pas spécifique à un appareil ; il s’agit plutôt d’une approche générale applicable à l’amélioration de tous les modèles de diffusion potentiels.
Cette recherche ouvre de nombreuses possibilités pour exécuter une IA générative localement sur votre téléphone sans connexion de données ni serveur cloud. Stable Diffusion n'a été lancé que l'automne dernier et peut déjà être branché sur des appareils et exécuté aujourd'hui, ce qui montre à quelle vitesse ce domaine se développe.

Adresse papier : https://arxiv.org/pdf/2304.11267.pdf
Afin d'atteindre cette vitesse de génération, Google a proposé quelques suggestions d'optimisation. Voyons comment Google fait. il. Optimisé.
Introduction à la méthode
Cette recherche vise à proposer des méthodes d'optimisation pour améliorer la vitesse des diagrammes vincentiens de modèles de diffusion à grande échelle, y compris quelques suggestions d'optimisation pour la diffusion stable, qui sont également applicables à d'autres modèles de diffusion à grande échelle.
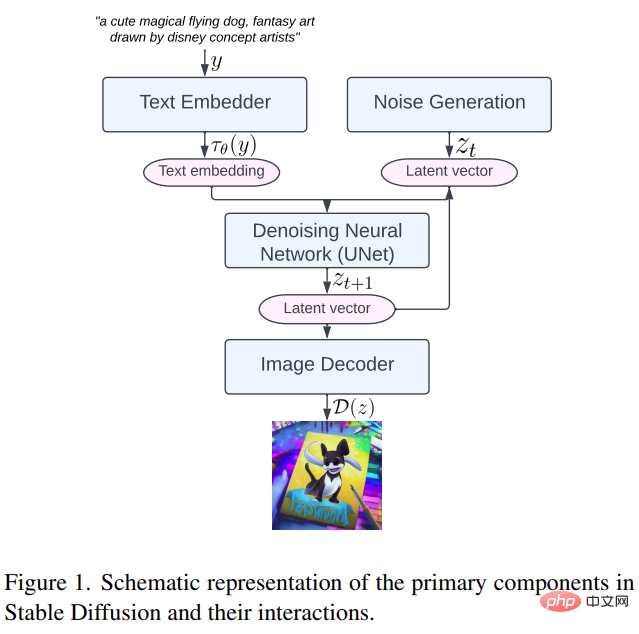
Tout d'abord, examinons les principaux composants de Stable Diffusion, notamment : l'intégration de texte, la génération de bruit, le réseau neuronal de débruitage et le décodeur d'image, comme suit. Comme le montre la figure 1.
Ensuite, nous examinons spécifiquement les trois méthodes d'optimisation proposées dans cette étude
Noyaux spécialisés : Group Norm et GELU
( Le principe de fonctionnement de la méthode GN est de diviser les canaux de la carte de caractéristiques en groupes plus petits et normaliser chaque groupe indépendamment, rendant ainsi GN moins dépendant de la taille du lot et plus adapté à différents lots et architectures de réseau. Au lieu d'effectuer des opérations de remodelage, de moyenne, de variance et de normalisation en séquence, cette recherche a conçu une forme de shader GPU unique. de noyau qui peut effectuer toutes ces opérations dans une seule commande GPU. Sans aucun tenseur intermédiaire
L'unité linéaire d'erreur gaussienne (GELU) est une fonction d'activation de modèle couramment utilisée qui contient un grand nombre de calculs numériques, tels que la multiplication, l'addition. , et les fonctions d'erreur gaussienne. Cette étude utilise un shader dédié. Consolidez ces calculs numériques et les opérations de division et de multiplication qui les accompagnent afin qu'ils puissent être effectués en un seul appel de peinture AI
Amélioration de l'efficacité du module d'attention.
.Le transformateur texte en image de Stable Diffusion aide à modéliser les distributions conditionnelles, ce qui est crucial pour les tâches de génération de texte en image. Cependant, les mécanismes d’auto-attention et d’attention croisée rencontrent des difficultés dans le traitement de longues séquences en raison de la complexité de la mémoire et de la complexité temporelle. Sur cette base, cette étude propose deux méthodes d'optimisation pour atténuer le goulot d'étranglement informatique.
D'une part, afin d'éviter d'effectuer l'intégralité du calcul softmax sur une grande matrice, cette recherche utilise un shader GPU pour réduire les opérations de calcul, réduisant considérablement l'empreinte mémoire et la latence globale du tenseur intermédiaire. est illustré dans la figure 2 ci-dessous.

D'autre part, cette étude utilise FlashAttention [7], un algorithme d'attention précis sensible aux IO, qui rend le nombre d'accès à la mémoire à large bande passante (HBM) inférieur au mécanisme d'attention standard, améliorant l’efficacité globale.
Convolution Winograd
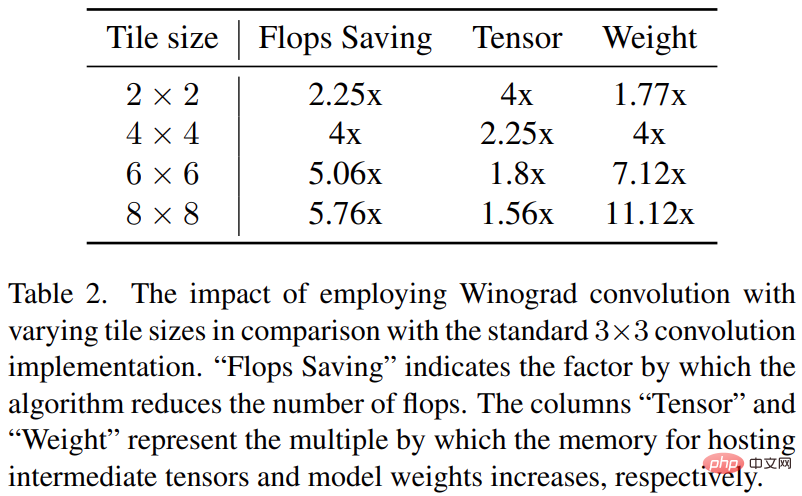
La convolution Winograd convertit l'opération de convolution en une série de multiplications matricielles. Cette méthode peut réduire de nombreuses opérations de multiplication et améliorer l'efficacité des calculs. Cependant, cela augmente également la consommation de mémoire et les erreurs numériques, en particulier lors de l'utilisation de tuiles plus grandes.
L'épine dorsale de Stable Diffusion repose fortement sur des couches convolutionnelles 3×3, notamment dans le décodeur d'images, où elles représentent 90 %. Cette étude fournit une analyse approfondie de ce phénomène pour explorer les avantages potentiels de l'utilisation de Winograd avec différentes tailles de tuiles sur des convolutions de noyau 3 × 3. Des recherches ont montré qu'une taille de tuile de 4 × 4 est optimale car elle offre le meilleur équilibre entre l'efficacité de calcul et l'utilisation de la mémoire.
L'étude a été comparée sur une variété d'appareils : Samsung S23 Ultra (Adreno 740) et iPhone 14 Pro Max (A16). Les résultats du benchmark sont présentés dans le tableau 1 ci-dessous :
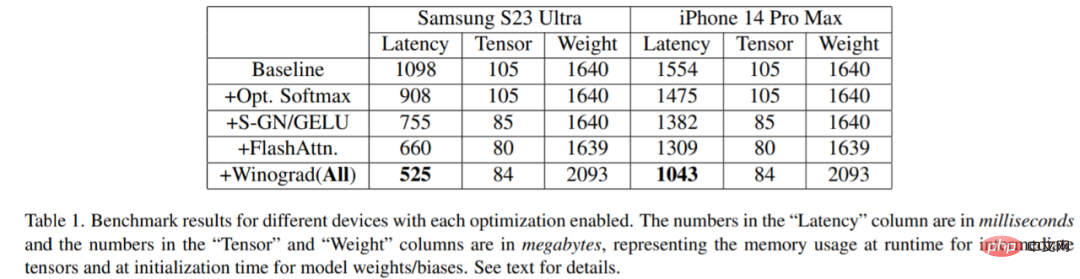
Il est évident qu'à mesure que chaque optimisation est activée, la latence diminue progressivement (peut être comprise comme le temps de génération des images diminue). Plus précisément, par rapport à la référence : réduction de la latence de 52,2 % sur le Samsung S23 Ultra ; réduction de la latence de 32,9 % sur l’iPhone 14 Pro Max. En outre, l'étude évalue également la latence de bout en bout du Samsung S23 Ultra, générant une image de 512 × 512 pixels en 20 étapes d'itération de débruitage, obtenant ainsi des résultats SOTA en moins de 12 secondes.
Les petits appareils peuvent exécuter leurs propres modèles d'IA génératifs. Qu'est-ce que cela signifie pour l'avenir ? On peut s'attendre à une vague.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI