
Maison >développement back-end >Tutoriel Python >Ces bibliothèques Python intéressantes et puissantes
Ces bibliothèques Python intéressantes et puissantes

- 王林avant
- 2023-04-27 20:49:042223parcourir
ython Le langage a toujours été réputé pour ses riches bibliothèques tierces. Aujourd'hui, je vais vous présenter de très belles bibliothèques, amusantes, amusantes et puissantes !
Collecte de données
À l'ère d'Internet d'aujourd'hui, les données sont vraiment importantes. Tout d'abord, présentons plusieurs excellents projets de collecte de données
AKShare
.AKShare est une bibliothèque d'interface de données financières basée sur Python. Elle vise à générer des données fondamentales, des données en temps réel et historiques de produits financiers tels que les actions, les contrats à terme, les options, les fonds, les devises, les obligations, les indices et les crypto-monnaies. . Un ensemble d'outils pour les données de marché et les données dérivées de la collecte de données, du nettoyage des données à la mise en œuvre des données, principalement utilisés à des fins de recherche universitaire.
import akshare as ak stock_zh_a_hist_df = ak.stock_zh_a_hist(symbol="000001", period="daily", start_date="20170301", end_date='20210907', adjust="") print(stock_zh_a_hist_df)
Sortie :
日期开盘 收盘最高...振幅 涨跌幅 涨跌额 换手率 0 2017-03-01 9.49 9.49 9.55...0.840.110.010.21 1 2017-03-02 9.51 9.43 9.54...1.26 -0.63 -0.060.24 2 2017-03-03 9.41 9.40 9.43...0.74 -0.32 -0.030.20 3 2017-03-06 9.40 9.45 9.46...0.740.530.050.24 4 2017-03-07 9.44 9.45 9.46...0.630.000.000.17 ............... ... ... ... ... 11002021-09-0117.4817.8817.92...5.110.450.081.19 11012021-09-0218.0018.4018.78...5.482.910.521.25 11022021-09-0318.5018.0418.50...4.35 -1.96 -0.360.72 11032021-09-0617.9318.4518.60...4.552.270.410.78 11042021-09-0718.6019.2419.56...6.564.280.790.84 [1105 rows x 11 columns]
https://github.com/akfamily/akshare
TuShare#🎜 🎜#
TuShare est un outil qui met en œuvre la collecte, le nettoyage et le traitement des données financières telles que les actions/futures. Il répond aux besoins d'acquisition de données des analystes financiers quantitatifs et des personnes qui étudient l'analyse des données. caractéristiques Il a une large couverture de données, une interface d'appel simple et une réponse rapide. Cependant, certaines fonctions de ce projet sont payantes, veuillez choisir de les utiliserimport tushare as ts
ts.get_hist_data('600848') #一次性获取全部数据Output:openhigh close low volumep_changema5 date 2012-01-11 6.880 7.380 7.060 6.880 14129.96 2.62 7.060 2012-01-12 7.050 7.100 6.980 6.9007895.19-1.13 7.020 2012-01-13 6.950 7.000 6.700 6.6906611.87-4.01 6.913 2012-01-16 6.680 6.750 6.510 6.4802941.63-2.84 6.813 2012-01-17 6.660 6.880 6.860 6.4608642.57 5.38 6.822 2012-01-18 7.000 7.300 6.890 6.880 13075.40 0.44 6.788 2012-01-19 6.690 6.950 6.890 6.6806117.32 0.00 6.770 2012-01-20 6.870 7.080 7.010 6.8706813.09 1.74 6.832 ma10ma20v_ma5 v_ma10 v_ma20 turnover date 2012-01-11 7.060 7.060 14129.96 14129.96 14129.96 0.48 2012-01-12 7.020 7.020 11012.58 11012.58 11012.58 0.27 2012-01-13 6.913 6.9139545.679545.679545.67 0.23 2012-01-16 6.813 6.8137894.667894.667894.66 0.10 2012-01-17 6.822 6.8228044.248044.248044.24 0.30 2012-01-18 6.833 6.8337833.338882.778882.77 0.45 2012-01-19 6.841 6.8417477.768487.718487.71 0.21 2012-01-20 6.863 6.8637518.008278.388278.38 0.23
https:/ / github.com/waditu/tushare
GoPUPLes données collectées par le projet GoPUP proviennent toutes de sources de données publiques et n'impliquent aucune donnée de confidentialité personnelle et les données non publiques. Mais de la même manière, certaines interfaces nécessitent un enregistrement TOKEN avant de pouvoir être utilisées.import gopup as gp df = gp.weibo_index(word="疫情", time_type="1hour") print(df)Sortie :
疫情 index 2022-12-17 18:15:0018544 2022-12-17 18:20:0014927 2022-12-17 18:25:0013004 2022-12-17 18:30:0013145 2022-12-17 18:35:0013485 2022-12-17 18:40:0014091 2022-12-17 18:45:0014265 2022-12-17 18:50:0014115 2022-12-17 18:55:0015313 2022-12-17 19:00:0014346 2022-12-17 19:05:0014457 2022-12-17 19:10:0013495 2022-12-17 19:15:0014133
https://github.com/justinzm/gopup
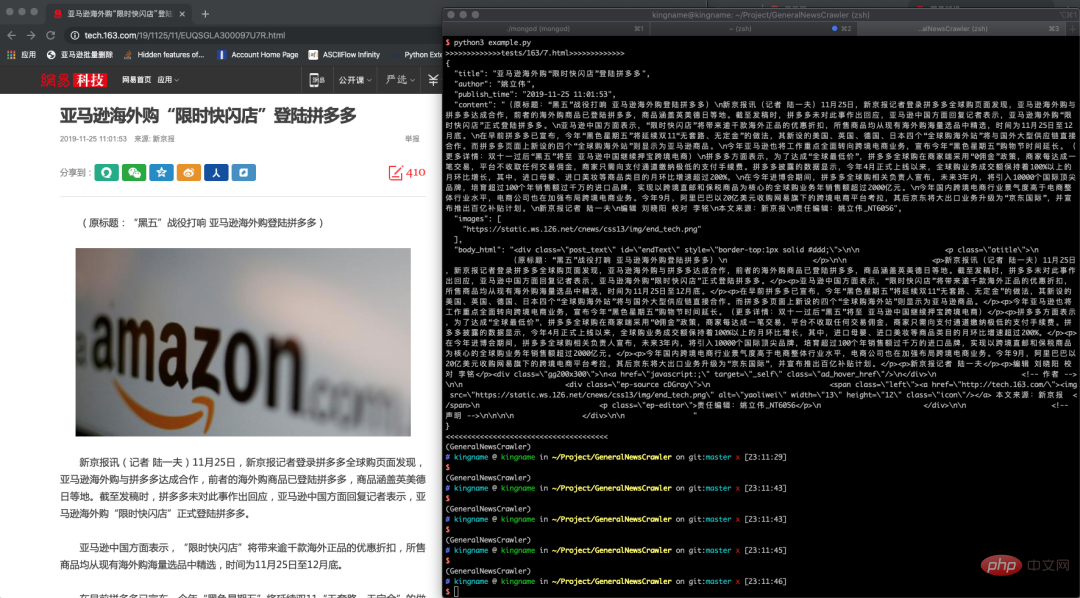
GeneralNewsExtractor#🎜 🎜#Ce projet est basé sur l'article "Méthode d'extraction de texte de page Web basée sur la densité du texte et des symboles". L'extracteur de texte implémenté à l'aide de Python peut être utilisé pour extraire le contenu, l'auteur et le titre du texte en HTML.
>>> from gne import GeneralNewsExtractor >>> html = '''经过渲染的网页 HTML 代码''' >>> extractor = GeneralNewsExtractor() >>> result = extractor.extract(html, noise_node_list=['//div[@]']) >>> print(result)
Sortie :
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}Exemple d'extraction de page d'actualité
Crawler est également une direction d'application majeure du langage Python, et de nombreux amis commencent également avec les robots d'exploration. Jetons un coup d'œil à quelques excellents projets de robots
playwright-python
L'outil d'automatisation de navigateur open source de Microsoft peut faire fonctionner le navigateur en utilisant le langage Python. Prend en charge les navigateurs Chromium, Firefox et WebKit sous les systèmes Linux, macOS et Windows.
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = browser_type.launch()
page = browser.new_page()
page.goto('http://whatsmyuseragent.org/')
page.screenshot(path=f'example-{browser_type.name}.png')
browser.close()https://github.com/microsoft/playwright-python
awesome-python-login-model# 🎜🎜#Ce projet collecte les méthodes de connexion des principaux sites Web et les programmes d'exploration de certains sites Web. Les méthodes de connexion incluent la connexion au sélénium, la connexion directe simulée via la capture de paquets, etc. Aide les novices à rechercher et à rédiger des robots d'exploration. Cependant, comme nous le savons tous, les robots d'exploration sont très exigeants pour la post-maintenance. Le projet n'a pas été mis à jour depuis longtemps, des doutes subsistent donc quant à savoir si les différentes interfaces de connexion peuvent encore être utilisées normalement. . Chacun choisit de les utiliser, ou de recommencer par lui-même.
 https://github.com/Kr1s77/awesome-python-login-model
https://github.com/Kr1s77/awesome-python-login-model
# 🎜🎜#DecryptLogin
Par rapport au précédent, ce projet est toujours en cours de mise à jour. Il simule également la connexion aux principaux sites Web, et il est toujours très précieux pour les novices.from DecryptLogin import login # the instanced Login class object lg = login.Login() # use the provided api function to login in the target website (e.g., twitter) infos_return, session = lg.twitter(username='Your Username', password='Your Password')https://github.com/CharlesPikachu/DecryptLogin
Scylla
Scylla est une haute- fin Outil de pool IP proxy gratuit de qualité, ne prend actuellement en charge que Python 3.6.http://localhost:8899/api/v1/stats
Sortie :
{
"median": 181.2566407083,
"valid_count": 1780,
"total_count": 9528,
"mean": 174.3290085201
}https://github.com/scylladb/scylladb
ProxyPool#🎜 🎜#
La fonction principale du projet de pool IP de proxy d'exploration est de collecter régulièrement des proxys gratuits publiés en ligne pour vérification et de les mettre dans la base de données. Les proxys qui sont régulièrement vérifiés et mis dans la base de données garantissent la disponibilité des agents. . Il propose deux façons d’utiliser l’API et la CLI. Dans le même temps, la source proxy peut également être étendue pour augmenter la qualité et la quantité des adresses IP du pool de proxy. Le document de conception du projet est détaillé et la structure du module est concise et facile à comprendre. Il convient également aux robots d'exploration novices pour mieux apprendre la technologie des robots.
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
# your spider code
def getHtml():
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)})
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy)
return Nonehttps://github.com/Python3WebSpider/ProxyPool
getproxygetproxy est à saisir programme qui distribue des sites Web proxy et obtient les données de mise à jour du proxy http/https toutes les 15 minutes.
(test2.7) ➜~ getproxy INFO:getproxy.getproxy:[*] Init INFO:getproxy.getproxy:[*] Current Ip Address: 1.1.1.1 INFO:getproxy.getproxy:[*] Load input proxies INFO:getproxy.getproxy:[*] Validate input proxies INFO:getproxy.getproxy:[*] Load plugins INFO:getproxy.getproxy:[*] Grab proxies INFO:getproxy.getproxy:[*] Validate web proxies INFO:getproxy.getproxy:[*] Check 6666 proxies, Got 666 valid proxies ...
https://github.com/fate0/getproxy
freeproxyest aussi à saisir A projet de proxy gratuit qui prend en charge l'exploration de nombreux sites Web proxy et est facile à utiliser.
from freeproxy import freeproxy
proxy_sources = ['proxylistplus', 'kuaidaili']
fp_client = freeproxy.FreeProxy(proxy_sources=proxy_sources)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response = fp_client.get('https://space.bilibili.com/406756145', headers=headers)
print(response.text)https://github.com/CharlesPikachu/freeproxy
fake-useragentFake identité de navigateur , souvent utilisé dans les robots d'exploration. Le code de ce projet est très petit, vous pouvez le lire pour voir comment ua.random renvoie une identité de navigateur aléatoire.
from fake_useragent import UserAgent ua = UserAgent() ua.ie # Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US); ua.msie # Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)' ua['Internet Explorer'] # Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US) ua.opera # Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11 ua.chrome # Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2' ua.google # Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13 ua['google chrome'] # Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11 ua.firefox # Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1 ua.ff # Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1 ua.safari # Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25 # and the best one, get a random browser user-agent string ua.random
https://github.com/fake-useragent/fake-useragent
Web liéIl existe trop de bibliothèques excellentes et bien établies dans Python Web, telles que Django et Flask, je ne les mentionnerai pas car tout le monde les connaît. Présentons-en quelques-unes de niche mais utiles.
streamlitstreamlit est un framework Python qui peut rapidement transformer les données en pages visuelles et interactives. Transformez nos données en graphiques en quelques minutes.import streamlit as st
x = st.slider('Select a value')
st.write(x, 'squared is', x * x)Sortie :
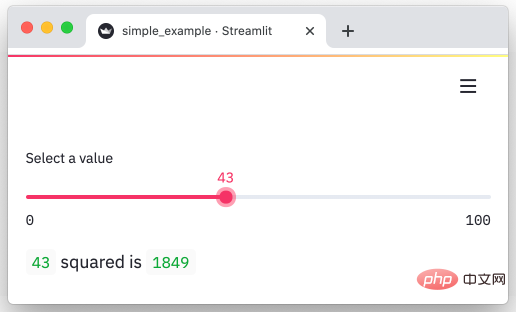
https://github.com/streamlit/streamlit
wagtail
是一个强大的开源 Django CMS(内容管理系统)。首先该项目更新、迭代活跃,其次项目首页提到的功能都是免费的,没有付费解锁的骚操作。专注于内容管理,不束缚前端实现。
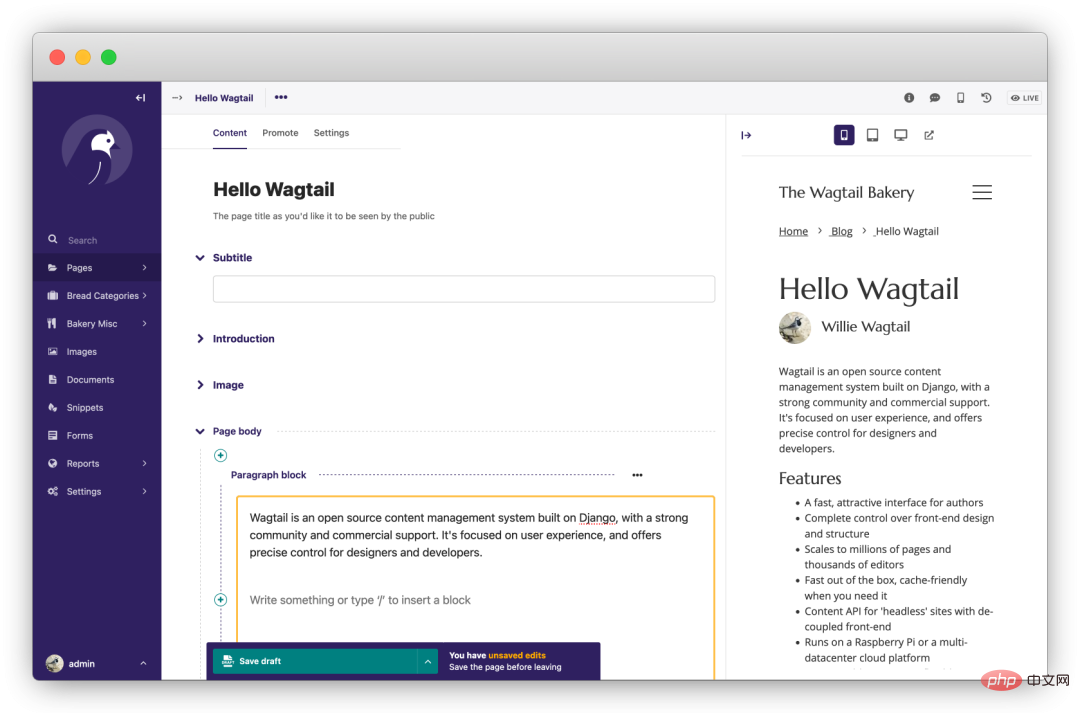
https://github.com/wagtail/wagtail
fastapi
基于 Python 3.6+ 的高性能 Web 框架。“人如其名”用 FastAPI 写接口那叫一个快、调试方便,Python 在进步而它基于这些进步,让 Web 开发变得更快、更强。
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
https://github.com/tiangolo/fastapi
django-blog-tutorial
这是一个 Django 使用教程,该项目一步步带我们使用 Django 从零开发一个个人博客系统,在实践的同时掌握 Django 的开发技巧。
https://github.com/jukanntenn/django-blog-tutorial
dash
dash 是一个专门为机器学习而来的 Web 框架,通过该框架可以快速搭建一个机器学习 APP。
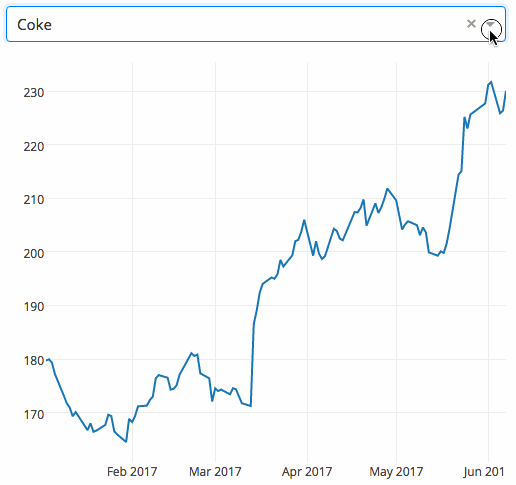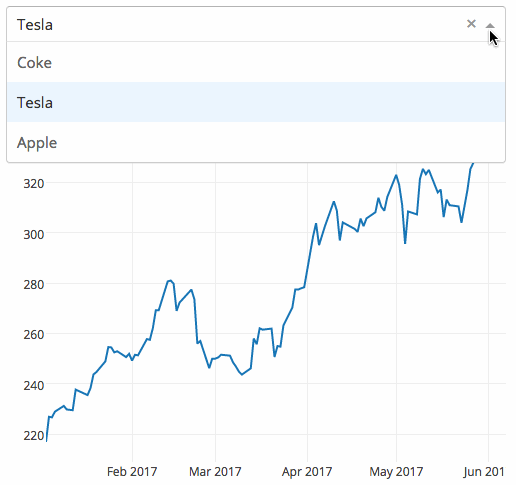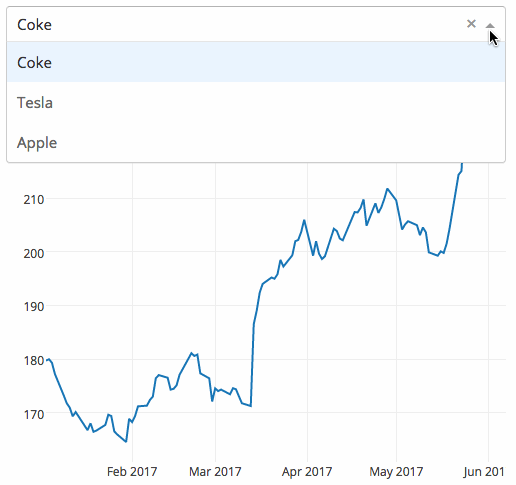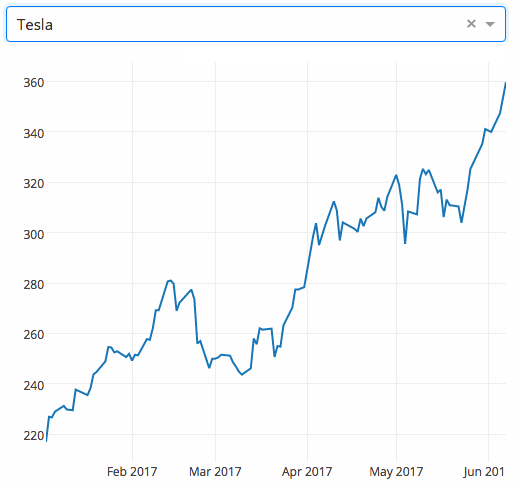
https://github.com/plotly/dash
PyWebIO
同样是一个非常优秀的 Python Web 框架,在不需要编写前端代码的情况下就可以完成整个 Web 页面的搭建,实在是方便。
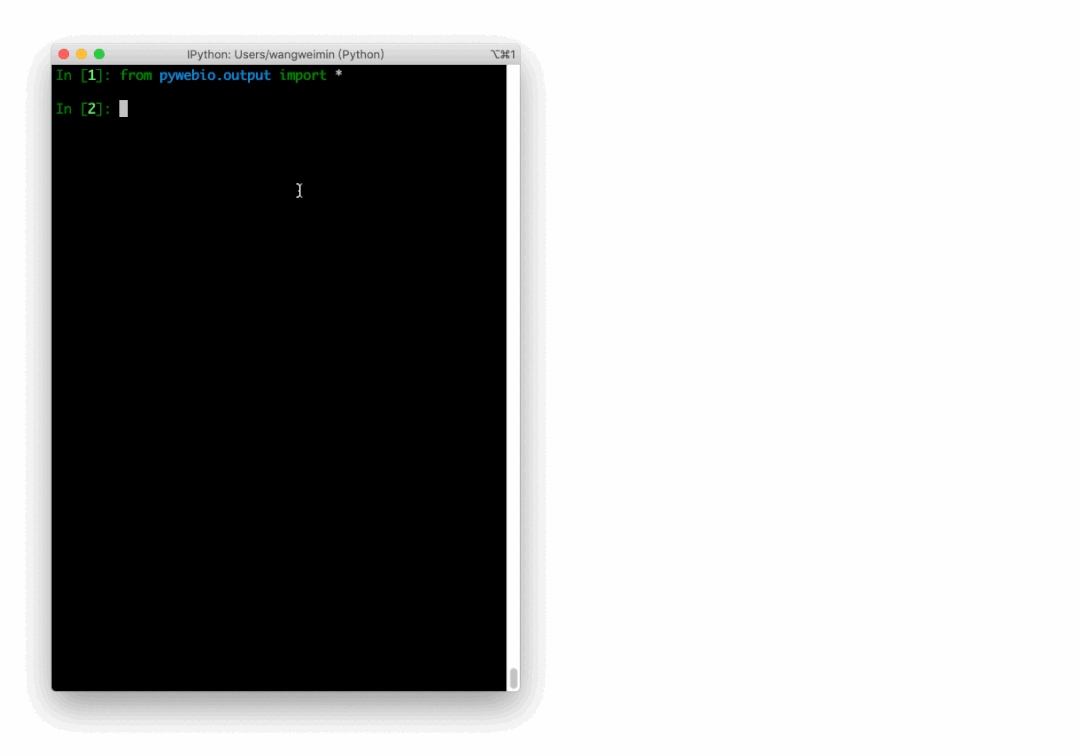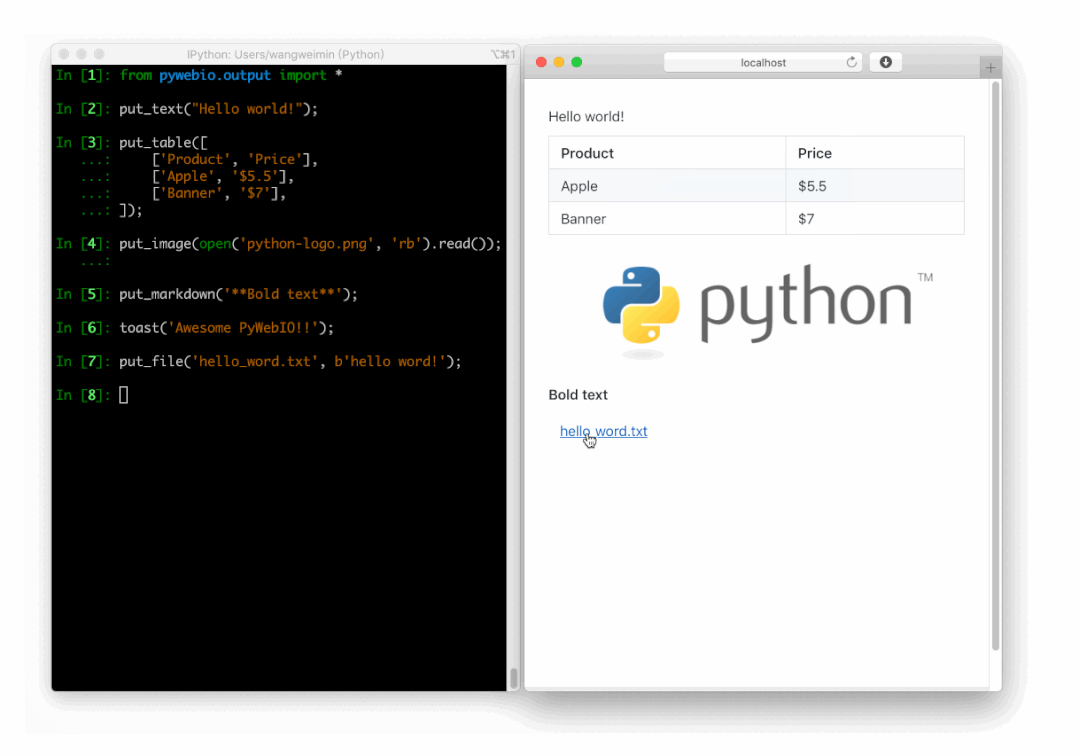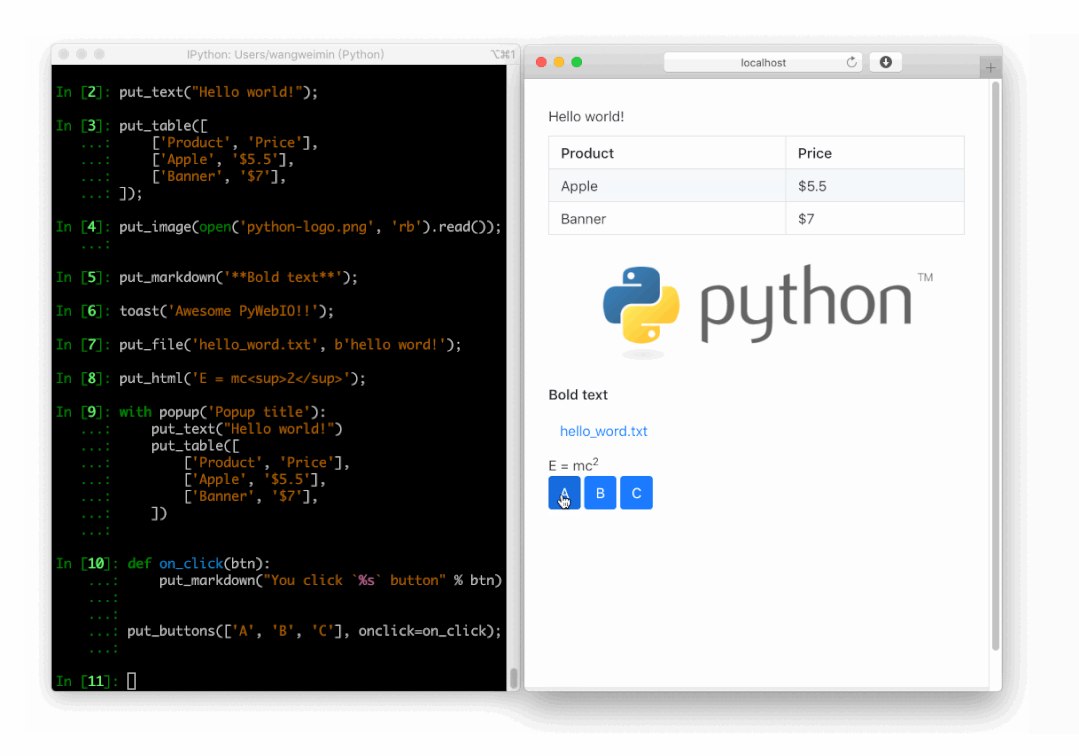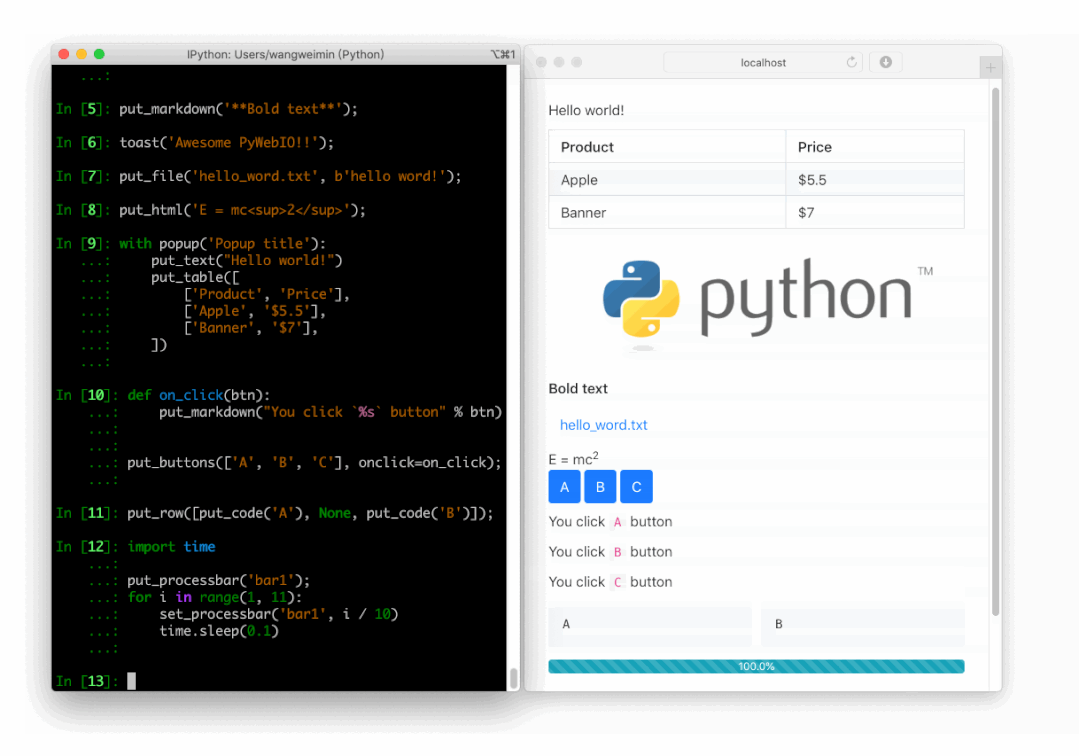
https://github.com/pywebio/PyWebIO
Python 教程
practical-python
一个人气超高的 Python 学习资源项目,是 MarkDown 格式的教程,非常友好。
https://github.com/dabeaz-course/practical-python
learn-python3
一个 Python3 的教程,该教程采用 Jupyter notebooks 形式,便于运行和阅读。并且还包含了练习题,对新手友好。
https://github.com/jerry-git/learn-python3
python-guide
Requests 库的作者——kennethreitz,写的 Python 入门教程。不单单是语法层面的,涵盖项目结构、代码风格,进阶、工具等方方面面。一起在教程中领略大神的风采吧~
https://github.com/realpython/python-guide
其他
pytools
这是一位大神编写的类似工具集的项目,里面包含了众多有趣的小工具。
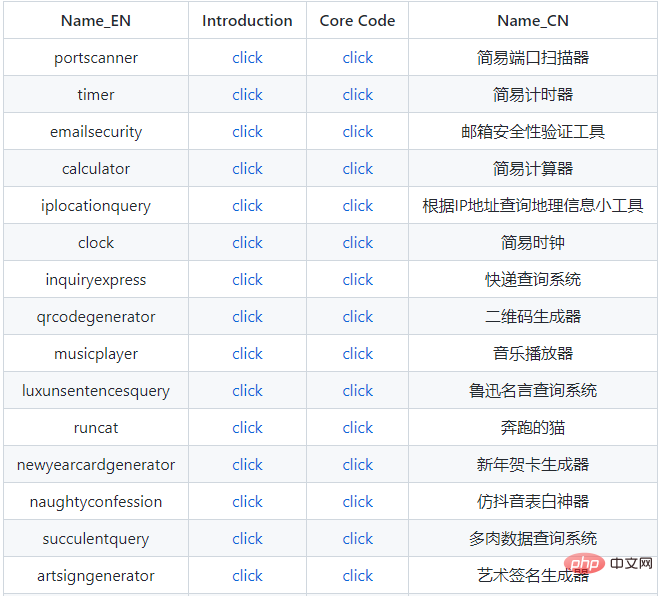
截图只是冰山一角,全貌需要大家自行探索了
import random from pytools import pytools tool_client = pytools.pytools() all_supports = tool_client.getallsupported() tool_client.execute(random.choice(list(all_supports.values())))
https://github.com/CharlesPikachu/pytools
amazing-qr
可以生成动态、彩色、各式各样的二维码,真是个有趣的库。
#3 -n, -d amzqr https://github.com -n github_qr.jpg -d .../paths/
https://github.com/x-hw/amazing-qr
sh
sh 是一个成熟的,用于替代 subprocess 的库,它允许我们调用任何程序,看起来它就是一个函数一样。
$> ./run.sh FunctionalTests.test_unicode_arg
https://github.com/amoffat/sh
tqdm
强大、快速、易扩展的 Python 进度条库。
from tqdm import tqdm for i in tqdm(range(10000)): ...
https://github.com/tqdm/tqdm
loguru
一个让 Python 记录日志变得简单的库。
from loguru import logger
logger.debug("That's it, beautiful and simple logging!")
https://github.com/Delgan/loguru
click
Python 的第三方库,用于快速创建命令行。支持装饰器方式调用、多种参数类型、自动生成帮助信息等。
import click
@click.command()
@click.option("--count", default=1, help="Number of greetings.")
@click.option("--name", prompt="Your name", help="The person to greet.")
def hello(count, name):
"""Simple program that greets NAME for a total of COUNT times."""
for _ in range(count):
click.echo(f"Hello, {name}!")
if __name__ == '__main__':
hello()Output:
$ python hello.py --count=3 Your name: Click Hello, Click! Hello, Click! Hello, Click!
KeymouseGo
Python 实现的精简绿色版按键精灵,记录用户的鼠标、键盘操作,自动执行之前记录的操作,可设定执行的次数。在进行某些简单、单调重复的操作时,使用该软件可以十分省事儿。只需要录制一遍,剩下的交给 KeymouseGo 来做就可以了。
https://github.com/taojy123/KeymouseGo
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!