
Maison >Périphériques technologiques >IA >Pas besoin d'écrire de code, le modèle BabyGPT le plus simple peut être réalisé à la main : le nouveau travail de l'ancien directeur de Tesla AI
Pas besoin d'écrire de code, le modèle BabyGPT le plus simple peut être réalisé à la main : le nouveau travail de l'ancien directeur de Tesla AI

- 王林avant
- 2023-04-27 20:25:051025parcourir
Nous savons que la série GPT d'OpenAI a ouvert une nouvelle ère d'intelligence artificielle grâce à des méthodes de pré-formation à grande échelle. Cependant, pour la plupart des chercheurs, les grands modèles de langage (LLM) sont trop coûteux en raison de leur volume et de leurs besoins en puissance de calcul. Inaccessible. Alors que la technologie évolue, les gens explorent également le modèle GPT « le plus simple ».
Récemment, Andrej Karpathy, l'ancien directeur de l'IA de Tesla et qui vient de revenir chez OpenAI, a présenté une manière plus simple de jouer à GPT, qui pourrait aider davantage de personnes à comprendre la technologie derrière ce modèle d'IA populaire.
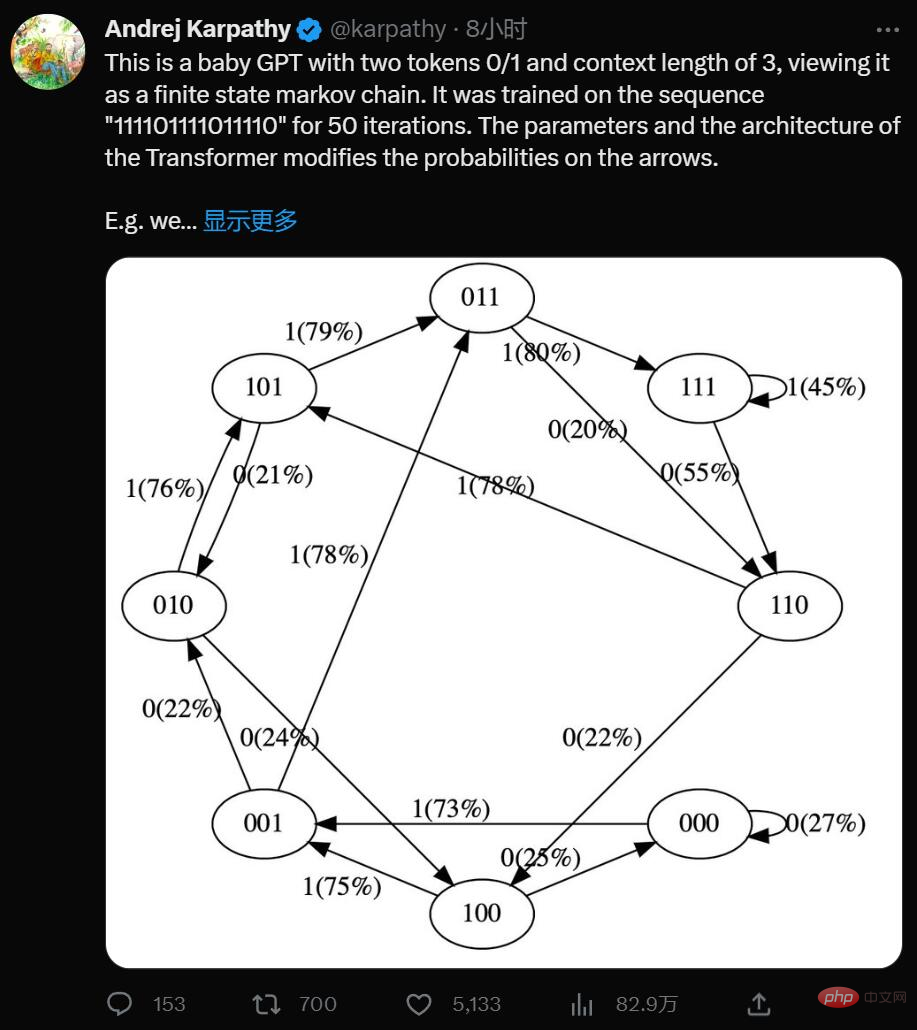
Oui, il s'agit d'un GPT minimaliste avec deux jetons 0/1 et une longueur de contexte de 3, considérez-le comme une chaîne de Markov à états finis. Il est entraîné sur la séquence "111101111011110" pendant 50 itérations, et les paramètres et l'architecture du Transformateur modifient les probabilités sur les flèches.
Par exemple, nous pouvons voir :
- Dans les données d'entraînement, l'état 101 passe de manière déterministe à 011, donc la probabilité de cette transition devient plus élevée (79 %). Mais pas proche de 100 %, car seules 50 étapes d’optimisation ont été effectuées ici.
- L'état 111 passe respectivement à 111 et 110 avec une probabilité de 50 %, ce que le modèle a presque appris (45 %, 55 %).
- Jamais rencontré un état comme 000 pendant l'entraînement, mais a une probabilité de transition relativement forte, comme 73% allant à 001. Ceci est le résultat de la polarisation inductive du transformateur. Vous pensez peut-être que cela représente 50 %, sauf que dans les déploiements réels, presque chaque séquence d'entrée est unique et n'apparaît pas littéralement dans les données d'entraînement.
Grâce à la simplification, Karpathy a rendu les modèles GPT faciles à visualiser, vous permettant de comprendre intuitivement l'ensemble du système.
Vous pouvez l'essayer ici : https://colab.research.google.com/drive/1SiF0KZJp75rUeetKOWqpsA8clmHP6jMg?usp=sharing
En fait, même la version initiale de GPT, le volume du modèle Assez impressionnant : en 2018, OpenAI a publié le modèle GPT de première génération. Dans l'article "Improving Language Understanding by Generative Pre-Training", nous pouvons apprendre qu'il utilise une structure Transformer Decoder à 12 couches et utilise environ 5 Go de données texte non supervisées. . Effectuer une formation.
Mais si vous simplifiez son concept, GPT est un réseau neuronal qui prend des séquences de jetons discrètes et prédit la probabilité du prochain jeton dans la séquence. Par exemple, s'il n'y a que deux marqueurs 0 et 1, alors un petit GPT binaire peut nous dire par exemple :
[0,1,0] ---> GPT ---> [P (0) = 20%, P (1) = 80%]
Ici, le GPT prend la séquence de bits [0,1,0] et en fonction du paramètre courant paramètres, la probabilité de prédire que le prochain sera 1 est de 80 %. Il est important de noter que la longueur du contexte de GPT est limitée par défaut. Si la longueur du contexte est de 3, ils ne peuvent utiliser que jusqu'à 3 jetons en entrée. Dans l'exemple ci-dessus, si nous lançons une pièce biaisée et échantillonnons 1 qui devrait effectivement être le suivant, nous passerons de l'état d'origine [0,1,0] au nouvel état [1,0,1]. Nous avons ajouté un nouveau bit à droite (1) et tronqué la séquence à la longueur de contexte 3 en supprimant le bit le plus à gauche (0), et ce processus peut ensuite être répété encore et encore pour passer d'un état à l'autre.
Évidemment, GPT est une chaîne de Markov à états finis : il existe un ensemble fini d'états et des flèches de transition probabilistes entre eux. Chaque état est défini par un paramètre spécifique de jetons à l'entrée GPT (par exemple [0,1,0]). Nous pouvons le faire passer à un nouvel état avec une certaine probabilité, telle que [1,0,1]. Voyons comment cela fonctionne en détail :
# hyperparameters for our GPT # vocab size is 2, so we only have two possible tokens: 0,1 vocab_size = 2 # context length is 3, so we take 3 bits to predict the next bit probability context_length = 3
L'entrée du réseau neuronal GPT est une séquence de jetons de longueur context_length. Ces jetons sont discrets, donc l'espace d'état est simple :
print ('state space (for this exercise) = ', vocab_size ** context_length)
# state space (for this exercise) = 8Détails : Pour être précis, GPT peut prendre n'importe quel nombre de jetons de 1 à context_length. Donc, si la longueur du contexte est de 3, nous pourrions en principe saisir 1, 2 ou 3 jetons tout en essayant de prédire le prochain jeton. Nous ignorons cela ici et supposons que la longueur du contexte est « maximisée » juste pour simplifier une partie du code ci-dessous, mais cela vaut la peine de le garder à l'esprit.
print ('actual state space (in reality) = ', sum (vocab_size ** i for i in range (1, context_length+1)))
# actual state space (in reality) = 14我们现在要在 PyTorch 中定义一个 GPT。出于本笔记本的目的,你无需理解任何此代码。
现在让我们构建 GPT 吧:
config = GPTConfig ( block_size = context_length, vocab_size = vocab_size, n_layer = 4, n_head = 4, n_embd = 16, bias = False, ) gpt = GPT (config)
对于这个笔记本你不必担心 n_layer、n_head、n_embd、bias,这些只是实现 GPT 的 Transformer 神经网络的一些超参数。
GPT 的参数(12656 个)是随机初始化的,它们参数化了状态之间的转移概率。如果你平滑地更改这些参数,就会平滑地影响状态之间的转换概率。
现在让我们试一试随机初始化的 GPT。让我们获取上下文长度为 3 的小型二进制 GPT 的所有可能输入:
def all_possible (n, k): # return all possible lists of k elements, each in range of [0,n) if k == 0: yield [] else: for i in range (n): for c in all_possible (n, k - 1): yield [i] + c list (all_possible (vocab_size, context_length))
[[0, 0, 0], [0, 0, 1], [0, 1, 0], [0, 1, 1], [1, 0, 0], [1, 0, 1], [1, 1, 0], [1, 1, 1]]
这是 GPT 可能处于的 8 种可能状态。让我们对这些可能的标记序列中的每一个运行 GPT,并获取序列中下一个标记的概率,并绘制为可视化程度比较高的图形:
# we'll use graphviz for pretty plotting the current state of the GPT
from graphviz import Digraph
def plot_model ():
dot = Digraph (comment='Baby GPT', engine='circo')
for xi in all_possible (gpt.config.vocab_size, gpt.config.block_size):
# forward the GPT and get probabilities for next token
x = torch.tensor (xi, dtype=torch.long)[None, ...] # turn the list into a torch tensor and add a batch dimension
logits = gpt (x) # forward the gpt neural net
probs = nn.functional.softmax (logits, dim=-1) # get the probabilities
y = probs [0].tolist () # remove the batch dimension and unpack the tensor into simple list
print (f"input {xi} ---> {y}")
# also build up the transition graph for plotting later
current_node_signature = "".join (str (d) for d in xi)
dot.node (current_node_signature)
for t in range (gpt.config.vocab_size):
next_node = xi [1:] + [t] # crop the context and append the next character
next_node_signature = "".join (str (d) for d in next_node)
p = y [t]
label=f"{t}({p*100:.0f}%)"
dot.edge (current_node_signature, next_node_signature, label=label)
return dot
plot_model ()input [0, 0, 0] ---> [0.4963349997997284, 0.5036649107933044] input [0, 0, 1] ---> [0.4515703618526459, 0.5484296679496765] input [0, 1, 0] ---> [0.49648362398147583, 0.5035163760185242] input [0, 1, 1] ---> [0.45181113481521606, 0.5481888651847839] input [1, 0, 0] ---> [0.4961162209510803, 0.5038837194442749] input [1, 0, 1] ---> [0.4517717957496643, 0.5482282042503357] input [1, 1, 0] ---> [0.4962802827358246, 0.5037197470664978] input [1, 1, 1] ---> [0.4520467519760132, 0.5479532480239868]
我们看到了 8 个状态,以及连接它们的概率箭头。因为有 2 个可能的标记,所以每个节点有 2 个可能的箭头。请注意,在初始化时,这些概率中的大多数都是统一的(在本例中为 50%),这很好而且很理想,因为我们甚至根本没有训练模型。
下面开始训练:
# let's train our baby GPT on this sequence seq = list (map (int, "111101111011110")) seq
[1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0]
# convert the sequence to a tensor holding all the individual examples in that sequence
X, Y = [], []
# iterate over the sequence and grab every consecutive 3 bits
# the correct label for what's next is the next bit at each position
for i in range (len (seq) - context_length):
X.append (seq [i:i+context_length])
Y.append (seq [i+context_length])
print (f"example {i+1:2d}: {X [-1]} --> {Y [-1]}")
X = torch.tensor (X, dtype=torch.long)
Y = torch.tensor (Y, dtype=torch.long)
print (X.shape, Y.shape)我们可以看到在那个序列中有 12 个示例。现在让我们训练它:
# init a GPT and the optimizer torch.manual_seed (1337) gpt = GPT (config) optimizer = torch.optim.AdamW (gpt.parameters (), lr=1e-3, weight_decay=1e-1)
# train the GPT for some number of iterations for i in range (50): logits = gpt (X) loss = F.cross_entropy (logits, Y) loss.backward () optimizer.step () optimizer.zero_grad () print (i, loss.item ())
print ("Training data sequence, as a reminder:", seq)
plot_model ()我们没有得到这些箭头的准确 100% 或 50% 的概率,因为网络没有经过充分训练,但如果继续训练,你会期望接近。
请注意一些其他有趣的事情:一些从未出现在训练数据中的状态(例如 000 或 100)对于接下来应该出现的 token 有很大的概率。如果在训练期间从未遇到过这些状态,它们的出站箭头不应该是 50% 左右吗?这看起来是个错误,但实际上是可取的,因为在部署期间的真实应用场景中,几乎每个 GPT 的测试输入都是训练期间从未见过的输入。我们依靠 GPT 的内部结构(及其「归纳偏差」)来适当地执行泛化。
大小比较:
- GPT-2 有 50257 个 token 和 2048 个 token 的上下文长度。所以 `log2 (50,257) * 2048 = 每个状态 31,984 位 = 3,998 kB。这足以实现量变。
- GPT-3 的上下文长度为 4096,因此需要 8kB 的内存;大约相当于 Atari 800。
- GPT-4 最多 32K 个 token,所以大约 64kB,即 Commodore64。
- I/O 设备:一旦开始包含连接到外部世界的输入设备,所有有限状态机分析就会崩溃。在 GPT 领域,这将是任何一种外部工具的使用,例如必应搜索能够运行检索查询以获取外部信息并将其合并为输入。
Andrej Karpathy 是 OpenAI 的创始成员和研究科学家。但在 OpenAI 成立一年多后,Karpathy 便接受了马斯克的邀请,加入了特斯拉。在特斯拉工作的五年里,他一手促成了 Autopilot 的开发。这项技术对于特斯拉的完全自动驾驶系统 FSD 至关重要,也是马斯克针对 Model S、Cybertruck 等车型的卖点之一。
今年 2 月,在 ChatGPT 火热的背景下,Karpathy 回归 OpenAI,立志构建现实世界的 JARVIS 系统。

最近一段时间,Karpathy 给大家贡献了很多学习材料,包括详解反向传播的课程 、重写的 minGPT 库、从零开始构建 GPT 模型的完整教程等。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI