
Maison >Périphériques technologiques >IA >Google a étendu les paramètres du modèle de transfert visuel à 22 milliards et les chercheurs ont pris des mesures collectives depuis que ChatGPT est devenu populaire
Google a étendu les paramètres du modèle de transfert visuel à 22 milliards et les chercheurs ont pris des mesures collectives depuis que ChatGPT est devenu populaire

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-27 11:31:071310parcourir
Semblable au traitement du langage naturel, le transfert de structures visuelles pré-entraînées améliore les performances du modèle sur diverses tâches visuelles. Des ensembles de données plus volumineux, des architectures évolutives et de nouvelles méthodes de formation ont tous entraîné des améliorations des performances des modèles.
Cependant, les modèles visuels sont encore loin derrière les modèles linguistiques. Plus précisément, ViT, le plus grand modèle de vision à ce jour, n'a que 4B de paramètres, tandis que les modèles de langage d'entrée de gamme dépassent souvent les 10B de paramètres, sans parler des grands modèles de langage avec 540B de paramètres.
Afin d'explorer les limites de performances des modèles d'IA, Google Research a récemment mené une étude dans le domaine CV, prenant les devants en élargissant la taille du paramètre Vision Transformer à 22B, et a proposé ViT-22B par rapport au précédent similaire. taille des paramètres du modèle de 4B, on dit qu'il s'agit du plus grand modèle ViT dense à ce jour.

Adresse papier : https://arxiv.org/pdf/2302.05442.pdf
En comparant les plus grands ViT-G et ViT-e précédents, le tableau 1 donne les résultats de la comparaison, comme le montre le tableau ci-dessous, le ViT-22B élargit principalement la largeur du modèle, augmentant ainsi le nombre de paramètres, et la profondeur est la même que celle du ViT-G.
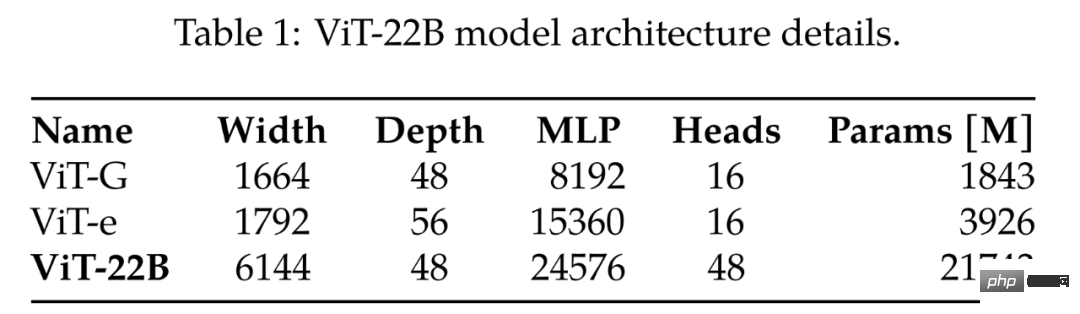
Le grand modèle ViT actuel
Comme l'a dit cet internaute de Zhihu, est-ce parce que Google a perdu une manche sur ChatGPT et est voué à rivaliser dans le domaine des CV ?

Comment faire ? Il s’est avéré qu’au début de la recherche, ils ont découvert qu’une instabilité de la formation se produisait lors de l’expansion de ViT, ce qui pourrait conduire à des changements architecturaux. Les chercheurs ont ensuite soigneusement conçu le modèle et l’ont entraîné en parallèle avec une efficacité sans précédent. La qualité du ViT-22B a été évaluée à travers un ensemble complet de tâches, depuis la classification (en quelques tirs) jusqu'aux tâches de sortie denses, où il a atteint ou dépassé les niveaux SOTA actuels. Par exemple, ViT-22B a atteint une précision de 89,5 % sur ImageNet, même lorsqu'il est utilisé comme extracteur de caractéristiques visuelles gelées. En entraînant une tour de texte pour qu'elle corresponde à ces caractéristiques visuelles, elle atteint une précision de tir nul de 85,9 % sur ImageNet. De plus, le modèle peut être considéré comme un enseignant et utilisé comme cible de distillation. Les chercheurs ont formé un modèle étudiant ViT-B et ont atteint une précision de 88,6 % sur ImageNet, atteignant le niveau SOTA pour un modèle de cette échelle.
Architecture du modèle
ViT-22B est un modèle d'encodeur basé sur Transformer similaire à l'architecture originale de Vision Transformer, mais contient les trois modifications principales suivantes pour améliorer l'efficacité et la stabilité pour la formation à grande échelle : couche parallèle, requête/clé (QK) normalisation et biais omis.
Couche parallèle. Comme mentionné dans l'étude de Wang et Komatsuzaki, cette étude a conçu une structure parallèle Attention et MLP :
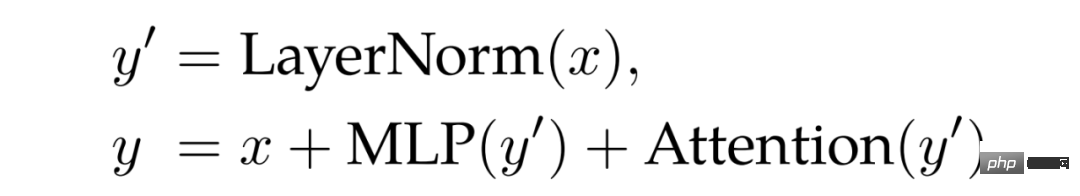
Cela peut obtenir une parallélisation supplémentaire en combinant des projections linéaires de MLP et des blocs d'attention. Notamment, la multiplication matricielle pour la projection requête/clé/valeur et la première couche linéaire de MLP sont fusionnées en une seule opération, comme c'est le cas pour la projection hors attention et la deuxième couche linéaire de MLP.
normalisation QK. L’une des difficultés liées à la formation de grands modèles réside dans la stabilité du modèle. Lors du processus d’extension de ViT, les chercheurs ont constaté que la perte de formation diverge après des milliers d’étapes. Ce phénomène est particulièrement important dans le modèle paramétrique 8B. Pour stabiliser la formation du modèle, les chercheurs ont adopté la méthode de Gilmer et al pour appliquer les opérations de normalisation LayerNorm sur les requêtes et les clés avant les calculs d'attention des produits scalaires afin d'améliorer la stabilité de la formation. Plus précisément, le poids d'attention est calculé comme suit :
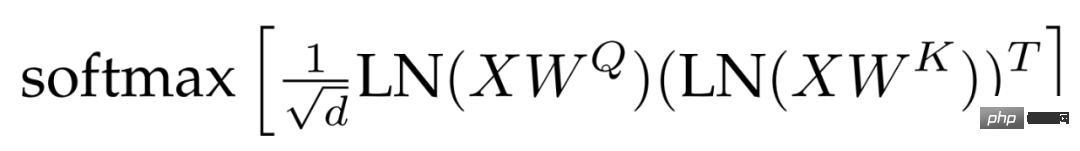
préjugés omis. Après PaLM, le terme de biais est supprimé de la projection QKV et toutes les normes de couche sont appliquées sans biais, ce qui entraîne une utilisation améliorée de l'accélérateur (3 %) sans dégradation de la qualité. Cependant, contrairement à PaLM, les chercheurs ont utilisé un terme de biais pour la couche dense MLP, et même ainsi, cette approche n'a pas compromis la vitesse tout en prenant en compte la qualité.
La figure 2 montre un bloc encodeur ViT-22B. La couche d'intégration effectue des opérations telles que l'extraction de patchs, la projection linéaire et l'intégration de positions ajoutées en fonction du ViT d'origine. Les chercheurs ont utilisé la mise en commun de l’attention de plusieurs têtes pour regrouper chaque représentation symbolique dans les têtes.

ViT-22B utilise un patch 14 × 14 et la résolution de l'image est 224 × 224. ViT-22B utilise une intégration de position unidimensionnelle apprise. Lors du réglage fin des images haute résolution, les chercheurs ont effectué une interpolation bidimensionnelle en fonction de l'endroit où se trouvaient les intégrations de positions pré-entraînées dans l'image d'origine.
Training Infrastructure & Efficiency
ViT-22B utilise la bibliothèque FLAX, implémentée en JAX, et construite dans Scenic. Il exploite à la fois le parallélisme des modèles et des données. Les chercheurs ont notamment utilisé l'API jax.xmap, qui fournit un contrôle explicite sur le partitionnement de tous les intermédiaires (tels que les poids et les activations) ainsi que sur la communication entre les puces. Les chercheurs ont organisé les puces dans une grille logique 2D de taille t × k, où t est la taille de l'axe parallèle des données et k est la taille de l'axe du modèle. Ensuite, pour chacun des t groupes, k appareils acquièrent le même lot d'images, chaque appareil ne conservant que 1/k activations et étant responsable du calcul de 1/k de toutes les sorties de couche linéaire (détails ci-dessous).
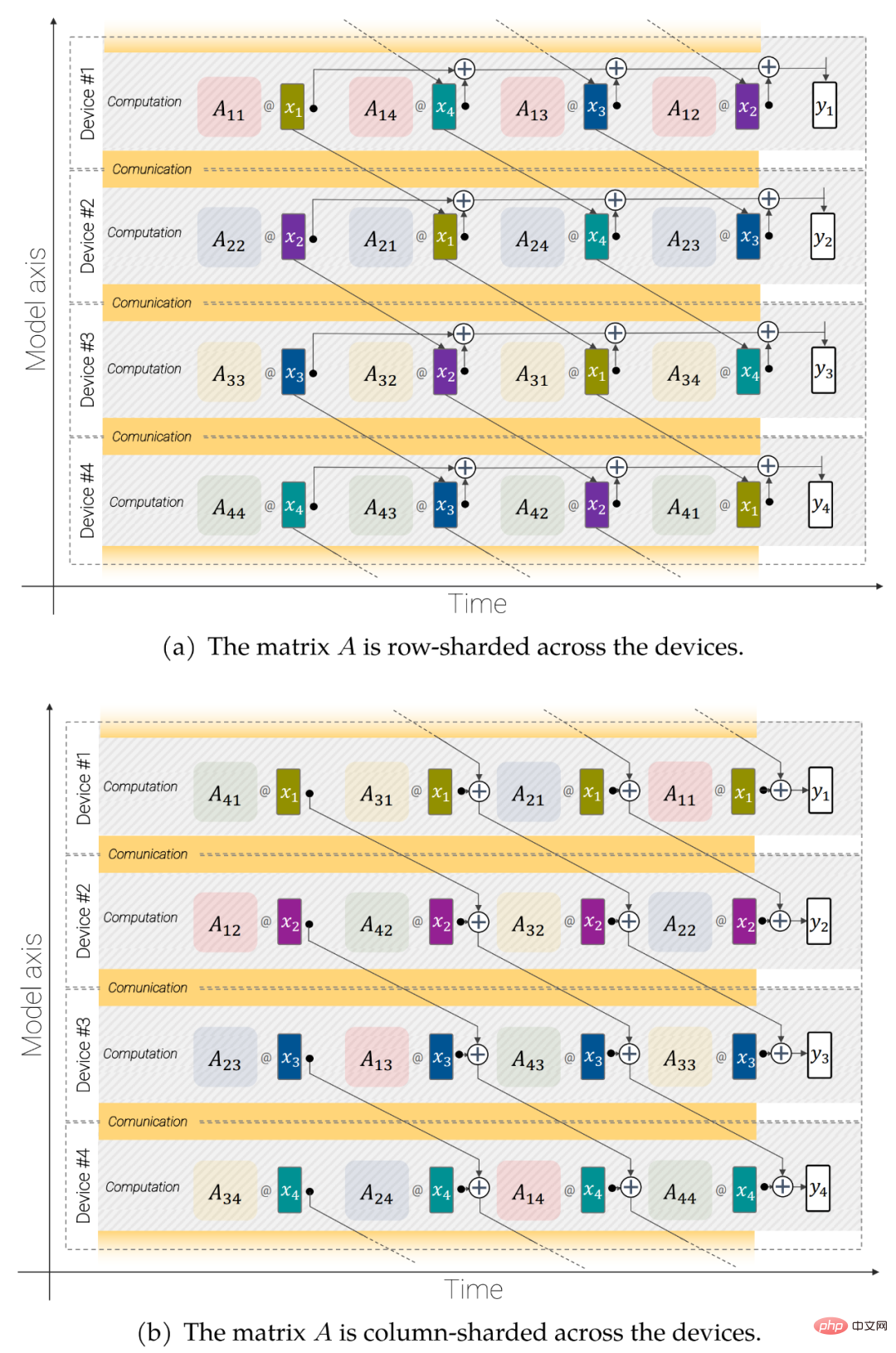
Figure 3 : Opérations linéaires parallèles asynchrones (y = Axe) : multiplication matricielle parallèle au modèle pour chevaucher la communication et le calcul entre les appareils.
Opérations linéaires parallèles asynchrones. Pour maximiser le débit, le calcul et la communication doivent être pris en compte. Autrement dit, si vous souhaitez que ces opérations soient analytiquement équivalentes au cas non fragmenté, vous devez communiquer le moins possible, en les laissant idéalement se chevaucher afin de pouvoir préserver l'unité de multiplication matricielle (où réside la majeure partie de la capacité du FLOP). toujours occupé.
Partage des paramètres. Le modèle est constitué de données parallèles sur le premier axe. Chaque paramètre peut être entièrement répliqué sur cet axe, ou chaque appareil peut être enregistré avec une partie de celui-ci. Les chercheurs ont choisi de séparer certains grands tenseurs des paramètres du modèle afin de pouvoir s'adapter à des modèles et à des tailles de lots plus grands.
En utilisant ces techniques, ViT-22B traite 1,15k jetons par seconde et par cœur lors de l'entraînement sur TPUv4. L'utilisation des échecs du modèle (MFU) du ViT-22B est de 54,9 %, ce qui indique une utilisation très efficace du matériel. Notez que PaLM rapporte un MFU de 46,2 %, tandis que les chercheurs ont mesuré un MFU de 44,0 % pour ViT-e (parallélisme des données uniquement) sur le même matériel.
Résultats expérimentaux
L'expérience a exploré les résultats de l'évaluation du ViT-22B pour la classification d'images.
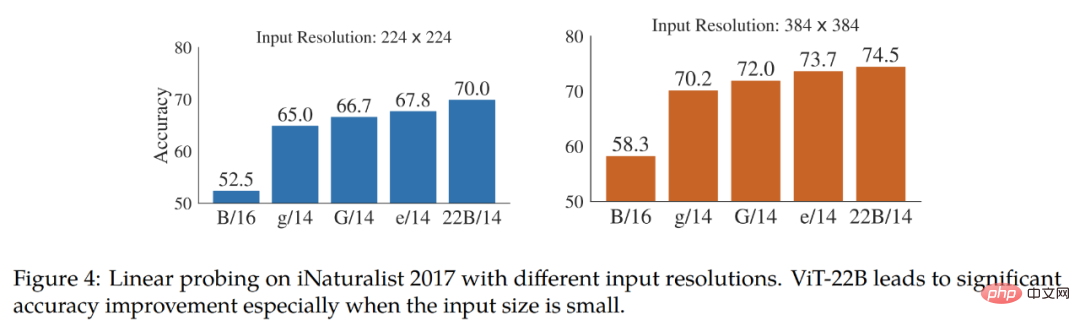
Les résultats du tableau 2 montrent que le ViT-22B présente encore des améliorations significatives dans divers indicateurs. En outre, des études ont montré que le sondage linéaire de grands modèles comme le ViT-22B peut approcher ou dépasser les performances de réglage fin des petits modèles à haute résolution, ce qui est souvent moins cher et plus facile à réaliser. L'étude teste en outre la faisabilité linéaire sur l'ensemble de données de classification à grain fin. iNaturalist 2017 Séparabilité, comparant le ViT-22B avec d'autres variantes de ViT. L'étude a testé des résolutions d'entrée de 224 px et 384 px. Les résultats sont présentés dans la figure 4. L'étude a observé que le ViT-22B surpasse considérablement les autres variantes du ViT, en particulier à la résolution d'entrée standard de 224 px. Cela montre que le grand nombre de paramètres de ViT-22B est utile pour extraire des informations détaillées à partir d’images.
Le tableau 3 montre les résultats de migration sans échantillon de ViT-22B pour les modèles CLIP, ALIGN, BASIC, CoCa et LiT. Le bas du tableau 3 compare les performances des trois modèles ViT.
ViT-22B obtient des résultats comparables ou meilleurs dans tous les ensembles de tests ImageNet. Notamment, les résultats zéro sur l'ensemble de tests ObjectNet sont fortement corrélés à la taille du modèle ViT. Le plus grand, ViT-22B, définit un nouveau SOTA sur l'ensemble de test exigeant ObjectNet.

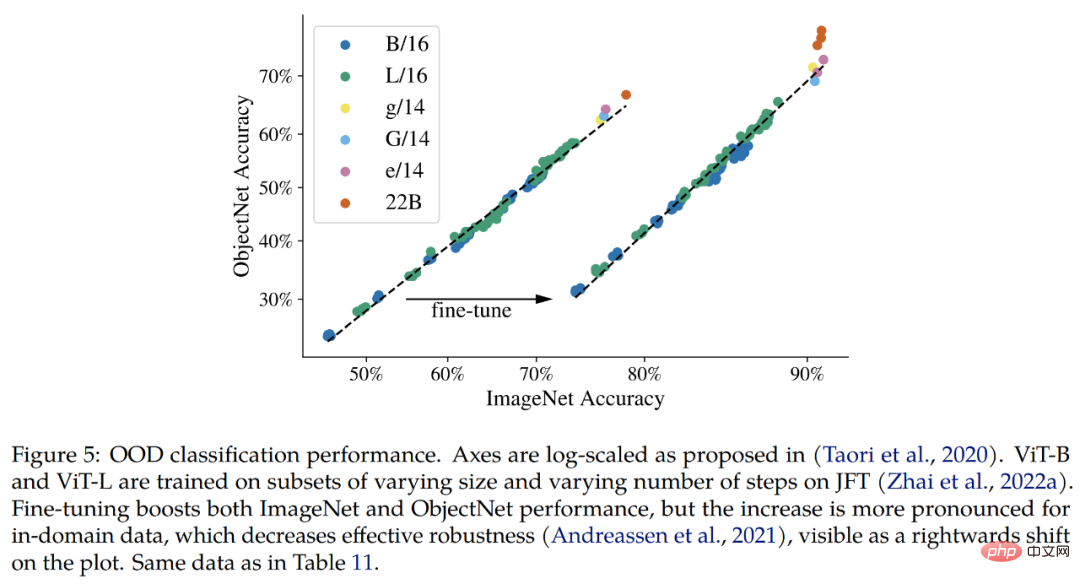
Hors distribution (OOD). L'étude construit un mappage d'étiquettes de JFT à ImageNet et d'ImageNet à différents ensembles de données hors distribution, à savoir ObjectNet, ImageNet-v2, ImageNet-R et ImageNet-A.
Les résultats qui peuvent être confirmés jusqu'à présent sont que, conformément aux améliorations apportées à ImageNet, le modèle étendu augmente les performances hors distribution. Cela fonctionne pour les modèles qui n'ont vu que des images JFT, ainsi que pour les modèles affinés sur ImageNet. Dans les deux cas, le ViT-22B poursuit la tendance vers de meilleures performances OOD sur les modèles plus grands (Fig. 5, Tableau 11).
De plus, les chercheurs ont étudié la qualité des informations géométriques et spatiales capturées par le modèle ViT-22B dans les tâches de segmentation sémantique et d'estimation de profondeur monoculaire.
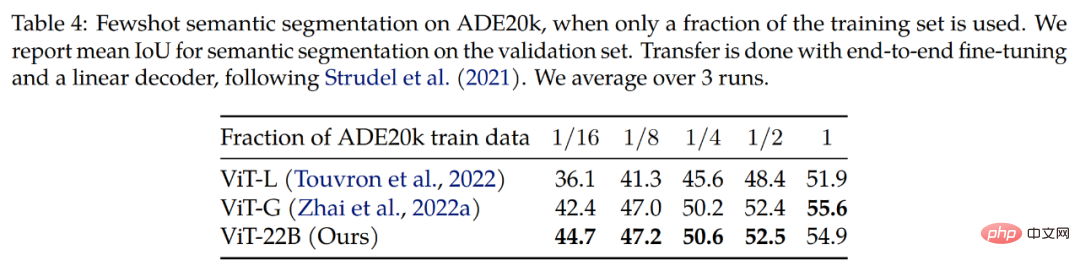
Segmentation sémantique. Les chercheurs ont évalué ViT-22B en tant qu'épine dorsale de segmentation sémantique sur trois critères : ADE20K, Pascal Context et Pascal VOC. Comme le montre le tableau 4, la migration du backbone ViT-22B fonctionne mieux lorsque seuls quelques masques de segmentation sont visibles.
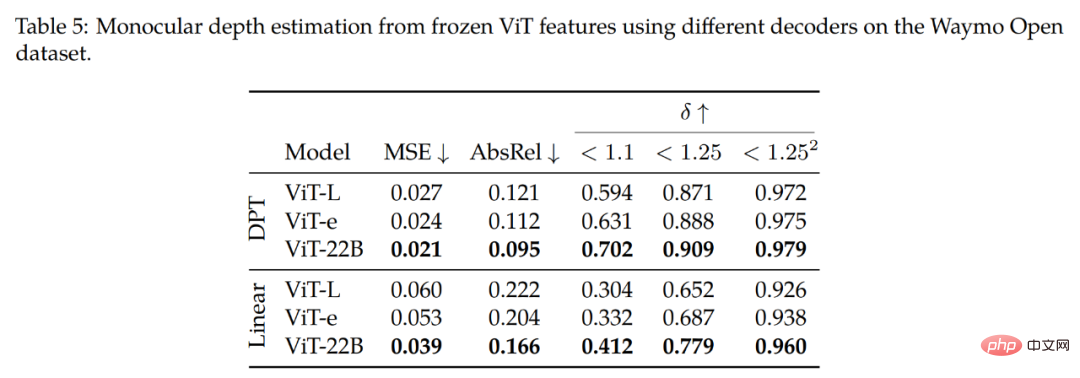
Estimation de la profondeur monoculaire. Le tableau 5 résume les principales conclusions de l'étude. Comme on peut l'observer dans la rangée supérieure (décodeur DPT), l'utilisation des fonctionnalités du ViT-22B donne les meilleures performances (sur toutes les métriques) par rapport aux différents backbones. En comparant le backbone ViT-22B au ViT-e, un modèle plus petit mais formé sur les mêmes données que le ViT-22B, nous avons constaté que l'extension de l'architecture améliore les performances.
De plus, en comparant le backbone ViT-e avec ViT-L (une architecture similaire à ViT-e mais formée sur moins de données), il a été constaté que ces améliorations proviennent également de l'extension des données de pré-entraînement. Ces résultats suggèrent que des modèles plus grands et des ensembles de données plus volumineux contribuent à améliorer les performances.
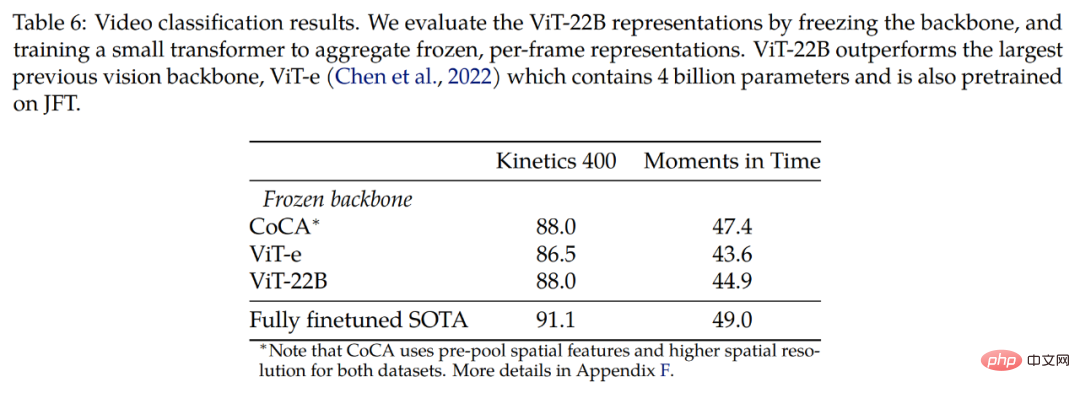
L'étude a également été explorée sur un ensemble de données vidéo. Le tableau 6 présente les résultats de la classification vidéo sur les ensembles de données Kinetics 400 et Moments in Time, démontrant que des résultats compétitifs peuvent être obtenus en utilisant des dorsales gelées. L’étude est d’abord comparée à ViT-e, qui possède le plus grand modèle de base visuelle antérieur, composé de 4 milliards de paramètres, et est également formé sur l’ensemble de données JFT. Nous avons observé que le plus grand modèle ViT-22B s'est amélioré de 1,5 point sur Kinetics 400 et de 1,3 point sur Moments in Time.
La recherche finale a révélé qu'il y avait encore place à l'amélioration avec un réglage fin complet de bout en bout.
Veuillez vous référer au document original pour plus de détails techniques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI