
Maison >Périphériques technologiques >IA >La diffusion stable peut-elle surpasser les algorithmes tels que JPEG et améliorer la compression de l'image tout en conservant la clarté ?
La diffusion stable peut-elle surpasser les algorithmes tels que JPEG et améliorer la compression de l'image tout en conservant la clarté ?

- WBOYavant
- 2023-04-27 08:28:072133parcourir
Le modèle de génération d'images basé sur du texte est très populaire. Non seulement le modèle de diffusion est populaire, mais aussi le modèle de diffusion stable open source. Récemment, un ingénieur logiciel suisse, Matthias Bühlmann, a découvert accidentellement que la diffusion stable peut non seulement être utilisée pour générer des images, mais également pour compresser des images bitmap , même avec un taux de compression plus élevé que JPEG et WebP.

L'image originale fait 768 Ko, qui est compressée à 5,66 Ko en utilisant JPEG et stable La diffusion peut davantage# 🎜🎜#Compressée à 4,98 Ko, et peut conserver plus de détails en haute résolution et
moins d'artefacts de compression, ce qui est visiblement mieux pour à l’œil nu d’autres algorithmes de compression. Cependant, cette méthode de compression présente également des défauts, c'est-à-dire que ne convient pas pour compresser le visage et des images de texte , dans certains cas, même générent des images originales sans contenu
.
Bien que recycler un auto-encodeur peut également faire quelque chose de similaire à Stable L'effet de compression de Diffusion, mais l'un des principaux avantages de l'utilisation de Stable Diffusion est que quelqu'un a investi des millions de fonds
pour vous aider à en former un, et vousPourquoi dépenser de l'argent pour vous entraîner à nouveau# 🎜🎜#Et un modèle à compression ? 
Comment Stable Diffusion compresse les imagesLes modèles de diffusion remettent en question la domination des modèles génératifs, et le modèle open source Stable Diffusion correspondant est également présent la communauté du machine learning Commencez une révolution artistique.
La diffusion stable est obtenue en concaténant trois réseaux de neurones entraînés, c'est-à-dire
un encodeur variationnel ( VAE), modèle U-Net et
un encodeur de texte. 
L'autoencodeur variationnel encode et décode l'image dans l'espace image pour obtenir l'image dans # 🎜🎜#Le vecteur de représentation de l'espace latent est représenté par une résolution inférieure (64x64) avec précision supérieure (4x32 bits)
vecteur# 🎜🎜#Image source (512x512 po 3x8 ou 4x8 bits). 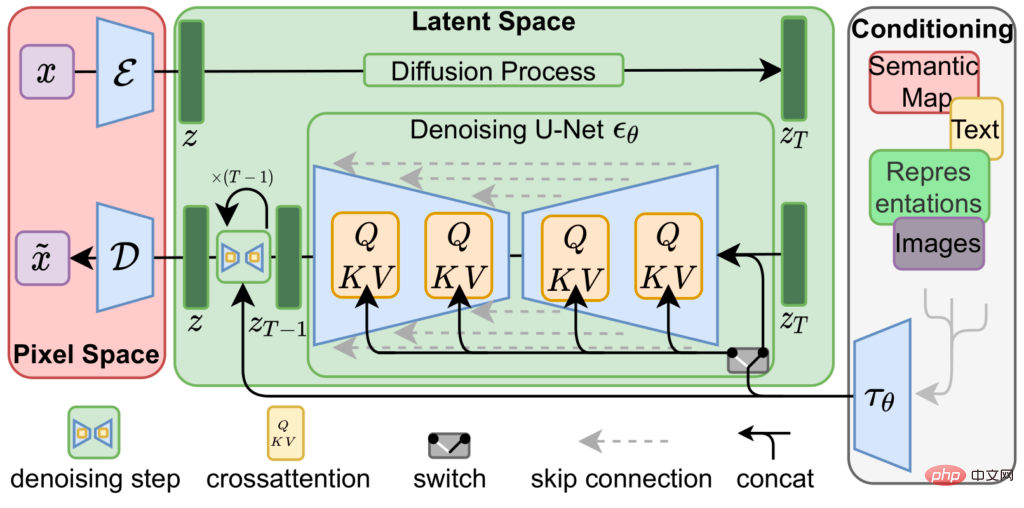
Le processus de formation de la VAE pour encoder des images dans un espace latent repose principalement sur un apprentissage auto-supervisé, c'est-à-dire que l'entrée et la sortie sont toutes deux des images sources, de sorte que le modèle est davantage formé, différent La représentation de l'espace latent peut être différente pour différentes versions du modèle. Après avoir remappé et interprété la représentation de l'espace latent en une image couleur à 4 canaux à l'aide de Stable Diffusion v1.4, elle ressemble à l'image du milieu ci-dessous, dans l'image source Les principales fonctionnalités sont toujours visibles .
Il est à noter que l'encodage aller-retour VAE une fois et
n'est pas sans perte #🎜🎜 #.Par exemple, après décodage, le ANNA nom
sur la bande bleue n'est pas aussi clair que l'image source, et la lisibilité est considérablement réduit. Les auto-encodeurs variationnels dans
Stable Diffusion v1.4 ne sont pas très bons pour représenter #🎜 🎜#Petit texte et visage images, je ne sais pas si ça sera amélioré dans la v1.5.
Le principal algorithme de compression de Stable Diffusion consiste à utiliser cette représentation spatiale latente des images pour générer de nouvelles images à partir de courtes descriptions textuelles.
Partez du bruit aléatoire représenté par l'espace latent, utilisez un U-Net entièrement entraîné pour supprimer de manière itérative le bruit de l'image de l'espace latent et utilisez une représentation plus simple pour générer la prédiction dans laquelle le modèle pense "voir" ce bruit, c'est un peu comme quand on regarde des nuages, restaure les formes ou les visages dans notre esprit à partir de formes irrégulières.
Lors de l'utilisation de Stable Diffusion pour générer des images, cette étape itérative de débruitage est guidée par un troisième composant, l'encodeur de texte, qui donne à U-Net une idée de ce qu'il devrait essayer de voir dans les informations sur le bruit.
Cependant, pour les tâches de compression, il n'est pas nécessaire d'avoir un encodeur de texte, donc le processus expérimental a uniquement créé un encodage de chaîne vide pour indiquer à U-Net d'effectuer un décodage non guidé pendant le processus de reconstruction d'image. Bruyant.
Afin d'utiliser Stable Diffusion comme codec de compression d'image, l'algorithme doit compresser efficacement la représentation latente produite par VAE.
On peut constater dans des expériences que le sous-échantillonnage de la représentation latente ou l'utilisation directe des méthodes de compression d'image avec perte existantes réduiront considérablement la qualité de l'image reconstruite.
Mais l'auteur a constaté que le décodage VAE semble être très efficace dans la quantification des représentations latentes.
La mise à l'échelle, le serrage et le remappage des potentiels de la virgule flottante aux entiers non signés de 8 bits ne produisent que de petites erreurs de reconstruction visibles.

En quantifiant la représentation latente de 8 bits, la taille des données représentée par l'image est désormais de 64*64*4*8 bits=16 Ko, ce qui est beaucoup plus petit que les 512*512*3*8 bits=768 Ko de l'image source non compressée
Si le nombre de représentations latentes est inférieur à 8 bits, cela ne produira pas de meilleurs résultats.
Si vous effectuez davantage de palettisation et de tramage sur l'image, l'effet de quantification s'améliorera à nouveau.
Création d'une représentation de palette utilisant la représentation latente de vecteurs 256*4*8 bits et le tramage Floyd-Steinberg, compressant davantage la taille des données à 64*64*8+256*4*8bit=5kB

Le jittering de la palette d'espace latent introduit du bruit, faussant les résultats du décodage. Cependant, étant donné que la diffusion stable est basée sur la suppression du bruit latent, U-Net peut être utilisé pour supprimer le bruit provoqué par la gigue.
Après 4 itérations, le résultat de la reconstruction est visuellement très proche de la version non quantifiée.

Bien que la quantité de données soit considérablement réduite (l'image source est 155 fois plus grande que l'image compressée), l'effet est très bon, mais certains artefacts sont également introduits (comme le motif en forme de cœur qui n'existe pas dans l'image originale) artefacts).
Fait intéressant, les artefacts introduits par ce schéma de compression ont un impact plus important sur le contenu de l'image que sur la qualité de l'image, et les images compressées de cette manière peuvent contenir ces types d'artefacts de compression.
L'auteur a également utilisé zlib pour effectuer une compression sans perte sur la palette et l'index. Dans les échantillons de test, la plupart des résultats de compression étaient moins de 5 Ko, mais cette méthode de compression a encore plus de place pour l'optimisation.
Afin d'évaluer le codec de compression, l'auteur n'a utilisé aucune image de test standard trouvée sur Internet , car les images sur Internet peuvent être apparues dans l'ensemble d'entraînement de Stable Diffusion, et la compression de ces images peut causer un avantage comparatif injuste.
Pour rendre la comparaison aussi juste que possible, l'auteur a utilisé les paramètres d'encodeur de la plus haute qualité de la bibliothèque d'images Python et a ajouté une compression de données sans perte des données JPG compressées à l'aide de la bibliothèque mozjpeg.
Il convient de noter que même si les résultats de Stable Diffusion semblent subjectivement bien meilleurs que les images compressées JPG et WebP, ils ne sont pas significativement meilleurs lorsqu'il s'agit de mesures standard comme PSNR ou SSIM. Mieux, mais pas pire.
C'est juste que les types d'artefacts introduits sont moins évidents car ils ont un impact plus important sur le contenu de l'image que sur la qualité de l'image.
Cette méthode de compression est également un peu dangereuse, bien que la qualité des fonctionnalités reconstruites soit élevée, le contenu peut être affecté par des artefacts de compression, même s'il semble très net .
Par exemple, dans une image de test, tandis que Stable Diffusion en tant que codec fait un bien meilleur travail pour maintenir la qualité de l'image, même le grain de la caméra La texture (grain de la caméra) est préservée (ce qui est difficile pour la plupart des algorithmes de compression traditionnels), mais son contenu est toujours affecté par les artefacts de compression et des fonctionnalités fines telles que les formes des bâtiments peuvent changer.

Bien sûr, il est impossible d'identifier plus de vérité dans une image compressée JPG que dans une image compressée à diffusion stable valeur, mais la haute qualité visuelle des résultats de compression à diffusion stable peut être trompeuse car les artefacts de compression dans JPG et WebP sont plus faciles à identifier.
Si vous aussi vous souhaitez reproduire l'expérience, l'auteur a open source le code sur Colab.
Lien du code : https://colab.research.google.com/drive/ 1Ci1VYHuFJK5eOX9TB0Mq4NsqkeDr MaaH ?usp=sharing
Enfin, l'auteur a déclaré que l'expérience conçue dans l'article est encore assez simple, mais l'effet est toujours surprenant,# 🎜🎜#Il y a encore beaucoup de choses à améliorer à l'avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI