
Maison >Périphériques technologiques >IA >SEEM, un modèle de segmentation universel créé par une équipe chinoise, porte la segmentation ponctuelle à un nouveau niveau
SEEM, un modèle de segmentation universel créé par une équipe chinoise, porte la segmentation ponctuelle à un nouveau niveau

- 王林avant
- 2023-04-26 22:07:071516parcourir
Au début du mois, Meta a publié le modèle d'IA « Segment Anything » - Segment Anything Model (SAM). SAM est considéré comme un modèle de base universel pour la segmentation d'images. Il apprend les concepts généraux sur les objets et peut générer des masques pour n'importe quel objet dans n'importe quelle image ou vidéo, y compris les objets et les types d'images qui n'ont pas été rencontrés au cours du processus de formation. Cette capacité de « migration sans échantillon » est étonnante, et certains disent même que le domaine CV a inauguré un « moment GPT-3 ».
Récemment, un nouveau document "Segment Everything Everywhere All at Once" a de nouveau attiré l'attention. Dans cet article, plusieurs chercheurs chinois de l’Université du Wisconsin-Madison, de Microsoft et de l’Université des sciences et technologies de Hong Kong ont proposé un nouveau modèle d’interaction basé sur des invites, SEEM. SEEM peut segmenter tout le contenu d'une image ou d'une vidéo à la fois et identifier des catégories d'objets en fonction de diverses entrées modales fournies par l'utilisateur (y compris le texte, les images, les graffitis, etc.). Le projet est open source et une adresse d'essai est fournie à tous.

Lien papier : https://arxiv.org/pdf/2304.06718.pdf
Lien du projet : https://github.com/UX-Decoder/Segment-Everything -Everywhere-All-At-Once
Adresse d'essai : https://huggingface.co/spaces/xdecoder/SEEM
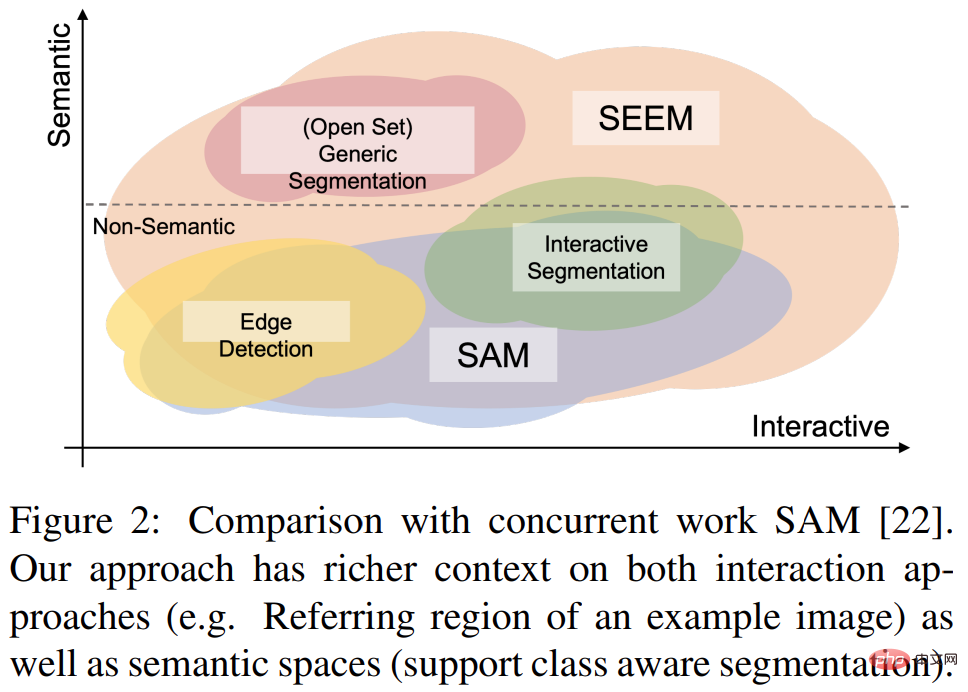
Cette étude a vérifié les performances de SEEM dans diverses tâches de segmentation grâce à l'efficacité d'expériences complètes sur. Même si SEEM n’a pas la capacité de comprendre les intentions des utilisateurs, il présente de fortes capacités de généralisation car il apprend à écrire différents types d’invites dans un espace de représentation unifié. De plus, SEEM peut gérer efficacement plusieurs séries d’interactions grâce à un décodeur d’invite léger.
Regardons d'abord l'effet de segmentation :
Segment "Optimus Prime" dans la photo Transformers :

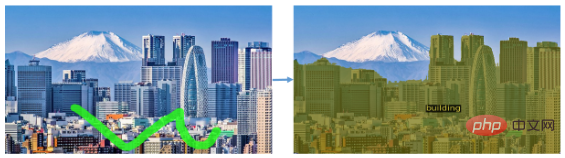
Il peut également segmenter un type d'objet, tel comme segmenter tous les bâtiments dans une image de paysage :
SEEM peut également facilement segmenter des objets en mouvement dans la vidéo :

Cet effet de segmentation peut être considéré comme très fluide . Jetons un coup d’œil à l’approche proposée dans cette étude.
Présentation de la méthode
Cette recherche vise à proposer une interface générale pour la segmentation d'images à l'aide d'invites multimodales. Afin d'atteindre cet objectif, ils ont proposé une nouvelle solution contenant 4 attributs, dont la polyvalence, la compositionnalité, l'interactivité et la conscience sémantique, dont
1) Polyvalence Cette recherche propose d'encoder des éléments hétérogènes tels que des points, des masques, des textes, des boîtes de détection (boîtes) et même la région de référence d'une autre image dans la même invite sémantique visuelle commune dans l'espace.
2) La compositionnalité écrit des requêtes à la volée pour le raisonnement en apprenant un espace sémantique visuel commun d'invites visuelles et textuelles. SEEM peut gérer n’importe quelle combinaison d’invites de saisie.
3) Interactivité : Cette étude introduit la conservation des informations de l'historique des conversations en combinant des invites de mémoire apprenables et une attention croisée guidée par des masques.
4) Conscience sémantique : utilisez un encodeur de texte pour encoder les requêtes de texte et masquer les étiquettes, fournissant ainsi une sémantique ouverte pour tous les résultats de segmentation de sortie.

En termes d'architecture, SEEM suit une architecture simple d'encodeur-décodeur Transformer et ajoute un encodeur de texte supplémentaire. Dans SEEM, le processus de décodage est similaire au LLM génératif, mais avec des entrées et des sorties multimodales. Toutes les requêtes sont renvoyées au décodeur sous forme d'invites, et les encodeurs d'images et de texte sont utilisés comme encodeurs d'invites pour coder tous les types de requêtes.
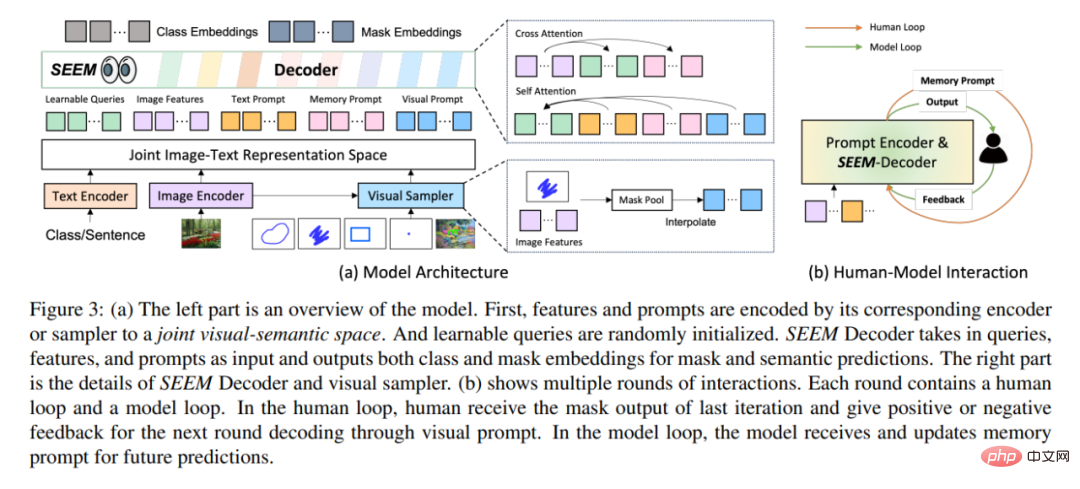
Plus précisément, cette étude encode toutes les requêtes (telles que les points, les cases et les masques) en invites visuelles, tout en utilisant un encodeur de texte pour convertir les requêtes de texte en invites de texte, telles que les invites visuelles et textuelles à maintenir l’alignement. Cinq types différents d'invites peuvent tous être mappés dans l'espace sémantique visuel commun, et les invites utilisateur invisibles peuvent être traitées grâce à une adaptation sans tir. En s'entraînant sur différentes tâches de segmentation, le modèle a la capacité de gérer diverses invites. De plus, différents types d’invites peuvent s’entraider en matière d’attention croisée. En fin de compte, les modèles SEEM peuvent utiliser diverses invites pour obtenir des résultats de segmentation supérieurs.
En plus de ses fortes capacités de généralisation, SEEM est également très efficace en fonctionnement. Les chercheurs ont utilisé des invites comme entrée dans le décodeur, de sorte que SEEM n’a dû exécuter l’extracteur de fonctionnalités qu’une seule fois au début, au cours de plusieurs cycles d’interactions avec des humains. À chaque itération, exécutez simplement à nouveau un décodeur léger avec une nouvelle invite. Par conséquent, lors du déploiement du modèle, l'extracteur de fonctionnalités avec un grand nombre de paramètres et une lourde charge d'exécution peut être exécuté sur le serveur, tandis que seul le décodeur relativement léger est exécuté sur la machine de l'utilisateur pour atténuer le problème de latence du réseau lors de plusieurs appels à distance.
Comme le montre la figure 3(b) ci-dessus, dans plusieurs cycles d'interaction, chaque interaction contient une boucle manuelle et une boucle modèle. Dans la boucle artificielle, l'humain reçoit la sortie du masque de l'itération précédente et donne un retour positif ou négatif pour le prochain cycle de décodage via des invites visuelles. Pendant la boucle du modèle, le modèle reçoit et met à jour les invites de mémoire pour les prédictions futures.
Résultats expérimentaux
Cette étude a comparé expérimentalement le modèle SEEM avec le modèle de segmentation interactif SOTA, et les résultats sont présentés dans le tableau 1 ci-dessous.
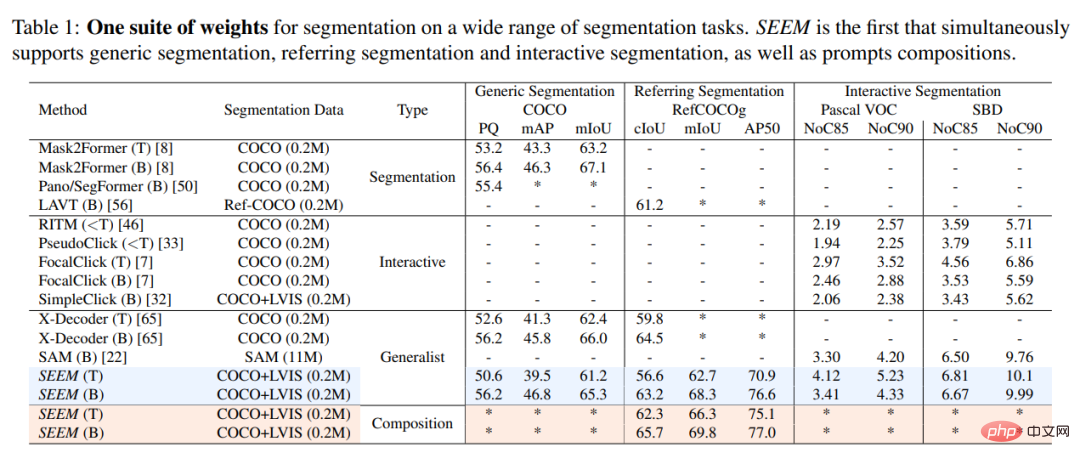
En tant que modèle général, SEEM atteint des performances comparables à celles de RITM, SimpleClick et d'autres modèles, et est très proche des performances de SAM, tandis que les données segmentées utilisées pour la formation par SAM sont 50 fois supérieures à celles de SEMBLER .
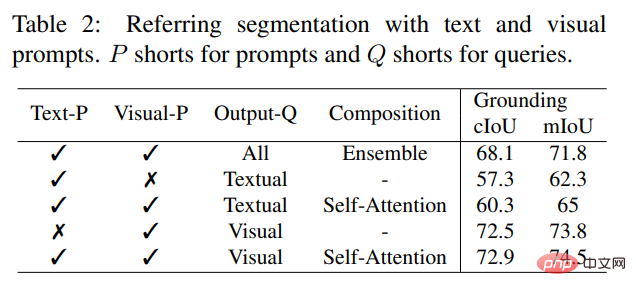
Contrairement aux modèles interactifs existants, SEEM est la première interface universelle qui prend en charge non seulement les tâches de segmentation classiques, mais également divers types de saisie utilisateur, notamment le texte, les points, les gribouillages, les cases et les images, offrant ainsi de puissantes combinaisons de fonctions. Comme le montre le tableau 2 ci-dessous, en ajoutant des invites combinables, SEEM a considérablement amélioré les performances de segmentation dans cIoU, mIoU et d'autres indicateurs.
Jetons un coup d'œil aux résultats de visualisation de la segmentation d'images interactive. Les utilisateurs n'ont qu'à dessiner un point ou simplement griffonner, et SEEM peut fournir de très bons résultats de segmentation

Vous pouvez également saisir du texte et laisser SEEM effectuer la segmentation d'image

Vous pouvez également saisir directement l'image de référence et indiquer la zone de référence, segmenter d'autres images et trouver des objets cohérents avec la zone de référence :

Ce projet peut déjà être essayé en ligne pour les personnes intéressées lecteurs, allez-y et essayez-le.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI