
Maison >développement back-end >Tutoriel Python >Résumé des méthodes courantes de manipulation des données de séries chronologiques Python
Résumé des méthodes courantes de manipulation des données de séries chronologiques Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-24 22:22:062149parcourir
Les données de séries chronologiques sont un type de données collectées sur une période de temps. Elles sont souvent utilisées dans des domaines tels que la finance, l'économie et la météorologie, et sont souvent analysées pour comprendre les tendances et les modèles au fil du temps. est une bibliothèque de manipulation de données puissante et populaire en Python, particulièrement adaptée au traitement des données de séries chronologiques. Il fournit un ensemble d'outils et de fonctions permettant de charger, manipuler et analyser facilement des données de séries chronologiques.
Dans cet article, nous introduisons l'indexation et le découpage des données de séries chronologiques, le rééchantillonnage et les calculs de fenêtres glissantes, ainsi que d'autres opérations courantes utiles, qui sont des techniques clés pour manipuler les données de séries chronologiques à l'aide de Pandas. 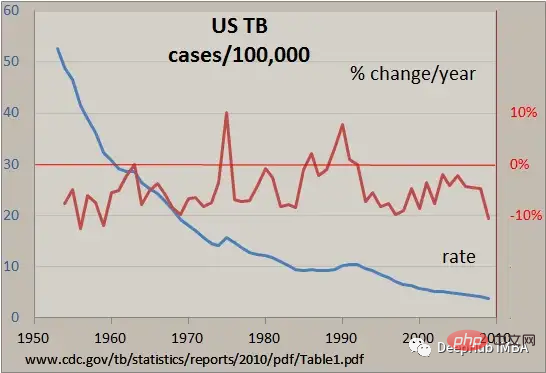
import datetime
t = datetime.datetime.now()
print(f"type: {type(t)} and t: {t}")
#type: <class 'datetime.datetime'> and t: 2022-12-26 14:20:51.278230
Généralement, nous utilisons des chaînes pour stocker les dates et les heures. Nous devons donc convertir ces chaînes en objets datetime lors de leur utilisation. Généralement, la chaîne d'heure a le format suivant :
AAAA-MM-JJ (par exemple 01/01/2022)
AAAA/MM/JJ (par exemple 01/01/2022)
- JJ-MM-AAAA (par exemple 01-01-2022)
- JJ/MM/AAAA (par exemple 01/01/2022)
- MM-JJ-AAAA (par exemple 01-01-2022)
- MM/JJ/AAAA (par exemple 01/01 /2022)
- HH:MM:SS (par exemple 11:30:00)
- HH:MM:SS AM/PM (par exemple 11:30:00 AM)
- HH:MM AM/PM (par exemple 11:30 AM)
- La fonction strptime prend une chaîne et une chaîne de format comme paramètres et renvoie un objet datetime.
string = '2022-01-01 11:30:09'
t = datetime.datetime.strptime(string, "%Y-%m-%d %H:%M:%S")
print(f"type: {type(t)} and t: {t}")
#type: <class 'datetime.datetime'> and t: 2022-01-01 11:30:09Vous pouvez également utiliser la fonction strftime pour reconvertir l'objet datetime en une représentation sous forme de chaîne dans un format spécifique.
t = datetime.datetime.now()
t_string = t.strftime("%m/%d/%Y, %H:%M:%S")
#12/26/2022, 14:38:47
t_string = t.strftime("%b/%d/%Y, %H:%M:%S")
#Dec/26/2022, 14:39:32Le temps Unix (temps POSIX ou temps d'époque) est un système qui représente le temps comme une valeur numérique unique. Il représente le nombre de secondes écoulées depuis 00:00:00 Temps universel coordonné (UTC) le jeudi 1er janvier 1970. 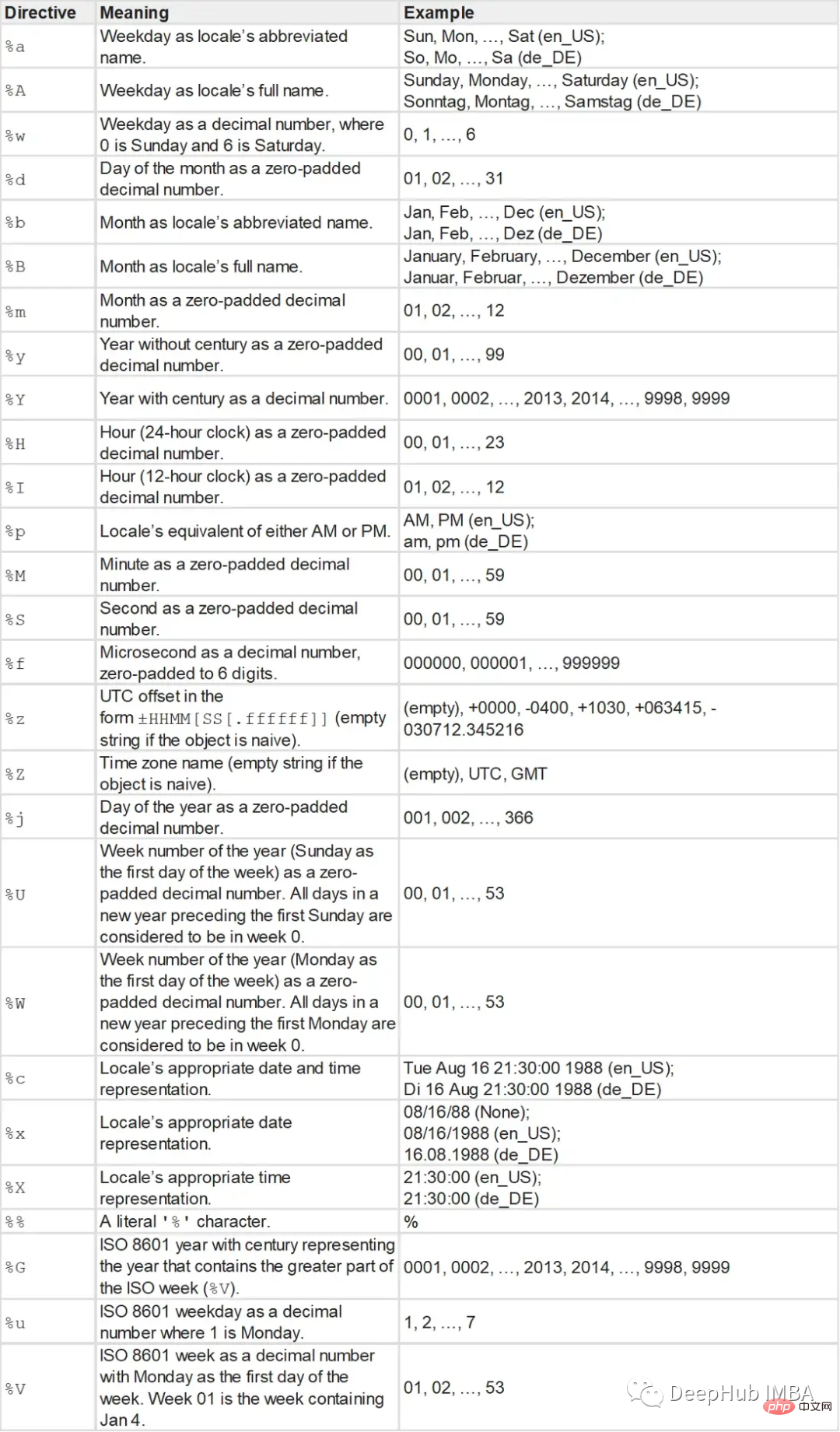
#convert datetime to unix time import time from datetime import datetime t = datetime.now() unix_t = int(time.mktime(t.timetuple())) #1672055277 #convert unix time to datetime unix_t = 1672055277 t = datetime.fromtimestamp(unix_t) #2022-12-26 14:47:57Utilisez le module dateutil pour analyser la chaîne de date afin d'obtenir l'objet datetime.
from dateutil import parser
date = parser.parse("29th of October, 1923")
#datetime.datetime(1923, 10, 29, 0, 0)PandasPandas fournit trois types de données de date : 1, Timestamp ou DatetimeIndex : il fonctionne comme les autres types d'index, mais possède également des fonctions spécialisées pour les opérations de séries chronologiques. t = pd.to_datetime("29/10/1923", dayfirst=True)
#Timestamp('1923-10-29 00:00:00')
t = pd.Timestamp('2019-01-01', tz = 'Europe/Berlin')
#Timestamp('2019-01-01 00:00:00+0100', tz='Europe/Berlin')
t = pd.to_datetime(["04/23/1920", "10/29/1923"])
#DatetimeIndex(['1920-04-23', '1923-10-29'], dtype='datetime64[ns]', freq=None)
2. période ou PeriodIndex : un intervalle de temps avec un début et une fin. Il se compose d'intervalles fixes. t = pd.to_datetime(["04/23/1920", "10/29/1923"])
period = t.to_period("D")
#PeriodIndex(['1920-04-23', '1923-10-29'], dtype='period[D]')3. Timedelta ou TimedeltaIndex : L'intervalle de temps entre deux dates. delta = pd.TimedeltaIndex(data =['1 days 03:00:00', '2 days 09:05:01.000030']) """ TimedeltaIndex(['1 days 02:00:00', '1 days 06:05:01.000030'], dtype='timedelta64[ns]', freq=None) """Dans Pandas, vous pouvez utiliser la méthode to_datetime pour convertir un objet en type de données datetime ou effectuer toute autre conversion.
import pandas as pd
df = pd.read_csv("dataset.txt")
df.head()
"""
date value
0 1991-07-01 3.526591
1 1991-08-01 3.180891
2 1991-09-01 3.252221
3 1991-10-01 3.611003
4 1991-11-01 3.565869
"""
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null object
1 value 204 non-null float64
dtypes: float64(1), object(1)
memory usage: 3.3+ KB
"""
# Convert to datetime
df["date"] = pd.to_datetime(df["date"], format = "%Y-%m-%d")
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null datetime64[ns]
1 value 204 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 3.3 KB
"""
# Convert to Unix
df['unix_time'] = df['date'].apply(lambda x: x.timestamp())
df.head()
"""
date value unix_time
0 1991-07-01 3.526591 678326400.0
1 1991-08-01 3.180891 681004800.0
2 1991-09-01 3.252221 683683200.0
3 1991-10-01 3.611003 686275200.0
4 1991-11-01 3.565869 688953600.0
"""
df["date_converted_from_unix"] = pd.to_datetime(df["unix_time"], unit = "s")
df.head()
"""
date value unix_time date_converted_from_unix
0 1991-07-01 3.526591 678326400.0 1991-07-01
1 1991-08-01 3.180891 681004800.0 1991-08-01
2 1991-09-01 3.252221 683683200.0 1991-09-01
3 1991-10-01 3.611003 686275200.0 1991-10-01
4 1991-11-01 3.565869 688953600.0 1991-11-01
""" Nous pouvons également déclarer la colonne date directement sur n'importe quel chargement de fichier en utilisant le paramètre parse_dates. df = pd.read_csv("dataset.txt", parse_dates=["date"])
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null datetime64[ns]
1 value 204 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 3.3 KB
"""S'il s'agit d'une donnée de série chronologique unique, il est préférable d'utiliser la colonne de date comme index de l'ensemble de données. df.set_index("date",inplace=True)
"""
Value
date
1991-07-01 3.526591
1991-08-01 3.180891
1991-09-01 3.252221
1991-10-01 3.611003
1991-11-01 3.565869
... ...
2008-02-01 21.654285
2008-03-01 18.264945
2008-04-01 23.107677
2008-05-01 22.912510
2008-06-01 19.431740
"""Numpy a également son propre type datetime np.Datetime64. Surtout lorsque vous travaillez avec de grands ensembles de données, la vectorisation est très utile et doit être utilisée en premier. import numpy as np
arr_date = np.array('2000-01-01', dtype=np.datetime64)
arr_date
#array('2000-01-01', dtype='datetime64[D]')
#broadcasting
arr_date = arr_date + np.arange(30)
"""
array(['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04',
'2000-01-05', '2000-01-06', '2000-01-07', '2000-01-08',
'2000-01-09', '2000-01-10', '2000-01-11', '2000-01-12',
'2000-01-13', '2000-01-14', '2000-01-15', '2000-01-16',
'2000-01-17', '2000-01-18', '2000-01-19', '2000-01-20',
'2000-01-21', '2000-01-22', '2000-01-23', '2000-01-24',
'2000-01-25', '2000-01-26', '2000-01-27', '2000-01-28',
'2000-01-29', '2000-01-30'], dtype='datetime64[D]')
"""Fonctions utilesVous trouverez ci-dessous quelques fonctions qui peuvent être utiles pour les séries chronologiques. df = pd.read_csv("dataset.txt", parse_dates=["date"])
df["date"].dt.day_name()
"""
0 Monday
1 Thursday
2 Sunday
3 Tuesday
4 Friday
...
199 Friday
200 Saturday
201 Tuesday
202 Thursday
203 Sunday
Name: date, Length: 204, dtype: object
"""DataReaderPandas_datareader est une bibliothèque auxiliaire pour la bibliothèque pandas. Il fournit de nombreuses données de séries chronologiques financières courantes. #pip install pandas-datareader from pandas_datareader import wb #GDP per Capita From World Bank df = wb.download(indicator='NY.GDP.PCAP.KD', country=['US', 'FR', 'GB', 'DK', 'NO'], start=1960, end=2019) """ NY.GDP.PCAP.KD country year Denmark 2019 57203.027794 2018 56563.488473 2017 55735.764901 2016 54556.068955 2015 53254.856370 ... ... United States 1964 21599.818705 1963 20701.269947 1962 20116.235124 1961 19253.547329 1960 19135.268182 [300 rows x 1 columns] """Plage de datesNous pouvons définir une plage de dates en utilisant la méthode date_range de pandas.
pd.date_range(start="2021-01-01", end="2022-01-01", freq="D")
"""
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
'2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08',
'2021-01-09', '2021-01-10',
...
'2021-12-23', '2021-12-24', '2021-12-25', '2021-12-26',
'2021-12-27', '2021-12-28', '2021-12-29', '2021-12-30',
'2021-12-31', '2022-01-01'],
dtype='datetime64[ns]', length=366, freq='D')
"""
pd.date_range(start="2021-01-01", end="2022-01-01", freq="BM")
"""
DatetimeIndex(['2021-01-29', '2021-02-26', '2021-03-31', '2021-04-30',
'2021-05-31', '2021-06-30', '2021-07-30', '2021-08-31',
'2021-09-30', '2021-10-29', '2021-11-30', '2021-12-31'],
dtype='datetime64[ns]', freq='BM')
"""
fridays= pd.date_range('2022-11-01', '2022-12-31', freq="W-FRI")
"""
DatetimeIndex(['2022-11-04', '2022-11-11', '2022-11-18', '2022-11-25',
'2022-12-02', '2022-12-09', '2022-12-16', '2022-12-23',
'2022-12-30'],
dtype='datetime64[ns]', freq='W-FRI')
"""
Nous pouvons créer une série chronologique en utilisant la méthode timedelta_range.
t = pd.timedelta_range(0, periods=10, freq="H") """ TimedeltaIndex(['0 days 00:00:00', '0 days 01:00:00', '0 days 02:00:00', '0 days 03:00:00', '0 days 04:00:00', '0 days 05:00:00', '0 days 06:00:00', '0 days 07:00:00', '0 days 08:00:00', '0 days 09:00:00'], dtype='timedelta64[ns]', freq='H') """
Formatting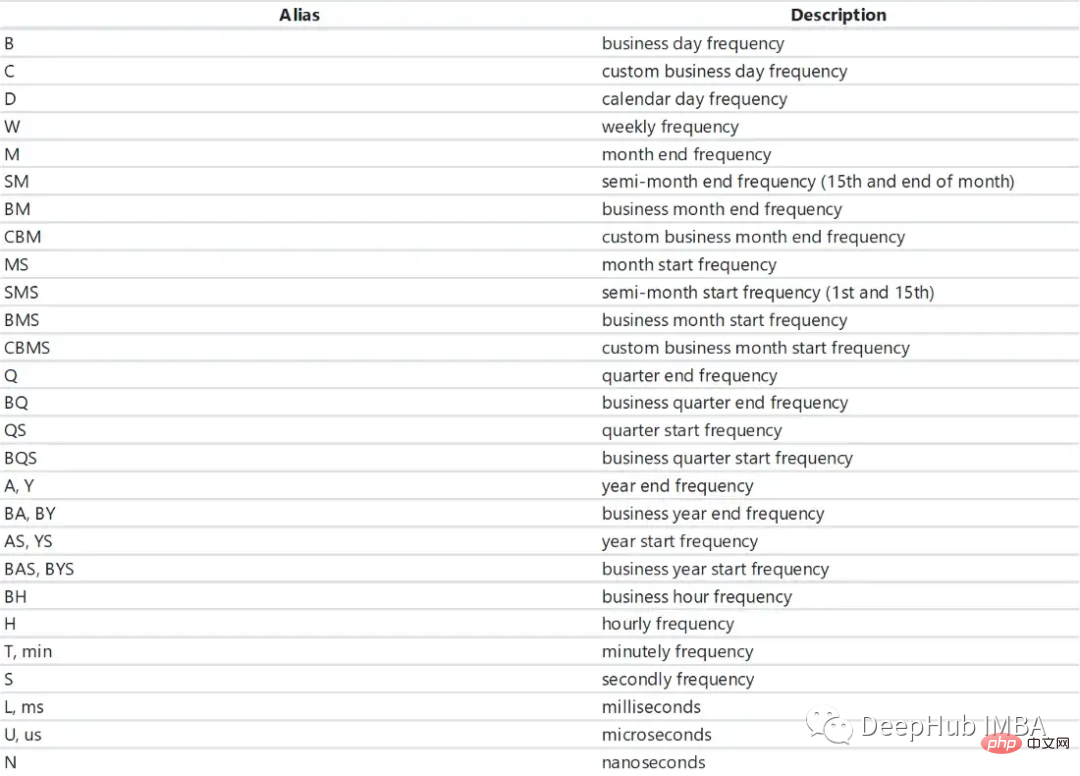
df["new_date"] = df["date"].dt.strftime("%b %d, %Y")
df.head()
"""
date value new_date
0 1991-07-01 3.526591 Jul 01, 1991
1 1991-08-01 3.180891 Aug 01, 1991
2 1991-09-01 3.252221 Sep 01, 1991
3 1991-10-01 3.611003 Oct 01, 1991
4 1991-11-01 3.565869 Nov 01, 1991
"""ParsesAnalyse un objet datetime et obtient l'objet enfant de la date. df["year"] = df["date"].dt.year df["month"] = df["date"].dt.month df["day"] = df["date"].dt.day df["calendar"] = df["date"].dt.date df["hour"] = df["date"].dt.time df.head() """ date value year month day calendar hour 0 1991-07-01 3.526591 1991 7 1 1991-07-01 00:00:00 1 1991-08-01 3.180891 1991 8 1 1991-08-01 00:00:00 2 1991-09-01 3.252221 1991 9 1 1991-09-01 00:00:00 3 1991-10-01 3.611003 1991 10 1 1991-10-01 00:00:00 4 1991-11-01 3.565869 1991 11 1 1991-11-01 00:00:00 """Vous pouvez également les recombiner.
df["date_joined"] = pd.to_datetime(df[["year","month","day"]])
print(df["date_joined"])
"""
0 1991-07-01
1 1991-08-01
2 1991-09-01
3 1991-10-01
4 1991-11-01
...
199 2008-02-01
200 2008-03-01
201 2008-04-01
202 2008-05-01
203 2008-06-01
Name: date_joined, Length: 204, dtype: datetime64[ns]
Filter queryUtilisez la méthode loc pour filtrer le DataFrame. df = df.loc["2021-01-01":"2021-01-10"]
truncate peut interroger des données dans deux intervalles de temps
df_truncated = df.truncate('2021-01-05', '2022-01-10')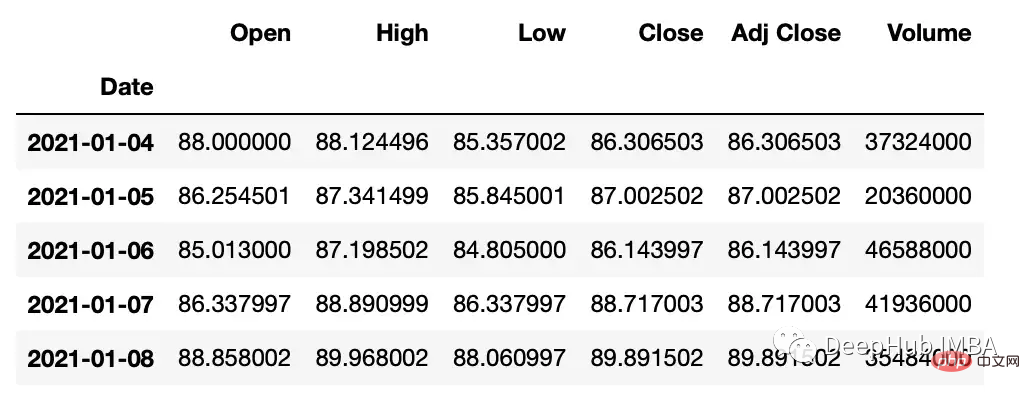
Opérations de données courantes
Les opérations suivantes sont sur les valeurs dans les ensembles de données de séries chronologiques. Nous utilisons la bibliothèque yfinance pour créer un ensemble de données boursières pour notre exemple. 
#get google stock price data import yfinance as yf start_date = '2020-01-01' end_date = '2023-01-01' ticker = 'GOOGL' df = yf.download(ticker, start_date, end_date) df.head() """ Date Open High Low Close Adj Close Volume 2020-01-02 67.420502 68.433998 67.324501 68.433998 68.433998 27278000 2020-01-03 67.400002 68.687500 67.365997 68.075996 68.075996 23408000 2020-01-06 67.581497 69.916000 67.550003 69.890503 69.890503 46768000 2020-01-07 70.023003 70.175003 69.578003 69.755501 69.755501 34330000 2020-01-08 69.740997 70.592499 69.631500 70.251999 70.251999 35314000 """Calculer la différenceLa fonction diff peut calculer l'interpolation entre un élément et un autre élément.
#subtract that day's value from the previous day df["Diff_Close"] = df["Close"].diff() #Subtract that day's value from the day's value 2 days ago df["Diff_Close_2Days"] = df["Close"].diff(periods=2)
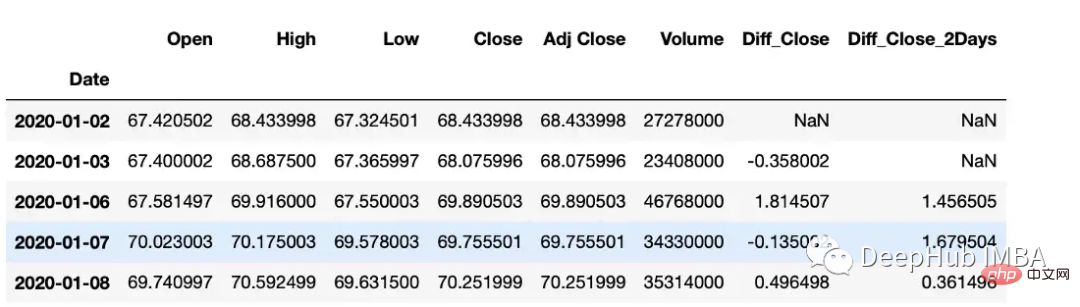
累计总数
df["Volume_Cumulative"] = df["Volume"].cumsum()
滚动窗口计算
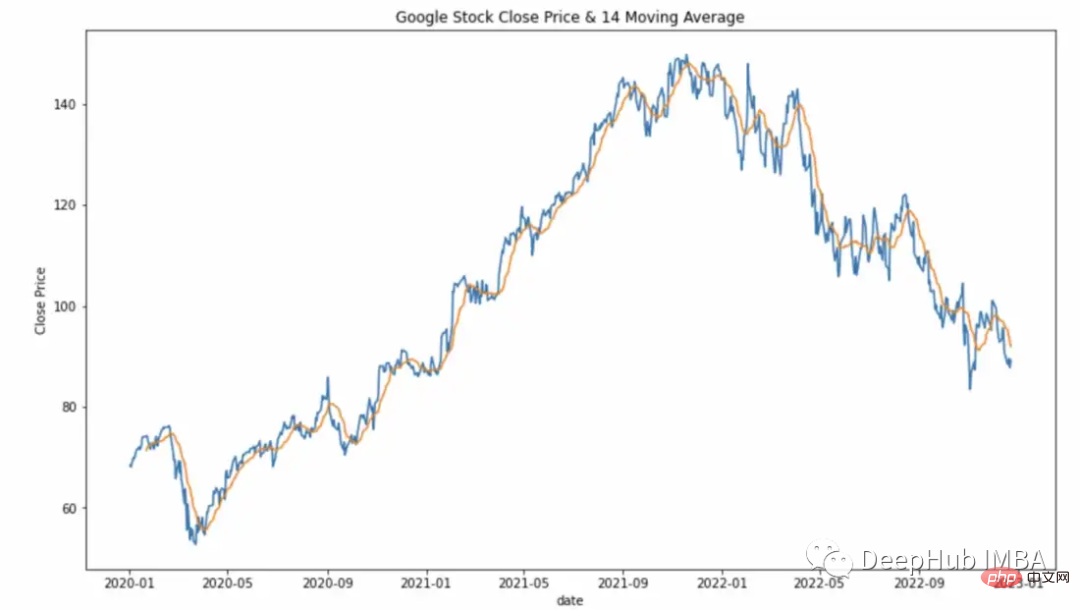
滚动窗口计算(移动平均线)。
df["Close_Rolling_14"] = df["Close"].rolling(14).mean() df.tail()
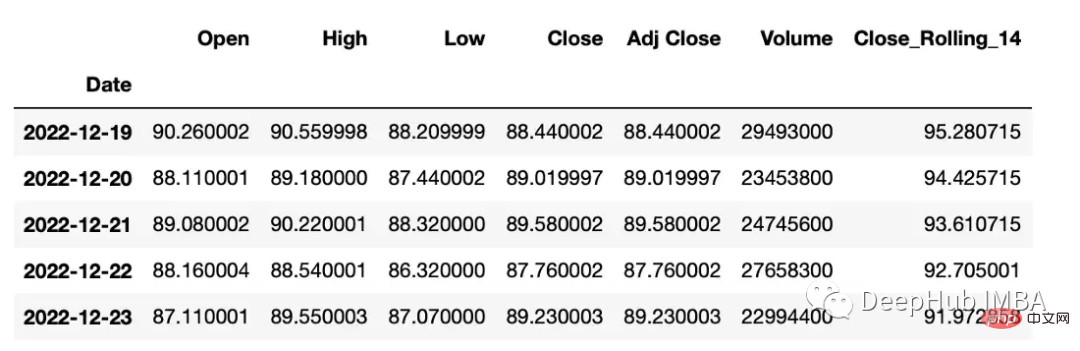
可以对我们计算的移动平均线进行可视化
常用的参数:
- center:决定滚动窗口是否应以当前观测值为中心。
- min_periods:窗口中产生结果所需的最小观测次数。
s = pd.Series([1, 2, 3, 4, 5]) #the rolling window will be centered on each observation rolling_mean = s.rolling(window=3, center=True).mean() """ 0 NaN 1 2.0 2 3.0 3 4.0 4 NaN dtype: float64 Explanation: first window: [na 1 2] = na second window: [1 2 3] = 2 """ # the rolling window will not be centered, #and will instead be anchored to the left side of the window rolling_mean = s.rolling(window=3, center=False).mean() """ 0 NaN 1 NaN 2 2.0 3 3.0 4 4.0 dtype: float64 Explanation: first window: [na na 1] = na second window: [na 1 2] = na third window: [1 2 3] = 2 """
平移
Pandas有两个方法,shift()和tshift(),它们可以指定倍数移动数据或时间序列的索引。Shift()移位数据,而tshift()移位索引。
#shift the data df_shifted = df.shift(5,axis=0) df_shifted.head(10) #shift the indexes df_tshifted = df.tshift(periods = 4, freq = 'D') df_tshifted.head(10)
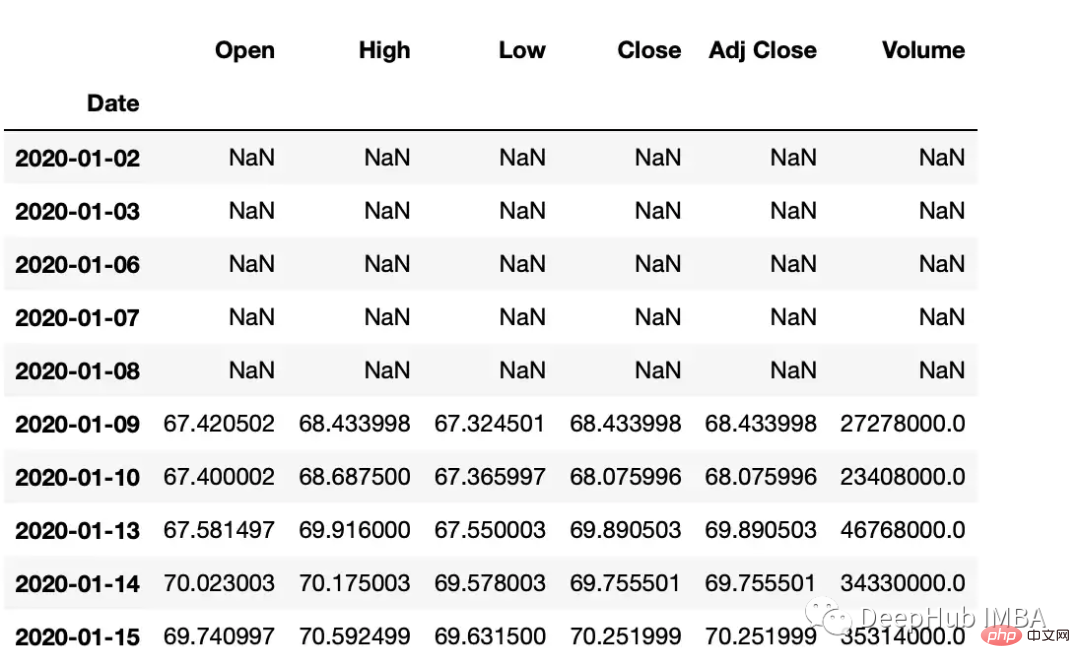
df_shifted
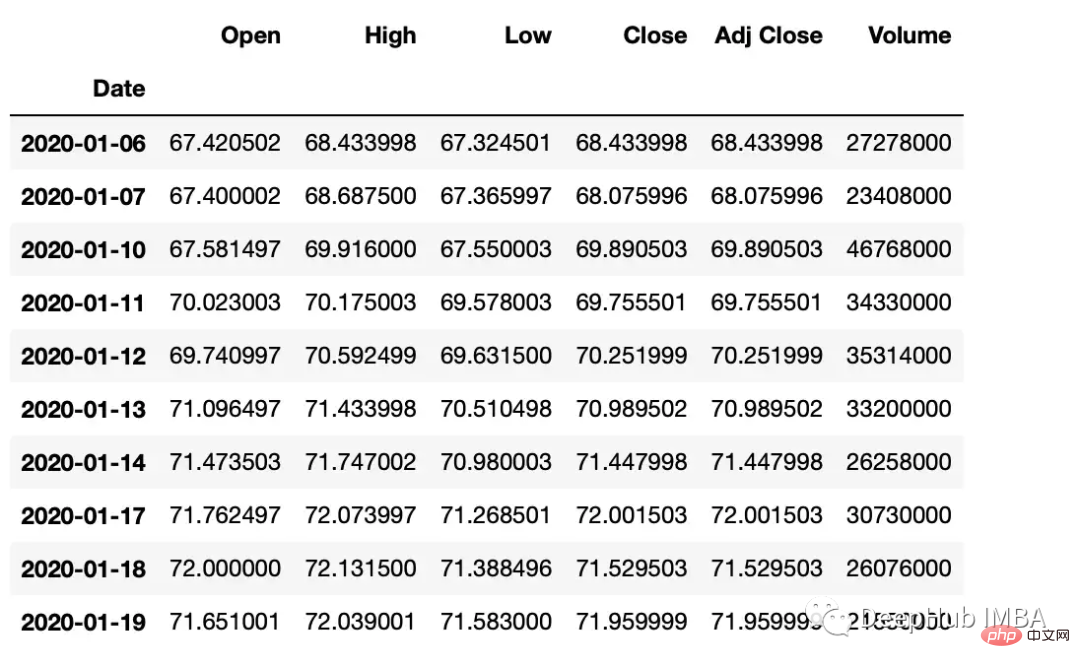
df_tshifted
时间间隔转换
在 Pandas 中,操 to_period 函数允许将日期转换为特定的时间间隔。可以获取具有许多不同间隔或周期的日期
df["Period"] = df["Date"].dt.to_period('W')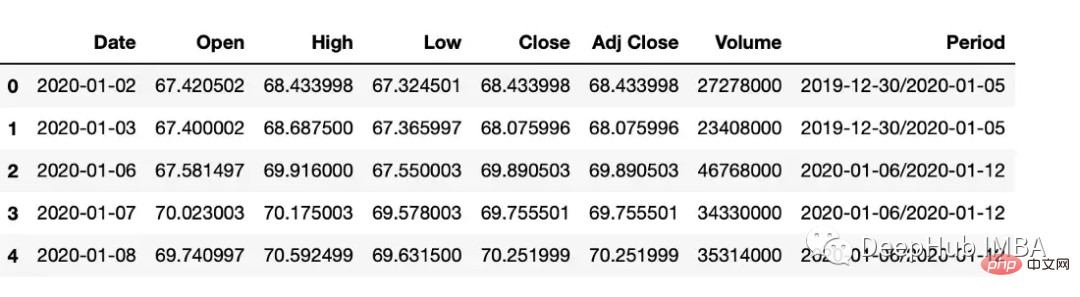
频率
Asfreq方法用于将时间序列转换为指定的频率。
monthly_data = df.asfreq('M', method='ffill')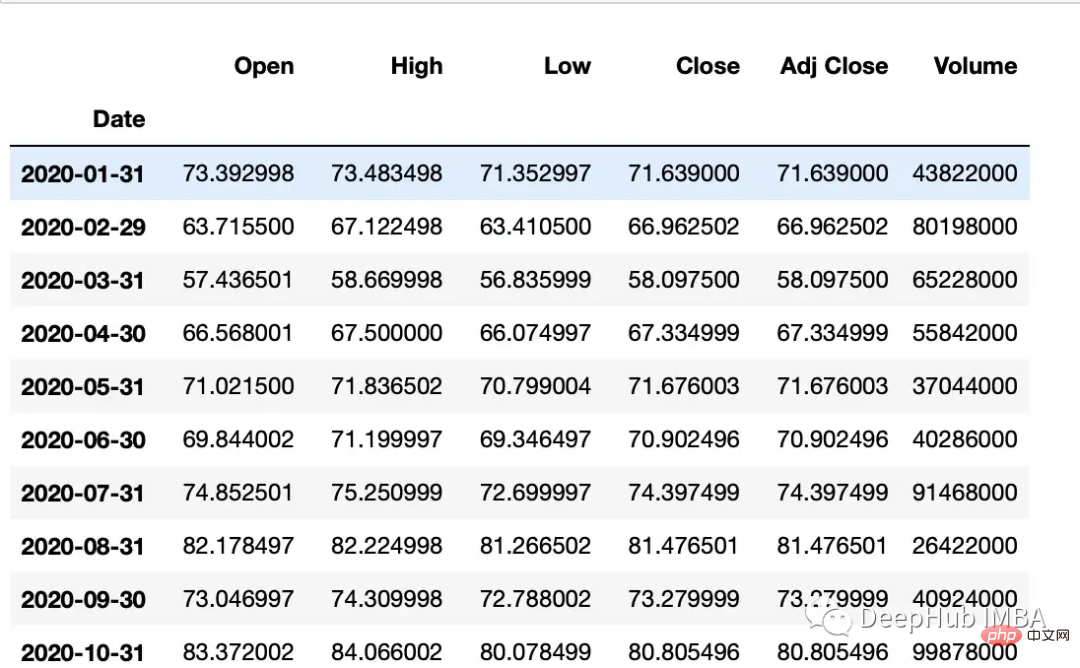
常用参数:
freq:数据应该转换到的频率。这可以使用字符串别名(例如,'M'表示月,'H'表示小时)或pandas偏移量对象来指定。
method:如何在转换频率时填充缺失值。这可以是'ffill'(向前填充)或'bfill'(向后填充)之类的字符串。
采样
resample可以改变时间序列频率并重新采样。我们可以进行上采样(到更高的频率)或下采样(到更低的频率)。因为我们正在改变频率,所以我们需要使用一个聚合函数(比如均值、最大值等)。
resample方法的参数:
rule:数据重新采样的频率。这可以使用字符串别名(例如,'M'表示月,'H'表示小时)或pandas偏移量对象来指定。
#down sample
monthly_data = df.resample('M').mean()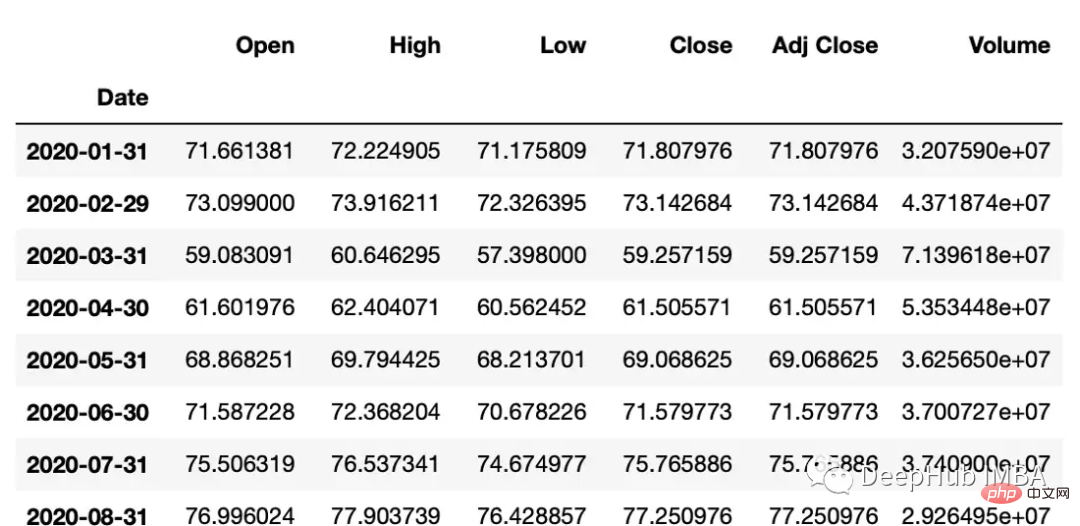
#up sample
minute_data = data.resample('T').ffill()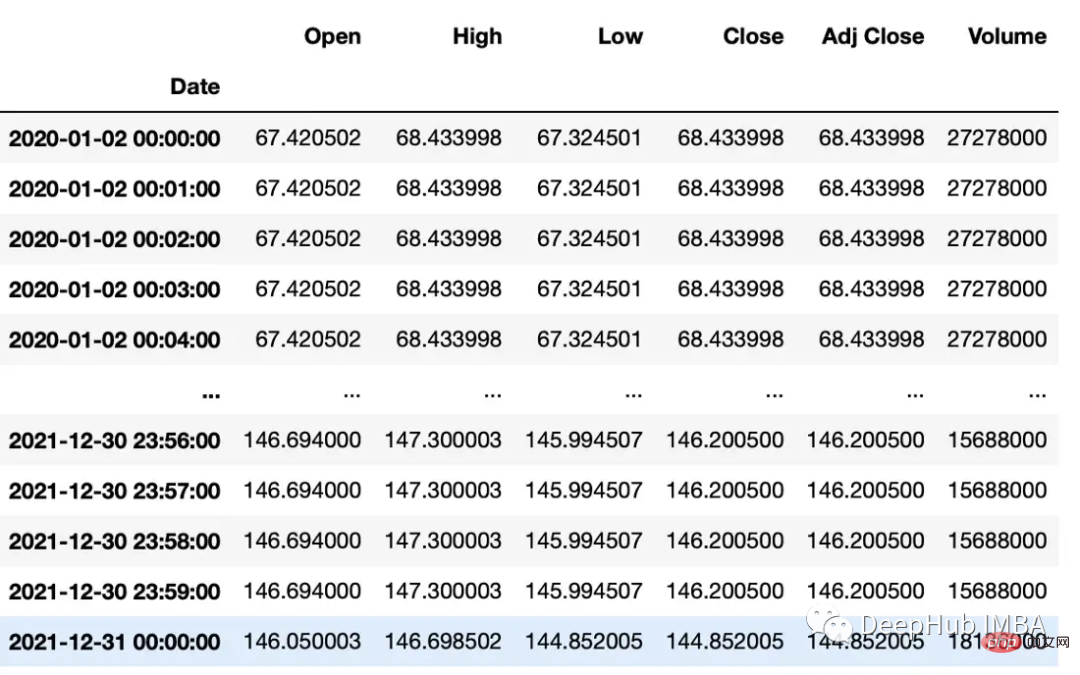
百分比变化
使用pct_change方法来计算日期之间的变化百分比。
df["PCT"] = df["Close"].pct_change(periods=2) print(df["PCT"]) """ Date 2020-01-02 NaN 2020-01-03 NaN 2020-01-06 0.021283 2020-01-07 0.024671 2020-01-08 0.005172 ... 2022-12-19 -0.026634 2022-12-20 -0.013738 2022-12-21 0.012890 2022-12-22 -0.014154 2022-12-23 -0.003907 Name: PCT, Length: 752, dtype: float64 """
总结
在Pandas和NumPy等库的帮助下,可以对时间序列数据执行广泛的操作,包括过滤、聚合和转换。本文介绍的是一些在工作中经常遇到的常见操作,希望对你有所帮助。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!