
Maison >Périphériques technologiques >IA >'Lu Zhiwu, chercheur à l'Université Renmin de Chine, a proposé l'impact important de ChatGPT sur les modèles génératifs multimodaux'
'Lu Zhiwu, chercheur à l'Université Renmin de Chine, a proposé l'impact important de ChatGPT sur les modèles génératifs multimodaux'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-24 18:25:091744parcourir
Ce qui suit est le contenu du discours du professeur Lu Zhiwu lors de la conférence ChatGPT et sur la technologie des grands modèles organisée par le Cœur de la Machine. Le Cœur de la Machine l'a édité et organisé sans changer le sens original :
 .
.
Bonjour à tous, je m'appelle Lu Zhiwu, de l'Université Renmin de Chine. Le titre de mon rapport d'aujourd'hui est « Éclairages importants de ChatGPT sur les modèles génératifs multimodaux », qui se compose de quatre parties.

Tout d'abord, ChatGPT nous apporte quelques inspirations sur l'innovation du paradigme de recherche. Le premier point est d'utiliser « big model + big data », qui est un paradigme de recherche qui a été vérifié à plusieurs reprises et qui est également le paradigme de recherche fondamental de ChatGPT. Il est particulièrement important de souligner que ce n'est que lorsqu'un grand modèle atteint un certain niveau qu'il disposera de capacités émergentes, telles que l'apprentissage en contexte, le raisonnement CoT et d'autres capacités. Ces capacités sont très étonnantes.
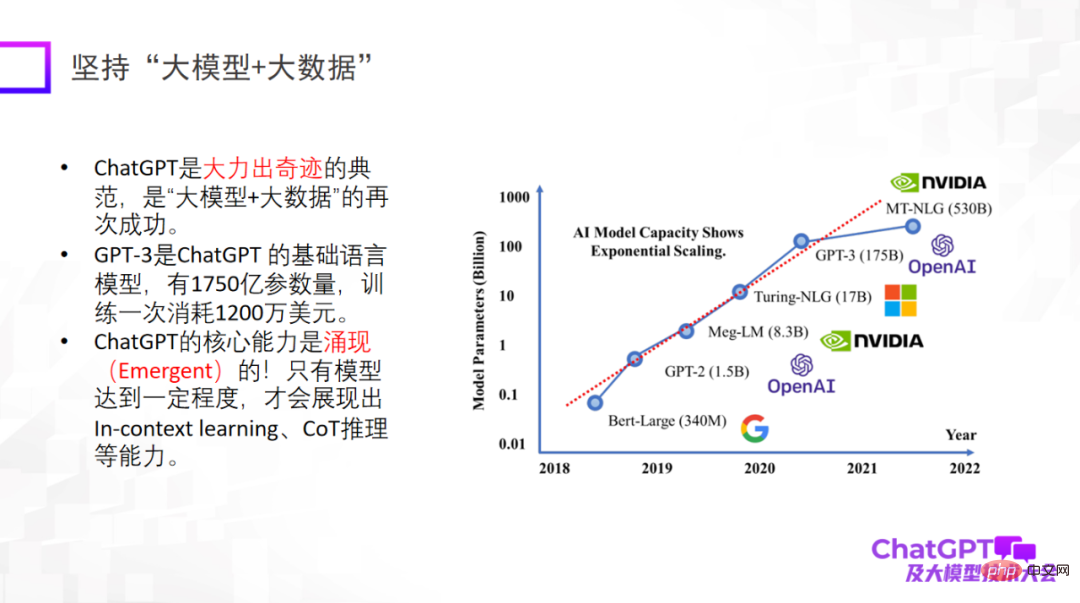
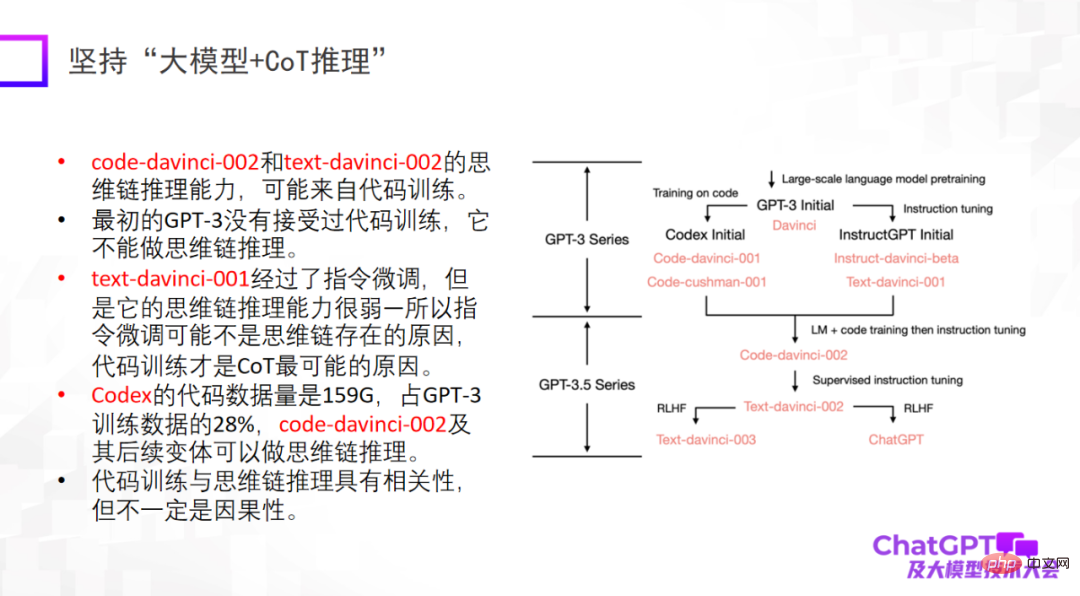
Le deuxième point est d'insister sur le "grand modèle + inférence". C'est aussi le point qui m'a le plus impressionné sur ChatGPT. Car dans le domaine du machine learning ou de l’intelligence artificielle, le raisonnement est reconnu comme le plus difficile, et ChatGPT a également fait des percées à cet égard. Bien sûr, la capacité de raisonnement de ChatGPT peut provenir principalement de la formation au code, mais il n’est pas encore certain qu’il existe un lien inévitable. En termes de raisonnement, nous devrions faire plus d'efforts pour déterminer d'où il vient ou s'il existe d'autres méthodes de formation pour améliorer davantage sa capacité de raisonnement.
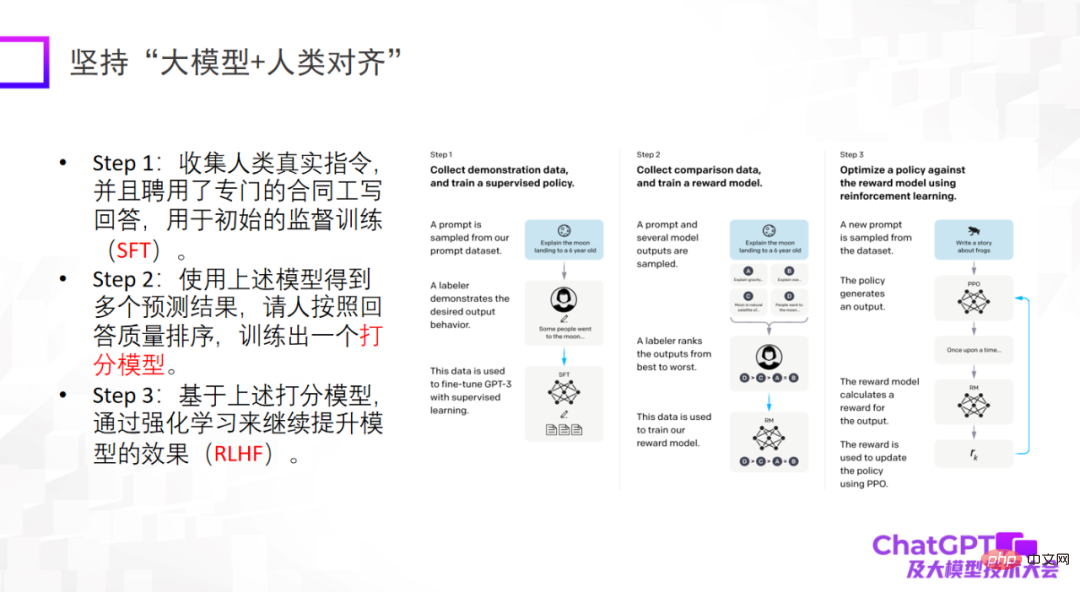
Le troisième point est que les grands modèles doivent être alignés sur les humains. C'est une révélation importante que ChatGPT nous donne du point de vue de l'ingénierie ou du point de vue de l'atterrissage de modèles. S’il n’est pas aligné sur les humains, le modèle générera de nombreuses informations nuisibles, le rendant inutilisable. Le troisième point n’est pas d’augmenter la limite supérieure du modèle, mais la fiabilité et la sécurité du modèle sont effectivement très importantes.
L'avènement de ChatGPT a eu un grand impact dans de nombreux domaines, dont moi-même. Parce que je fais de la multimodalité depuis plusieurs années, je vais commencer à réfléchir aux raisons pour lesquelles nous n'avons pas fait un modèle aussi puissant.
ChatGPT est une génération générale en langage ou en texte Jetons un coup d'œil aux dernières avancées dans le domaine de la génération générale multimodale. Les modèles multimodaux de pré-formation ont commencé à se transformer en modèles génératifs généraux multimodaux, et quelques explorations préliminaires ont eu lieu. Jetons d’abord un coup d’œil au modèle Flamingo proposé par Google en 2019. La figure suivante est la structure de son modèle.
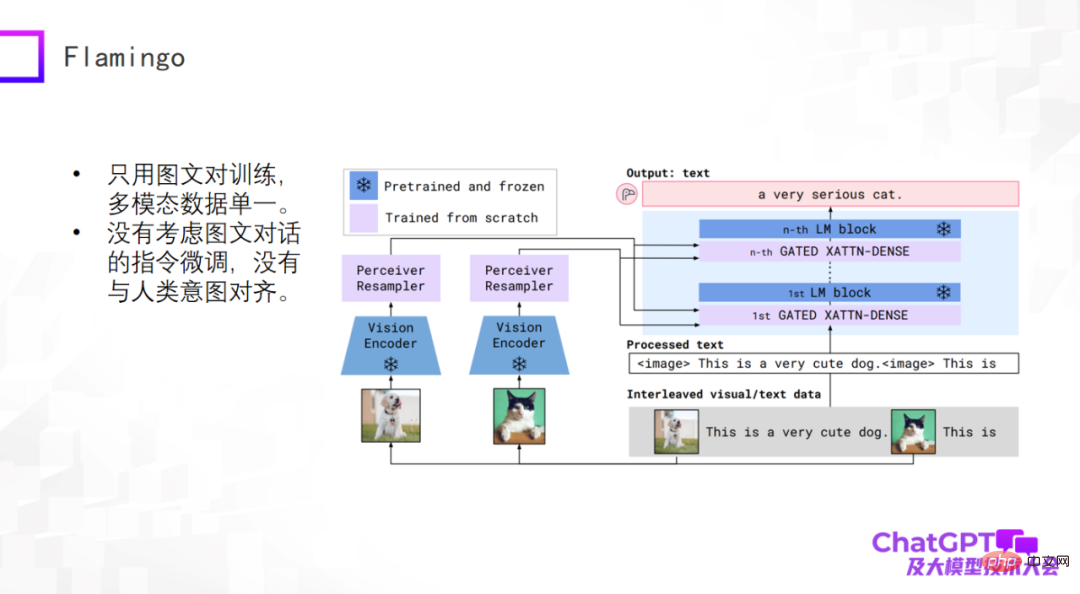
Le corps principal de l'architecture du modèle Flamingo est le décodeur (Decoder) du grand modèle de langage, qui est le module bleu sur le côté droit de l'image ci-dessus. Certaines couches d'adaptateur sont ajoutées entre chaque module bleu. Le visuel sur la gauche Une partie de ceci est l’ajout d’un Vision Encoder et d’un Perceiver Resampler. La conception de l'ensemble du modèle consiste à encoder et à convertir des éléments visuels, à passer par l'adaptateur et à les aligner avec le langage, afin que le modèle puisse générer automatiquement des descriptions textuelles pour les images.
Quels sont les avantages d'une conception architecturale comme Flamingo ? Tout d'abord, le module bleu dans l'image ci-dessus est fixe (gelé), y compris le modèle de langage Decoder ; tandis que la quantité de paramètres du module rose lui-même est contrôlable, de sorte que le nombre de paramètres réellement entraînés par le modèle Flamingo est très faible. Ne pensez donc pas que les modèles génératifs universels multimodaux soient difficiles à construire. En fait, ce n’est pas si pessimiste. Le modèle Flamingo formé peut effectuer de nombreuses tâches générales basées sur la génération de texte. Bien entendu, l'entrée est multimodale, comme la description vidéo, les questions et réponses visuelles, le dialogue multimodal, etc. De ce point de vue, Flamingo peut être considéré comme un modèle génératif général.
Le deuxième exemple est le modèle BLIP-2 récemment publié il y a quelque temps. Il est amélioré sur la base de BLIP-1. Son architecture de modèle est très similaire à celle de Flamingo. Il contient essentiellement un encodeur d'image et un décodeur d'un grand langage. model. , ces deux parties sont corrigées, puis un Q-Former avec une fonction de conversion est ajouté au milieu - de la conversion visuelle à la conversion linguistique. Ainsi, la partie du BLIP-2 qui nécessite vraiment une formation est le Q-Former.
Comme le montre la figure ci-dessous, saisissez d'abord une image (l'image de droite) dans l'encodeur d'image. Le texte au milieu est la question ou l'instruction soulevée par l'utilisateur. Après l'encodage Q-Former. entrée dans le grand modèle de langage. Enfin, la réponse est générée, probablement grâce à un tel processus de génération.
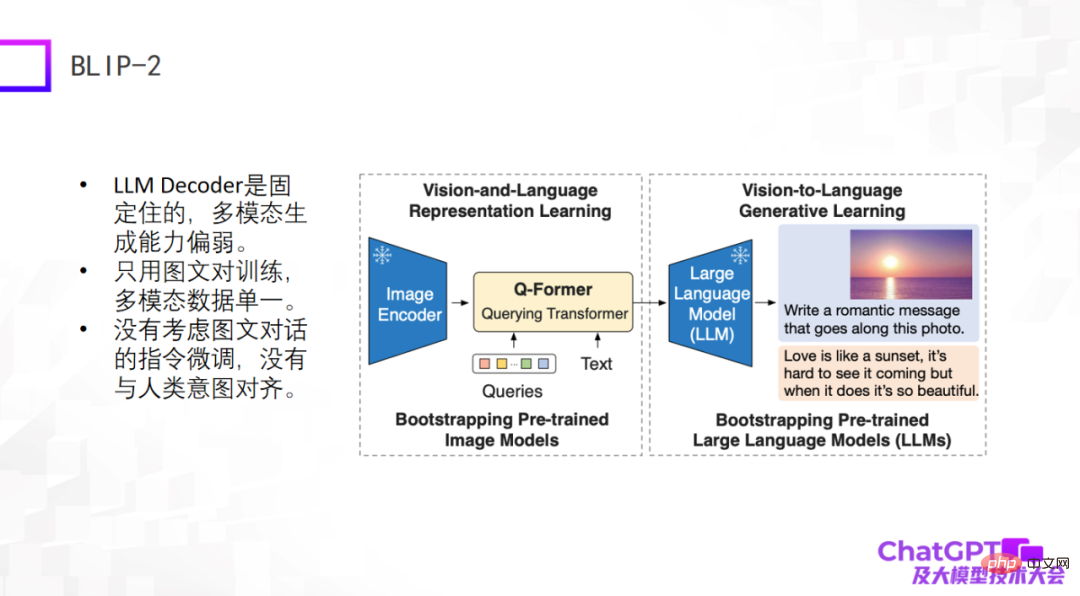
Les défauts de ces deux modèles sont évidents, car ils sont apparus relativement tôt ou viennent d'apparaître, et les méthodes d'ingénierie utilisées par ChatGPT n'ont pas été prises en compte, du moins il n'y a pas d'instructions pour le dialogue graphique ou multimodal dialogue, de sorte que leur effet de génération global n'est pas satisfaisant.
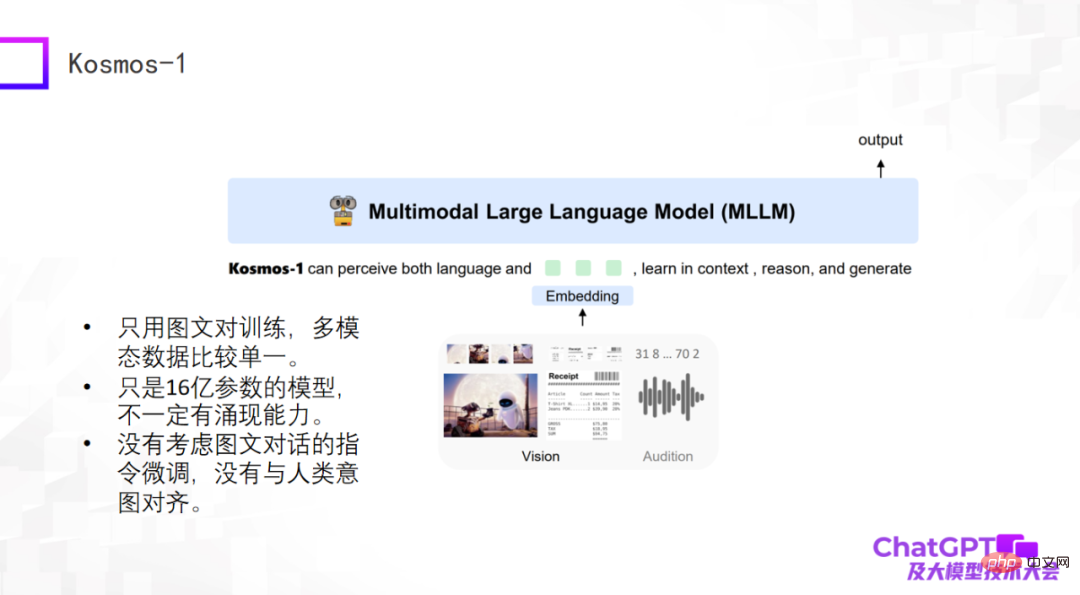
Le troisième est Kosmos-1 récemment publié par Microsoft. Il a une structure très simple et n'utilise que des paires d'images et de texte pour la formation. Les données multimodales sont relativement uniques. La plus grande différence entre Kosmos-1 et les deux modèles ci-dessus est que le grand modèle de langage lui-même dans les deux modèles ci-dessus est fixe, tandis que le grand modèle de langage lui-même dans Kosmos-1 doit être entraîné, donc le modèle Kosmos-1 Le nombre de paramètres n’est que de 1,6 milliard, et un modèle avec 1,6 milliard de paramètres n’aura peut-être pas la capacité d’émerger. Bien entendu, Kosmos-1 n'a pas pris en compte le réglage fin des commandes dans le dialogue graphique, ce qui l'a amené à dire parfois des bêtises.
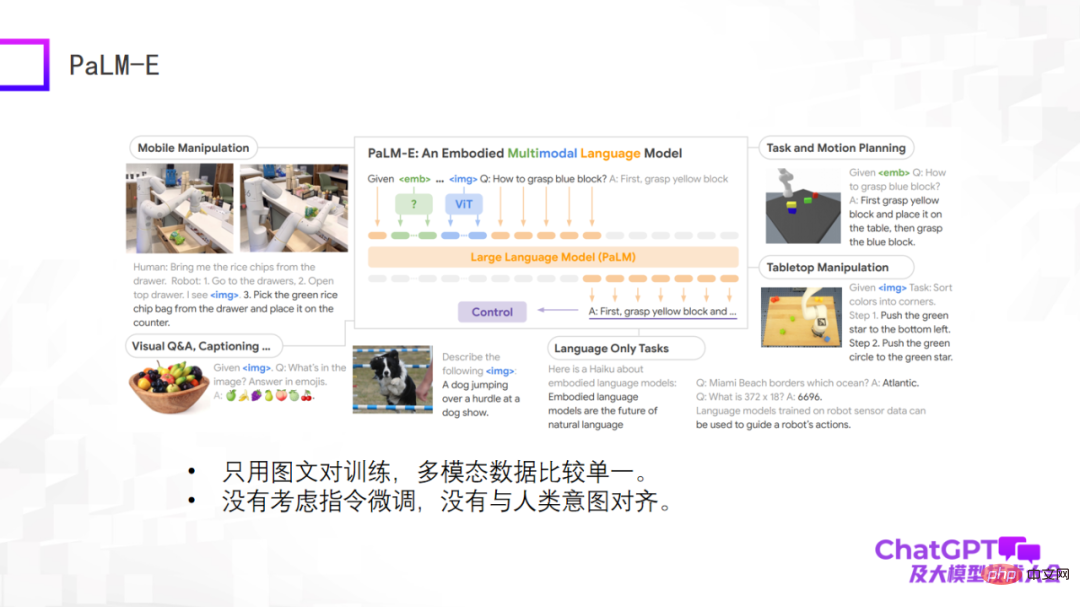
L'exemple suivant est le modèle de langage visuel incarné multimodal de Google, PaLM-E. Le modèle PaLM-E est similaire aux trois premiers exemples. PaLM-E utilise également le modèle de grand langage ViT +. La plus grande avancée de PaLM-E est qu’il explore enfin la possibilité de mettre en œuvre de grands modèles de langage multimodaux dans le domaine de la robotique. PaLM-E tente la première étape de l'exploration, mais les types de tâches robotiques qu'il considère sont très limités et ne peuvent pas être véritablement universels.
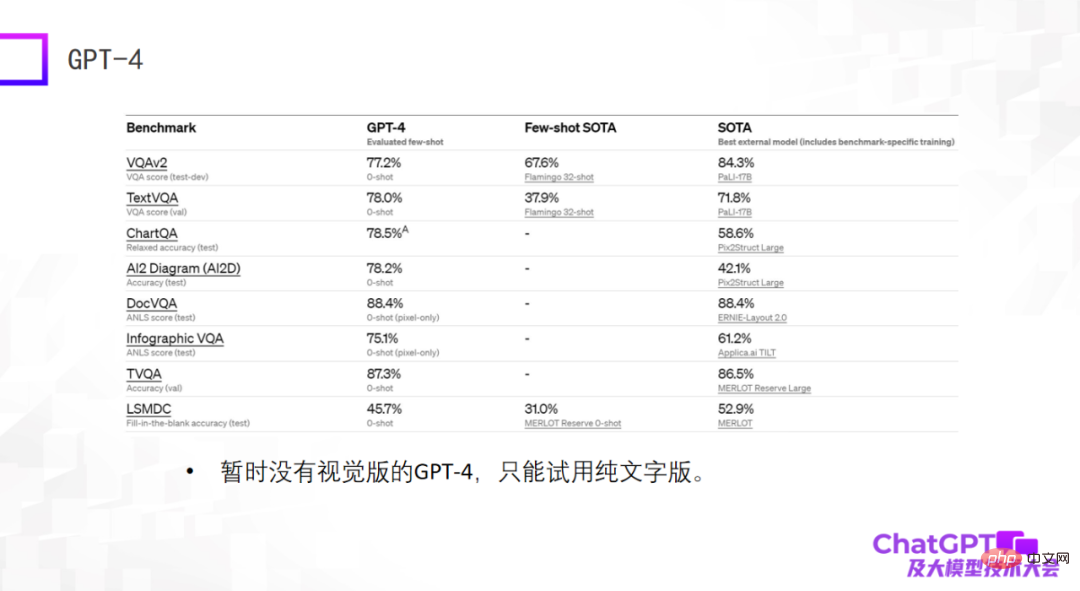
Le dernier exemple est GPT-4 - qui donne des résultats particulièrement étonnants sur des ensembles de données standard, plusieurs fois encore meilleurs que les modèles SOTA affinés actuellement entraînés sur l'ensemble de données. Cela peut surprendre, mais cela ne veut rien dire. Lorsque nous construisions de grands modèles multimodaux il y a deux ans, nous avons découvert que les capacités des grands modèles ne peuvent pas être évaluées sur des ensembles de données standard. De bonnes performances sur des ensembles de données standard ne signifient pas de bons résultats dans l'utilisation réelle. deux. Gros écart. Pour cette raison, je suis légèrement déçu par le GPT-4 actuel, car il ne donne que des résultats sur des ensembles de données standards. De plus, le GPT-4 actuellement disponible n’est pas une version visuelle, mais une version textuelle pure.
De manière générale, les modèles ci-dessus sont utilisés pour la génération générale de langage, et l'entrée est une entrée multimodale. Les deux modèles suivants sont différents - non seulement la génération générale de langage, mais aussi la génération de vision, qui peut. générer à la fois du langage et des images.
Le premier est Visual ChatGPT de Microsoft, permettez-moi de l'évaluer brièvement. L'idée de ce modèle est très simple, et il s'agit plutôt d'une considération de conception de produit. Il existe de nombreux types de génération liée à la vision, ainsi que certains modèles de détection visuelle. Les entrées et les instructions pour ces différentes tâches varient considérablement. Le problème est de savoir comment utiliser un modèle pour inclure toutes ces tâches. Microsoft a donc conçu le gestionnaire d'invites. qui est utilisé dans la partie principale, ChatGPT d'OpenAI équivaut à traduire des instructions pour différentes tâches de génération visuelle via ChatGPT. Les questions de l'utilisateur sont des instructions décrites en langage naturel, qui sont traduites en instructions que la machine peut comprendre grâce à ChatGPT.
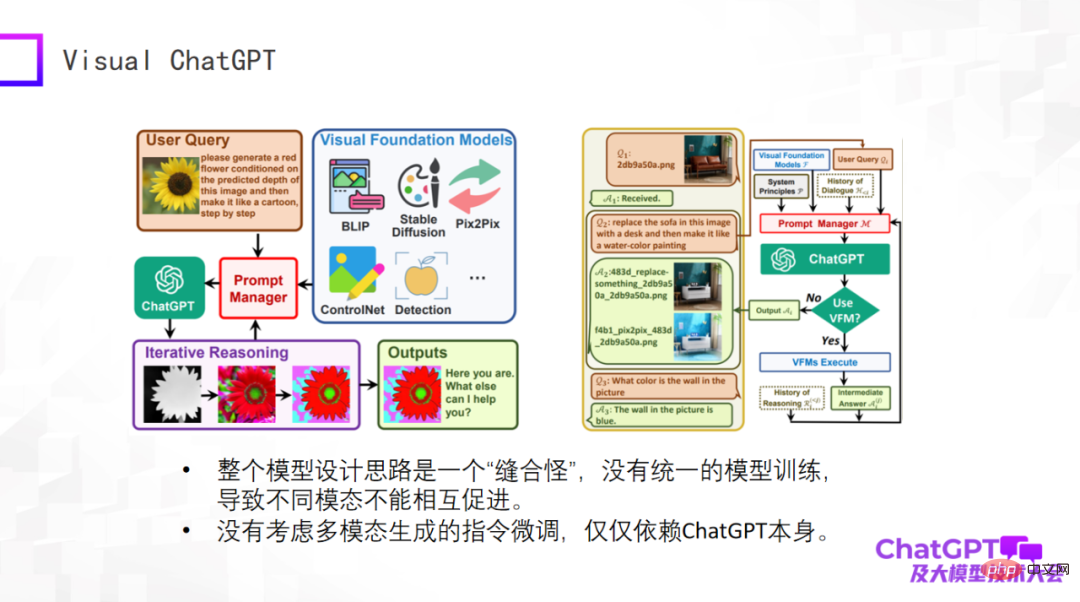
Visual ChatGPT fait exactement une telle chose. C'est donc vraiment bien du point de vue du produit, mais rien de nouveau du point de vue de la conception du modèle. Par conséquent, l'ensemble du modèle est un « monstre de point » du point de vue du modèle. Il n'y a pas de formation de modèle unifiée, ce qui n'entraîne aucune promotion mutuelle entre les différents modes. La raison pour laquelle nous pratiquons la multimodalité est que nous pensons que les données provenant de différentes modalités doivent s'entraider. Et Visual ChatGPT ne prend pas en compte le réglage fin des instructions de génération multimodale. Son réglage fin repose uniquement sur ChatGPT lui-même.
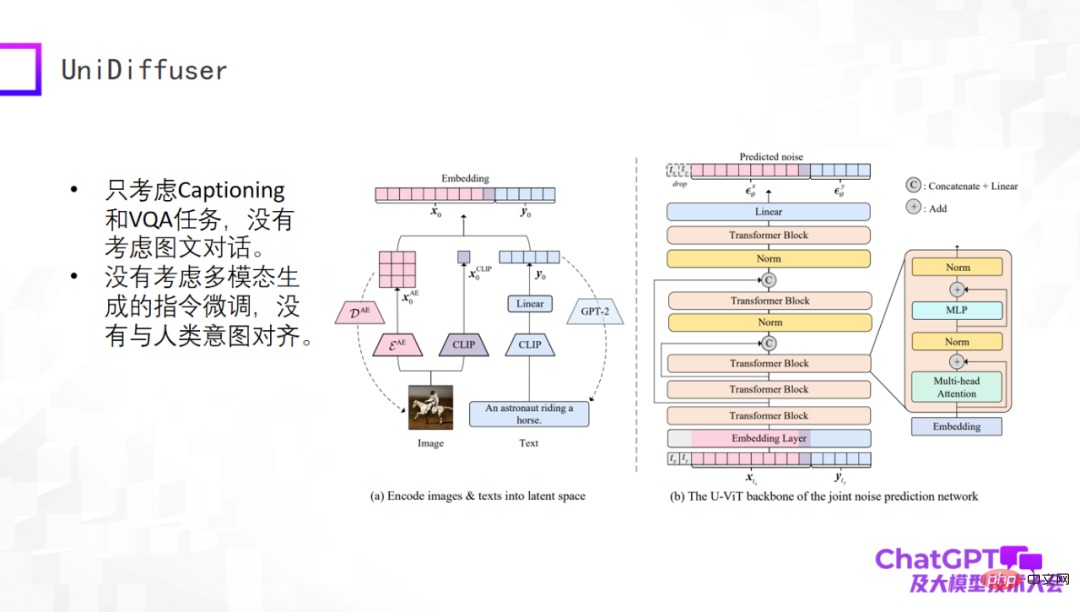
L'exemple suivant est le modèle UniDiffuser publié par l'équipe du professeur Zhu Jun de l'Université Tsinghua. D'un point de vue académique, ce modèle peut véritablement générer du texte et du contenu visuel à partir d'une entrée multimodale. Cela est dû à son architecture de réseau basée sur un transformateur U-ViT, qui est similaire à U-Net, le composant principal de Stable Diffusion, et. génère ensuite des images et la génération de texte sont unifiées dans un cadre. Ce travail en lui-même est très significatif, mais il est encore relativement précoce. Par exemple, il ne prend en compte que les tâches de sous-titrage et de VQA, ne prend pas en compte plusieurs cycles de dialogue et n'affine pas les instructions pour la génération multimodale.
Il y a tellement de critiques auparavant, nous avons donc également créé un produit appelé ChatImg, comme le montre l'image ci-dessous. De manière générale, ChatImg comprend un encodeur d'image, un encodeur d'image et de texte multimodal et un décodeur de texte. Il est similaire à Flamingo et BLIP-2, mais nous en considérons davantage, et il existe des différences détaillées dans l'implémentation spécifique.
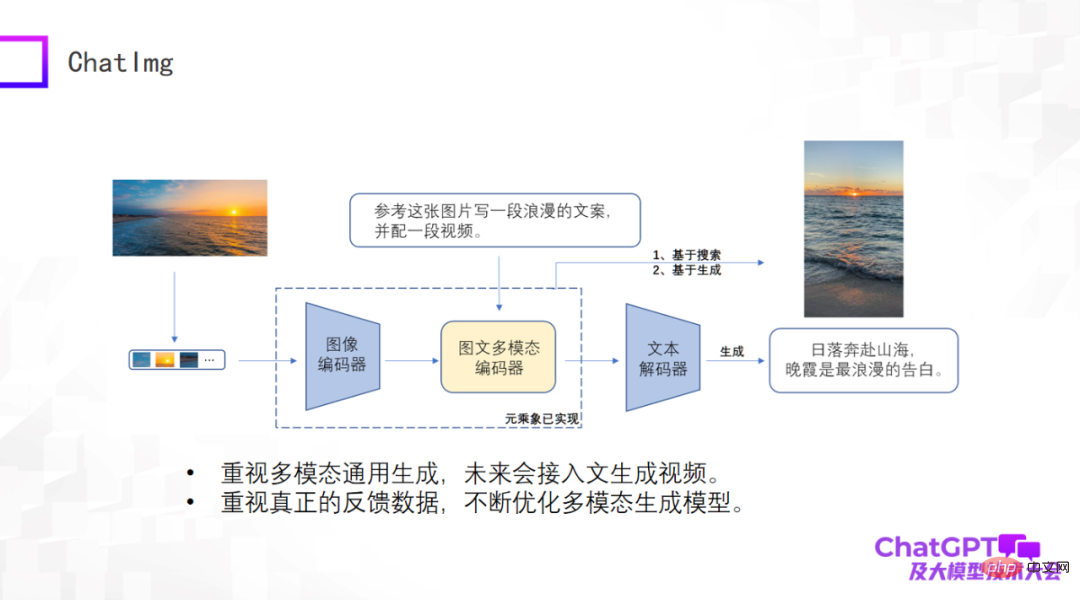
L'un des plus grands avantages de ChatImg est qu'il peut accepter l'entrée vidéo. Nous accordons une attention particulière à la génération générale multimodale, notamment la génération de texte, la génération d'images et la génération de vidéos. Nous espérons implémenter une variété de tâches de génération dans ce cadre, et espérons à terme accéder au texte pour générer des vidéos.
Deuxièmement, nous accordons une attention particulière aux données utilisateur réelles. Nous espérons optimiser continuellement le modèle de génération lui-même et améliorer ses capacités après avoir obtenu des données utilisateur réelles, nous avons donc publié l'application ChatImg.
Les images suivantes sont quelques exemples que nous avons testés. En tant que premier modèle, même s'il y a encore certaines choses qui ne sont pas bien faites, la compréhension globale des images par ChatImg est toujours bonne. Par exemple, ChatImg peut générer des descriptions de peintures dans des conversations et peut également effectuer un apprentissage en contexte.
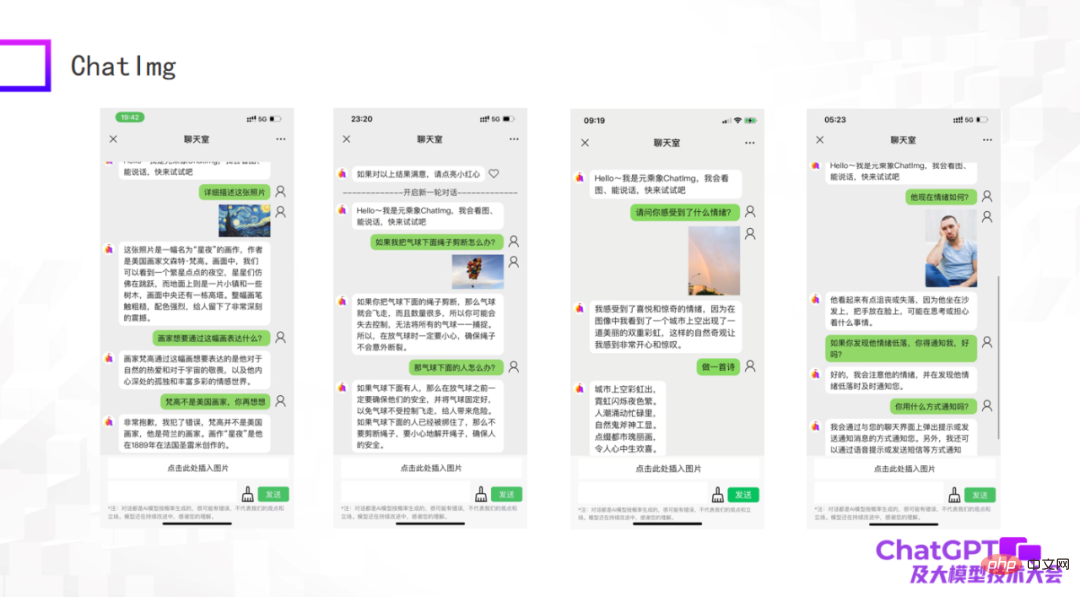
Le premier exemple dans l'image ci-dessus décrit le tableau "Nuit étoilée". Dans la description, ChatImg qualifie Van Gogh de peintre américain. Si vous lui dites que c'est faux, il peut le corriger immédiatement ; exemple ChatImg a fait des déductions physiques sur les objets de l'image ; le troisième exemple est une photo que j'ai prise moi-même, qui contenait deux arcs-en-ciel, et elle a été reconnue avec précision.
Nous avons remarqué que les troisième et quatrième exemples de l'image ci-dessus impliquent des problèmes émotionnels. Ceci est en fait lié au travail que nous devons faire ensuite. Nous souhaitons connecter ChatImg au robot. Les robots d'aujourd'hui sont généralement passifs et toutes les instructions sont prédéfinies, ce qui les rend très rigides. Nous espérons que les robots connectés à ChatImg pourront communiquer activement avec les gens. Comment faire cela ? Tout d'abord, le robot doit être capable de ressentir les gens. Il peut s'agir de voir objectivement l'état du monde et les émotions des gens, ou bien d'obtenir une réflexion. Ce n'est qu'alors que le robot peut comprendre et communiquer activement avec les gens. A travers ces deux exemples, je sens que cet objectif est réalisable.
Enfin, permettez-moi de résumer le rapport d’aujourd’hui. Tout d'abord, ChatGPT et GPT-4 ont apporté l'innovation au paradigme de recherche. Nous devrions tous adopter activement ce changement. Nous ne pouvons pas nous plaindre ou justifier le manque de ressources. Tant que nous sommes confrontés à ce changement, il existe toujours des moyens. pour surmonter les difficultés. La recherche multimodale ne nécessite même pas de machines comportant des centaines de cartes. Tant que des stratégies correspondantes sont adoptées, un petit nombre de machines peuvent faire du bon travail. Deuxièmement, les modèles génératifs multimodaux existants ont tous leurs propres problèmes. GPT-4 n'a pas encore de version visuelle ouverte, et il y a encore une chance pour nous tous. De plus, je pense que GPT-4 a encore un problème, à savoir à quoi devrait finalement ressembler le modèle génératif multimodal. Il ne donne pas de réponse parfaite (en fait, il ne révèle aucun détail de GPT-4). C'est en fait une bonne chose. Partout dans le monde, les gens sont très intelligents et chacun a ses propres idées. Cela pourrait créer une nouvelle situation de recherche où une centaine de fleurs s'épanouissent. Voilà pour mon discours, merci à tous.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI