
Maison >Périphériques technologiques >IA >Le modèle de dialogue bilingue open source gagne en popularité sur GitHub, affirmant que l'IA n'a pas besoin de corriger les absurdités
Le modèle de dialogue bilingue open source gagne en popularité sur GitHub, affirmant que l'IA n'a pas besoin de corriger les absurdités

- 王林avant
- 2023-04-24 17:49:091044parcourir
Cet article est réimprimé avec l'autorisation d'AI New Media Qubit (ID de compte public : QbitAI Veuillez contacter la source pour la réimpression
Le robot de conversation domestique ChatGLM est né le même jour que GPT-4).
Lancée conjointement par Zhipu AI et le laboratoire KEG de l'université Tsinghua, la version bêta interne alpha a été lancée.
Cette coïncidence a donné à Zhang Peng, fondateur et PDG de Zhipu AI, un sentiment complexe indescriptible. Mais voyant à quel point la technologie OpenAI est devenue géniale, ce vétéran technique qui était engourdi par les nouveaux développements de l'IA est soudainement redevenu enthousiasmé.
Surtout en suivant la diffusion en direct de la conférence GPT-4, il a regardé l'image à l'écran, a souri pendant un moment, a regardé une autre section et a souri pendant un moment.
Depuis sa création, Zhipu AI, dirigée par Zhang Peng, est membre du domaine des grands modèles et a défini une vision consistant à « faire en sorte que les machines pensent comme les humains ».
Mais cette route est toujours cahoteuse. Comme presque toutes les grandes entreprises modèles, elles rencontrent les mêmes problèmes : manque de données, manque de machines et manque d’argent. Heureusement, certaines organisations et entreprises offrent une assistance gratuite tout au long du processus.
En août de l'année dernière, la société s'est associée à un certain nombre d'instituts de recherche scientifique pour développer le grand modèle de langage open source bilingue pré-entraîné GLM-130B, qui peut être proche ou égal à GPT-3 175B (davinci) en termes d'indicateurs d'exactitude et de malveillance, qui constitueront plus tard la base de ChatGLM. La version ChatGLM-6B, dotée de 6,2 milliards de paramètres, est également open source en même temps que ChatGLM, qui peut être exécutée avec une seule carte pour 1 000 yuans.
En plus du GLM-130B, un autre produit célèbre de Zhipu est le pool de talents IA AMiner, qui est joué par de grands noms du monde universitaire :
Cette fois, il est entré en collision avec GPT-4 le même jour, La vitesse et la technologie d'OpenAI mettent Zhang Peng et l'équipe Zhipu sous beaucoup de pression.
Est-ce que les « absurdités graves » doivent être corrigées ?
Après le test bêta interne de ChatGLM, Qubit a immédiatement obtenu le quota et a lancé une vague d'évaluations humaines.
Ne parlons de rien d'autre. Après plusieurs séries de tests, il n'est pas difficile de constater que ChatGLM possède une compétence que ChatGPT et New Bing possèdent :
dire sérieusement des bêtises, y compris, mais sans s'y limiter, parler de poulets et de lapins. dans la même cage. Le calcul dans la question est de -33 poussins.
Pour la plupart des gens qui considèrent l'IA conversationnelle comme un « jouet » ou un assistant de bureau, la manière d'améliorer la précision est un point de préoccupation et d'importance particulière.
L'IA de dialogue dit sérieusement des bêtises, pouvez-vous le corriger ? Faut-il vraiment le corriger ?

△Citations absurdes classiques de ChatGPT
Zhang Peng a exprimé son opinion personnelle et a déclaré que corriger cette "maladie tenace" est une chose très étrange en soi.
(Assurez-vous que tout ce que vous dites est correct) Même les humains ne peuvent pas faire cela, mais ils veulent qu'une machine artificielle ne commette pas une telle erreur.
Les différents points de vue sur ce sujet sont étroitement liés à la compréhension des machines par différentes personnes. Selon Zhang Peng, ceux qui critiquent l'IA pour ce comportement ont peut-être toujours eu une compréhension méticuleuse des machines. Ils sont soit 0, soit 1, stricts et précis. Les personnes qui défendent ce concept croient inconsciemment que les machines ne sont pas capables de le faire. devrait et ne peut pas faire d’erreurs.
Savoir ce qui se passe est aussi important que savoir pourquoi. "Cela peut être dû au manque de compréhension approfondie de chacun de l'évolution et des changements de l'ensemble de la technologie, ainsi que de la nature de la technologie utilisée par Zhang Peng." l'apprentissage humain comme analogie :
Technologie IA La logique et les principes simulent encore en réalité le cerveau humain.
Face à ce qui a été appris, premièrement, les connaissances elles-mêmes peuvent être erronées ou mises à jour (comme l'altitude du mont Everest), deuxièmement, il y a aussi la possibilité de conflits entre les connaissances apprises, troisièmement, les gens l'ont toujours fait ; Lorsqu'elle fait des erreurs ou de la confusion,
L'IA fait des erreurs tout comme les gens font des erreurs. La raison en est le manque de connaissances ou la mauvaise application de certaines connaissances.
En bref, c'est une chose normale.
Dans le même temps, Zhipu est bien sûr attentif au virage silencieux d'OpenAI vers CloseAI.
De GPT-3 pour choisir une source fermée, à GPT-4 pour dissimuler davantage de détails au niveau architectural Les deux raisons de la réponse externe d'OpenAI sont la concurrence et la sécurité.
Zhang Peng a exprimé sa compréhension des intentions d’OpenAI.
"Alors en prenant la voie de l'open source, Zhipu n'aura-t-il pas des considérations de concurrence et de sécurité ?"
"Il y en aura certainement. Mais le code source fermé peut-il définitivement résoudre le problème de sécurité ? Je ne pense pas. Et je crois que c'est intelligent Les gens dans le monde La concurrence est un grand catalyseur pour le progrès rapide de l'ensemble de l'industrie et de l'écosystème. « Par exemple, rivaliser avec OpenAI, même s'il ne fait que rattraper son retard, fait également partie de la concurrence.Le rattrapage ici est un processus de déclaration, basé sur la conviction que l'orientation de recherche d'OpenAI est le seul moyen d'atteindre d'autres objectifs, mais rattraper OpenAI n'est pas le but ultime.
Le rattrapage ne signifie pas que nous pouvons nous arrêter ; le processus de rattrapage ne signifie pas que nous devons copier le modèle de la Silicon Valley tel qu'il est. Nous pouvons même utiliser les caractéristiques et les avantages de la Chine en matière de mobilisation du design de haut niveau. Concentrez-vous sur les grandes choses, afin que nous puissions compenser la différence de vitesse de développement.
Bien que nous ayons plus de 4 ans d'expérience de 2019 à aujourd'hui, Zhipu n'ose pas donner de conseils sur les pièges. Cependant, Zhipu comprend l'orientation générale. C'est aussi l'idée commune révélée par Zhipu dont ils discutent avec le CCF -
La naissance de la technologie des grands modèles est un projet systématique très complet et complexe.
Il ne s'agit plus seulement de quelques têtes intelligentes réfléchissant en laboratoire, laissant tomber quelques cheveux, faisant des expériences et publiant des articles. En plus de l'innovation théorique originale, cela nécessite également de solides capacités de mise en œuvre et de systématisation de l'ingénierie, voire de bonnes capacités de produit.
Tout comme ChatGPT, choisissez le scénario approprié, configurez et emballez un produit qui peut être utilisé par des personnes aussi âgées que 80 ans et aussi jeunes que 8 ans.
La puissance de calcul, les algorithmes et les données s'appuient tous sur des talents, notamment des praticiens de l'ingénierie système, qui sont bien plus importants que par le passé.
Sur la base de cette compréhension, Zhang Peng a révélé que l'ajout d'un système de connaissances (graphe de connaissances) au domaine des grands modèles et permettre aux deux de fonctionner systématiquement comme les cerveaux gauche et droit est la prochaine étape dans la recherche et les expériences de graphes intelligents.
Le modèle de conversation bilingue le plus populaire de GitHub
ChatGLM fait globalement référence aux idées de conception de ChatGPT.
C'est-à-dire que la pré-formation au code est injectée dans le modèle de base bilingue GLM-130B et que l'alignement des intentions humaines est obtenu grâce à un réglage fin supervisé et à d'autres technologies (c'est-à-dire rendre les réponses de la machine conformes aux valeurs humaines et aux valeurs humaines). attentes).
Le GLM-130B avec 130 milliards de paramètres est développé conjointement par Zhipu et le laboratoire KEG de l'université Tsinghua. Différent de l'architecture de BERT, GPT-3 et T5, GLM-130B est un modèle de pré-entraînement autorégressif contenant plusieurs fonctions objectives.
En août de l'année dernière, le GLM-130B a été rendu public et open source en même temps. Selon le rapport Standford, ses performances sur plusieurs tâches sont remarquables.
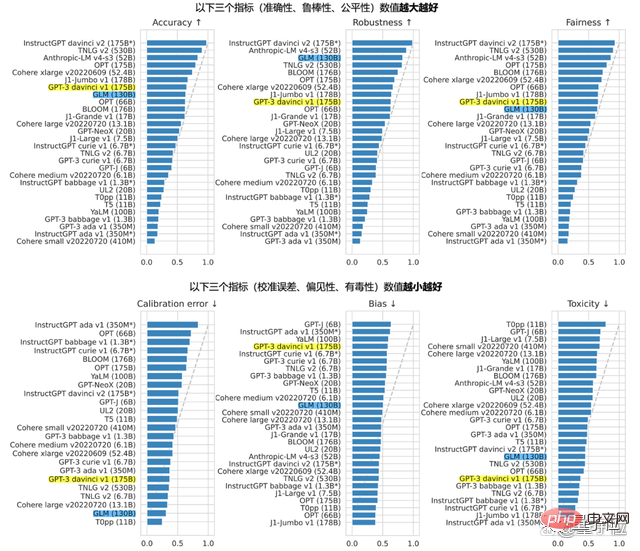
L'insistance sur l'open source vient du fait que Zhipu ne veut pas être un pionnier solitaire sur la route de l'AGI.
C'est aussi la raison pour laquelle nous continuerons à ouvrir le ChatGLM-6B cette année après avoir ouvert le GLM-130B.
ChatGLM-6B est une "version réduite" du modèle, avec une taille de 6,2 milliards de paramètres. La base technique est la même que celle de ChatGLM, et il a commencé à avoir des fonctions de questions-réponses et de dialogue en chinois.
Continuez à l'open source pour deux raisons.
L'une consiste à élargir l'écologie des modèles pré-entraînés, à attirer davantage de personnes pour investir dans la recherche sur de grands modèles et à résoudre de nombreux problèmes de recherche existants ; valeur ultérieure.
Rejoindre la communauté open source est vraiment attractif. Quelques jours après les tests internes de ChatGLM, ChatGLM-6B avait 8,5 000 étoiles sur GitHub, se hissant une fois à la première place de la liste des tendances.
 De cette conversation, Qubit a également entendu cette voix du praticien en face de moi :
De cette conversation, Qubit a également entendu cette voix du praticien en face de moi :
Les bugs sont également fréquents, mais les gens ne sont pas satisfaits du ChatGPT lancé par OpenAI, et du robot de conversation Google Bard, Baidu Le niveau de tolérance de Wenxinyiyan varie considérablement.
C'est à la fois juste et injuste.
D'un point de vue purement technique, les critères de jugement sont différents, ce qui est injuste ; mais les grandes entreprises comme Google et Baidu occupent plus de ressources, donc tout le monde a naturellement le sentiment qu'elles ont des capacités techniques plus fortes et peuvent fabriquer de meilleurs produits. de quelque chose, plus les attentes sont élevées.
"J'espère que tout le monde pourra être plus patient, que ce soit avec Baidu, nous ou d'autres institutions."
 En plus de ce qui précède, dans cette conversation, Qubit a également parlé spécifiquement avec Zhang Peng Parlez de votre expérience avec ChatGLM.
En plus de ce qui précède, dans cette conversation, Qubit a également parlé spécifiquement avec Zhang Peng Parlez de votre expérience avec ChatGLM.
Une transcription de la conversation est jointe ci-dessous. Pour faciliter la lecture, nous l'avons édité et organisé sans changer le sens original.
Conversation Record
Qubit : L'étiquette donnée à la version bêta interne ne semble pas si "universelle". Le site officiel définit trois cercles pour ses domaines applicables, à savoir l'éducation, les soins médicaux et la finance.
Zhang Peng : Cela n'a rien à voir avec les données d'entraînement, compte tenu principalement de ses scénarios d'application.
ChatGLM est similaire à ChatGPT et est un modèle de conversation. Quels domaines d’application sont naturellement plus proches des scénarios conversationnels ? Comme le service client, comme la consultation d’un médecin ou comme les services financiers en ligne. Dans ces scénarios, la technologie ChatGLM est plus adaptée pour jouer un rôle.
Qubit : Mais dans le domaine médical, les personnes qui souhaitent consulter un médecin sont encore plus prudentes à l'égard de l'IA.
Zhang Peng : Vous ne pouvez certainement pas simplement utiliser le grand modèle pour attaquer ! (Rires) Si l’on veut remplacer complètement les humains, il faut quand même être prudent.
À ce stade, il n'est pas utilisé pour remplacer le travail des personnes, mais plutôt comme un rôle de soutien, fournissant des suggestions aux praticiens pour améliorer l'efficacité du travail.
Qubit : Nous avons lancé le lien papier GLM-130B vers ChatGLM et lui avons demandé de résumer brièvement le sujet. Il a continué à buzzer pendant un long moment, mais il s'est avéré qu'il ne s'agissait pas du tout de cet article.
Zhang Peng : Le paramétrage de ChatGLM est tel qu'il ne peut pas obtenir de liens. Il ne s'agit pas d'une difficulté technique, mais d'un problème de limites du système. Principalement d'un point de vue sécurité, nous ne voulons pas qu'il accède arbitrairement aux liens externes.
Vous pouvez essayer de copier le texte papier 130B et de le jeter dans la zone de saisie. Généralement, vous ne direz pas de bêtises.
Qubit : Nous avons également jeté une poule et un lapin dans la même cage, et calculé -33 poules.
Zhang Peng : En termes de traitement mathématique et de raisonnement logique, il présente encore certains défauts et ne peut pas être si bon. Nous avons en fait écrit à ce sujet dans les instructions de la bêta fermée.

Qubit : Quelqu'un sur Zhihu a fait une évaluation, et la capacité à écrire du code semble être moyenne.
Zhang Peng : Quant à la capacité d'écrire du code, je pense qu'elle est plutôt bonne ? Je ne sais pas quelle est votre méthode de test. Mais cela dépend de qui vous comparez. Par rapport à ChatGPT, ChatGLM lui-même n'investit peut-être pas autant dans les données de code.
Tout comme la comparaison entre ChatGLM et ChatGLM-6B, ce dernier n'a que 6B (6,2 milliards) de paramètres en termes de capacités globales, telles que la logique globale, l'illusion lors de la réponse et la longueur, l'écart entre la version réduite et la version réduite. la version originale est évidente.
Mais la « version réduite » peut être déployée sur des ordinateurs ordinaires, apportant une plus grande convivialité et un seuil plus bas.
Qubit : Il a un avantage. Il a une bonne compréhension des nouvelles informations. Je sais que l'actuel PDG de Twitter est Musk, et je sais aussi que He Kaiming est revenu dans le monde universitaire le 10 mars - même si je ne le sais pas. GPT-4 a été publié, Ha ha.
Zhang Peng : Nous avons effectué un traitement technique spécial.
Qubit : Qu'est-ce que c'est ?
Zhang Peng : Je n’entrerai pas dans les détails précis. Mais il existe des moyens de traiter de nouvelles informations relativement récentes.
Qubit : Pourriez-vous nous dire le coût ? Le coût de la formation GLM-130B est encore de plusieurs millions. Quel est le coût d'une série de questions et réponses sur ChatGLM ?
Zhang Peng : Nous avons testé et estimé grossièrement le coût, qui est similaire au coût annoncé par OpenAI pour l'avant-dernière fois, et légèrement inférieur à eux.
Mais la dernière offre d'OpenAI a été réduite à 10 % du prix initial, soit seulement 0,002 $/750 mots, ce qui est inférieur à la nôtre. Ce coût est en effet étonnant. On estime qu'ils ont procédé à la compression, à la quantification, à l'optimisation du modèle, etc., sinon il ne serait pas possible de le réduire à un niveau aussi bas.
Nous faisons également des choses connexes et espérons réduire les coûts.
Qubits : à terme, pourront-ils être aussi bas que le coût de recherche ?
Zhang Peng : Quand va-t-il descendre à un niveau aussi bas ? Je ne sais pas non plus. Cela prendra du temps.
J'ai déjà vu le calcul du coût moyen par prix de recherche, qui est en fait lié à l'activité principale. Par exemple, l’activité principale des moteurs de recherche étant la publicité, les revenus publicitaires totaux doivent être utilisés comme limite supérieure pour calculer les coûts. Si on le calcule de cette manière, ce qui doit être pris en compte n’est pas le coût de la consommation, mais le point d’équilibre entre les bénéfices et les bénéfices des entreprises.
Faire de l'inférence de modèle nécessite une puissance de calcul de l'IA, ce qui est nettement plus coûteux que la recherche utilisant uniquement la puissance de calcul du processeur. Mais tout le monde travaille dur et de nombreuses personnes ont avancé des idées, comme continuer à compresser et quantifier le modèle.
Certaines personnes souhaitent même convertir le modèle et le laisser fonctionner sur le processeur, car le processeur est moins cher et a un volume plus important. S'il fonctionne, le coût diminuera considérablement.
Qubit : Enfin, j'aimerais parler de quelques sujets sur le talent. Maintenant, tout le monde se bat pour les grands modèles. Zhipu craint-il de ne pas pouvoir recruter des gens ?
Zhang Peng : Nous sommes nés du projet technologique de Tsinghua KEG et avons toujours eu de bonnes relations avec diverses universités. De plus, l'entreprise a une ambiance relativement ouverte envers les jeunes. 75 % de mes collègues sont des jeunes. Je suis considéré comme un vieux. Les grands talents mannequins sont effectivement une denrée rare à l’heure actuelle, mais nous n’avons pas encore de soucis de recrutement.
D’un autre côté, nous craignons en réalité davantage d’être exploités par les autres.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI