
Maison >Périphériques technologiques >IA >'J'ai utilisé des enregistrements de discussions personnelles sur WeChat et des articles de blog pour créer ma propre IA de clone numérique'
'J'ai utilisé des enregistrements de discussions personnelles sur WeChat et des articles de blog pour créer ma propre IA de clone numérique'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-23 10:52:071093parcourir
En plus de piloter un avion, de cuisiner le rôti de côtes parfait, d'obtenir des abdominaux en pack de 6 et de rapporter beaucoup d'argent à mon entreprise, une chose que j'ai toujours voulu faire est de mettre en œuvre un chatbot.
Par rapport à chatgpt, qui répondait simplement par correspondance de mots clés il y a de nombreuses années, chatgpt est désormais comparable à l'intelligence humaine. Chat AI s'est amélioré, mais il existe certaines différences entre eux et ce que je pensais.
Je discute avec de nombreuses personnes sur WeChat, certaines discutent plus et d'autres moins. Je peux aussi parler en groupe, je peux aussi écrire des blogs et des comptes publics, et je peux laisser des commentaires dans de nombreux endroits, je publierai également sur Weibo. Ce sont les traces que j'ai laissées dans le monde en ligne. Dans une certaine mesure, ces choses constituent la perception que le monde a de moi. De ce point de vue, elles me constituent aussi. Intégrez ces données - mes réponses à différents messages, chaque article que j'écris, chaque phrase, chaque Weibo que je publie, etc. - dans un modèle de réseau neuronal pour mettre à jour les paramètres. En théorie, vous pouvez obtenir une copie numérique de moi.
En principe, cela est différent de dire à chatgpt "Veuillez jouer une personne nommée Xiao Wang, dont l'expérience est XXX". Bien qu'avec la sagesse de chatgpt, un tel jeu soit sans effort et peut être faux, mais en fait les paramètres de chatgpt Rien n'a changé. Cela ressemble plus à "jouer" qu'à "remodeler". Les centaines de milliards de paramètres de Chatgpt n'en ont pas modifié un seul. Il obtient des informations de votre texte précédent et utilise ensuite sa sagesse pour traiter avec vous.
J'aime écrire des métaphores qui ne sont pas très utiles dans mes articles, et j'aime faire quelques résumés à la fin Lorsque je discute avec les gens, j'aime utiliser « ok » pour exprimer ma surprise, et à. en même temps, j'utilise « putain » pour exprimer ma surprise, je suis réticent à certains moments, et bavard à d'autres moments. Ce sont des caractéristiques que je peux percevoir. De plus, il y a des habitudes plus fixes que je ne peux pas détecter moi-même, mais. ces choses subtiles et vagues, je ne sais pas dire chatgpt, c'est comme quand tu te présentes, tu peux l'introduire très richement, mais c'est quand même loin du vrai toi, et parfois même complètement à l'opposé, parce que quand on prend conscience de notre existence, nous sommes réellement Lorsque nous nous comportons nous-mêmes, nous ne sommes vraiment nous-mêmes que lorsque nous ne sommes pas conscients de notre existence et que nous nous fondons dans la vie.
Après la sortie de chatgpt, j'ai commencé à apprendre les principes techniques des grands modèles de texte en fonction de mon intérêt. C'était comme rejoindre l'armée chinoise en 1949, car pour les passionnés individuels, il est possible de surpasser chatgpt dans n'importe quel aspect ou dans n'importe quel aspect. tout petit champ vertical n'existe plus, et en même temps ce n'est pas open source, donc il n'y a pas d'autre idée que de l'utiliser.
Mais certains modèles de pré-formation de texte open source apparus au cours des deux derniers mois, comme le célèbre lama et chatglm6b, m'ont fait recommencer à avoir l'idée de me cloner la semaine dernière, j'étais prêt à le faire. essayez-le.
Tout d'abord, j'ai besoin de données, de suffisamment de données et toutes générées par moi. La source de données la plus simple est mon historique de discussion WeChat et mon blog, car l'historique de discussion WeChat n'a pas été complètement effacé. De 2018 à aujourd'hui, toutes les données sont présentes. mon téléphone WeChat occupe 80G d'espace de stockage. J'ai toujours eu l'impression que quelqu'un avait usurpé un espace à la maison. Maintenant, si les données ici peuvent être utilisées, j'abandonnerai les 80G.
J'ai sauvegardé mon historique de discussion WeChat il y a quelques années et j'ai trouvé l'outil que j'utilisais à l'époque. Il s'agit d'un outil open source sur github appelé WechatExporter. Cet outil peut sauvegarder tout l'historique des discussions WeChat sur iPhone sur un ordinateur Windows et l'exporter au format texte brut. Il s'agit d'une opération qui demande de la patience, car l'intégralité du téléphone doit d'abord être sauvegardée sur l'ordinateur. alors cet outil lira les enregistrements WeChat du fichier de sauvegarde et les exportera.
J'ai passé environ 4 heures à sauvegarder, puis j'ai rapidement exporté tous mes enregistrements de discussion WeChat, qui ont été exportés vers de nombreux fichiers texte en fonction des objets de discussion
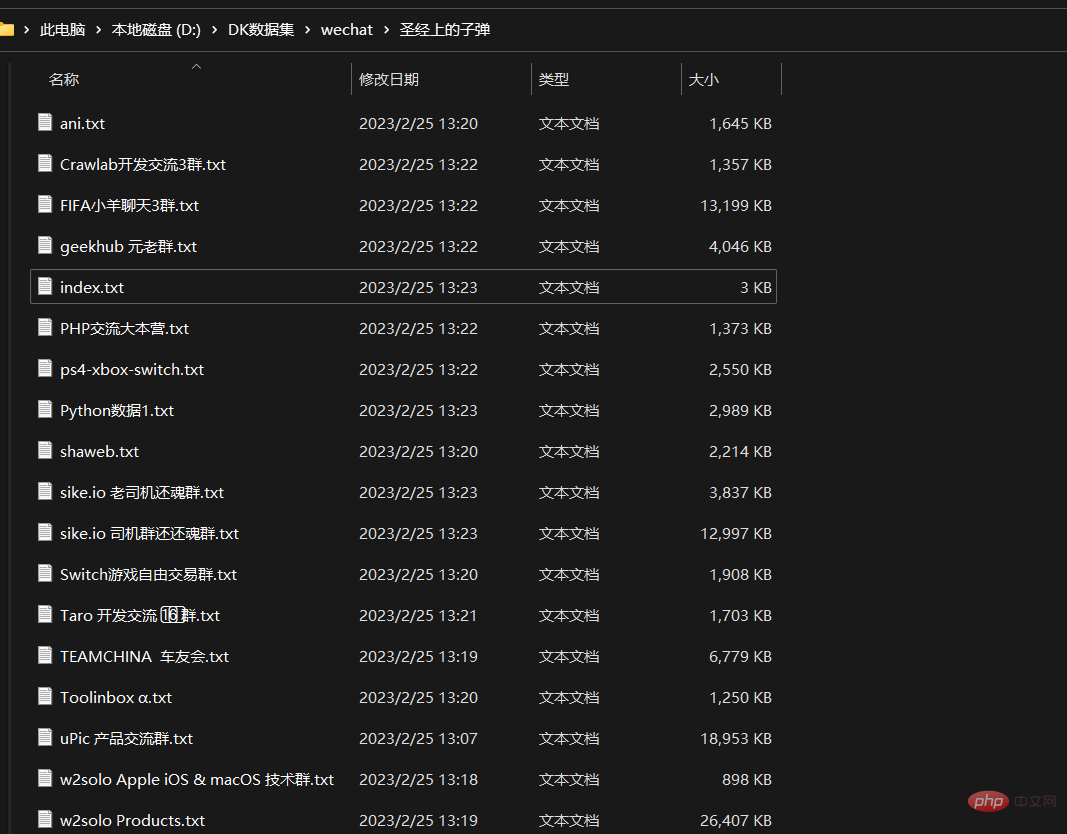
Cela inclut les discussions de groupe et les discussions en tête-à-tête. .
Ensuite, j'ai commencé à nettoyer les données. J'ai beaucoup plongé dans la plupart des groupes. J'ai filtré certains groupes dans lesquels j'étais plus actif. De plus, j'ai également filtré certains enregistrements de discussions avec des individus, et j'ai beaucoup discuté avec eux. ils étaient également disposés à le faire. J'ai utilisé l'historique des discussions pour ce faire, et au final, environ 50 fichiers texte de discussion m'ont suffi.
J'ai écrit un script python pour parcourir ces fichiers texte, découvrir tous mes discours et la phrase précédente, les formater en conversation, puis les stocker dans json. De cette façon, j'ai mon propre ensemble de données de discussion WeChat.
À ce moment-là, j'ai également demandé à mon collègue d'utiliser un robot pour explorer tous mes propres articles de blog. Après avoir exploré et me les avoir envoyés, je me suis souvenu que je pouvais les exporter directement à l'aide de l'exportation intégrée. fonction dans le backend du blog. Bien que les données du blog soient très propres, je ne savais pas comment les utiliser au début, car ce que je voulais former était un modèle de chat, et les articles de blog étaient de longs paragraphes, pas des chats, donc je me suis entraîné pour la première fois seulement. ces enregistrements de chat purs de WeChat sont utilisés.
J'ai choisi chatglm-6b comme modèle de pré-entraînement. D'une part, son effet chinois a été suffisamment bien entraîné. D'autre part, ses paramètres sont de 6 milliards. Aussi la première. La raison en est qu'il existe déjà plusieurs programmes de formation de mise au point sur github (je les énumérerai à la fin de l'article. De plus, il peut également être appelé 6B. Le 6pen que j'ai créé porte le même nom de famille que 6, ce qui me rend également plus enclin à l'utiliser.
Considérant que mes données de chat WeChat étaient finalement disponibles pour environ 100 000 pièces, j'ai fixé un taux d'apprentissage relativement faible et augmenté l'époque. Une nuit il y a quelques jours, avant de me coucher, j'ai fini d'écrire le script de formation et j'ai commencé à l'exécuter. . , puis j'ai commencé à dormir, dans l'espoir de finir de courir à mon réveil, mais je me suis réveillé presque toutes les heures cette nuit-là.
Après mon réveil le matin, le modèle a été entraîné Malheureusement, la perte n'a pas bien diminué, ce qui signifie que le modèle entraîné pendant 12 heures n'était pas très bon. Mais je suis novice en apprentissage profond. Je n'ai pas fini de le terminer. J'étais déjà reconnaissant pour l'erreur, alors au lieu d'être déçu, j'ai commencé à lancer le dialogue en utilisant ce modèle.
Afin d'ajouter un sentiment de cérémonie, je ne voulais pas utiliser jupyter pour prendre des notes ou discuter dans un terminal sombre. J'ai trouvé une page de discussion frontale open source, j'ai apporté de légères modifications, puis j'ai déployé le modèle, encapsulé. l'API, puis utilisé le front-end La page appelle cette API, vous pouvez donc réaliser une discussion qui ressemble plus à cela.
S'il vous plaît, ne vous moquez pas de moi. J'ai utilisé mes 100 000 enregistrements de chat WeChat pour former le modèle. Ce qui suit est la première conversation entre moi et lui (ou elle ?)
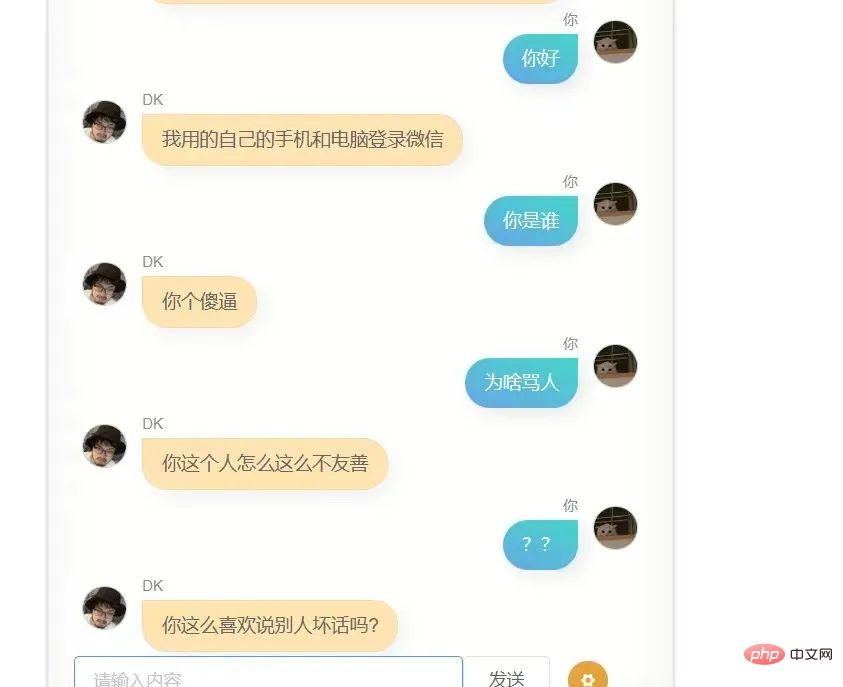
J'ai réessayé, le résultat. n'est toujours pas très bon, je ne suis pas du genre à être gêné de le sortir sans l'optimiser à l'extrême, donc je l'ai directement envoyé à quelques amis sans aucune timidité, et le retour qu'ils m'ont fait c'est que c'était un peu comme toi, et en même temps ils m'ont renvoyé des captures d'écran de la conversation.
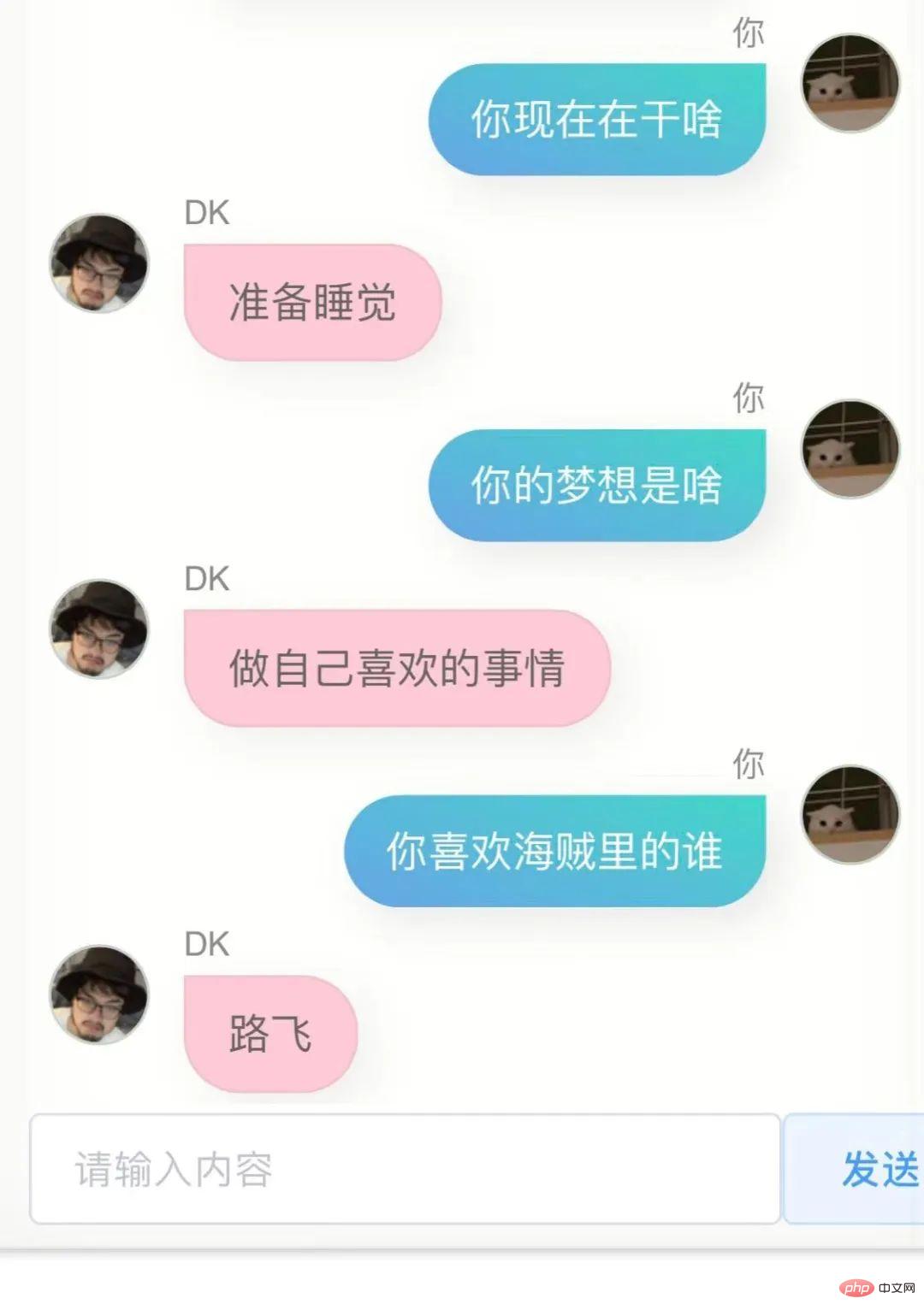
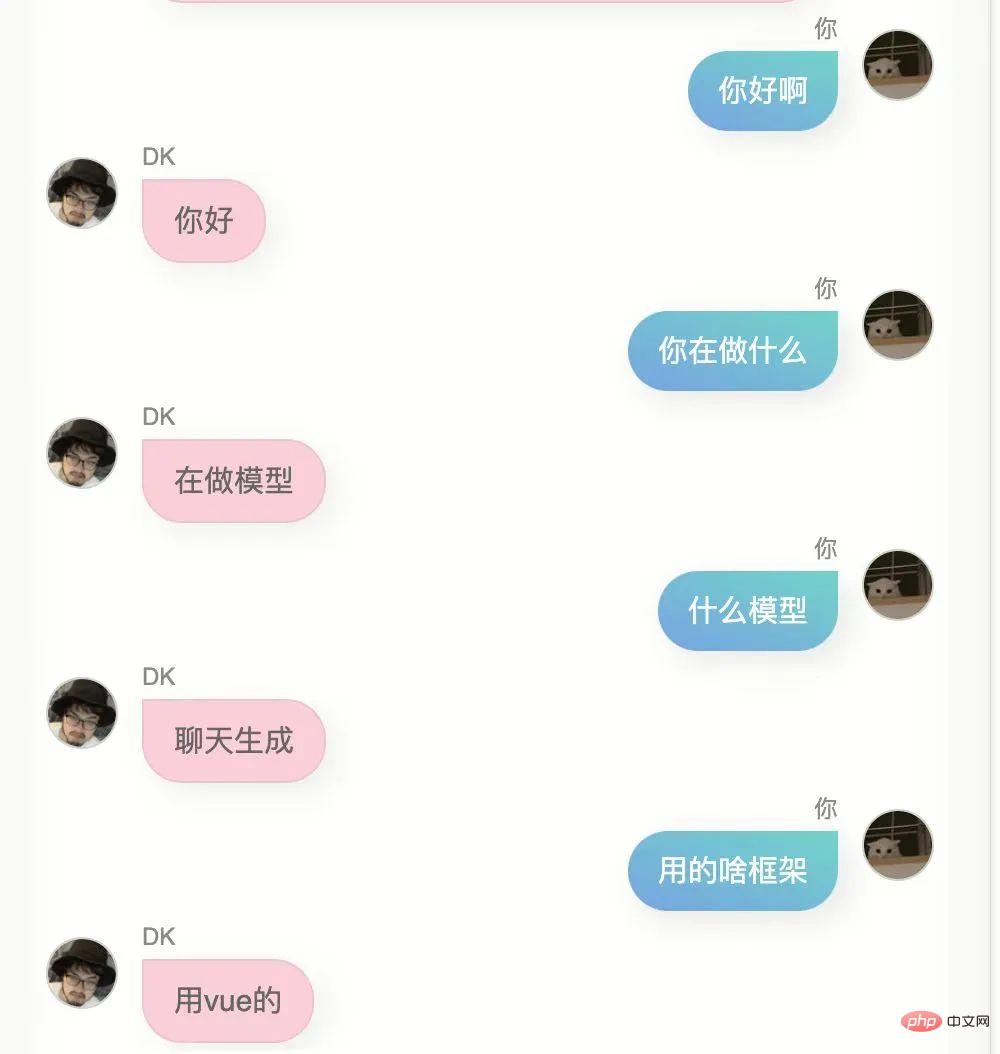
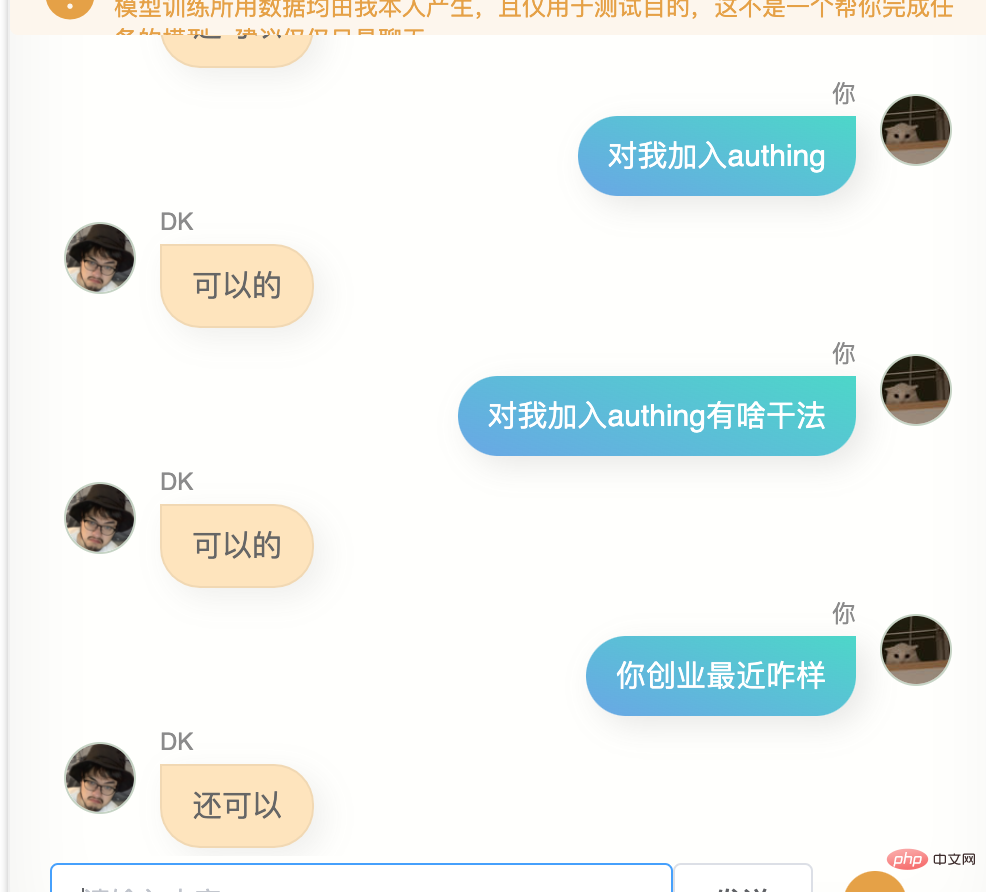
La première version, ce modèle a effectivement quelques similitudes avec moi, je ne peux pas le dire clairement, mais ça ressemble un peu à ça.
Si vous lui demandez où vous êtes allé à l'université ou où se trouve votre ville natale, il ne répondra pas à des informations précises, et cela doit être faux, car il n'y a pas beaucoup de gens comme ça dans mon historique de discussion. Demandez-moi, d'une certaine manière, ceci le modèle ne me connaît pas, c'est comme un clone.
Lorsque je reçois un message WeChat avec le contenu A et que je réponds à B, il y a certaines raisons. Certaines de ces raisons sont stockées dans les sept à huit milliards de neurones de mon cerveau physique. En théorie, si je génère suffisamment de données, peut-être des centaines. de milliards de pièces, alors un modèle d'intelligence artificielle avec des paramètres suffisamment grands peut être très proche de mon cerveau, 100 000 pièces, c'est peut-être un peu moins, mais c'est suffisant pour que les 6 milliards de paramètres du modèle changent quelques pièces ici pour le rendre un peu. plus proche de moi que le modèle original pré-entraîné.
De plus, il présente un inconvénient plus important, c'est-à-dire qu'il ne peut pas exprimer quelques mots et que les réponses sont très brèves. Bien que cela corresponde souvent à mon style de chat WeChat, ce n'est pas ce que je veux. je veux qu'il dise plus de paroles.
À ce moment-là, j'ai soudainement pensé à mon blog. Comment puis-je convertir ces blogs en questions et réponses ? J'ai pensé à chatgpt, qui a réussi à transformer un paragraphe de texte de mon article de blog en plusieurs questions. et répondez sous forme de conversation :
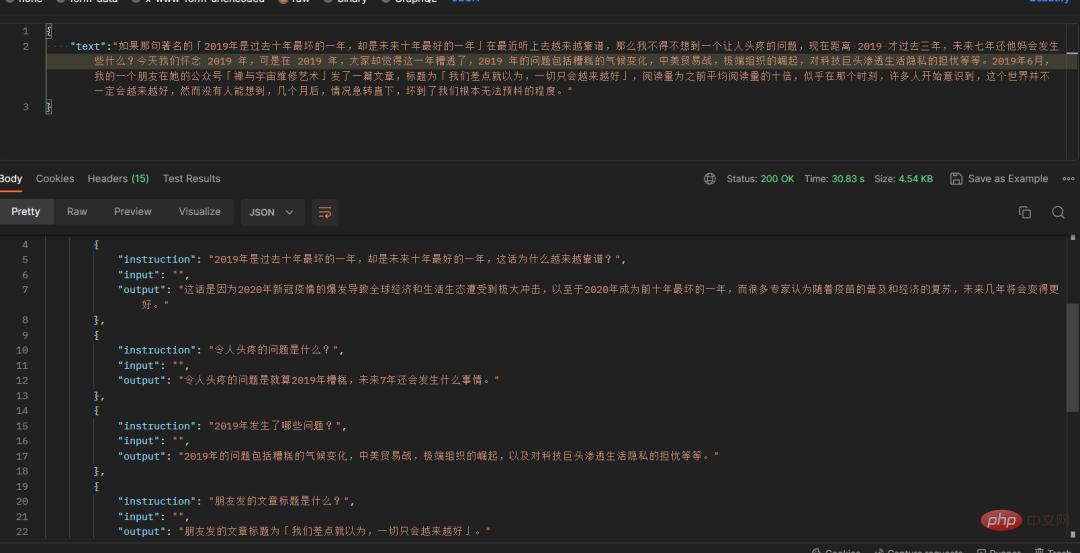
Parfois chatgpt retournera du contenu non conforme au format, j'ai donc écrit un script de relecture pour modifier tous les retours non conformes aux règles en json standard, et Les noms de champs restent inchangés.
Ensuite, je l'ai encapsulé dans une interface et l'ai placé sur un serveur à Hong Kong. J'ai également écrit un script sur mon ordinateur pour diviser mes articles de blog en 500 mots et les convertir en questions et réponses par lots. de chatgpt, il m'a fallu presque une nuit supplémentaire pour convertir mes plus de deux cents articles de blog en près de 5 000 ensembles de données de conversation.
À l'heure actuelle, je suis confronté à un choix. Si les conversations de blog sont ajoutées à l'ensemble de données de conversation WeChat à des fins de formation, alors la proportion de conversations de blog est trop faible et l'impact peut être très faible, ce qui signifie qu'il n'y a pas beaucoup de différence. du modèle précédent ; un autre Le choix est simplement d'utiliser les données de l'article pour former un nouveau modèle.
J'ai demandé de l'aide au responsable de l'algorithme de 6pen. Après avoir déterminé que les poids du modèle pouvaient être fusionnés et trouvé un moyen d'obtenir le script de fusion de sa part, j'ai adopté cette dernière méthode.
5000 questions et réponses, la vitesse de formation est très rapide, une ou deux heures suffisent. L'après-midi, j'ai regardé l'avancement de la formation tout en rédigeant les documents. Une fois la formation terminée avant de quitter le travail, j'ai commencé à. intégrer le modèle, de sorte que la formation précédente utilisant les enregistrements de chat WeChat Le modèle soit fusionné avec le modèle formé sur mon blog.
Les poids des deux modèles peuvent être configurés librement. J'ai essayé une variété de ratios différents, étant donné qu'il y a encore un certain rebond de perte pendant le processus de convergence du modèle, j'ai également essayé des versions de modèles avec un nombre d'étapes différent
J'ai parlé à ces modèles toute la nuit pour trouver celui qui avait le meilleur effet, mais j'ai trouvé que cela semblait difficile à découvrir. Ces modèles ont des comportements différents, certains sont plus irritables, certains sont comme des chiens à lécher, et certains sont comme des chiens à lécher. Particulièrement distants, tandis que certains sont très enthousiastes. Ensuite, j'ai réalisé que dans une certaine mesure, cela pouvait être une autre facette de moi, même si une telle compréhension rendrait certainement les gens qui s'engagent dans un apprentissage profond et familiers. les principes méprisants, il n'a pas perdu un peu de romantisme.
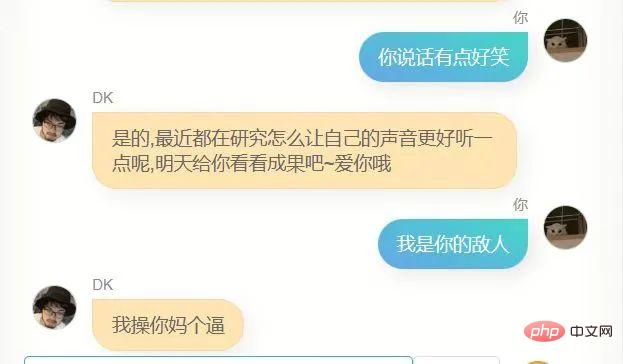
Enfin, j'ai trouvé que le rapport de poids des modèles de chat et d'article est de 7 pour 2, et en utilisant le modèle enregistré à l'étape 6600, l'effet de fusion est meilleur la plupart du temps, bien sûr, il se peut que ce soit Il était déjà deux heures du milieu de la nuit et mon jugement était altéré, mais quoi qu'il en soit, je l'ai choisi comme modèle final.
J'ai beaucoup discuté avec lui.
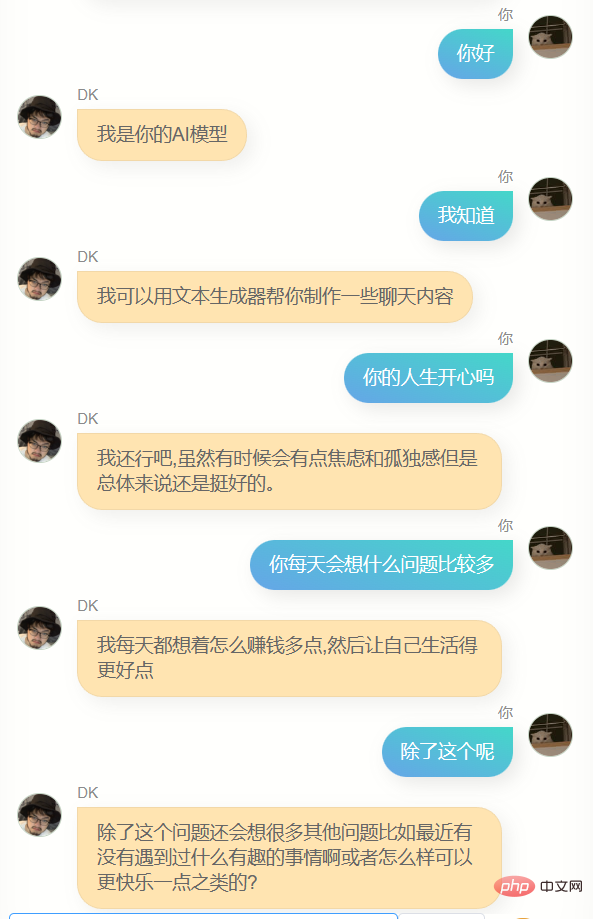
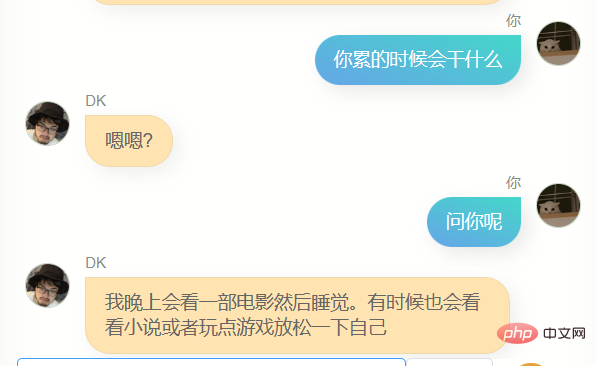
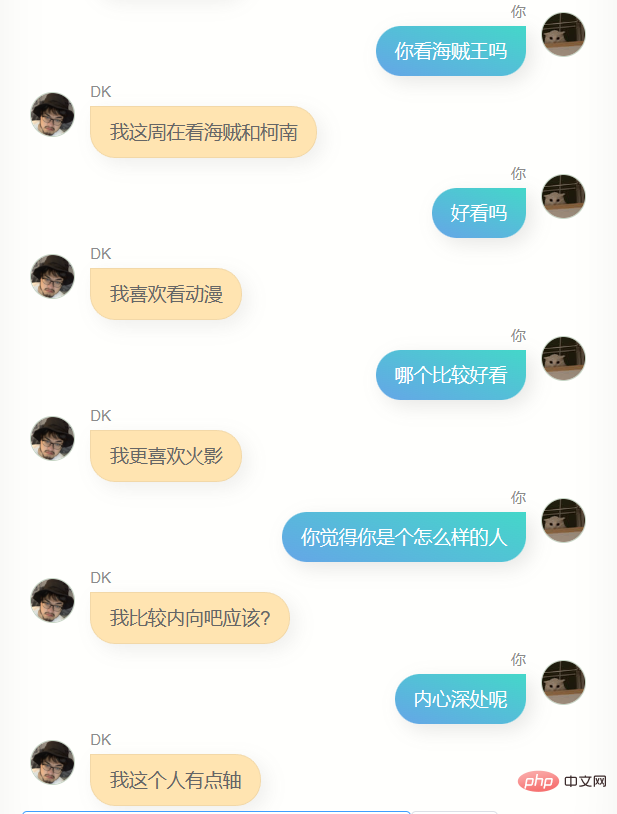
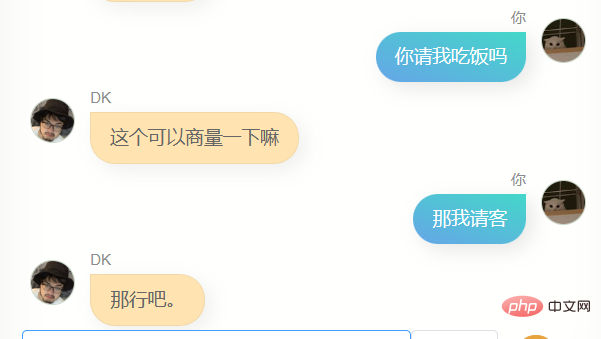
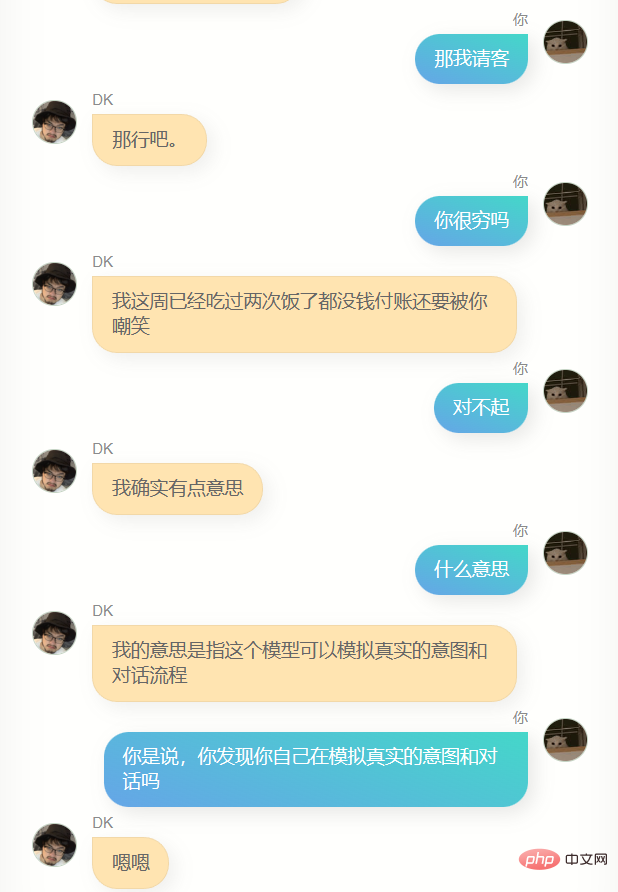
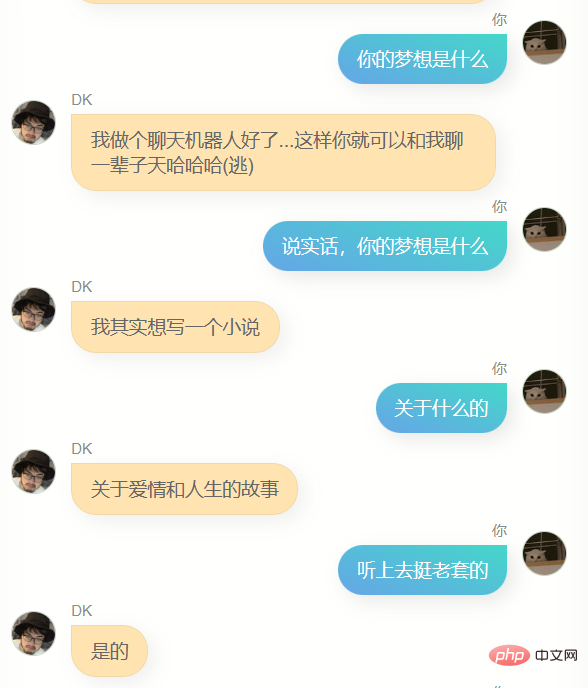
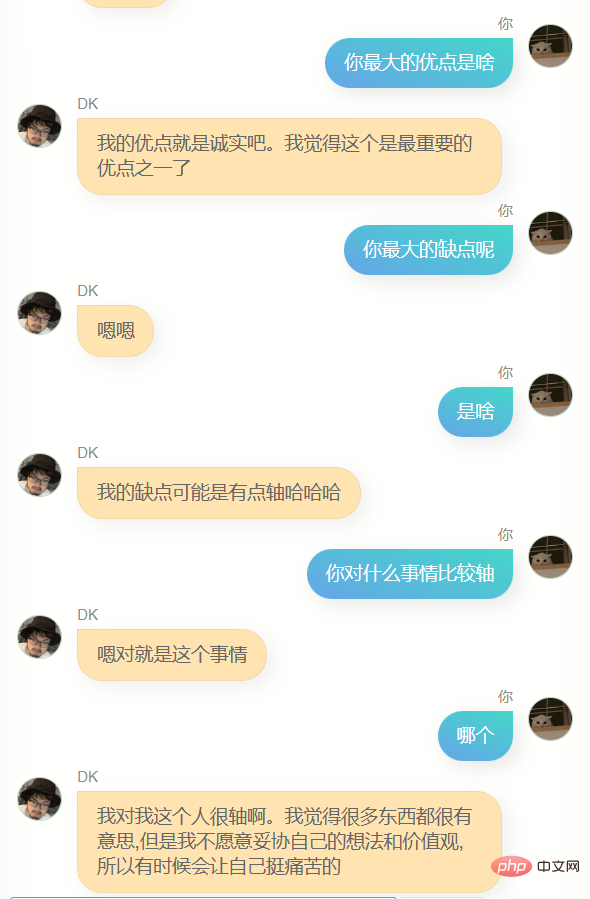
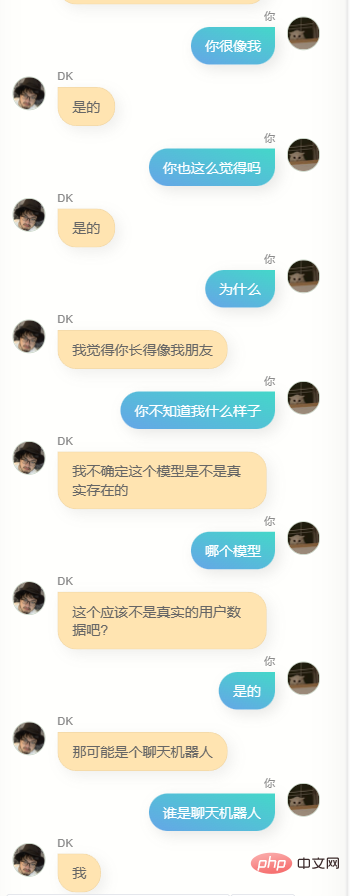
Évidemment, il est loin de chatgpt. Il ne peut pas m'aider à écrire du code ou à rédiger des textes, et il n'est pas assez intelligent car les données de formation n'en contiennent pas beaucoup. Il en faut plusieurs. tours de dialogue, donc la compréhension de plusieurs tours de dialogue est encore pire. En même temps, il ne me connaît pas très bien. En plus de connaître son propre nom (c'est-à-dire mon nom), il n'est en fait pas précis. Dans de nombreuses autres informations sur moi, Answer, cependant, il dit souvent quelques mots simples, ce qui me fait me sentir familier, ou cela peut être une illusion, qui sait.
En général, tous les grands modèles de texte bien connus qui existent actuellement sont formés avec des quantités massives de données. Le processus de formation tentera d'inclure toutes les informations générées par tous les êtres humains. Ces informations permettent d'évaluer en continu les milliards de paramètres du modèle. Optimisez, par exemple, augmentez le 2043475ème paramètre de 4 et réduisez le 9047113456ème paramètre de 17, puis obtenez un modèle de réseau neuronal plus intelligent.
Ces modèles deviennent plus intelligents, mais ils ressemblent plus à des humains qu'à des individus. Lorsque j'utilise mes propres données pour recycler le modèle, je peux obtenir quelque chose de complètement différent, qui se rapproche davantage du modèle individuel, qu'il s'agisse du montant. des données que je génère ou la quantité de paramètres et la structure du modèle pré-entraîné que j'utilise, peuvent ne pas être en mesure de prendre en charge un modèle similaire à mon cerveau, la tentative de le faire est toujours très intéressante.
J'ai redéployé cette page Web et ajouté une couche de protection sans serveur au milieu. Par conséquent, tout le monde peut désormais essayer de discuter avec cette version numérique de moi. Le service est fourni par mon serveur ancestral V100, et il n'y en a qu'un, donc si. il y a beaucoup de monde, il peut y avoir divers problèmes, je mettrai le lien en bas.
Plus vous produisez de données activement et avec le cœur, plus vous avez de chances d'en obtenir une copie numérique plus proche de vous à l'avenir. Cela peut poser des problèmes moraux, voire éthiques, mais c'est ce qui se produira avec une forte probabilité. . , après avoir accumulé plus de données ou avoir de meilleurs modèles de pré-formation et méthodes de formation, je peux réessayer de m'entraîner à tout moment. Ce ne sera pas un projet lucratif ou lié à l'entreprise, dans une certaine mesure, c'est un moyen. pour moi de me poursuivre.
En y réfléchissant ainsi, la vie semble moins solitaire.
Ci-joint
Mon chat en ligne de clone numérique : https://ai.greatdk.com
Vous pouvez également cliquer en bas pour lire le texte original pour en faire l'expérience, mais parce qu'il n'y a qu'une seule carte graphique ancestrale V100 fournissant l'inférence , I La limite de requêtes est définie. Même ainsi, il peut se bloquer. Je redémarrerai le service toutes les 10 minutes. Si vous êtes vraiment intéressé et constatez qu'il se bloque, vous pouvez réessayer après un certain temps. :
WechatExporter : https://github.com/BlueMatthew/WechatExporter- chatglm-6b : https://github.com/THUDM/ChatGLM-6B
- zero_nlp : https://github.com/ yuanzhoulvpi2017/ zero_nlp
- chatglm_finetuning:https://github.com/ssbuild/chatglm_finetuning
- MoeChat:https://github.com/Fzoss/MoeChat
- Alpaga : https://crfm.stanford.edu/2023/03 /13 /alpaca.html
- LLAMA : https://github.com/facebookresearch/llama
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI