
Maison >Java >javaDidacticiel >Analyse des problèmes courants et solutions de la file d'attente de messages Java RabbitMQ
Analyse des problèmes courants et solutions de la file d'attente de messages Java RabbitMQ

- 王林avant
- 2023-04-23 09:49:062307parcourir
Accumulation de messages
Le scénario de génération d'accumulation de messages :
La vitesse des messages générés par les producteurs est supérieure à la vitesse de consommation par les consommateurs. Solution : Augmenter le nombre ou la vitesse des consommateurs.
Quand il n'y a pas de consommateurs à consommer. Solution : file d'attente des lettres mortes, définition de la période de validité des messages. Cela équivaut à définir une période de validité pour nos messages. S'il n'y a pas de consommation dans le délai spécifié, elle expirera automatiquement. À son expiration, la méthode de surveillance du rappel client sera exécutée pour stocker le message dans l'enregistrement de la table de la base de données. l'indemnisation sera réalisée ultérieurement.
Garantie que les messages ne sont pas perdus
1 Le producteur utilise le mécanisme de confirmation de message pour garantir que le message peut être transmis à MQ à 100 % avec succès.
2. Le serveur MQ doit conserver le message sur le disque dur
3. Le consommateur utilise le mécanisme d'acquittement manuel pour confirmer que la consommation du message est réussie
Que dois-je faire si la capacité du serveur MQ est pleine ?
Utilisez la file d'attente des lettres mortes pour stocker les messages dans la base de données et compenser la consommation ultérieure.
File d'attente des lettres mortes
La file d'attente des lettres mortes RabbitMQ est communément appelée file d'attente de la roue de secours ; une fois que le middleware de messages a rejeté le message pour une raison quelconque, il peut également être transféré dans la file d'attente des lettres mortes pour le stockage. commutateurs et clés de routage, etc.
Contexte :
Le message délivré à MQ a expiré
La file d'attente a atteint la longueur maximale (le conteneur de file d'attente est plein) Le producteur a refusé de recevoir le message
Le consommateur n'a pas réussi à consommer plusieurs les messages, seront transférés et stockés dans la file d'attente des lettres mortes
Cas de code :
dépendance maven
<dependencies>
<!-- springboot-web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 添加springboot对amqp的支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<!--fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.49</version>
</dependency>
</dependencies>configuration yml
server:
# 服务启动端口配置
port: 8081
servlet:
# 应用访问路径
context-path: /
spring:
#增加application.druid.yml 的配置文件
# profiles:
# active: rabbitmq
rabbitmq:
####连接地址
host: www.kaicostudy.com
####端口号
port: 5672
####账号
username: kaico
####密码
password: kaico
### 地址
virtual-host: /kaicoStudy
###模拟演示死信队列
kaico:
dlx:
exchange: kaico_order_dlx_exchange
queue: kaico_order_dlx_queue
routingKey: kaico.order.dlx
###备胎交换机
order:
exchange: kaico_order_exchange
queue: kaico_order_queue
routingKey: kaico.orderclasse de configuration de la file d'attente
@Configuration
public class DeadLetterMQConfig {
/**
* 订单交换机
*/
@Value("${kaico.order.exchange}")
private String orderExchange;
/**
* 订单队列
*/
@Value("${kaico.order.queue}")
private String orderQueue;
/**
* 订单路由key
*/
@Value("${kaico.order.routingKey}")
private String orderRoutingKey;
/**
* 死信交换机
*/
@Value("${kaico.dlx.exchange}")
private String dlxExchange;
/**
* 死信队列
*/
@Value("${kaico.dlx.queue}")
private String dlxQueue;
/**
* 死信路由
*/
@Value("${kaico.dlx.routingKey}")
private String dlxRoutingKey;
/**
* 声明死信交换机
*
* @return DirectExchange
*/
@Bean
public DirectExchange dlxExchange() {
return new DirectExchange(dlxExchange);
}
/**
* 声明死信队列
*
* @return Queue
*/
@Bean
public Queue dlxQueue() {
return new Queue(dlxQueue);
}
/**
* 声明订单业务交换机
*
* @return DirectExchange
*/
@Bean
public DirectExchange orderExchange() {
return new DirectExchange(orderExchange);
}
/**
* 绑定死信队列到死信交换机
*
* @return Binding
*/
@Bean
public Binding binding() {
return BindingBuilder.bind(dlxQueue())
.to(dlxExchange())
.with(dlxRoutingKey);
}
/**
* 声明订单队列,并且绑定死信队列
*
* @return Queue
*/
@Bean
public Queue orderQueue() {
// 订单队列绑定我们的死信交换机
Map<String, Object> arguments = new HashMap<>(2);
arguments.put("x-dead-letter-exchange", dlxExchange);
arguments.put("x-dead-letter-routing-key", dlxRoutingKey);
return new Queue(orderQueue, true, false, false, arguments);
}
/**
* 绑定订单队列到订单交换机
*
* @return Binding
*/
@Bean
public Binding orderBinding() {
return BindingBuilder.bind(orderQueue())
.to(orderExchange())
.with(orderRoutingKey);
}
}consommateur de file d'attente de lettres incorrectes
@Component
public class OrderDlxConsumer {
/**
* 死信队列监听队列回调的方法
* @param msg
*/
@RabbitListener(queues = "kaico_order_dlx_queue")
public void orderDlxConsumer(String msg) {
System.out.println("死信队列消费订单消息" + msg);
}
}consommateur de file d'attente ordinaire
@Component
public class OrderConsumer {
/**
* 监听队列回调的方法
*
* @param msg
*/
@RabbitListener(queues = "kaico_order_queue")
public void orderConsumer(String msg) {
System.out.println("正常订单消费者消息msg:" + msg);
}
}La page de gestion de la file d'attente en arrière-plan est la suivante :
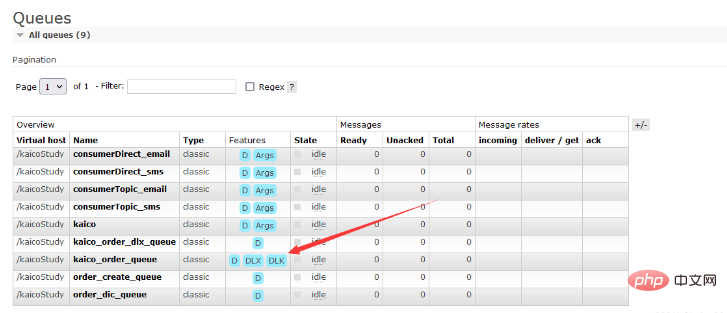
Méthode de déploiement : La file d'attente de lettres mortes ne peut pas exister sur le même serveur que la file d'attente normale et doit être stockée sur des serveurs distincts.
Delay Queue
Plan de mise en œuvre pour que le système expire et s'arrête automatiquement si la commande n'est pas payée pendant 30 minutes.
Mise en œuvre basée sur la planification des tâches, l'efficacité est très faible.
Implémenté en fonction de la clé redis expirée. Lorsque la clé expire, une méthode sera rappelée au client.
Lorsque l'utilisateur passe une commande, un token (durée de validité) est généré pendant 30 minutes et stocké dans notre redis Inconvénients : Très redondant, un champ redondant sera stocké dans la table ;
Situation RabbitMQ en file d'attente basée sur MQ (meilleure solution).
Principe : Lorsque nous passons une commande, nous envoyons un message à mq et fixons la période de validité à 30 minutes. Mais lorsque le message expire (sans être consommé), nous exécutons une méthode sur notre client pour nous indiquer que le message a été utilisé. expiré. Vérifiez à ce moment si la commande a été payée.
Logique d'implémentation :
Principalement implémenté à l'aide de files d'attente de lettres mortes.
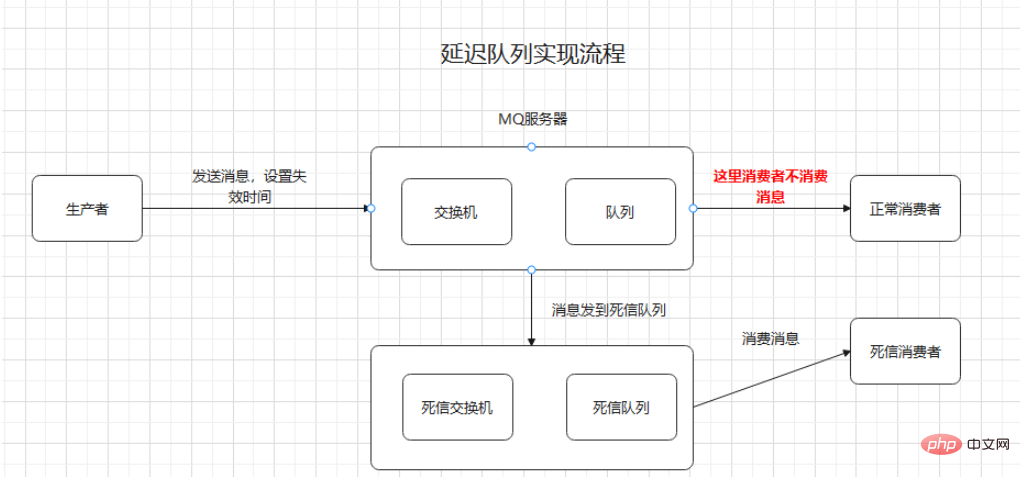
Le code que vous voulez : les consommateurs normaux ne consomment pas de messages, ou il n'y a pas de consommateurs normaux. Ils entrent dans la file d'attente des lettres mortes après le temps défini, puis les consommateurs de lettres mortes implémentent la logique métier correspondante.
Problème d'idempotence des messages RabbitMQ
Mécanisme de nouvelle tentative automatique des messages RabbitMQ
Lorsqu'une exception est levée dans le code logique métier du consommateur, la nouvelle tentative est automatiquement implémentée (la valeur par défaut est d'innombrables tentatives)
Il devrait y avoir une limite sur le nombre de RabbitMQ tentatives, par exemple, un maximum de 5 tentatives, avec un intervalle de 3 secondes à chaque fois ; si la nouvelle tentative échoue plusieurs fois, elle sera stockée dans la file d'attente des lettres mortes ou stockée dans une table de base de données pour enregistrer une compensation manuelle ultérieure. Car après le nombre de tentatives infructueuses, la file d'attente supprimera automatiquement le message.
Principe de nouvelle tentative de message : pendant le processus de nouvelle tentative, utilisez aop pour intercepter notre méthode de surveillance de la consommation, et ce journal d'erreurs ne sera pas imprimé. En cas d'échec après plusieurs tentatives, le journal des erreurs ne sera imprimé que lorsque le nombre maximum d'échecs est atteint.
Si la consommation échoue plusieurs fois :
1. Supprimez automatiquement le message (le message peut être perdu)
Solution :
Si l'enrichissement échoue plusieurs fois, il sera éventuellement stocké dans la file d'attente des lettres mortes ; journalisation de table pour enregistrer les journaux d’erreurs d’échec de consommation, puis compenser manuellement les messages.
Choix raisonnable du mécanisme de nouvelle tentative
Une fois que le consommateur a obtenu le message, il appelle une interface tierce (requête HTTP), mais que se passe-t-il si l'appel à l'interface tierce échoue ? Besoin de réessayer ?
Réponse : Parfois, l'appel échoue en raison d'une exception réseau et il peut être nécessaire de le réessayer plusieurs fois.
Une fois que le consommateur a obtenu le message, une exception de données est levée en raison de problèmes de code. Doit-il être réessayé ?
Réponse : Il n'est pas nécessaire de réessayer. Si le code est anormal, le projet de version de code doit être à nouveau modifié.
Le consommateur active le mode de réception manuel
La première étape, la configuration du projet Springboot doit activer le mode de réception
mode de reconnaissance : manuelLa deuxième étape, le code Java du consommateur
int result = orderMapper.addOrder(orderEntity);
if (result >= 0) {
// 开启消息确认机制
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
}Comment RabbitMQ résout-il le problème du pouvoir du message ?
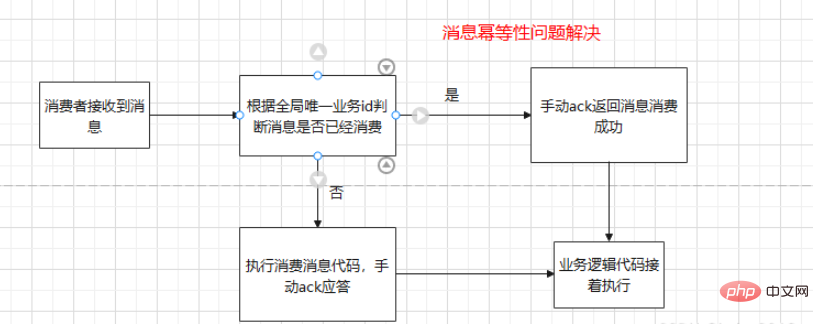
Qu'est-ce que l'idempotence du message ? Comment le consommateur MQ garantit-il l’idempotence ?
Raison : le consommateur peut activer la nouvelle tentative automatique, et le processus de nouvelle tentative peut entraîner l'exécution répétée du code logique métier du consommateur. À ce moment-là, le message a été consommé. Étant donné que l'erreur métier a provoqué la consommation du message, la solution apparaîtra à ce moment-là : utilisez l'identifiant global du message pour déterminer en fonction de l'identifiant métier (global unique). id), le consommateur peut juger que le message a été consommé.
Logique du code consommateur :
 RabbitMQ résout les problèmes de transactions distribuées
RabbitMQ résout les problèmes de transactions distribuées
Transactions distribuées : dans un système distribué, en raison des interfaces d'appel interservices, il existe plusieurs transactions différentes et chaque transaction ne s'affecte pas. Il y a un problème de transactions distribuées.
Résoudre l'idée centrale des transactions distribuées : la cohérence finale des données.
Nom dans le domaine distribué :
Cohérence forte : Soit la vitesse de synchronisation est très rapide, soit le mécanisme de verrouillage n'autorise pas les lectures sales ;
Solution de cohérence forte : Soit la base de données A synchronise les données avec les données B très rapidement, soit la base de données B ; ne peut pas lire les données avant que la synchronisation de la base de données A ne soit terminée.
Faible cohérence : les données dont la lecture est autorisée sont les données originales sales, et les résultats lus peuvent être incohérents.
Cohérence éventuelle : dans notre système distribué, étant donné que les données sont communiquées de manière synchrone via le réseau, de courts délais de données sont autorisés, mais les données finales doivent être cohérentes.
L'idée de résoudre les transactions distribuées basées sur RabbitMQ
L'idée de résoudre les transactions distribuées basées sur RabbitMQ : (Adoption de la solution de cohérence finale)
- Confirmez que nos messages de producteur doivent être livrés à MQ (message mécanisme de confirmation) Si la livraison échoue, continuez à réessayer
- Les consommateurs utilisent un accusé de réception manuel pour confirmer le message afin de réaliser la consommation. Faites attention au problème d'idempotence. En cas d'échec de consommation, mq aide automatiquement le consommateur à réessayer.
- Assurez-vous que la première transaction de notre producteur est exécutée en premier. Si l'exécution échoue, une file d'attente de commandes supplémentaire est utilisée (pour compléter la propre transaction du producteur afin de garantir que la première transaction du producteur est exécutée [cohérence éventuelle des données]).
- Carte des solutions : l'essentiel est d'utiliser mq pour envoyer des messages à d'autres systèmes afin de modifier les données en retour.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!