
Maison >développement back-end >Tutoriel Python >Quelles sont les bibliothèques de visualisation de données Python couramment utilisées ?
Quelles sont les bibliothèques de visualisation de données Python couramment utilisées ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-22 16:16:081396parcourir

Quelle bibliothèque utiliseriez-vous pour la visualisation de données en Python ?
Aujourd'hui, je vais partager avec vous un membre puissant de la bibliothèque de visualisation de données Python-Altair !
C'est très simple, convivial et construit sur la puissante spécification Vega-Lite JSON, nous n'avons besoin que d'un code court pour générer des visualisations belles et efficaces.
Qu'est-ce qu'Altair
Altair est une bibliothèque Python de visualisation statistique qui compte actuellement plus de 3 000 étoiles sur GitHub.
Avec Altair, nous pouvons consacrer plus d'énergie et de temps à la compréhension des données elles-mêmes et de leur signification, et nous libérer du processus complexe de visualisation des données.
En termes simples, Altair est une grammaire visuelle et un langage déclaratif pour créer, enregistrer et partager des conceptions visuelles interactives. Il peut utiliser le format JSON pour décrire l'apparence visuelle et le processus d'interaction, et générer des images basées sur le réseau.
Jetons un coup d'œil aux effets de visualisation réalisés avec Altair !
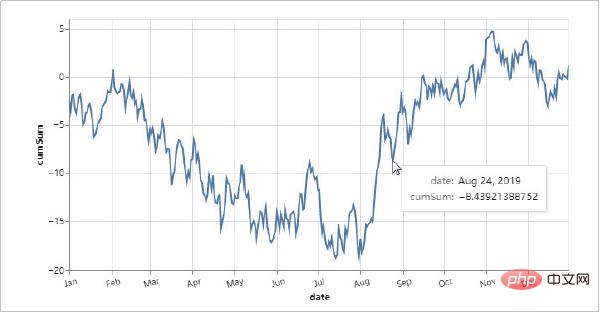
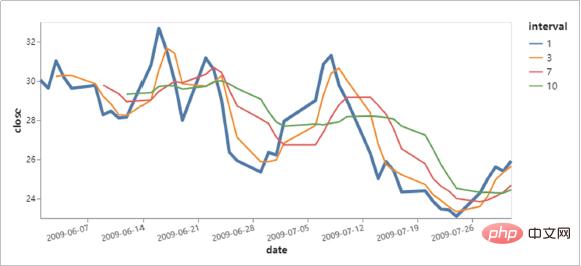
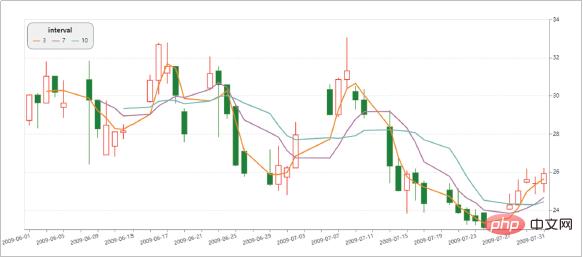
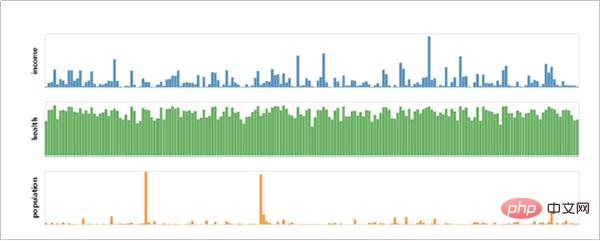
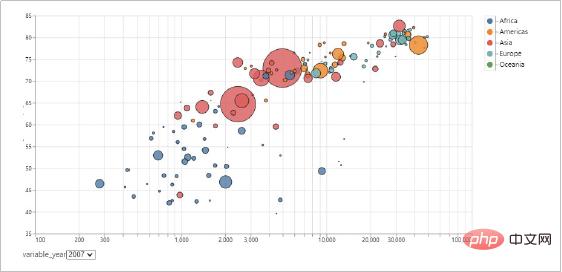
Avantages d'Altair
Altair peut comprendre et comprendre de manière globale les données grâce à l'agrégation, la transformation des données, l'interaction des données, la composition graphique, etc. Données et données analytiques. Ces processus peuvent nous aider à accroître notre compréhension des données elles-mêmes et de leur signification, et à cultiver une réflexion intuitive sur l’analyse des données.
En général, les caractéristiques d'Altair incluent les aspects suivants.
- API Python déclarative basée sur la syntaxe graphique.
- Générez le code Python d'Altair basé sur les règles de syntaxe JSON de Vega-Lite.
- Affichez le processus de visualisation statistique dans Jupyter Notebook, JupyterLab et nteract démarrés.
- Vous pouvez exporter le travail de visualisation sous forme d'image au format PNG/SVG, une page Web au format HTML qui peut être exécutée indépendamment, ou vous pouvez visualiser l'effet en cours dans l'éditeur en ligne Vega-Lite.
Dans Altair, le jeu de données utilisé est chargé dans un "format propre". DataFrame in Pandas est l'une des principales structures de données utilisées par Altair. Altair a un bon effet de chargement sur Pandas DataFrame, et la méthode de chargement est simple et efficace. Par exemple, utilisez Pandas pour lire un ensemble de données Excel et utilisez Altair pour charger le code d'implémentation des valeurs de retour Pandas, comme indiqué ci-dessous :
import altair as alt import pandas as pd data = pd.read_excel( "Index_Chart_Altair.xlsx", sheet_name="Sales", parse_dates=["Year"] ) alt.Chart( data )
Test rapide - créer un graphique à barres
Altair accorde une grande importance à la distinction et à la combinaison. de types variables. La valeur d'une variable est une donnée et il existe des différences. Elle peut être exprimée sous forme de valeurs numériques, de chaînes, de dates, etc. Les variables sont des conteneurs de stockage de données et les données sont le contenu des unités de stockage des variables.
D'un autre côté, du point de vue de l'échantillonnage statistique, la variable est la population et les données sont l'échantillon. Les échantillons doivent être utilisés pour étudier et analyser la population. Des graphiques statistiques peuvent être générés en combinant différents types de variables entre eux pour fournir une compréhension plus intuitive des données.
Divisée selon la combinaison de différents types de variables, la combinaison de types de variables peut être divisée en types suivants.
- Variable nominale + variable quantitative.
- Variable de temps + variable de quantité.
- Variable temporelle + variable nominale.
- Variable quantitative + variable quantitative.
Parmi eux, la variable temps est un type spécial de variable quantitative. La variable temps peut être définie comme une variable nominale (N) ou une variable ordinale (O) pour réaliser la discrétisation de la variable temps, formant ainsi une combinaison avec. variables quantitatives.
Ici, nous expliquerons l'une des variables nominales + variables quantitatives.
Si vous mappez des variables quantitatives sur l'axe des x, mappez des variables nominales sur l'axe des y et utilisez toujours des colonnes comme style d'encodage (style de marquage) des données, vous pouvez dessiner un graphique à barres. Les graphiques à barres peuvent mieux utiliser les changements de longueur pour comparer l'écart de bénéfice provenant des ventes de marchandises, comme le montre la figure ci-dessous.
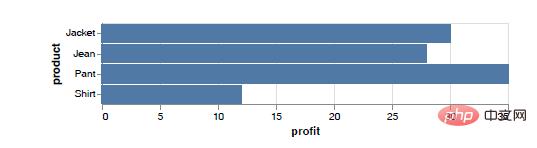
Par rapport au code d'implémentation de l'histogramme, les changements dans le code d'implémentation de l'histogramme sont les suivants.
chart = alt.Chart(df).mark_bar().encode(x="profit:Q",y="product:N")
Les graphiques complexes sont également très simples
Ce qui suit est une démonstration de partitionnement pour afficher les précipitations mensuelles moyennes de différentes années !
我们可以使用面积图描述西雅图从2012 年到2015 年的每个月的平均降雨量统计情况。接下来,进一步拆分平均降雨量,以年份为分区标准,使用阶梯图将具体年份的每月平均降雨量分区展示,如下图所示。
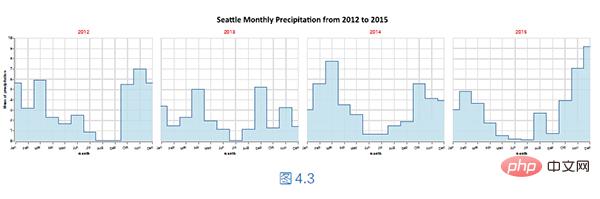
核心的实现代码如下所示。
…
chart = alt.Chart(df).mark_area(
color="lightblue",
interpolate="step",
line=True,
opacity=0.8
).encode(
alt.X("month(date):T",
axis=alt.Axis(format="%b",
formatType="time",
labelAngle=-15,
labelBaseline="top",
labelPadding=5,
title="month")),
y="mean(precipitation):Q",
facet=alt.Facet("year(date):Q",
columns=4,
header=alt.Header(
labelColor="red",
labelFontSize=15,
title="Seattle Monthly Precipitation from 2012 to 2015",
titleFont="Calibri",
titleFontSize=25,
titlePadding=15)
)
0)
…在类alt.X()中,使用month 提取时间型变量date 的月份,映射在位置通道x轴上,使用汇总函数mean()计算平均降雨量,使用折线作为编码数据的标记样式。
在实例方法encode()中,使用子区通道facet 设置分区,使用year 提取时间型变量date 的年份,作为拆分从2012 年到2015 年每个月的平均降雨量的分区标准,从而将每年的不同月份的平均降雨量分别显示在对应的子区上。使用关键字参数columns设置子区的列数,使用关键字参数header 设置子区序号和子区标题的相关文本内容。
具体而言,使用Header 架构包装器设置文本内容,也就是使用类alt.Header()的关键字参数完成文本内容的设置任务,关键字参数的含义如下所示。
- labelColor:序号标签颜色。
- labelFontSize:序号标签大小。
- title:子区标题。
- titleFont:子区字体。
- titleFontSize:子区字体大小。
- titlePadding:子区标题与序号标签的留白距离。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!