
Maison >Java >javaDidacticiel >Quels sont les quatre problèmes majeurs que le système de cache distribué Java doit résoudre ?
Quels sont les quatre problèmes majeurs que le système de cache distribué Java doit résoudre ?

- 王林avant
- 2023-04-22 14:40:16873parcourir
Le système de cache distribué est un élément indispensable de l'architecture à trois niveaux, qui améliore considérablement la concurrence et la vitesse de réponse de l'ensemble du projet, mais il apporte également de nouveaux problèmes qui doivent être résolus, à savoir : la pénétration du cache, les percées de la mise en cache, le cache avalanches et problèmes de cohérence du cache.
Pénétration du cache
Le premier gros problème est la pénétration du cache. Ce concept est plus facile à comprendre et est lié au taux de réussite. Si le taux de réussite est faible, la pression sera alors concentrée sur la couche de persistance de la base de données.
Si nous pouvons trouver des données pertinentes, nous pouvons les mettre en cache. Mais le problème est que cette requête n’a pas atteint la couche de cache ou de persistance. Cette situation est appelée pénétration du cache.
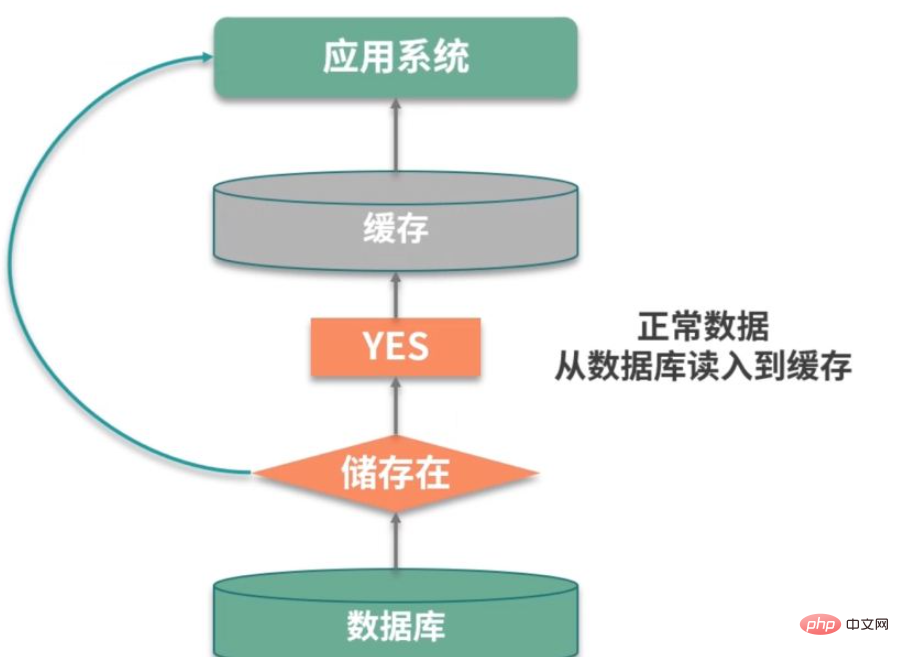
Par exemple, comme le montre l'image ci-dessus, dans un système de connexion, il y a une attaque externe, et il continue d'essayer de se connecter en utilisant des utilisateurs inexistants. Ces utilisateurs sont virtuels et ne peuvent pas être mis en cache efficacement, et arrivera à chaque fois. Une requête une fois dans la base de données entraînera éventuellement une défaillance des performances du service.
Il existe de nombreuses solutions à ce problème, présentons-les brièvement.
La première méthode consiste à mettre en cache les objets vides. N'est-ce pas parce que la couche de persistance ne parvient pas à trouver les données ? Ensuite, nous pouvons définir le résultat de cette requête sur null et le mettre dans le cache. En définissant un délai d'expiration raisonnable, la sécurité de la base de données principale peut être assurée.
La mise en cache des objets vides occupera de l'espace de cache supplémentaire et il y aura également une fenêtre temporelle pour l'incohérence des données. La deuxième méthode consiste donc à utiliser des filtres Bloom pour traiter de grandes quantités de valeurs de clé régulières.
L'existence ou la non-existence d'un enregistrement est une valeur booléenne, qui peut être stockée en utilisant seulement 1 bit. Les filtres Bloom peuvent compresser cette opération oui et non dans une structure de données. Par exemple, les données telles que le numéro de téléphone portable et le sexe de l'utilisateur sont très adaptées à l'utilisation des filtres Bloom.
Panne du cache
La panne du cache fait également référence à la situation dans laquelle les requêtes des utilisateurs tombent sur la base de données. Dans la plupart des cas, elle est causée par l'expiration du temps de cache par lots.
Nous fixons généralement un délai d'expiration pour les données dans le cache. Si une grande quantité de données est obtenue à partir de la base de données à un certain moment et que le même délai d'expiration est défini, elles expireront en même temps, provoquant une panne du cache.
Pour les données chaudes, nous pouvons les configurer pour qu'elles n'expirent pas ; ou mettre à jour leur délai d'expiration lors de l'accès ; les éléments du cache qui sont stockés par lots doivent également essayer d'attribuer un délai d'expiration relativement moyen pour éviter l'expiration en même temps.
Avalanche de cache
Le mot avalanche fait peur, mais la situation réelle est en effet plus grave. La mise en cache est utilisée pour accélérer le système, et la base de données principale n'est qu'une sauvegarde des données, et non une alternative à haute disponibilité.
Lorsque le système de cache tombe en panne, le trafic sera instantanément transféré vers la base de données back-end. D'ici peu, la base de données sera submergée par le trafic intense et raccrochera. Cette défaillance de service en cascade peut être clairement qualifiée d'avalanche.
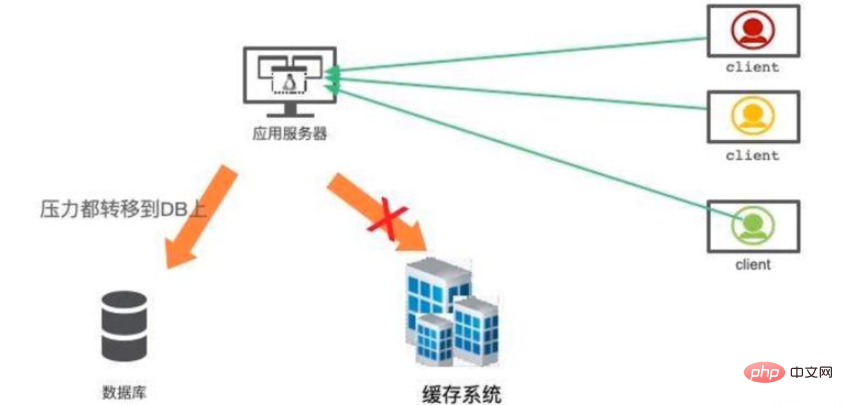
La construction de cache à haute disponibilité est très importante. Redis propose des modes maître-esclave et cluster. Le mode cluster est simple à utiliser et chaque fragment peut également agir indépendamment comme maître-esclave, garantissant une disponibilité extrêmement élevée.
De plus, nous avons une évaluation générale des goulots d'étranglement des performances de la base de données. Si le système de cache tombe en panne, vous pouvez utiliser le composant de limitation actuel pour intercepter les requêtes circulant vers la base de données.
Cohérence du cache
Après l'introduction des composants de cache, un autre problème difficile est la cohérence du cache.
Voyons d’abord comment le problème se produit. Pour un élément de cache, il existe quatre opérations couramment utilisées : écriture, mise à jour, lecture et suppression.
Écriture : Le cache et la base de données sont deux composants différents. Tant qu'une double écriture est impliquée, il est possible qu'une seule des écritures réussisse, provoquant une incohérence des données.
Mise à jour : la situation de mise à jour est similaire, deux composants différents doivent être mis à jour.
Lecture : La lecture doit garantir que les informations lues dans le cache sont les plus récentes et cohérentes avec celles de la base de données.
Suppression : lors de la suppression d'enregistrements de base de données, comment supprimer les données du cache ?
Parce que la logique métier est relativement complexe dans la plupart des cas. Les opérations de mise à jour sont très coûteuses. Par exemple, le solde d'un utilisateur est un nombre calculé en calculant une série d'actifs. Si ces actifs associés doivent actualiser le cache à chaque fois qu'ils sont modifiés, la structure du code sera très déroutante et impossible à maintenir.
Je recommande d'utiliser la méthode de cohérence du cache déclenché. L'utilisation de la méthode de chargement différé peut rendre la synchronisation du cache très simple :
Lors de la lecture du cache, s'il n'y a pas de données pertinentes dans le cache, les données pertinentes seront exécutées. Logique métier , construisez les données du cache et stockez-les dans le système de cache ;
Lorsque les ressources liées à l'élément de cache changent, l'élément de cache correspondant sera d'abord supprimé, puis la ressource sera mise à jour dans la base de données, et enfin l'élément de cache correspondant sera supprimé.
En plus du modèle de programmation simple, cette opération présente un avantage évident. Je charge ce cache dans le système de cache uniquement lorsque je l'utilise. Si des ressources sont créées et mises à jour à chaque fois qu'une modification est effectuée, il y aura beaucoup de données froides dans le système de cache. Cela implémente en fait le modèle Cache-Aside, qui charge les données du stockage de données dans le cache à la demande. L'effet le plus important est d'améliorer les performances et de réduire les requêtes inutiles.
Mais cela pose encore des problèmes. Le scénario présenté ensuite est également une question souvent posée lors des entretiens.
L'action de mise à jour de la base de données et l'action de suppression du cache que nous avons mentionnées ci-dessus ne font évidemment pas partie de la même transaction. Cela peut entraîner une incohérence entre le contenu de la base de données et le contenu du cache pendant le processus de mise à jour.
Lors de l'entretien, tant que vous soulignez cette question, l'intervieweur lèvera le pouce.
Vous pouvez utiliser des verrous distribués pour résoudre ce problème. Vous pouvez utiliser des verrous pour isoler les opérations de base de données et les opérations de cache des autres opérations de lecture du cache. De manière générale, l'opération de lecture n'a pas besoin d'être verrouillée. Lorsqu'elle rencontre un verrou, elle réessaye et attend jusqu'à expiration.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!