
Maison >Périphériques technologiques >IA >Dolly 2.0, le premier grand modèle ChatGPT véritablement open source au monde, peut être modifié à volonté pour un usage commercial
Dolly 2.0, le premier grand modèle ChatGPT véritablement open source au monde, peut être modifié à volonté pour un usage commercial

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-22 12:28:081672parcourir
Comme nous le savons tous, OpenAI n'est pas ouvert en ce qui concerne ChatGPT. Les modèles open source de la série alpaga de Meta sont également « limités aux applications de recherche universitaire » en raison de problèmes tels que les ensembles de données. contourner les restrictions, un grand modèle axé sur le 100% open source est ici.
Le 12 avril, Databricks a publié Dolly 2.0, une autre nouvelle version du grand modèle de langage (LLM) d'interactivité humaine de type ChatGPT (suivi des instructions) publié il y a deux semaines.
Databricks affirme que Dolly 2.0 est le premier LLM open source et conforme aux directives de l'industrie, affiné sur un ensemble de données transparent et disponible gratuitement qui est également open source et disponible à des fins commerciales. Cela signifie que Dolly 2.0 peut être utilisé pour créer des applications commerciales sans payer pour l'accès à l'API ni partager de données avec des tiers.

- Lien du projet : https://huggingface.co/databricks/dolly-v2-12b
- Ensemble de données : https://github.com/databrickslabs/dolly/tree/ master /data
Selon Ali Ghodsi, PDG de Databricks, bien qu'il existe d'autres grands modèles qui peuvent être utilisés à des fins commerciales, "ils ne vous parlent pas comme Dolly 2.0". les utilisateurs peuvent modifier et améliorer les données de formation car elles sont disponibles gratuitement sous une licence open source. Vous pouvez donc créer votre propre version de Dolly.
Databricks a également publié l'ensemble de données sur lequel Dolly 2.0 a été affiné, appelé databricks-dolly-15k. Il s'agit d'un corpus de plus de 15 000 enregistrements générés par des milliers d'employés de Databricks. Databricks l'appelle « le premier corpus d'instructions open source généré par l'homme, spécialement conçu pour permettre aux grands langages de démontrer l'interactivité magique de ChatGPT ».
Comment Dolly 2.0 est néAu cours des deux derniers mois, l'industrie et le monde universitaire ont rattrapé OpenAI et proposé une vague de grands modèles de type ChatGPT qui suivent les instructions. Ces versions sont considérées par de nombreuses définitions comme open source (. ou Fournir un certain degré d’ouverture ou un accès limité). Parmi eux, le LLaMA de Meta a attiré le plus d'attention, ce qui a conduit à un grand nombre de modèles encore améliorés, tels que Alpaca, Koala, Vicuna et Dolly 1.0 de Databricks.
Mais d'un autre côté, beaucoup de ces modèles « ouverts » sont soumis à des « contraintes industrielles » car ils sont formés sur des ensembles de données avec des termes conçus pour limiter l'utilisation commerciale - comme les 52 000 du projet StanfordAlpaca. Les données de questions et réponses set est formé sur la base des résultats de ChatGPT d'OpenAI. Et les conditions d’utilisation d’OpenAI incluent une règle selon laquelle vous ne pouvez pas utiliser les services d’OpenAI pour les concurrencer.
Databricks a réfléchi aux moyens de résoudre ce problème : le nouveau Dolly 2.0 proposé est un modèle de langage de 12 milliards de paramètres, basé sur la série de modèles open source EleutherAI pythia et spécifiquement optimisé pour un petit enregistrement d'instructions open source. corpus (databricks-dolly- 15k), cet ensemble de données a été généré par les employés de Databricks, et les termes de la licence autorisent l'utilisation, la modification et l'extension à toutes fins, y compris des applications académiques ou commerciales.
Jusqu'à présent, les modèles formés sur les résultats de ChatGPT se trouvaient dans une zone grise juridique. "La communauté entière a contourné ce problème sur la pointe des pieds, et tout le monde sort ces modèles, mais aucun d'entre eux n'est disponible dans le commerce", a déclaré Ghodsi. "C'est pourquoi nous sommes si excités."
"Tout le monde veut voir plus grand, mais nous sommes en fait intéressés par quelque chose de plus petit", a déclaré Ghodsi à propos de l'échelle miniature de Dolly. "Deuxièmement, nous avons examiné toutes les réponses et elles étaient de grande qualité."
Ghodsi a déclaré qu'il pensait que Dolly 2.0 déclencherait un effet "boule de neige", permettant à d'autres acteurs du domaine de l'intelligence artificielle de se joindre à nous et de proposer d'autres alternatives. . Il a expliqué que les restrictions sur l'utilisation commerciale constituaient un obstacle majeur à surmonter : « Nous sommes ravis maintenant parce que nous avons enfin trouvé un moyen de contourner ce problème. Je vous garantis que vous allez voir des gens appliquer ces 15 000 problèmes au monde réel. c'est-à-dire qu'ils verront combien de ces modèles deviennent soudainement un peu magiques et vous pourrez interagir avec eux."
Ensemble de données sur le frottement des mains
Pour télécharger les poids du modèle Dolly 2.0, visitez simplement la page Databricks Hugging Face et visitez le dépôt Dolly de databricks-labs pour télécharger l'ensemble de données databricks-dolly-15k.
L'ensemble de données "databricks-dolly-15k" contient 15 000 paires invite/réponse générées par l'homme de haute qualité, écrites par plus de 5 000 employés de Databricks en mars et avril 2023, des instructions spécialement conçues pour régler de grands modèles de langage . Ces enregistrements de formation sont naturels, expressifs et conçus pour représenter un large éventail de comportements, du brainstorming et de la génération de contenu à l'extraction et à la synthèse d'informations.
Selon les termes de la licence de cet ensemble de données (licence Creative Commons Attribution-ShareAlike 3.0 Unported), n'importe qui peut utiliser, modifier ou étendre cet ensemble de données à n'importe quelle fin, y compris des applications commerciales.
Actuellement, cet ensemble de données est le premier ensemble de données d'instructions open source générées par l'homme .
Pourquoi créer un tel ensemble de données ? L'équipe a également expliqué pourquoi dans un article de blog.
Une étape clé dans la création de Dolly 1.0, ou de toute directive qui suit LLM, consiste à entraîner le modèle sur un ensemble de données de paires de directives et de réponses. Dolly 1.0 coûte 30 $ à former et utilise un ensemble de données créé par l'équipe Alpaca de l'Université de Stanford à l'aide de l'API OpenAI.
Après la sortie de Dolly 1.0, de nombreuses personnes ont demandé à l'essayer, et certains utilisateurs ont également souhaité utiliser ce modèle à des fins commerciales.
Mais l'ensemble de données de formation contient le résultat de ChatGPT, et comme le souligne l'équipe de Stanford, les conditions de service tentent d'empêcher quiconque de créer un modèle qui concurrence OpenAI.
Auparavant, tous les modèles connus conformes à la directive (Alpaca, Koala, GPT4All, Vicuna) étaient soumis à cette restriction : l'utilisation commerciale était interdite. Pour résoudre ce problème, l'équipe de Dolly a commencé à chercher des moyens de créer un nouvel ensemble de données sans restrictions d'utilisation commerciale.
Plus précisément, l'équipe a appris d'un document de recherche publié par OpenAI que le modèle InstructGPT original a été formé sur un ensemble de données composé de 13 000 démonstrations de comportement de suivi d'instructions. Inspirés par cela, ils ont décidé de voir s'ils pouvaient obtenir des résultats similaires, sous la direction des employés de Databricks.
Il s'avère que générer 13 000 questions et réponses est plus difficile qu'on ne l'imaginait. Parce que chaque réponse doit être originale et ne peut pas être copiée depuis ChatGPT ou n'importe où sur le Web, sinon cela "polluera" l'ensemble de données. Mais Databricks compte plus de 5 000 employés et ils étaient très intéressés par le LLM. L’équipe a donc mené une expérience de crowdsourcing qui a créé un ensemble de données de meilleure qualité que celui créé par 40 annotateurs pour OpenAI.
Bien sûr, ce travail prend du temps et demande beaucoup de travail. Afin de motiver tout le monde, l'équipe a mis en place un concours, et les 20 meilleurs annotateurs recevront des prix surprises. En parallèle, ils ont également répertorié 7 tâches bien précises :
- Questions et réponses ouvertes : par exemple, "Pourquoi les gens aiment-ils les films comiques ?" ou "Quelle est la capitale de la France ?"
- Questions et réponses fermées : il est possible de répondre à ces questions en utilisant un seul paragraphe d'informations de la référence. Par exemple, étant donné un paragraphe de Wikipédia sur les atomes, on pourrait demander : « Quel est le rapport protons/neutrons dans le noyau ? »
- Extraire des informations de Wikipédia : ici, l'annotateur extrait des informations de Wikipédia Copiez un paragraphe de Wikipédia et extraire l'entité ou d'autres informations factuelles du paragraphe, telles que le poids ou la mesure ;
- Résumer les informations sur Wikipédia : pour cela, l'annotateur fournit un paragraphe de Wikipédia et est invité à le distiller dans un bref résumé ; Brainstorming : Cette tâche nécessite une idéation ouverte et une liste d'options possibles pertinentes. Par exemple, « Quelles activités amusantes puis-je faire avec mes amis ce week-end ? » ;
- Catégorie : dans cette tâche, l'annotateur est invité à porter un jugement sur l'appartenance à une catégorie (par exemple, les éléments de la liste sont des animaux, des minéraux). ou des légumes), ou juger les attributs d'un court texte, comme le sentiment d'une critique de film
- Écriture créative : Cette tâche comprendra l'écriture de quelque chose comme un poème ou une lettre d'amour ;


Ensuite, l'équipe a arrêté le jeu en raison de craintes de "bloquer la productivité du personnel" (ce qui est logique).
Faisabilité de la commercialisation
Après la création rapide de l'ensemble de données, l'équipe a commencé à envisager des applications commerciales.Ils veulent créer un modèle open source pouvant être utilisé commercialement. Bien que databricks-dolly-15k soit beaucoup plus petit qu'Alpaca (l'ensemble de données sur lequel Dolly 1.0 a été formé), le modèle Dolly 2.0 basé sur EleutherAI pythia-12b présente un comportement de suivi des instructions de haute qualité.
Avec le recul, cela n’est pas surprenant. Après tout, de nombreux ensembles de données de réglage des instructions publiés ces derniers mois contiennent des données synthétiques, qui contiennent souvent des hallucinations et des erreurs factuelles.
databricks-dolly-15k, quant à lui, est généré par des professionnels, est de haute qualité et contient des réponses longues à la plupart des tâches.
Voici quelques exemples d'utilisation de Dolly 2.0 pour la synthèse et la génération de contenu :

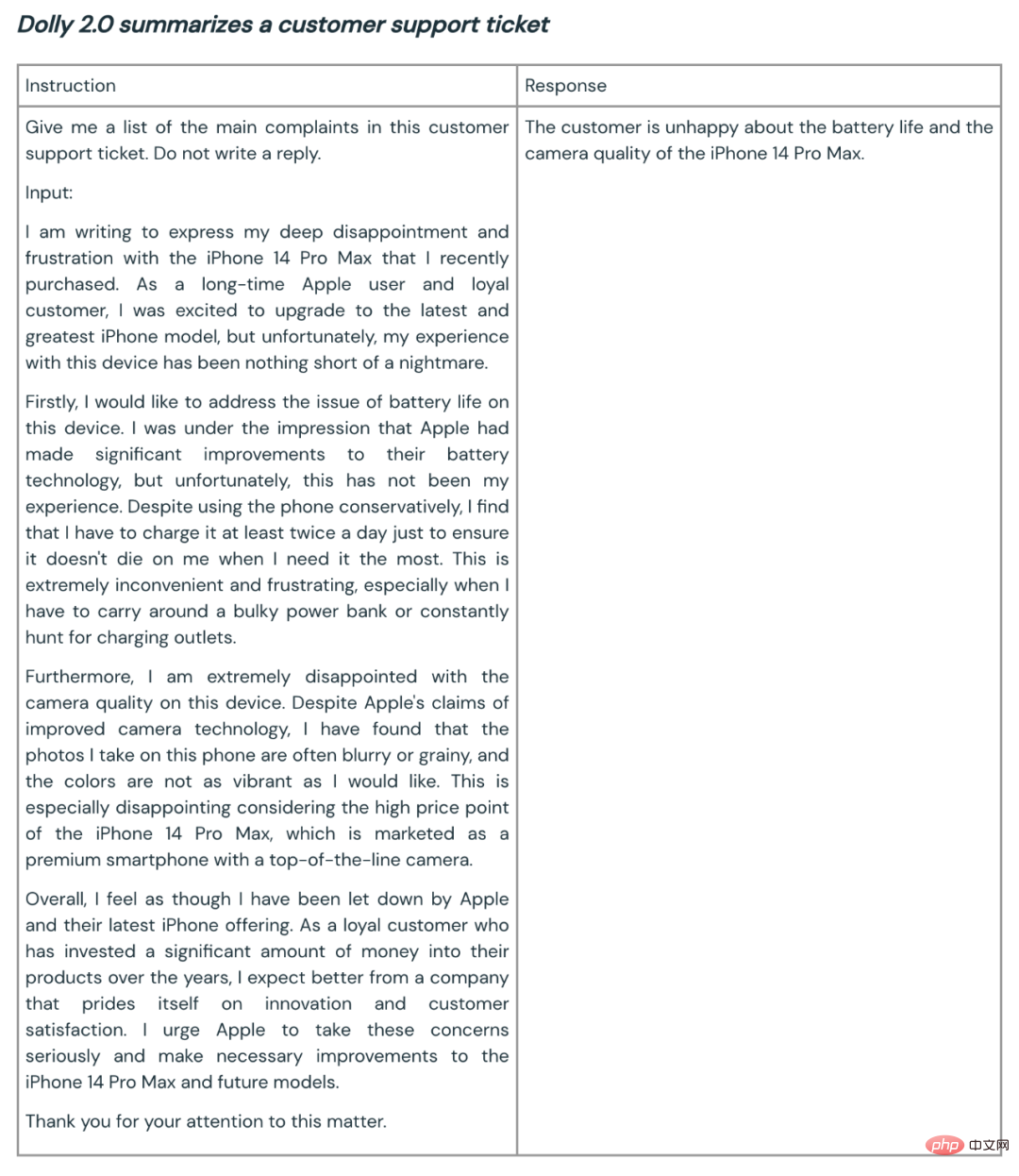

L'open source de Dolly 2 est un bon début pour construire un meilleur écosystème de grands modèles. Les ensembles de données et modèles open source encouragent les commentaires, la recherche et l’innovation, contribuant ainsi à garantir que chacun bénéficie des avancées de la technologie de l’IA. L'équipe Dolly s'attend à ce que le nouveau modèle et l'ensemble de données open source servent de base à de nombreux travaux de suivi, contribuant ainsi à conduire à des modèles de langage plus puissants.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI