
Maison >Périphériques technologiques >IA >L'Académie chinoise des logiciels des sciences a publié un nouveau modèle CV ViG qui surpasse ViT en termes de performances. Deviendra-t-il un représentant des réseaux de neurones graphiques à l'avenir ?
L'Académie chinoise des logiciels des sciences a publié un nouveau modèle CV ViG qui surpasse ViT en termes de performances. Deviendra-t-il un représentant des réseaux de neurones graphiques à l'avenir ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-21 23:37:081822parcourir
La structure réseau de la vision par ordinateur est-elle sur le point de subir une autre innovation ?
Des réseaux de neurones convolutifs aux transformateurs visuels dotés de mécanismes d'attention, les modèles de réseaux de neurones traitent l'image d'entrée comme une grille ou une séquence de patchs, mais cette méthode ne peut pas capturer des objets changeants ou complexes.
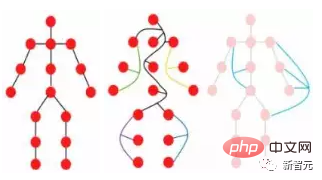
Par exemple, lorsque les gens observent une image, ils divisent naturellement l'image entière en plusieurs objets et établissent des relations spatiales et d'autres relations de position entre les objets. En d'autres termes, l'image entière est en fait une image pour le cerveau humain. dessinés et les objets sont des nœuds sur le graphique.
Récemment, des chercheurs de l'Institut du logiciel de l'Académie chinoise des sciences, du laboratoire Arche de Noé de Huawei, de l'Université de Pékin et de l'Université de Macao ont proposé conjointement une nouvelle architecture modèle Vision GNN (ViG), qui peut extraire Les fonctionnalités au niveau graphique des images sont utilisées dans les tâches de vision.

Lien papier : https://arxiv.org/pdf/2206.00272.pdf
Tout d'abord, vous devez diviser l'image en plusieurs patchs en tant que nœuds dans le graphique et construire un graphique en connectant les patchs voisins les plus proches. , puis utilisez le modèle ViG pour transformer et échanger les informations de tous les nœuds de l'ensemble du graphique.
ViG se compose de deux modules de base. Le module Grapher utilise la convolution graphique pour agréger et mettre à jour les informations graphiques, et le module FFN utilise deux couches linéaires pour transformer les caractéristiques des nœuds.
Les expériences menées sur les tâches de reconnaissance d'images et de détection d'objets ont également prouvé la supériorité de l'architecture ViG. Les recherches pionnières du GNN sur les tâches de vision générales fourniront une inspiration et une expérience utiles pour les recherches futures.
L'auteur de l'article est le professeur Wu Enhua, directeur de doctorat à l'Institut du logiciel de l'Académie chinoise des sciences et professeur honoraire à l'Université de Macao. Il est diplômé du Département d'ingénierie mécanique et de mathématiques de l'Université Tsinghua. 1970 et son doctorat du Département d'informatique de l'Université de Manchester au Royaume-Uni en 1980. Les principaux domaines de recherche sont l'infographie et la réalité virtuelle, notamment : la réalité virtuelle, la génération de graphiques photoréalistes, la simulation basée sur la physique et le calcul en temps réel, la modélisation et le rendu basés sur la physique, le traitement et la modélisation d'images et de vidéos, l'informatique visuelle et l'étude des machines.
Visual GNN
La structure du réseau est souvent le facteur le plus critique pour améliorer les performances. Tant que la quantité et la qualité des données peuvent être garanties, en changeant le modèle de CNN en ViT, vous pouvez obtenir un modèle avec de meilleures performances.
Mais différents réseaux traitent les images d'entrée différemment. CNN fait glisser la fenêtre sur l'image et introduit l'invariance de traduction et les fonctionnalités locales.
ViT et le perceptron multicouche (MLP) convertissent l'image en une séquence de patchs, par exemple en divisant une image 224×224 en plusieurs patchs 16×16, et forment enfin une séquence d'entrée d'une longueur de 196.
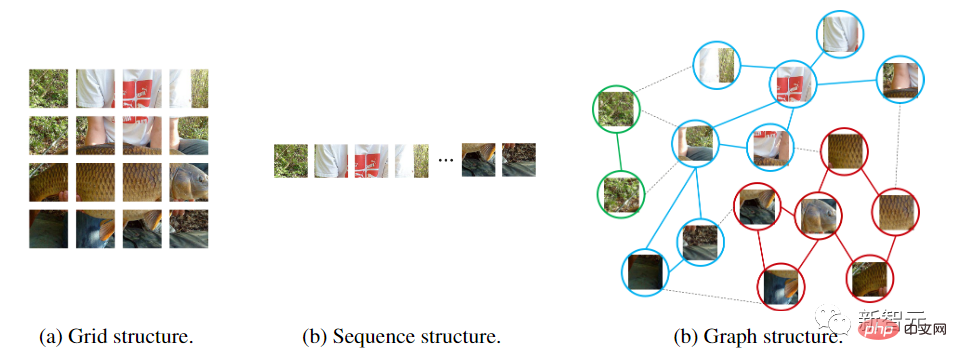
Les réseaux de neurones graphiques sont plus flexibles. Par exemple, en vision par ordinateur, une tâche de base consiste à identifier des objets dans des images. Étant donné que les objets ne sont généralement pas quadrilatères et peuvent avoir des formes irrégulières, les structures de grille ou de séquence couramment utilisées dans les réseaux précédents tels que ResNet et ViT sont redondantes et peu flexibles à gérer.
Un objet peut être considéré comme composé de plusieurs parties. Par exemple, une personne peut être grossièrement divisée en tête, haut du corps, bras et jambes.
Ces pièces reliées par des articulations forment naturellement une structure graphique. En analysant le schéma, nous avons enfin pu identifier que l'objet pouvait être un humain.
De plus, le graphique est une structure de données générale, et la grille et la séquence peuvent être considérées comme un cas particulier de graphique. Penser une image sous forme de graphique est plus flexible et plus efficace pour la perception visuelle.
L'utilisation d'une structure graphique nécessite de diviser l'image d'entrée en plusieurs patchs et de traiter chaque patch comme un nœud. Si chaque pixel est traité comme un nœud, cela entraînera trop de nœuds dans le graphique (> 10K).
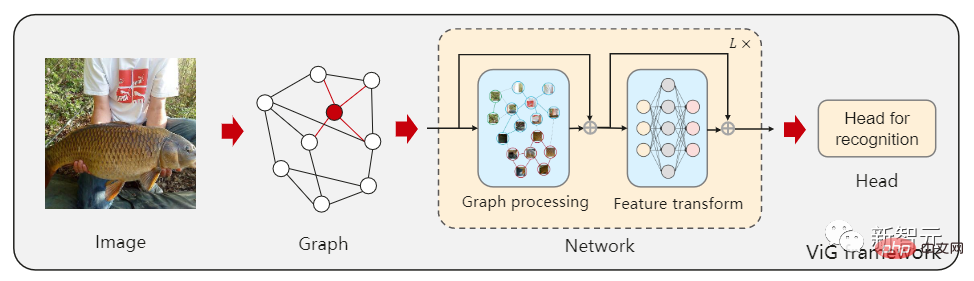
Après avoir établi le graphique, agrégez d'abord les caractéristiques entre les nœuds adjacents via un réseau neuronal convolutif graphique (GCN) et extrayez la représentation de l'image.
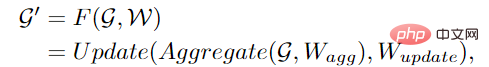
Afin de permettre à GCN d'obtenir des fonctionnalités plus diversifiées, l'auteur applique une opération multi-têtes à la convolution graphique. Les caractéristiques agrégées sont mises à jour par des têtes avec des poids différents, et enfin cascadées dans la représentation d'image.
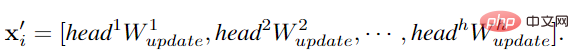
Les GCN précédents réutilisaient généralement plusieurs couches convolutives de graphiques pour extraire les caractéristiques agrégées des données graphiques, tandis que le phénomène de lissage excessif dans les GCN profonds réduirait le caractère unique des caractéristiques des nœuds, entraînant une diminution des performances de reconnaissance visuelle.
Pour atténuer ce problème, les chercheurs ont introduit davantage de transformations de fonctionnalités et de fonctions d'activation non linéaires dans le bloc ViG.
Appliquez d'abord une couche linéaire avant et après la convolution du graphique pour projeter les fonctionnalités des nœuds dans le même domaine et augmenter la diversité des fonctionnalités. Insertion d'une fonction d'activation non linéaire après convolution du graphique pour éviter l'effondrement des couches.
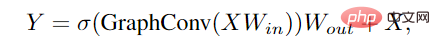
Afin d'améliorer encore la capacité de conversion de fonctionnalités et d'atténuer le phénomène de lissage excessif, il est également nécessaire d'utiliser un réseau à action directe (FFN) sur chaque nœud. Le module FFN est un simple perceptron multicouche avec deux couches entièrement connectées.
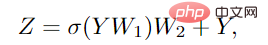
Dans les modules Grapher et FFN, la normalisation par lots est effectuée après chaque couche entièrement connectée ou couche de convolution graphique. La pile du module Grapher et du module FFN constitue un bloc ViG, qui est également l'unité de base pour construire un. grand réseau.
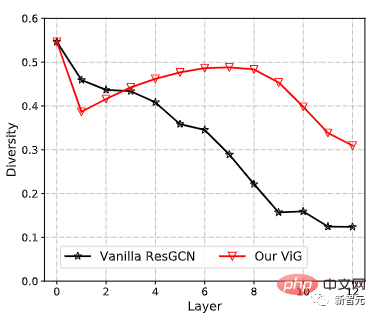
Par rapport au ResGCN original, le ViG nouvellement proposé peut maintenir la diversité des fonctionnalités, et à mesure que de nouvelles couches sont ajoutées, le réseau peut également apprendre des représentations plus fortes.
Dans l'architecture de réseau de vision par ordinateur, les modèles Transformer couramment utilisés ont généralement une structure isotrope (comme ViT), tandis que CNN préfère utiliser une structure pyramidale (comme ResNet).
Afin de comparer avec d'autres types de réseaux de neurones, les chercheurs ont établi deux architectures de réseau pour ViG : isotrope et pyramidale.
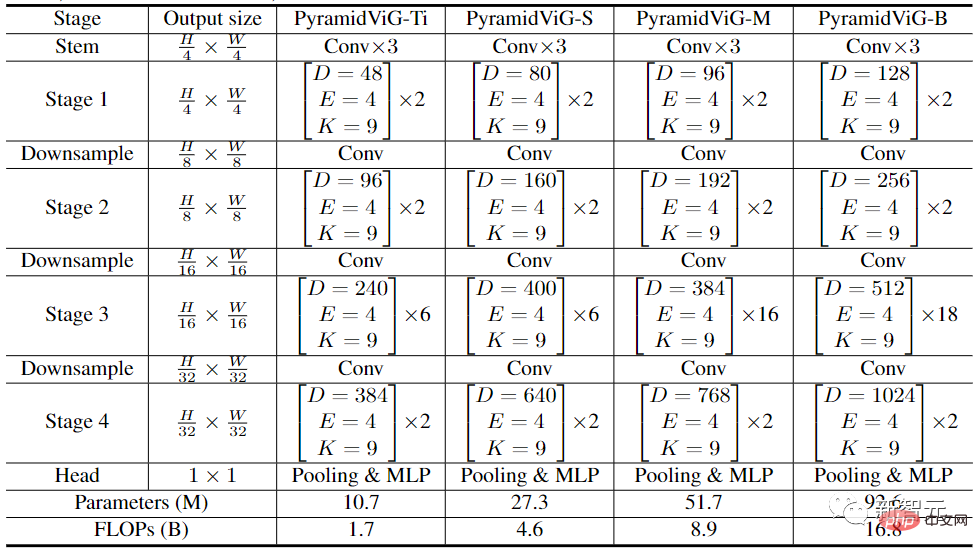
Au cours de la phase de comparaison expérimentale, les chercheurs ont sélectionné l'ensemble de données ImageNet ILSVRC 2012 dans la tâche de classification d'images, qui contient 1 000 catégories, 120 millions d'images de formation et 50 000 images de vérification.
Dans la tâche de détection de cible, l'ensemble de données COCO 2017 avec 80 catégories cibles a été sélectionné, dont 118 000 images d'entraînement et 5 000 images d'ensemble de vérification.

Dans l'architecture ViG isotrope, la taille des caractéristiques peut rester inchangée pendant son processus de calcul principal, qui est facile à étendre et convivial pour l'accélération matérielle. Après l'avoir comparé aux CNN, transformateurs et MLP isotropes existants, nous pouvons voir que ViG fonctionne mieux que les autres types de réseaux. Parmi eux, ViG-Ti a atteint une précision de premier ordre de 73,9 %, soit 1,7 % de plus que le modèle DeiT-Ti, alors que le coût de calcul est similaire.
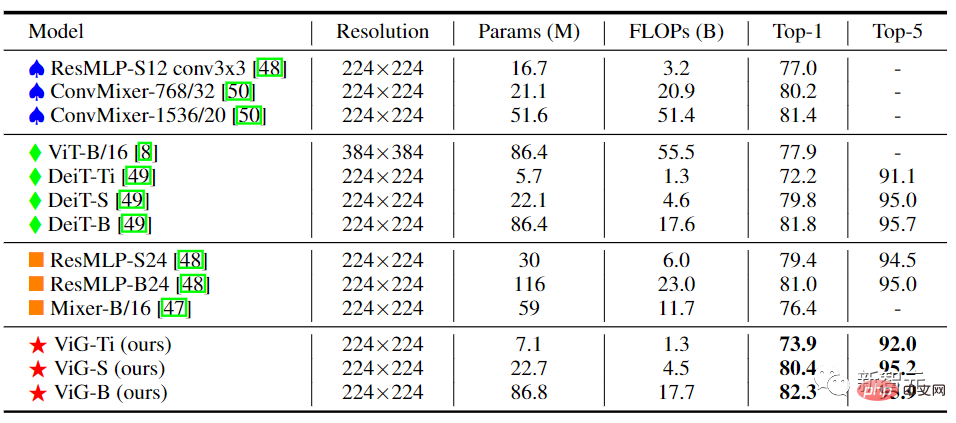
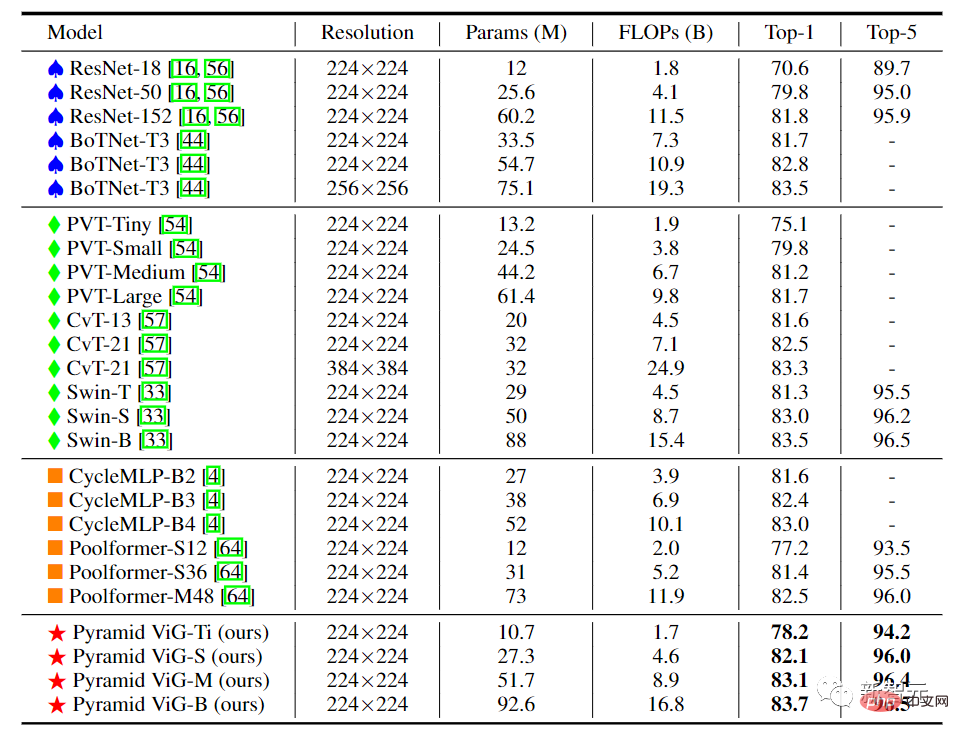
Dans le ViG à structure pyramidale, à mesure que le réseau s'approfondit, la taille spatiale de la carte des caractéristiques est progressivement réduite et les caractéristiques invariantes d'échelle de l'image sont utilisées pour générer des caractéristiques multi-échelles en même temps.
La plupart des réseaux hautes performances utilisent des structures pyramidales, telles que ResNet, Swin Transformer et CycleMLP. Après avoir comparé Pyramid ViG avec ces réseaux pyramidaux représentatifs, on peut constater que la série Pyramid ViG peut surpasser ou rivaliser avec les réseaux pyramidaux de pointe, notamment CNN, MLP et Transformer.
Les résultats montrent que les réseaux de neurones graphiques peuvent bien effectuer des tâches visuelles et peuvent devenir un composant fondamental des systèmes de vision par ordinateur.
Pour mieux comprendre le flux de travail du modèle ViG, les chercheurs ont visualisé la structure graphique construite dans ViG-S. Placements d'échantillons à deux profondeurs différentes (blocs 1 et 12). Le pentagramme est le nœud central et les nœuds de même couleur sont ses voisins. Seuls les deux nœuds centraux sont visualisés car dessiner tous les bords semblerait encombré.

On peut observer que le modèle ViG peut sélectionner des nœuds liés au contenu comme voisins de premier ordre. Aux niveaux superficiels, les nœuds voisins sont souvent sélectionnés en fonction de caractéristiques locales et de bas niveau, telles que la couleur et la texture. Aux niveaux profonds, les voisins du nœud central sont plus sémantiques et appartiennent à la même catégorie. Le réseau ViG peut progressivement connecter les nœuds grâce à leur contenu et leur représentation sémantique, aidant ainsi à mieux identifier les objets.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI