
Maison >Opération et maintenance >exploitation et maintenance Linux >qu'est-ce que le canal Linux
qu'est-ce que le canal Linux

- 青灯夜游original
- 2023-04-21 18:54:182045parcourir
Le pipeline est une méthode de communication entre les processus Linux. Deux processus peuvent transférer des informations via une zone de mémoire partagée, et les données dans le pipeline ne peuvent circuler que dans une seule direction, ce qui signifie qu'il ne peut y avoir que des processus d'écriture et de lecture fixes. Actuellement, dans n'importe quel shell, vous pouvez utiliser "|" pour connecter deux commandes. Le shell connectera l'entrée et la sortie des deux processus avec un canal pour atteindre l'objectif de communication inter-processus.

L'environnement d'exploitation de ce tutoriel : système linux7.3, ordinateur Dell G3.
Les tuyaux sont la plus ancienne méthode de communication inter-processus dans les environnements UNIX. Cet article explique principalement comment utiliser les tubes dans l'environnement Linux.
Qu'est-ce qu'un pipeline ?
Pipe, l'anglais est pipe. Les tubes sont une méthode de communication entre les processus Linux. Deux processus peuvent transférer des informations via une zone de mémoire partagée, et les données dans le tube ne peuvent circuler que dans une seule direction, ce qui signifie qu'il ne peut y avoir que des processus d'écriture et de lecture fixes.
L'inventeur du pipeline est Douglas McElroy, qui était également l'inventeur du premier shell sous UNIX. Après avoir inventé le shell, il a découvert que lors de l'exécution de commandes dans des opérations système, il était souvent nécessaire de transférer la sortie d'un programme vers un autre programme pour le traitement. Cette opération peut être réalisée en utilisant la redirection d'entrée et de sortie et l'ajout de fichiers, tels que. :
[zorro@zorro-pc pipe]$ ls -l /etc/ > etc.txt
[zorro@zorro-pc pipe]$ wc -l etc.txt
183 etc.txt Mais cela semble trop gênant. C’est ainsi qu’est né le concept de pipeline. Actuellement, dans n'importe quel shell, vous pouvez utiliser "|" pour connecter deux commandes. Le shell connectera l'entrée et la sortie des deux processus avec un tube pour atteindre l'objectif de communication inter-processus :
[zorro@zorro-pc pipe]$ ls -l /etc/ | wc -l 183
Comparez les deux méthodes ci-dessus. , On peut également comprendre qu'un tube est essentiellement un fichier. Le processus précédent ouvre le fichier en mode écriture, et le processus suivant l'ouvre en mode lecture. De cette façon, après avoir écrit devant et lu plus tard, la communication est réalisée. En fait, la conception du pipeline suit également le principe de conception UNIX « tout est un fichier ». Il s'agit essentiellement d'un fichier. Le système Linux implémente directement le pipeline dans un système de fichiers et utilise VFS pour fournir des interfaces d'exploitation pour les applications.
Bien que l'implémentation se présente sous la forme d'un fichier, le pipeline lui-même n'occupe pas de disque ou autre espace de stockage externe. Dans l'implémentation Linux, il occupe de l'espace mémoire. Par conséquent, un tube sous Linux est une mémoire tampon dont le mode de fonctionnement est un fichier.
Classification et utilisation des pipes
Il existe deux types de pipes sous Linux :
Tubes anonymes
Tubes nommés
Ces deux tubes sont également appelés tubes nommés ou sans nom. La forme la plus courante de canaux anonymes est le "|" que nous utilisons le plus souvent dans les opérations shell. Sa caractéristique est qu'il ne peut être utilisé que dans les processus parent-enfant. Le processus parent doit ouvrir un fichier tube avant de générer un processus enfant, puis fork pour générer le processus enfant. De cette façon, le processus enfant obtient le descripteur du processus enfant. même fichier de canal en copiant l'espace d'adressage du processus parent, afin d'atteindre l'objectif d'utiliser le même pipeline pour la communication. À l'heure actuelle, personne, à l'exception des processus parent et enfant, ne connaît le descripteur de ce fichier canal, les informations contenues dans ce canal ne peuvent donc pas être transmises à d'autres processus. Cela garantit la sécurité des données transmises, mais réduit bien sûr également la polyvalence du canal, de sorte que le système fournit également des canaux nommés.
On peut utiliser la commande mkfifo ou mknod pour créer un tube nommé, ce qui n'est pas différent de la création d'un fichier :
[zorro@zorro-pc pipe]$ mkfifo pipe
[zorro@zorro-pc pipe]$ ls -l pipe
prw-r--r-- 1 zorro zorro 0 Jul 14 10:44 pipeVous pouvez voir que le type de fichier créé est assez particulier, c'est du type p. Indique qu'il s'agit d'un fichier pipeline. Avec ce fichier de canal, il existe un nom global pour un canal dans le système, de sorte que deux processus non liés peuvent communiquer via ce fichier de canal. Par exemple, laissons maintenant un processus écrire ce fichier pipe :
[zorro@zorro-pc pipe]$ echo xxxxxxxxxxxxxx > pipeA ce moment, l'opération d'écriture sera bloquée car personne ne lit à l'autre extrémité du tube. Il s'agit du comportement par défaut du noyau pour les définitions de fichiers de tubes. S'il y a un processus qui lit ce tube à ce moment-là, alors le blocage de cette opération d'écriture sera levé :
[zorro@zorro-pc pipe]$ cat pipe
xxxxxxxxxxxxxxVous pouvez observer qu'après avoir traité le fichier, la commande echo à l'autre extrémité revient également. Il s'agit d'un canal nommé.
Le système Linux utilise le même comportement de fonctionnement du système de fichiers au niveau de la couche inférieure pour les canaux nommés et les canaux anonymes. Ce système de fichiers est appelé pipefs. Vous pouvez savoir si votre système prend en charge ce système de fichiers dans le fichier /etc/proc/filesystems :
[zorro@zorro-pc pipe]$ cat /proc/filesystems |grep pipefs
nodev pipefs观察完了如何在命令行中使用管道之后,我们再来看看如何在系统编程中使用管道。
PIPE
我们可以把匿名管道和命名管道分别叫做PIPE和FIFO。这主要因为在系统编程中,创建匿名管道的系统调用是pipe(),而创建命名管道的函数是mkfifo()。使用mknod()系统调用并指定文件类型为为S_IFIFO也可以创建一个FIFO。
使用pipe()系统调用可以创建一个匿名管道,这个系统调用的原型为:
#include <unistd.h>
int pipe(int pipefd[2]);这个方法将会创建出两个文件描述符,可以使用pipefd这个数组来引用这两个描述符进行文件操作。pipefd[0]是读方式打开,作为管道的读描述符。pipefd[1]是写方式打开,作为管道的写描述符。从管道写端写入的数据会被内核缓存直到有人从另一端读取为止。我们来看一下如何在一个进程中使用管道,虽然这个例子并没有什么意义:
[zorro@zorro-pc pipe]$ cat pipe.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
if (write(pipefd[1], STRING, strlen(STRING)) < 0) {
perror("write()");
exit(1);
}
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
exit(0);
}这个程序创建了一个管道,并且对管道写了一个字符串之后从管道读取,并打印在标准输出上。用一个图来说明这个程序的状态就是这样的:

一个进程自己给自己发送消息这当然不叫进程间通信,所以实际情况中我们不会在单个进程中使用管道。进程在pipe创建完管道之后,往往都要fork产生子进程,成为如下图表示的样子:
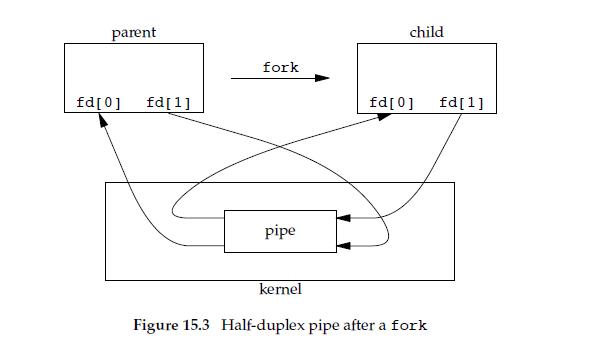
如图中描述,fork产生的子进程会继承父进程对应的文件描述符。利用这个特性,父进程先pipe创建管道之后,子进程也会得到同一个管道的读写文件描述符。从而实现了父子两个进程使用一个管道可以完成半双工通信。此时,父进程可以通过fd[1]给子进程发消息,子进程通过fd[0]读。子进程也可以通过fd[1]给父进程发消息,父进程用fd[0]读。程序实例如下:
[zorro@zorro-pc pipe]$ cat pipe_parent_child.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
bzero(buf, BUFSIZ);
snprintf(buf, BUFSIZ, "Message from child: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
} else {
/* this is parent */
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
sleep(1);
bzero(buf, BUFSIZ);
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
wait(NULL);
}
exit(0);
}父进程先给子进程发一个消息,子进程接收到之后打印消息,之后再给父进程发消息,父进程再打印从子进程接收到的消息。程序执行效果:
[zorro@zorro-pc pipe]$ ./pipe_parent_child
Parent pid is: 8309
Child pid is: 8310
Message from parent: My pid is: 8309
Message from child: My pid is: 8310从这个程序中我们可以看到,管道实际上可以实现一个半双工通信的机制。使用同一个管道的父子进程可以分时给对方发送消息。我们也可以看到对管道读写的一些特点,即:
在管道中没有数据的情况下,对管道的读操作会阻塞,直到管道内有数据为止。当一次写的数据量不超过管道容量的时候,对管道的写操作一般不会阻塞,直接将要写的数据写入管道缓冲区即可。
当然写操作也不会再所有情况下都不阻塞。这里我们要先来了解一下管道的内核实现。上文说过,管道实际上就是内核控制的一个内存缓冲区,既然是缓冲区,就有容量上限。我们把管道一次最多可以缓存的数据量大小叫做PIPESIZE。内核在处理管道数据的时候,底层也要调用类似read和write这样的方法进行数据拷贝,这种内核操作每次可以操作的数据量也是有限的,一般的操作长度为一个page,即默认为4k字节。我们把每次可以操作的数据量长度叫做PIPEBUF。POSIX标准中,对PIPEBUF有长度限制,要求其最小长度不得低于512字节。PIPEBUF的作用是,内核在处理管道的时候,如果每次读写操作的数据长度不大于PIPEBUF时,保证其操作是原子的。而PIPESIZE的影响是,大于其长度的写操作会被阻塞,直到当前管道中的数据被读取为止。
在Linux 2.6.11之前,PIPESIZE和PIPEBUF实际上是一样的。在这之后,Linux重新实现了一个管道缓存,并将它与写操作的PIPEBUF实现成了不同的概念,形成了一个默认长度为65536字节的PIPESIZE,而PIPEBUF只影响相关读写操作的原子性。从Linux 2.6.35之后,在fcntl系统调用方法中实现了F_GETPIPE_SZ和F_SETPIPE_SZ操作,来分别查看当前管道容量和设置管道容量。管道容量容量上限可以在/proc/sys/fs/pipe-max-size进行设置。
#define BUFSIZE 65536
......
ret = fcntl(pipefd[1], F_GETPIPE_SZ);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
printf("PIPESIZE: %d\n", ret);
ret = fcntl(pipefd[1], F_SETPIPE_SZ, BUFSIZE);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
......PIPEBUF和PIPESIZE对管道操作的影响会因为管道描述符是否被设置为非阻塞方式而有行为变化,n为要写入的数据量时具体为:
O_NONBLOCK关闭,n cd9b8164773b34f128e3f4b20077da4a PIPE_BUF:
对n字节的写入操作不保证是原子的,就是说这次写入操作的数据可能会跟其他进程写这个管道的数据进行交叉。当管道容量长度低于要写的数据长度的时候write操作会被阻塞。
O_NONBLOCK打开,n > PIPE_BUF:
如果管道空间已满。write调用报错返回并且errno被设置为EAGAIN。如果没满,则可能会写入从1到n个字节长度,这取决于当前管道的剩余空间长度,并且这些数据可能跟别的进程的数据有交叉。
以上是在使用半双工管道的时候要注意的事情,因为在这种情况下,管道的两端都可能有多个进程进行读写处理。如果再加上线程,则事情可能变得更复杂。实际上,我们在使用管道的时候,并不推荐这样来用。管道推荐的使用方法是其单工模式:即只有两个进程通信,一个进程只写管道,另一个进程只读管道。实现为:
[zorro@zorro-pc pipe]$ cat pipe_parent_child2.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
close(pipefd[1]);
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
} else {
/* this is parent */
close(pipefd[0]);
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
wait(NULL);
}
exit(0);
}这个程序实际上比上一个要简单,父进程关闭管道的读端,只写管道。子进程关闭管道的写端,只读管道。整个管道的打开效果最后成为下图所示:
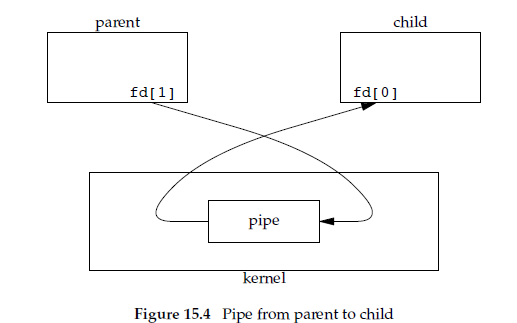
此时两个进程就只用管道实现了一个单工通信,并且这种状态下不用考虑多个进程同时对管道写产生的数据交叉的问题,这是最经典的管道打开方式,也是我们推荐的管道使用方式。另外,作为一个程序员,即使我们了解了Linux管道的实现,我们的代码也不能依赖其特性,所以处理管道时该越界判断还是要判断,该错误检查还是要检查,这样代码才能更健壮。
FIFO
命名管道在底层的实现跟匿名管道完全一致,区别只是命名管道会有一个全局可见的文件名以供别人open打开使用。再程序中创建一个命名管道文件的方法有两种,一种是使用mkfifo函数。另一种是使用mknod系统调用,例子如下:
[zorro@zorro-pc pipe]$ cat mymkfifo.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "Argument error!\n");
exit(1);
}
/*
if (mkfifo(argv[1], 0600) < 0) {
perror("mkfifo()");
exit(1);
}
*/
if (mknod(argv[1], 0600|S_IFIFO, 0) < 0) {
perror("mknod()");
exit(1);
}
exit(0);
}我们使用第一个参数作为创建的文件路径。创建完之后,其他进程就可以使用open()、read()、write()标准文件操作等方法进行使用了。其余所有的操作跟匿名管道使用类似。需要注意的是,无论命名还是匿名管道,它的文件描述都没有偏移量的概念,所以不能用lseek进行偏移量调整。
相关推荐:《Linux视频教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que dois-je faire si j'oublie mon mot de passe Linux Mysql ?
- Que faire si vous oubliez votre mot de passe Linux MySQL
- Comment utiliser Yum pour installer MySQL sous Linux
- Comment définir les autorisations MySQL dans le système Linux
- Comment installer le service Linux MySQL
- Comment définir les autorisations MySQL sous Linux