
Maison >Périphériques technologiques >IA >Problèmes d'interprétabilité des réseaux de neurones : revisiter la critique des NN d'il y a trente ans
Problèmes d'interprétabilité des réseaux de neurones : revisiter la critique des NN d'il y a trente ans

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-21 14:19:091396parcourir
1 stationnement), il est crucial d’expliquer ces décisions, plutôt que de simplement produire un score prédit.
La recherche en intelligence artificielle explicable (XAI) s'est récemment concentrée sur le concept d'exemples contrefactuels. L'idée est simple : créez d'abord des exemples contrefactuels avec les résultats attendus et introduisez-les dans le réseau d'origine ; puis lisez les unités de couche cachées pour expliquer pourquoi le réseau a produit un autre résultat ; Plus formellement :
« La fraction p est renvoyée car la variable V a une valeur (v1, v2, ...) qui lui est associée Si V a une valeur (v′1, v′2, ...). ), Toutes les autres variables étant maintenues constantes, le score p' sera renvoyé. 45 000 £ et vous obtenez un prêt. » Cependant, un article de Browne et Swift [1] (ci-après dénommé B&W) a récemment montré que l'exemple contrefactuel n'est que légèrement plus significatif. entrée, ce qui amène le réseau à les classer mal avec un degré de confiance élevé.
De plus, les exemples contrefactuels « expliquent » ce que devraient être certaines caractéristiques pour obtenir des prédictions correctes, mais « n'ouvrent pas la boîte noire », c'est-à-dire n'expliquent pas comment fonctionne l'algorithme. L'article poursuit en affirmant que les exemples contrefactuels n'apportent pas de solution en matière d'interprétabilité et que « sans sémantique, il n'y a pas d'explication ».
En fait, l'article fait même une suggestion plus forte :
1) Soit on trouve un moyen d'extraire la sémantique supposée exister dans les couches cachées du réseau, soit
2) Admettons que nous échouons.
Et Walid S. Saba lui-même est pessimiste sur (1) En d'autres termes, il admet à regret notre échec. Voici ses raisons.
2 L'auteur estime que la raison pour laquelle l'espoir d'une explication satisfaisante ne peut se réaliser est précisément pour les raisons exposées par Fodor et Pylyshyn [2] il y a plus de trente ans.Walid S. Saba a ensuite argumenté : Avant d'expliquer où se situe le problème, nous devons noter que les modèles purement extensionnels (tels que les réseaux de neurones) ne peuvent pas modéliser la systémique et la compositionnalité, car ils ne reconnaissent pas les structures symboliques avec une syntaxe et une syntaxe dérivables. sémantique correspondante.
Ainsi, les représentations dans les réseaux de neurones ne sont pas vraiment des "symboles" qui correspondent à quelque chose d'interprétable - mais plutôt des valeurs distribuées, corrélées et continues qui n'impliquent pas elles-mêmes quoi que ce soit qui puisse être conceptuellement les choses expliquées ci-dessus.
En termes plus simples, les représentations sous-symboliques dans les réseaux de neurones ne font elles-mêmes référence à rien que les humains peuvent comprendre conceptuellement (les unités cachées elles-mêmes ne peuvent pas représenter des objets d'une quelconque signification métaphysique). Il s'agit plutôt d'un ensemble d'unités cachées qui, ensemble, représentent généralement une caractéristique saillante (par exemple, les moustaches d'un chat).
Mais c'est exactement pourquoi les réseaux de neurones ne peuvent pas atteindre l'interprétabilité, notamment parce que la combinaison de plusieurs caractéristiques cachées est indéterminable - une fois la combinaison terminée (par une fonction de combinaison linéaire), les unités individuelles sont perdues (nous le montrerons ci-dessous ).
3Module[2].
Dans les systèmes symboliques, il existe des fonctions sémantiques compositionnelles bien définies qui calculent la signification des mots composés en fonction de la signification de leurs constituants. Mais cette combinaison est réversible -
c'est-à-dire que l'on a toujours accès aux composants (d'entrée) qui ont produit cette sortie, et précisément parce que dans un système symbolique on a accès à une "structure syntaxique", cette structure contient une carte de la façon d'assembler les composants. Rien de tout cela n’est vrai dans NN. Une fois que les vecteurs (tenseurs) sont combinés dans un NN, leur décomposition ne peut pas être déterminée (les façons dont les vecteurs (y compris les scalaires) peuvent être décomposés sont infinies !)
Pour illustrer pourquoi c'est le cœur du problème, considérons Proposition B&W pour extraire la sémantique dans les DNN afin d'atteindre l'interprétabilité. La suggestion de B&W est de suivre ces directives :
L'image d'entrée est étiquetée "Architecture" car le neurone caché 41435 qui active normalement l'enjoliveur a une valeur d'activation de 0,32. Si la valeur d'activation du neurone caché 41435 est de 0,87, l'image d'entrée sera étiquetée « voiture ».
Pour comprendre pourquoi cela ne conduit pas à l'interprétabilité, notons simplement qu'exiger que le neurone 41435 ait une activation de 0,87 n'est pas suffisant. Pour plus de simplicité, supposons que le neurone 41435 n'ait que deux entrées, x1 et x2. Ce que nous avons maintenant est illustré dans la figure 1 ci-dessous :
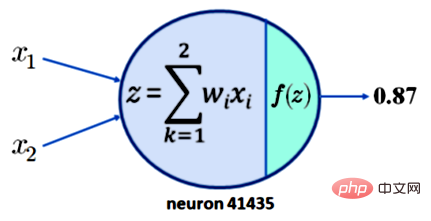
Légende : La sortie d'un seul neurone avec deux entrées est de 0,87
Supposons maintenant que notre fonction d'activation f soit la fonction ReLU populaire, alors une sortie de z = 0,87 peut être produite. Cela signifie que pour les valeurs de x1, x2, w1 et w2 indiquées dans le tableau ci-dessous, un résultat de 0,87 est obtenu.
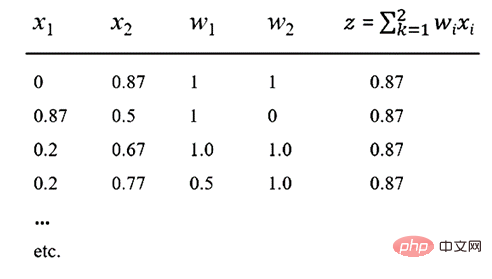
Remarque sur le tableau : diverses méthodes de saisie peuvent produire une valeur de 0,87
En regardant le tableau ci-dessus, il est facile de voir qu'il existe d'innombrables combinaisons linéaires de x1, x2, w1 et w2. , et ils produiront un résultat de 0,87. Le point important ici est que la compositionnalité des NN est irréversible, de sorte qu’une sémantique significative ne peut être capturée à partir d’aucun neurone ou d’une quelconque collection de neurones.
Conformément au slogan de B&W « Pas de sémantique, pas d’explication », nous affirmons qu’aucune explication ne pourra jamais être obtenue de NN. En bref, il n’y a pas de sémantique sans compositionnalité, il n’y a pas d’explication sans sémantique, et DNN ne peut pas modéliser la compositionnalité. Cela peut être formalisé comme suit :
1. Il n'y a pas d'explication sans sémantique[1] 2. Il n'y a pas de sémantique sans compositionnalité réversible[2]
3.
=> DNN inexplicable (sans XAI)Fin.
D'ailleurs, le fait que la compositionnalité des DNN soit irréversible a des conséquences autres que l'incapacité de produire des prédictions interprétables, en particulier dans les domaines qui nécessitent un raisonnement de plus haut niveau, comme la compréhension du langage naturel (NLU).
En particulier, un tel système ne peut vraiment pas expliquer comment un enfant peut apprendre à interpréter un nombre infini de phrases simplement à partir de modèles comme (
Enfin, l'auteur souligne qu'il y a plus de trente ans, Fodor et Pylyshyn [2] ont émis une critique de NN en tant qu'architecture cognitive - ils ont montré pourquoi NN ne peut pas modéliser la systématicité, la productivité et la compositionnalité, qui sont toutes nécessaires pour parler de tout "sémantique" - et cette critique impérieuse n'a jamais reçu de réponse parfaite. Alors que la nécessité de résoudre le problème de l'explicabilité de l'IA devient critique, nous devons revoir cet article classique car il montre les limites de l'assimilation de la reconnaissance statistique des formes aux progrès de l'IA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI