
Maison >Java >javaDidacticiel >Comment utiliser le flux et le réseau Java IO pour créer un robot d'exploration d'images simple
Comment utiliser le flux et le réseau Java IO pour créer un robot d'exploration d'images simple

- 王林avant
- 2023-04-20 12:49:14964parcourir
Java IO流和网络的简单应用
最近看到了 URL 类的用法,简单的做了一个Java 版的爬虫。发现还挺有趣的,就拿出来分享一下。通过关键字爬取百度图片,这个和我们使用搜索引擎搜索百度图片是一样的,只是通过爬虫可以学习技术的使用。(这个程序只是用来学习使用的,没有其它用途!)
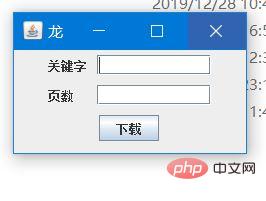
Java IO 流和 URL 类
Java IO流
Java 的 IO 流是实现输入/输出的基础,它可以方便的实现数据的输入/输出操作,在 Java 中把不同的输入/输出源(键盘、文件、网络连接等)抽象表述为”流“(Stream),通过流的方法运行Java 程序使用相同的方式来访问不同的输入/输出源。
因为 IO流 已经对各种输入输出源做了一个抽象处理,所以我们可以使用相对一致的代码处理各种的源,只需要把它们作为输入输出流来进行处理就行了,这就是面向抽象的好处。
URL 类
URI 和 URL
先来了解一下什么是 URL 吧,说 URL 之前先简单了解URI。
**URI,统一资源标识符(Uniform Resource Identifier)**是采用一种特定语法标识一个资源的字符串。所标识的资源可能是服务器上的一个文件或者其它任何内容。URI 的语法是由一个模式和一个模式特定部分组成,模式和模式特定部分用一个冒号分隔,如下所示:
模式:模式特定部分
URI 中的模式特定部分没有特定的语法,很多都采用一种层次结构形式,如:
//authority/path?query
**URL,统一资源定位符(Uniform Resource Location)**是URI的一个子集,它除了标识一个资源外 ,还会为资源提供一个特定的网络位置,客户端可以用它来获取这个资源的一个表示。
注意:URL和URI并不是完全相同的,通用的URI可以告诉你一个资源是什么,但是无法告诉你它在哪里,以及如何得到这个资源。
在Java中,这二者都有相应的实现,java.net.URI 类(只标识资源)与 java.net.URL 类(既能标识资源,又能获取资源)
URL 中的网络位置通常包括用来访问服务器的协议(FTP、HTTP等)、服务器的主机名或IP地址,以及文件在该服务器上的路径。典型的 URL 类似于 https://www.baidu.com/。它表示百度服务器上的一个 html 文件(百度搜索的首页),它可以通过 HTTP 协议访问虽然没有直接在 URL 后面加上 html 文件的名字。如果使用 tomcat 的话,通常是 http://127.0.0.1:8080/foods/index.html 这种形式,其实二者是相同的。
好了,简单的了解就到此为止了,感兴趣的话,可以查阅相关书籍了解更详细的知识,上面只是提到一些基础的概念。
URL类
java.net.URL类是对统一资源定位符的抽象表示。它不依赖于继承来配置不同类型的URL的实例,而使用了策略设计模式。协议处理器就是策略,URL 类构成上下文,通过它来选择不同的策略。(值得一提的是:
java 的 IO流也是使用了一种设计模式:装饰器模式。
例如如下代码:
DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(new File())))。
URL 类包含很多的构造方法,我也只是第一次使用,就使用了最简单的一种形式:(刚开始学习,根本不需要了解这么多,先用着再说,慢慢掌握知识。)
public URL(String url) throws MalformedURLException
Java 爬虫
Talk is cheap, show me the code!
前面主要是一下简单的基础知识,如果已经了解可以直接看下面这部分。
项目的基本结构:
Client
package dragon;
import java.io.File;
import java.io.IOException;
public class Client {
public static final String downloadFilePath = "D:\\DragonDataFile\\cat";
public static void main(String[] args) throws IOException {
//初始化创建文件下载目录
File dir = new File(Client.downloadFilePath);
if (!dir.exists()) {
dir.mkdirs();
}
//启动下载窗口
new Window("龙");
}
}DataProcessUtil
package dragon;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.net.URL;
import java.net.URLConnection;
import java.util.LinkedList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
public class DataProcessUtil {
//根据链接获取 html 文件数据。
public static String getData(String link) throws IOException {
URL url = new URL(link);
URLConnection connection = url.openConnection();
StringBuilder strBuilder = new StringBuilder();
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream())){
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
strBuilder.append(new String(b, 0, hasRead));
}
}
return strBuilder.toString();
}
public static List<String> getLinkList(String str){
String regx = "\"objURL\":\"(.*?)\",";
Pattern p = Pattern.compile(regx);
Matcher m = p.matcher(str);
List<String> strs = new LinkedList<>();
while (m.find()) {
strs.add(m.group(0));
}
//使用 Stream API 进行处理并返回。
return strs.stream()
.map(s->s.substring(10, s.length()-2))
.collect(Collectors.toList());
}
}说明:
获取html页面的信息,并进行处理,使用正则表达式从html中提取图片的链接。
(正则表达式是参考其它人的实现,这个涉及到对html内容的分析)
String regx = "\"objURL\":\"(.*?)\",";
//使用 Stream API 进行处理并返回。 return strs.stream() .map(s->s.substring(10, s.length()-2)) .collect(Collectors.toList());
使用Java 8新增加的 Stream 对数据进行遍历,提取所有的图片的 URL 组成一个列表集合返回。
DownLoadUtil
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.util.Date;
import java.util.List;
import java.util.Random;
public class DownLoadUtil {
public static void downLoad(List<String> strs) {
strs.stream().forEach(u->{
try {
URL url = new URL(u);
String contentType = url.openConnection().getContentType();
if (contentType != null && contentType.contains("image/")) {
//获取图片的类型:content type
String filetype = null;
if (contentType.contains("jpeg")) {
filetype = ".jpeg";
} else if (contentType.contains("jpg")) {
filetype = ".jpg";
} else{
filetype = ".png";
} //gif 格式图片,似乎无法正常显示
//使用当前日期的毫秒数+随机数+contentType 作为文件名
Random rand = new Random(System.currentTimeMillis());
String filename = new Date().getTime()+rand.nextInt(10000)+filetype;
Runnable r = ()->{
int flag = 0;
File imageFile = new File(Client.downloadFilePath, filename);
try(
BufferedInputStream bis = new BufferedInputStream(url.openConnection().getInputStream());
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(imageFile))){
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
} catch (IOException e) {
System.out.println("下载失败!");
//对于下载失败的图片进行删除,不然会出现错误!图片只能正常现实一部分
if (imageFile.exists()) {
boolean b = imageFile.delete();
System.out.println("下载失败,删除图片"+b);
}
flag = 1;
e.printStackTrace();
}
if (flag == 0)
System.out.println("下载完成:"+filename);
};
Thread t = new Thread(r);
t.start(); //启动下载线程。
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("链接错误!");
}
});
}
}注意:这里遇到一个问题,就是图片的下载过程受到网络因素的影响,有时候会下载失败,但是如果图片已经开始下载,仍然提示下载失败,那么这张图片可以能会出现异常,比如出现一下奇怪的颜色,我对下载失败的图片,进行了处理,发现,似乎没有效果。
单纯的判断大小无法解决图片变形的问题,还有一种情况需要考虑!在最下面,会有详细说明解决方法。
Window
package dragon;
import java.awt.FlowLayout;
import java.io.IOException;
import java.util.List;
import javax.swing.Box;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JTextField;
public class Window extends JFrame{
/**
* 自动生成的序列化版本号
*/
private static final long serialVersionUID = 7809323808831342296L;
private JLabel label_keyWord, label_Page;
private JTextField textField, textPage;
private JButton download;
public Window(String name) {
super(name);
this.init();
//设置布局
this.setLayout(new FlowLayout());
this.setBounds(400, 400, 250, 150);
this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
this.setVisible(true);
}
private void init() {
label_keyWord = new JLabel("关键字");
label_Page = new JLabel("页数");
textField = new JTextField(10);
textPage = new JTextField(10);
download = new JButton("下载");
download.addActionListener(e->{
String keyWord = textField.getText().trim();
String page = textPage.getText().trim();
int download_page = 0;
if (keyWord.length() == 0 || page.length() == 0) {
JOptionPane.showMessageDialog(null, "关键字或页数不能为空!", "警告", JOptionPane.WARNING_MESSAGE);
return ;
}
try {
download_page = Integer.parseInt(page); //匹配单个数字,如果数字很多使用正则表达式
} catch (NumberFormatException exp) {
JOptionPane.showMessageDialog(null, "页数必须为数字!", "警告", JOptionPane.WARNING_MESSAGE);
return ;
}
String link = null;
for (int i = 1; i <= download_page; i++) {
//分页下载图片!
link = "http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="+keyWord+"&pn="+i*20;
this.download(link);
}
});
Box boxH1 = Box.createHorizontalBox();
boxH1.add(label_keyWord);
boxH1.add(Box.createHorizontalStrut(10));
boxH1.add(textField);
Box boxH2 = Box.createHorizontalBox();
boxH2.add(label_Page);
boxH2.add(Box.createHorizontalStrut(23));
boxH2.add(textPage);
Box boxH3 = Box.createHorizontalBox();
boxH3.add(download);
Box boxV = Box.createVerticalBox();
boxV.add(boxH1);
boxV.add(Box.createVerticalStrut(10));
boxV.add(boxH2);
boxV.add(Box.createVerticalStrut(10));
boxV.add(boxH3);
this.add(boxV);
}
private void download(String link) {
try {
String str = DataProcessUtil.getData(link);
List<String> links = DataProcessUtil.getLinkList(str);
//尝试下载!使用线程进行下载,防止阻塞!
Thread t = new Thread(()->{
DownLoadUtil.downLoad(links);
});
t.start();
} catch (IOException e1) {
e1.printStackTrace();
JOptionPane.showMessageDialog(null, "啥都没有!", "警告", JOptionPane.WARNING_MESSAGE);
}
}
}说明:
当图片没有下载完成时,不要再次点击下载按钮,否则会报错。因为线程不能被再次启动。
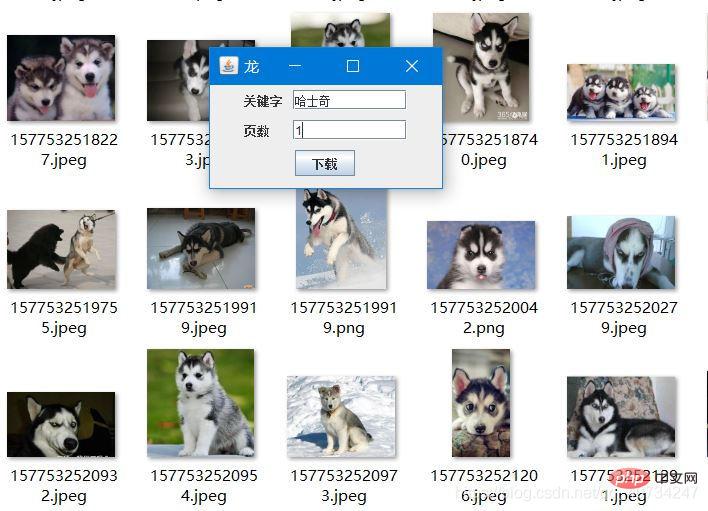
运行结果
基本原理
我来简单画一个示意图,大家凑合着看:
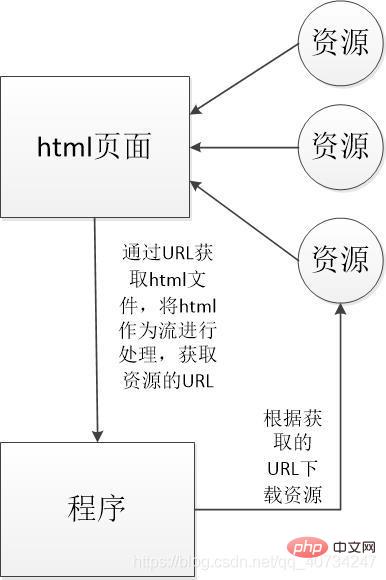
说明:首先通过百度图片的URL来获取百度图片那个页面的信息(html的内容),我们平时在浏览器使用,看到的都是浏览器处理好的页面,如果使用爬虫爬取的就是原始的html页面,在浏览器按 F12 也可以看到。因为图片的链接都在html 中,所以我们需要取出这些图片,这里就用到了**正则表达式(Regular Expression)**的知识了,通过正则表达式可以取出需要的信息(资源的URL或者说资源的地址)。其实获取html的过程和获取图片的过程,都是一样的。
这里说一下,这个步骤:
//根据链接获取 html 文件数据。
public static String getData(String link) throws IOException {
URL url = new URL(link);
URLConnection connection = url.openConnection();
StringBuilder strBuilder = new StringBuilder();
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream())){
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
strBuilder.append(new String(b, 0, hasRead));
}
}
return strBuilder.toString();
}通过参数 link,创建一个 URL 对象,然后通过使用URLConnection connection = url.openConnection();获取 URLConnection 对象,在通过 URLConnection 对象的getInputStream() 方法,获取输入流即可。这样就完成了对资源的获取。我这里强调资源,因为下载图片其实和这个过程是一样的。
总结
这个小软件虽然功能很简单,但是也用到了很多知识点,比较适合初学者进行学习(Java IO流、网络、Stream、线程的知识),知识虽然用到的都不难(一些基础知识),但是融合起来使用,还是很有意思的。
附
对于图片的奇怪颜色问题,可以确定是图片的大小和原来图片的大小不一致导致的,至于为什么是这样的,估计需要具备一定的图形学知识,才能解答,这个超出了这个东西的范围了。所以为了判断哪些图片出错,我就使用大小判断的方法,对最后生成的文件大小和网络图片文件大小进行比对,删除了一些无法下载的图片,但是有一些图片居然无法删除,我查阅了资料,大多说它被另一个进程占用,但是我这个图片应该是没有的。后来,经过检查发现是多线程惹得祸,因为是多线程,并且代码执行速度太快了(对的,和这个也有关系),因为我的文件命名是当前时间的毫秒数+一个种子为当前时间的随机数,在多线程的情况下,重复的概率居然还挺高的。
所以,原因就出现了,当发现图片大小不对,试图删除图片时,图片被另一个线程占用,无法删除。(关于名字重复的问题,就是两个线程在同一个毫秒启动了,所以随机数也是相等的(种子相等),因此有些图片就会和其它图片写入同一个图片文件,导致出现异常情况。)
总结一下:
图片异常的情况有两种:
1.网络原因,导致图片无法完整下载,这是无法解决的,只能删除。
2.图片名字重复,导致多张图片数据被写入同一张图片当中,这是程序错误,可以避免的。
解决方法:
对于第一种情况,只需要把错误的图片删除即可;
对于第二种情况,要避免图片名字重复,所以我重新设计了图片的命名方法,
采用:当前时间的毫秒数+UUID随机数(查阅资料,这个挺好用的)作为文件的命名方式。注:UUID 也有一个缺点,就是名字太长了。
修改后的源文件:
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.UUID;
public class DownLoadUtil {
public static void downLoad(List<String> strs) {
strs.stream().forEach(u->{
try {
URL url = new URL(u);
URLConnection urlConnection = url.openConnection();
String contentType = urlConnection.getContentType();
//获取资源文件的大小
long size = urlConnection.getContentLengthLong();
if (contentType != null && contentType.contains("image/")) {
//获取图片的类型:content type
String filetype = null;
if (contentType.contains("jpeg")) {
filetype = ".jpeg";
} else if (contentType.contains("jpg")) {
filetype = ".jpg";
} else{
filetype = ".png";
} //gif 格式图片,似乎无法正常显示
//使用当前时间戳+随机数+contentType 作为文件名
String filename = System.currentTimeMillis()+UUID.randomUUID().toString()+filetype;
//使用线程进行下载
Runnable r = ()->{
File imageFile = new File(Client.downloadFilePath, filename);
try(
BufferedInputStream bis = new BufferedInputStream(urlConnection.getInputStream());
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(imageFile))){
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
} catch (IOException e) {
System.out.println("下载失败!");
e.printStackTrace();
}
//对下载失败的图片进行删除。
if (imageFile.length() != size) {
boolean result = imageFile.delete();
System.out.println(imageFile.length()+" "+size+" "+filename+" 删除结果:"+result);
//大小不符合,说明图片下载有问题,删除图片。
} else {
System.out.println("下载完成:"+filename);
}
};
Thread t = new Thread(r);
t.start(); //启动下载线程。
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("链接错误!");
}
});
}
}运行截图
这样网络原因错误的图片直接删除,代码原因的错误,已经改正了。
注:还有一些图片无法显示,这个可能是官方不允许我们进行爬取,有的图片,爬取的就是不允许爬取那种图片,还有一些图片,不支持格式。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!