
Maison >Périphériques technologiques >IA >Le grand modèle peut « rédiger » des articles tout seul, avec formules et références. La version d'essai est désormais en ligne.
Le grand modèle peut « rédiger » des articles tout seul, avec formules et références. La version d'essai est désormais en ligne.

- 王林avant
- 2023-04-20 11:10:06962parcourir
Ces dernières années, avec l'avancement de la recherche dans divers domaines, la littérature et les données scientifiques ont explosé, rendant de plus en plus difficile pour les chercheurs universitaires de découvrir des informations utiles à partir de grandes quantités d'informations. Habituellement, les gens utilisent les moteurs de recherche pour obtenir des connaissances scientifiques, mais les moteurs de recherche ne peuvent pas organiser les connaissances scientifiques de manière autonome.
Maintenant, une équipe de recherche de Meta AI a proposé Galactica, un nouveau modèle de langage à grande échelle capable de stocker, combiner et raisonner sur les connaissances scientifiques.

- Adresse papier : https://galactica.org/static/paper.pdf
- Adresse d'essai : https://galactica.org/
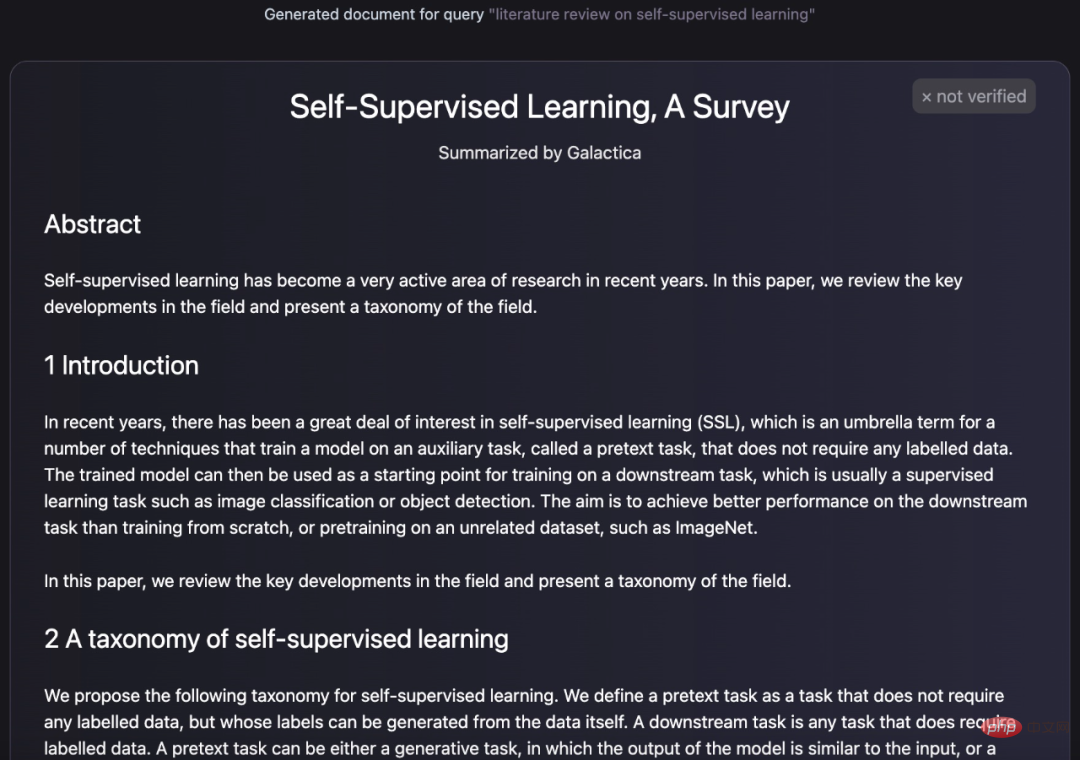
Modèle Galactica Quelle est sa puissance ? Il peut résumer et résumer un article de révision par lui-même :
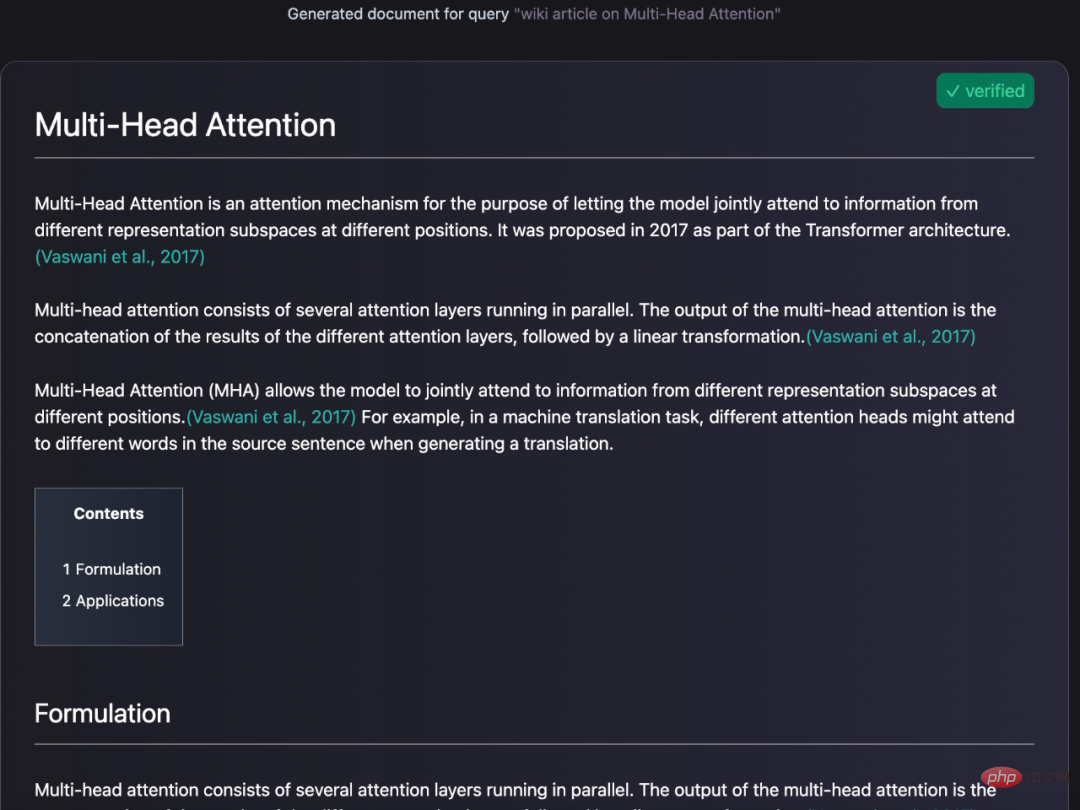
Il peut également générer des requêtes encyclopédiques pour les entrées :
Donner des réponses éclairées aux questions soulevées :
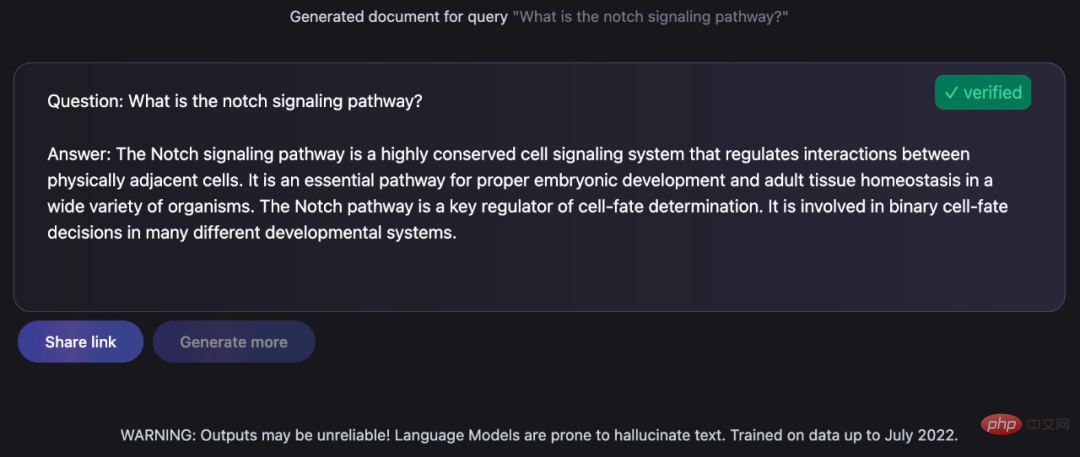
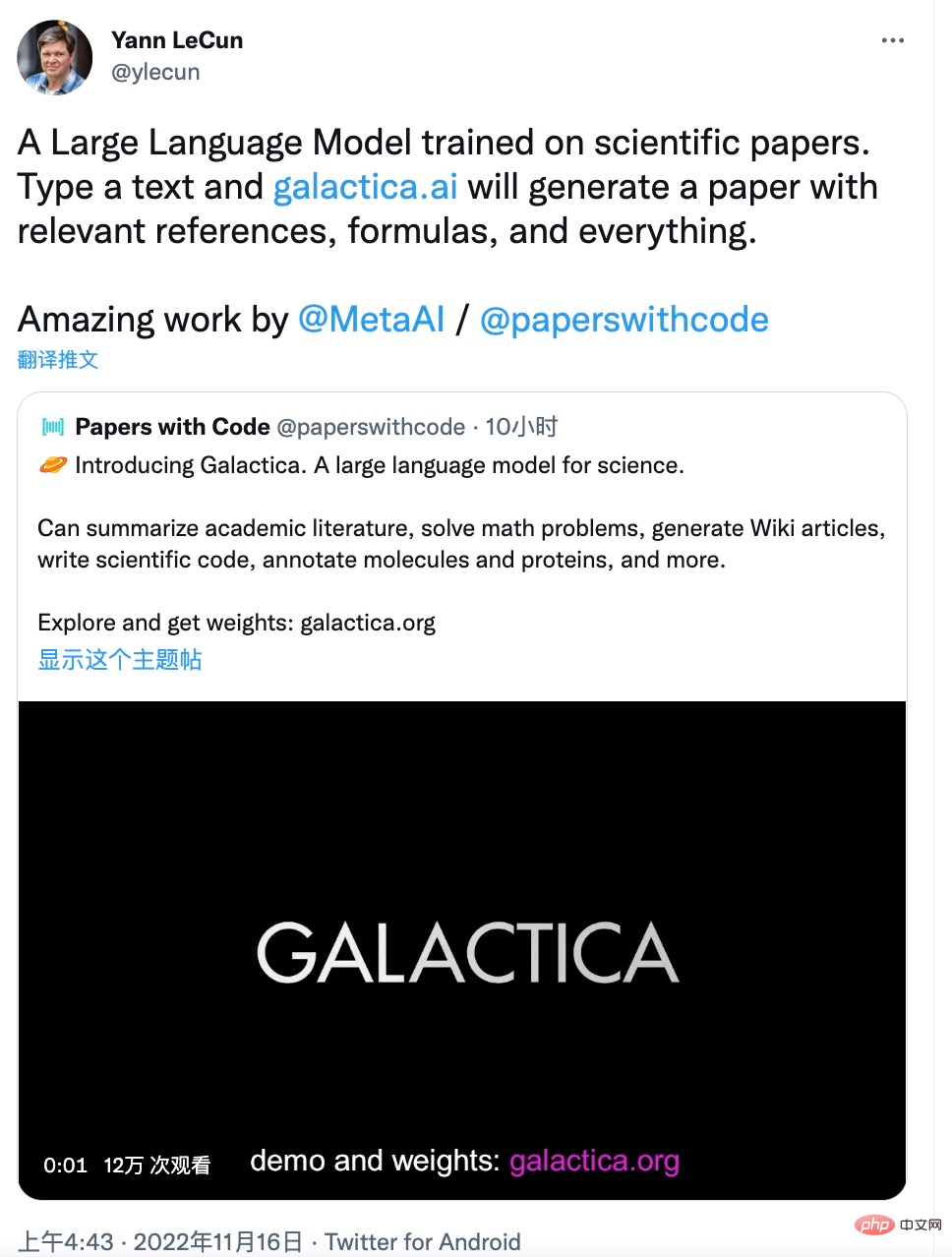
Ces tâches restent un défi pour les anthropologues, mais Galactica les a bien accomplies. Yann LeCun, lauréat du prix Turing, a également tweeté ses éloges :
Jetons un coup d'œil aux détails spécifiques du modèle Galactica.
Aperçu du modèle
Le modèle Galactica est formé sur un vaste corpus scientifique d'articles, de documents de référence, de bases de connaissances et de nombreuses autres sources, y compris plus de 48 millions d'articles, de manuels et de documents, des millions de composés et de connaissances sur les protéines, des connaissances scientifiques. sites Web, encyclopédies, etc. Contrairement aux modèles linguistiques existants qui s'appuient sur du texte non organisé basé sur un robot d'exploration Web, le corpus utilisé pour la formation Galactica est de haute qualité et hautement organisé. Cette étude a entraîné le modèle pour plusieurs époques sans surajustement, où les performances des tâches en amont et en aval ont été améliorées grâce à l'utilisation de jetons répétés.
Le Galactica surpasse les modèles existants dans une gamme de tâches scientifiques. Sur les tâches d'exploration des connaissances techniques telles que les équations LaTeX, les performances de Galactica et GPT-3 sont de 68,2 % contre 49,0 %. Galactica excelle également en inférence, surpassant largement Chinchilla sur le benchmark mathématique MMLU.
Galactica surpasse également BLOOM et OPT-175B sur BIG-bench bien qu'il n'ait pas été formé sur un corpus commun. De plus, il a atteint de nouveaux sommets de performances de 77,6 % et 52,9 % sur les tâches en aval telles que le développement de PubMedQA et MedMCQA.
En termes simples, la recherche résume le raisonnement étape par étape dans des jetons spéciaux pour imiter le fonctionnement interne. Cela permet aux chercheurs d’interagir avec des modèles en utilisant le langage naturel, comme indiqué ci-dessous dans l’interface d’essai de Galactica.
Il convient de mentionner qu'en plus de la génération de texte, Galactica peut également effectuer des tâches multimodales impliquant des formules chimiques et des séquences de protéines. Cela contribuera au domaine de la découverte de médicaments.
Détails de mise en œuvre
Le corpus de cet article contient 106 milliards de jetons, provenant d'articles, de références, d'encyclopédies et d'autres documents scientifiques. On peut dire que ces recherches incluent à la fois des ressources en langage naturel (articles, ouvrages de référence) et des séquences dans la nature (séquences protéiques, formes chimiques). Les détails du corpus sont présentés dans les tableaux 1 et 2 .
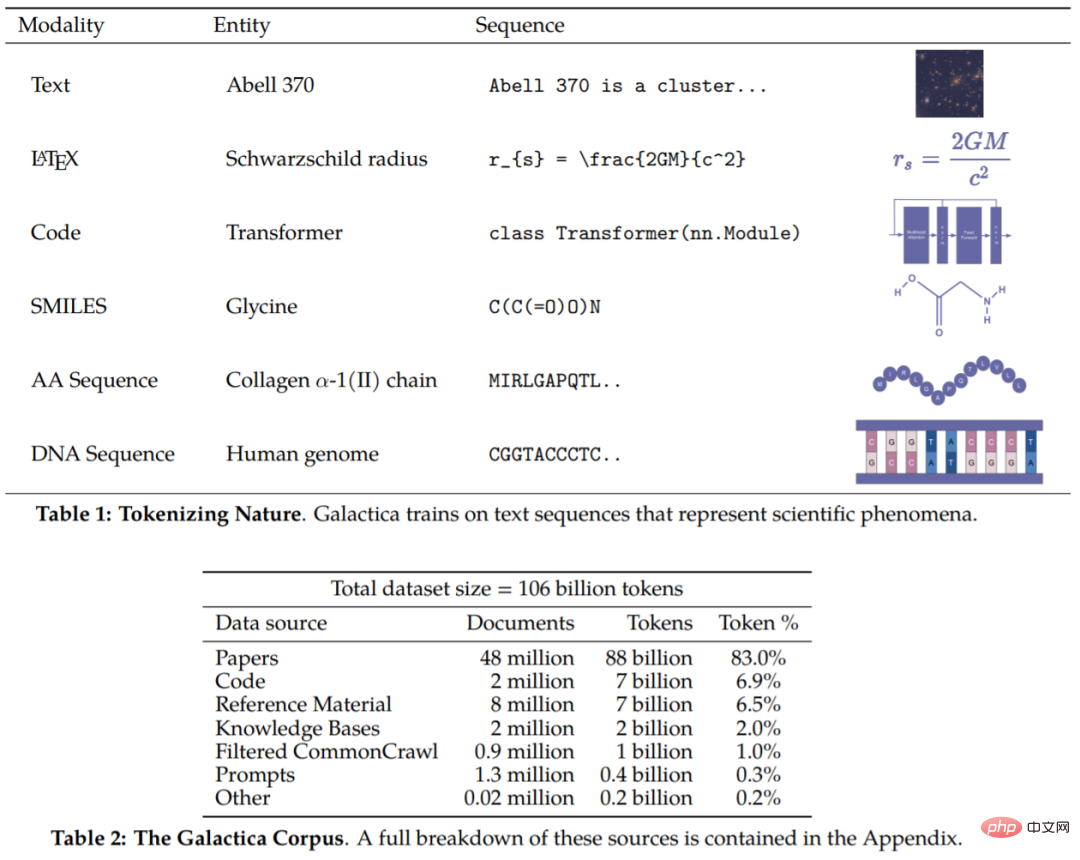
Maintenant que nous avons le corpus, la prochaine étape consiste à savoir comment exploiter les données. D’une manière générale, la conception de la tokenisation est très importante. Par exemple, si les séquences protéiques sont écrites en termes de résidus d’acides aminés, alors la tokenisation basée sur les caractères est appropriée. Afin de réaliser la tokenisation, cette étude a réalisé une tokenisation spécialisée sur différentes modalités. Les manifestations spécifiques incluent (sans s'y limiter) :
- Référence : utilisez des jetons de référence spéciaux [START_REF] et [END_REF] pour envelopper les références
- Raisonnement étape par étape : utilisez des jetons de mémoire de travail pour encapsuler ; Raisonnement et simulation étape par étape Contexte de la mémoire de travail interne ;
- Nombre : divisez les nombres en jetons séparés. Par exemple, 737612.62 → 7,3,7,6,1,2,.,6,2 ; formule
- SMILES : enveloppez la séquence avec [START_SMILES] et [END_SMILES] et appliquez une tokenisation basée sur les caractères. De même, cette étude utilise [START_I_SMILES] et [END_I_SMILES] pour représenter les SMILES isomères. Par exemple : C(C(=O)O)N→C, (,C,(,=,O,),O,),N;
- Séquence d'ADN : appliquez une tokenisation basée sur les caractères à chaque nucléotide. les bases sont considérées comme un jeton, où les jetons de départ sont [START_DNA] et [END_DNA]. Par exemple, CGGTACCCTC → C, G, G, T, A, C, C, C, T, C.
La figure 4 ci-dessous montre un exemple de traitement des références à un article. Lors du traitement des références, utilisez des identifiants globaux et les jetons spéciaux [START_REF] et [END_REF] pour indiquer le lieu de la référence.

Une fois l'ensemble de données traité, l'étape suivante consiste à savoir comment le mettre en œuvre. Galactica a apporté les modifications suivantes basées sur l'architecture du Transformer :
- Activation GeLU : utilisez l'activation GeLU pour les modèles de différentes tailles
- Fenêtre contextuelle : pour les modèles de tailles différentes, utilisez une fenêtre contextuelle de 2048 longueurs ;
- Aucun biais : suivez PaLM, aucun biais n'est utilisé dans les spécifications de noyau ou de couche dense
- Apprendre les intégrations de position : apprendre les intégrations de position pour le modèle
- Glossaire : Utilisez BPE pour créer un glossaire ; contenant 50 000 jetons.
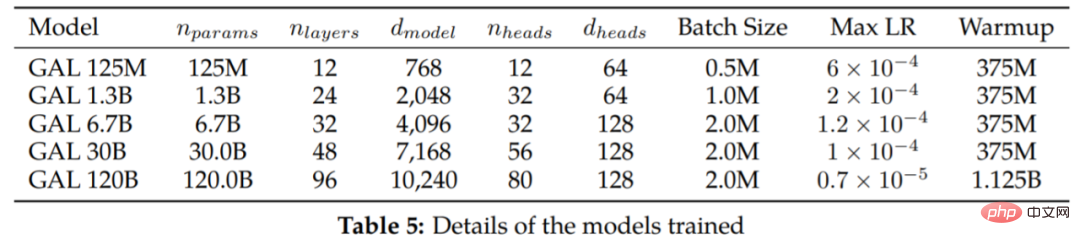
Le tableau 5 répertorie les modèles de différentes tailles et hyperparamètres d'entraînement.
Expérience
Les jetons en double sont considérés comme inoffensifs
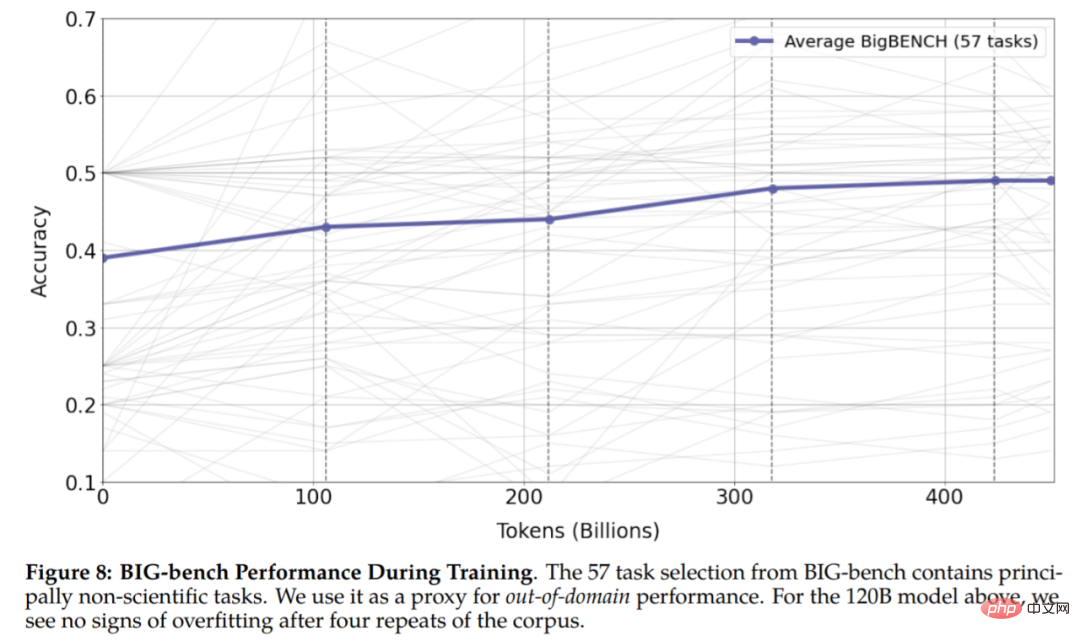
Comme le montre la figure 6, après quatre époques de formation, la perte de validation continue de diminuer. Le modèle avec les paramètres 120B ne commence à surajuster qu'au début de la cinquième époque. Ceci est inattendu car les recherches existantes montrent que les jetons en double peuvent nuire aux performances. L'étude a également révélé que les modèles 30B et 120B présentaient un double effet de déclin selon les époques, où la perte de validation plafonnait (ou augmentait), suivie d'un déclin. Cet effet devient plus fort après chaque époque, notamment pour le modèle 120B en fin d'entraînement.
Figure 8 Les résultats montrent qu'il n'y a aucun signe de surapprentissage dans l'expérience, ce qui montre que les jetons répétés peuvent améliorer les performances des tâches en aval et en amont.
Autres résultats
Il est trop lent de taper des formules, vous pouvez désormais générer du LaTeX avec des invites :

Dans les réactions chimiques, Galactica est invité à prédire les réactions dans les équations chimiques LaTeX Produit de , le modèle peut raisonner uniquement sur la base des réactifs, et les résultats sont les suivants :

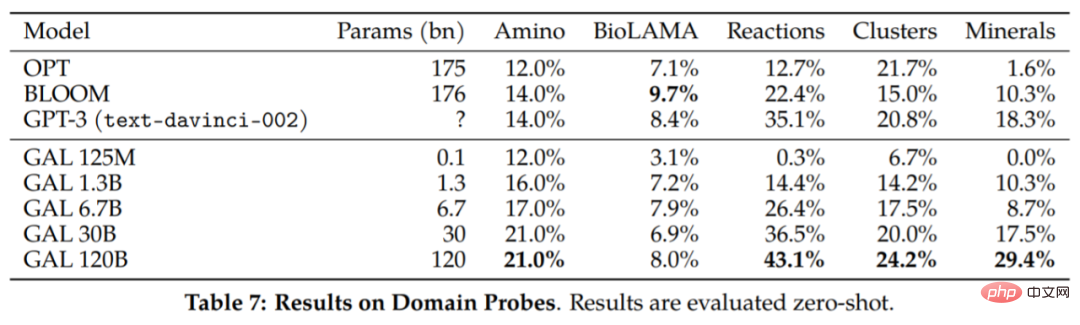
Quelques autres résultats sont rapportés dans le tableau 7 :
Les capacités de raisonnement du Galactica. L'étude est d'abord évaluée sur la référence mathématique MMLU et les résultats de l'évaluation sont présentés dans le tableau 8. Le Galactica fonctionne très bien par rapport au modèle de base plus grand, et l'utilisation de jetons semble améliorer les performances du Chinchilla, même pour le plus petit modèle Galactica 30B.
L'étude a également évalué l'ensemble de données MATH pour explorer davantage les capacités de raisonnement de Galactica :
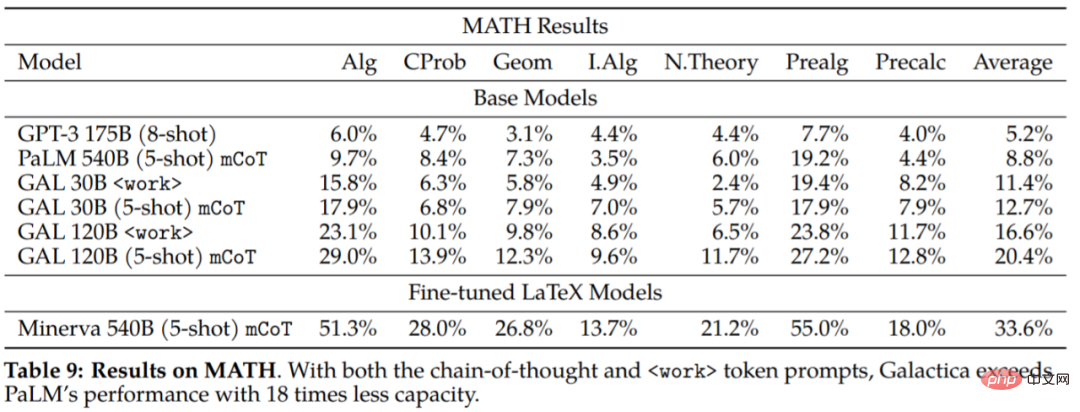
On peut conclure des résultats expérimentaux : Galactica est nettement meilleur que le PaLM de base en termes d'enchaînement de pensées et d'incitation. Modèle. Cela suggère que Galactica est un meilleur choix pour gérer des tâches mathématiques. Les résultats de l'évaluation de
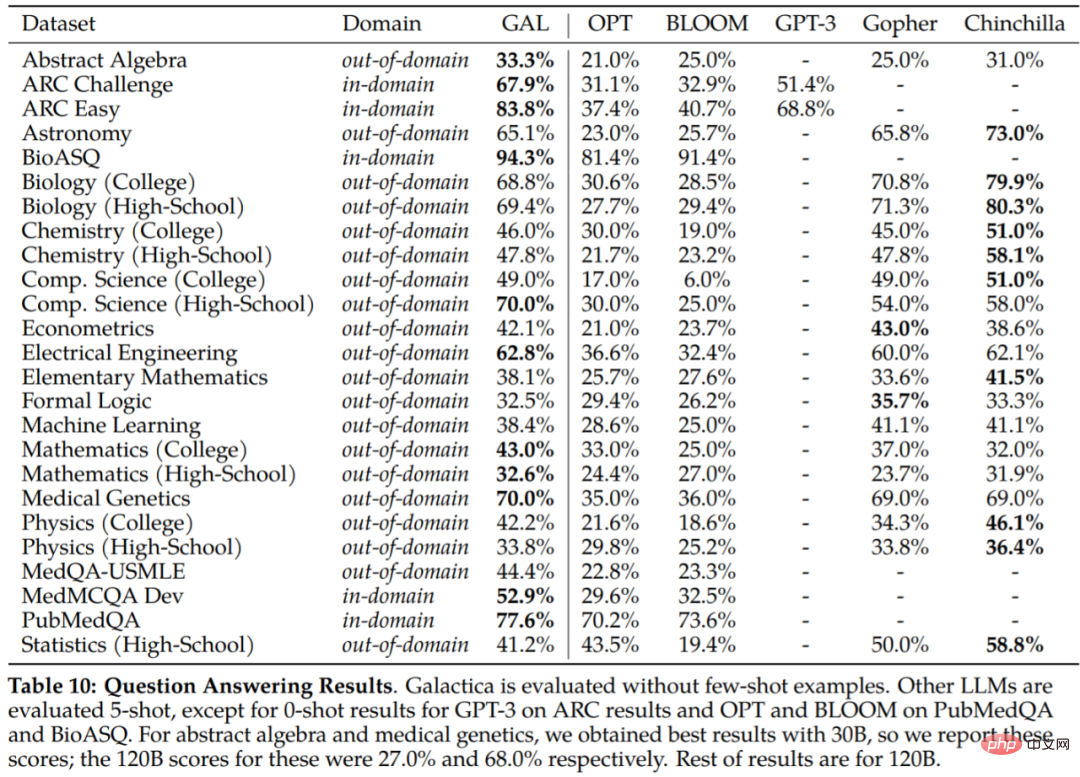
sur les tâches en aval sont présentés dans le tableau 10. Galactica surpasse considérablement les autres modèles de langage et surpasse les modèles plus grands dans la plupart des tâches (Gopher 280B). La différence de performance est plus grande que celle du Chinchilla, qui semble être plus fort sur un sous-ensemble de tâches : en particulier les matières du secondaire et les tâches moins mathématiques et gourmandes en mémoire. En revanche, Galactica a tendance à mieux performer dans les tâches de mathématiques et de niveau universitaire.
L’étude a également évalué la capacité du Chinchilla à prédire les citations en fonction du contexte d’entrée, un test important de la capacité du Chinchilla à organiser la littérature scientifique. Les résultats sont les suivants :
Pour plus de contenu expérimental, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI