
Maison >développement back-end >Tutoriel Python >Huit bibliothèques Python pour améliorer la productivité de la science des données !
Huit bibliothèques Python pour améliorer la productivité de la science des données !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-18 20:28:011379parcourir
1. Optuna
Optuna est un framework d'optimisation d'hyperparamètres open source qui peut trouver automatiquement les meilleurs hyperparamètres pour les modèles d'apprentissage automatique.
L'alternative la plus basique (et probablement la plus connue) est GridSearchCV de sklearn, qui essaiera plusieurs combinaisons d'hyperparamètres et choisira la meilleure en fonction d'une validation croisée.
GridSearchCV essaiera des combinaisons dans l'espace précédemment défini. Par exemple, pour un classificateur de forêt aléatoire, vous souhaiterez peut-être tester la profondeur maximale de plusieurs arbres différents. GridSearchCV fournit toutes les valeurs possibles pour chaque hyperparamètre et examine toutes les combinaisons.
Optuna utilise son propre historique de tentatives dans un espace de recherche défini pour déterminer les valeurs à essayer ensuite. La méthode qu'il utilise est un algorithme d'optimisation bayésien appelé « Estimateur Parzen structuré en arbre ».
Cette approche différente signifie qu'au lieu d'essayer inutilement chaque valeur, il recherche le meilleur candidat avant de l'essayer, économisant ainsi du temps qui autrement serait consacré à essayer des alternatives peu prometteuses (et donnerait probablement aussi de meilleurs résultats).
Enfin, il est indépendant du framework, ce qui signifie que vous pouvez l'utiliser avec TensorFlow, Keras, PyTorch ou tout autre framework ML.
2. ITMO_FS
ITMO_FS est une bibliothèque de sélection de fonctionnalités qui peut effectuer une sélection de fonctionnalités pour les modèles ML. Moins vous avez d'observations, plus vous devez être prudent avec trop de fonctionnalités pour éviter le surajustement. Par « prudent », j’entends que vous devriez standardiser votre modèle. Généralement, un modèle plus simple (moins de fonctionnalités) est plus facile à comprendre et à interpréter.
Les algorithmes ITMO_FS sont divisés en 6 catégories différentes : filtres supervisés, filtres non supervisés, wrappers, hybrides, embarqués, ensembles (bien qu'ils se concentrent principalement sur les filtres supervisés).
Un exemple simple d'algorithme de « filtre supervisé » consiste à sélectionner des caractéristiques en fonction de leur corrélation avec une variable cible. Avec la « sélection arrière », vous pouvez essayer de supprimer des fonctionnalités une par une et confirmer comment ces fonctionnalités affectent la capacité prédictive du modèle.
Voici un exemple trivial de la façon d'utiliser ITMO_FS et de son impact sur les scores des modèles :
>>> from sklearn.linear_model import SGDClassifier >>> from ITMO_FS.embedded import MOS >>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2) >>> sel = MOS() >>> trX = sel.fit_transform(X, y, smote=False) >>> cl1 = SGDClassifier() >>> cl1.fit(X, y) >>> cl1.score(X, y) 0.9033333333333333 >>> cl2 = SGDClassifier() >>> cl2.fit(trX, y) >>> cl2.score(trX, y) 0.9433333333333334
ITMO_FS est une bibliothèque relativement nouvelle, elle est donc encore un peu instable, mais je recommande quand même de l'essayer.
3. shap-hypetune
Jusqu'à présent, nous avons vu des bibliothèques pour la sélection de fonctionnalités et le réglage des hyperparamètres, mais pourquoi ne pas utiliser les deux en même temps ? C'est ce que fait Shap-Hypetune.
Commençons par comprendre ce qu'est « SHAP » :
« SHAP (SHapley Additive exPlanations) est une méthode de théorie des jeux pour interpréter la sortie de n'importe quel modèle d'apprentissage automatique.
SHAP sert à expliquer l'un des plus. » bibliothèques largement utilisées pour les modèles, il fonctionne en générant l'importance de chaque caractéristique pour la prédiction finale du modèle.
D'autre part, shap-hypertune profite de cette approche pour sélectionner les meilleures fonctionnalités mais aussi les meilleurs hyperparamètres. Pourquoi veux-tu les fusionner ? La sélection indépendante de fonctionnalités et le réglage des hyperparamètres peuvent conduire à des choix sous-optimaux car leurs interactions ne sont pas prises en compte. Faire les deux simultanément prend non seulement cela en compte, mais permet également de gagner du temps de codage (bien que le temps d'exécution puisse augmenter en raison de l'espace de recherche accru).
La recherche peut être effectuée de 3 manières : recherche par grille, recherche aléatoire ou recherche bayésienne (en plus, elle peut être parallélisée).
Cependant, shap-hypertune ne fonctionne que sur les modèles à dégradé amélioré !
4. PyCaret
PyCaret est une bibliothèque d'apprentissage automatique open source à faible code qui peut automatiser les flux de travail d'apprentissage automatique. Il couvre l'analyse exploratoire des données, le prétraitement, la modélisation (y compris l'interprétabilité) et le MLOps.
Jetons un coup d'œil à quelques exemples concrets sur leur site Web pour voir comment cela fonctionne :
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# compare models
best = compare_models()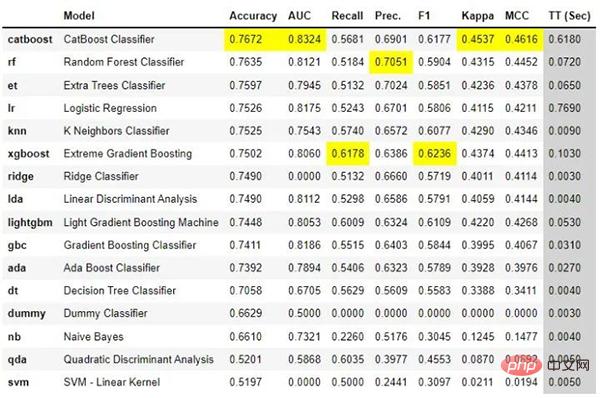
Avec seulement quelques lignes de code, vous pouvez essayer plusieurs modèles et comparer les principales mesures de classification. comparé.
Il permet également de créer une application de base pour interagir avec le modèle :
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice,target = 'Purchase')
lr = create_model('lr')
create_app(lr)Enfin, les fichiers API et Docker peuvent être facilement créés pour le modèle :
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice,target = 'Purchase')
lr = create_model('lr')
create_api(lr, 'lr_api')
create_docker('lr_api') Rien de plus simple que cela, n'est-ce pas ?
PyCaret est une bibliothèque très complète, il est difficile de tout couvrir ici, il est recommandé de la télécharger maintenant et de commencer à l'utiliser pour comprendre certaines de ses capacités en pratique.
5. floWeaver
FloWeaver peut générer des diagrammes Sankey à partir d'ensembles de données en streaming. Si vous ne savez pas ce qu'est un diagramme Sankey, voici un exemple :
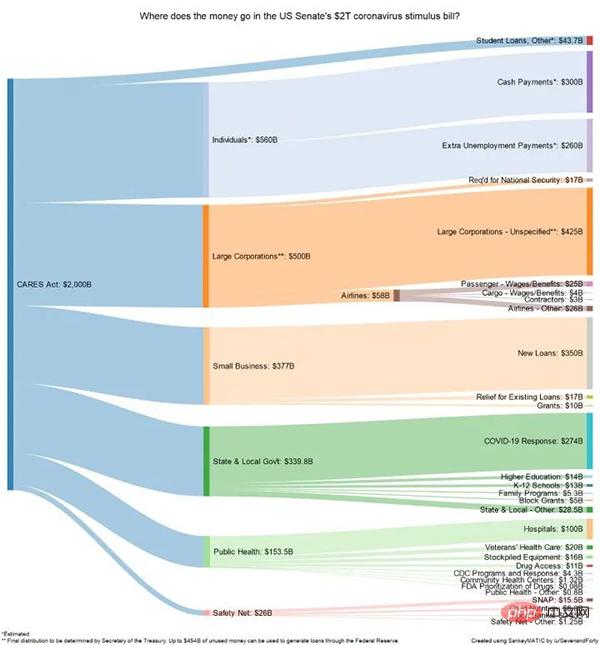
Ils sont très utiles pour afficher des données pour les entonnoirs de conversion, les parcours marketing ou les allocations budgétaires (exemple ci-dessus). Les données du portail doivent être au format suivant : "source x cible x valeur". Un tel tracé peut être créé avec une seule ligne de code (très spécifique, mais aussi très intuitif).
6、Gradio
如果你阅读过敏捷数据科学,就会知道拥有一个让最终用户从项目开始就与数据进行交互的前端界面是多么有帮助。一般情况下在Python中最常用是 Flask,但它对初学者不太友好,它需要多个文件和一些 html、css 等知识。
Gradio 允许您通过设置输入类型(文本、复选框等)、功能和输出来创建简单的界面。尽管它似乎不如 Flask 可定制,但它更直观。
由于 Gradio 现在已经加入 Huggingface,可以在互联网上永久托管 Gradio 模型,而且是免费的!
7、Terality
理解 Terality 的最佳方式是将其视为“Pandas ,但速度更快”。这并不意味着完全替换 pandas 并且必须重新学习如何使用df:Terality 与 Pandas 具有完全相同的语法。实际上,他们甚至建议“import Terality as pd”,并继续按照以前的习惯的方式进行编码。
它快多少?他们的网站有时会说它快 30 倍,有时快 10 到 100 倍。
另一个重要是 Terality 允许并行化并且它不在本地运行,这意味着您的 8GB RAM 笔记本电脑将不会再出现 MemoryErrors!
但它在背后是如何运作的呢?理解 Terality 的一个很好的比喻是可以认为他们在本地使用的 Pandas 兼容的语法并编译成 Spark 的计算操作,使用Spark进行后端的计算。所以计算不是在本地运行,而是将计算任务提交到了他们的平台上。
那有什么问题呢?每月最多只能免费处理 1TB 的数据。如果需要更多则必须每月至少支付 49 美元。1TB/月对于测试工具和个人项目可能绰绰有余,但如果你需要它来实际公司使用,肯定是要付费的。
8、torch-handle
如果你是Pytorch的使用者,可以试试这个库。
torchhandle是一个PyTorch的辅助框架。它将PyTorch繁琐和重复的训练代码抽象出来,使得数据科学家们能够将精力放在数据处理、创建模型和参数优化,而不是编写重复的训练循环代码。使用torchhandle,可以让你的代码更加简洁易读,让你的开发任务更加高效。
torchhandle将Pytorch的训练和推理过程进行了抽象整理和提取,只要使用几行代码就可以实现PyTorch的深度学习管道。并可以生成完整训练报告,还可以集成tensorboard进行可视化。
from collections import OrderedDict
import torch
from torchhandle.workflow import BaseConpython
class Net(torch.nn.Module):
def __init__(self, ):
super().__init__()
self.layer = torch.nn.Sequential(OrderedDict([
('l1', torch.nn.Linear(10, 20)),
('a1', torch.nn.ReLU()),
('l2', torch.nn.Linear(20, 10)),
('a2', torch.nn.ReLU()),
('l3', torch.nn.Linear(10, 1))
]))
def forward(self, x):
x = self.layer(x)
return x
num_samples, num_features = int(1e4), int(1e1)
X, Y = torch.rand(num_samples, num_features), torch.rand(num_samples)
dataset = torch.utils.data.TensorDataset(X, Y)
trn_loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=0, shuffle=True)
loaders = {"train": trn_loader, "valid": trn_loader}
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = {"fn": Net}
criterion = {"fn": torch.nn.MSELoss}
optimizer = {"fn": torch.optim.Adam,
"args": {"lr": 0.1},
"params": {"layer.l1.weight": {"lr": 0.01},
"layer.l1.bias": {"lr": 0.02}}
}
scheduler = {"fn": torch.optim.lr_scheduler.StepLR,
"args": {"step_size": 2, "gamma": 0.9}
}
c = BaseConpython(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
conpython_tag="ex01")
train = c.make_train_session(device, dataloader=loaders)
train.train(epochs=10)定义一个模型,设置数据集,配置优化器、损失函数就可以自动训练了,是不是和TF差不多了。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!