

 Périphériques technologiquesIAModélisation de jumeaux numériques basée sur l'apprentissage automatique et l'optimisation contrainte
Périphériques technologiquesIAModélisation de jumeaux numériques basée sur l'apprentissage automatique et l'optimisation contrainteModélisation de jumeaux numériques basée sur l'apprentissage automatique et l'optimisation contrainte

Traducteur | Zhu Xianzhong
Reviewer | Sun Shujuan
Introduction
De nos jours, la science des données est largement utilisée pour créer des jumeaux numériques (Digital Twins) - les jumeaux numériques sont des homologues numériques de systèmes ou de processus physiques du monde réel qui peuvent être utilisés Simulation et la prédiction du comportement des entrées, la surveillance, la maintenance, la planification, etc. Bien que les jumeaux numériques tels que les robots de service client cognitifs soient courants dans les applications quotidiennes, dans cet article, je comparerai les deux types différents de modélisation en illustrant deux types différents de jumeaux numériques dans la technologie de science des données Twin.
Deux domaines de la science des données largement utilisés des jumeaux numériques abordés dans cet article sont les suivants :
a) Analyse diagnostique et prédictive : Dans cette méthode d'analyse, à partir d'une série d'entrées, le jumeau numérique diagnostique la cause ou prédit le comportement futur du système. Des modèles d'apprentissage automatique basés sur l'IoT sont utilisés pour créer des machines et des usines intelligentes. Ce modèle permet d'analyser les entrées des capteurs en temps réel pour diagnostiquer, prédire et prévenir les problèmes et pannes futurs avant qu'ils ne surviennent.
b) Analyse prescriptive : Cette méthode d'analyse simule l'ensemble du réseau afin de déterminer la meilleure ou la meilleure solution parmi un grand nombre de candidats étant donné un ensemble de variables et de contraintes à respecter. Une solution réalisable, généralement visée. maximiser les objectifs commerciaux déclarés tels que le débit, l'utilisation, le rendement, etc. Ces problèmes d'optimisation sont largement utilisés dans le domaine de la planification et de l'ordonnancement de la chaîne d'approvisionnement, par exemple lorsqu'un prestataire logistique crée un planning pour ses ressources (véhicules, personnel) afin de maximiser les délais de livraison, également lorsqu'un fabricant crée un planning de cette manière ; qui optimisent l'utilisation des machines et des opérateurs pour obtenir une livraison OTIF (On Time In Full) maximale. La technique de science des données utilisée ici est l'optimisation mathématique contrainte, un algorithme qui utilise des solveurs puissants pour résoudre des problèmes complexes axés sur la décision.
En résumé, les modèles ML prédisent les résultats possibles pour un ensemble donné de fonctionnalités d'entrée sur la base de données historiques, et les modèles d'optimisation vous aident à décider, si le résultat prédit se produit, comment vous devez prévoir de le traiter/l'atténuer/l'exploiter, en fonction de votre entreprise. a plusieurs objectifs potentiellement concurrents que vous pouvez choisir d’atteindre avec des ressources limitées.
Ces deux domaines de la science des données, tout en partageant certains outils (comme les bibliothèques Python), mobilisent des data scientists aux compétences complètement différentes - ils nécessitent souvent des façons différentes de penser et de modéliser les problèmes métier. Essayons donc de comprendre et de comparer les méthodes impliquées afin qu’un data scientist expérimenté dans un domaine puisse comprendre et exploiter de manière croisée les compétences et techniques qui peuvent être applicables dans un autre domaine.
Cas d'application du modèle jumeau numérique
À titre de comparaison, considérons un modèle jumeau du processus d'analyse des causes profondes (RCA) de production basé sur le ML, dont le but est de diagnostiquer les défauts ou anomalies trouvés dans le produit fini ou le processus de fabrication à la racine. cause. Cela aidera les chefs de service à éliminer les causes profondes les plus probables sur la base des prédictions de l'outil, à finalement identifier les problèmes et à mettre en œuvre des CAPA (actions correctives et préventives : actions correctives et préventives) et à parcourir tous les enregistrements de maintenance des machines rapidement et sans dépenser beaucoup de main d'œuvre, opérateur. enregistrements historiques, processus SOP (Standard Operating Procedure : Standard Operating Procedure), entrée du capteur IoT, etc. L’objectif est de minimiser les temps d’arrêt des machines, les pertes de production et d’améliorer l’utilisation des ressources.
Techniquement, cela peut être considéré comme un problème de classification multi-classes. Dans ce problème, en supposant qu'il existe un certain défaut, le modèle tente de prédire la probabilité de chacun d'un ensemble de causes possibles, telles que liées à la machine, liées à l'opérateur, liées aux instructions de processus, liées aux matières premières. , ou autre chose, ainsi que des raisons plus fines telles que l'étalonnage de la machine, la maintenance de la machine, les compétences des opérateurs, la formation des opérateurs, etc. sous ces étiquettes de classification de premier niveau. Bien que la solution optimale à cette situation nécessite l'évaluation de plusieurs modèles ML complexes, pour souligner l'objectif de cet article, simplifions un peu - supposons qu'il s'agisse d'un problème de régression logistique multinomiale (pour des raisons qui seront expliquées clairement dans le prochain section).
À titre de comparaison, considérons un modèle jumeau optimisé du processus de planification de la production, qui génère un calendrier qui tente de maximiser les objectifs, tels que la production ou les revenus. De tels calendriers automatisés aident les organisations à ajuster rapidement leurs ressources pour répondre aux nouvelles opportunités du marché (telles que la demande de médicaments due au COVID-19) ou pour maximiser l'impact de leurs matières premières, de leurs fournisseurs, de leurs prestataires logistiques et de leur mix client/marché. l’impact d’événements imprévus, tels que les récents goulots d’étranglement de la chaîne d’approvisionnement.
Au niveau de base pour modéliser tout problème commercial, le développement d'un tel jumeau numérique nécessite la prise en compte des éléments suivants :
A Caractéristiques ou dimensions d'entrée
B Données d'entrée – les valeurs de ces dimensions
C. vers la sortie Les règles de transformation de
D, sortie ou cible
Ensuite, analysons et comparons plus en profondeur ces facteurs dans l'apprentissage automatique (ML) et les modèles d'optimisation contraints :
A. Caractéristiques d'entrée : Ce sont les dimensions des données dans le système, adaptées à la fois au ML et à l'optimisation. Pour un modèle ML essayant de diagnostiquer les problèmes dans un processus de production, les fonctionnalités à prendre en compte peuvent inclure : les entrées IoT, les données historiques de maintenance de la machine, les compétences et informations de formation des opérateurs, les informations sur la qualité des matières premières, les SOP suivies (procédures d'exploitation standard) et d'autres contenus. .
De même, dans un environnement d'optimisation sous contraintes, les caractéristiques à prendre en compte comprendront : la disponibilité des équipements, la disponibilité des opérateurs, la disponibilité des matières premières, les horaires de travail, la productivité, les compétences, etc. caractéristiques typiques requises pour élaborer un plan de production optimal.
B. Données d'entrée : C'est là que les deux méthodes ci-dessus utilisent les valeurs propres de manière significativement différente. Parmi eux, les modèles ML nécessitent une grande quantité de données historiques pour la formation. Cependant, un travail important lié à la préparation, à la gestion et à la normalisation des données est souvent nécessaire avant que les données puissent être introduites dans un modèle. Il est important de noter qu'un historique est un enregistrement d'un événement qui s'est réellement produit (comme une panne de machine ou un problème de compétence de l'opérateur ayant entraîné un rendement insuffisant), mais il ne s'agit généralement pas d'une simple combinaison de toutes les valeurs possibles que ces valeurs peuvent représenter. caractéristiques peuvent obtenir. En d’autres termes, l’historique des transactions contiendra plus d’enregistrements pour les scénarios qui se produisent fréquemment, et relativement moins d’enregistrements pour certains autres scénarios – incluant peut-être rarement des scénarios qui se produisent rarement. L'objectif de la formation d'un modèle est d'apprendre la relation entre les fonctionnalités et les étiquettes de sortie et de prédire des étiquettes précises, même lorsqu'il y a peu ou pas de valeurs de fonctionnalités ou de combinaisons de valeurs de fonctionnalités dans les données d'entraînement.
D'autre part, pour les méthodes d'optimisation, les valeurs caractéristiques sont généralement conservées comme données réelles, par exemple les jours, les lots, les délais, la disponibilité des matières premières par date, les calendriers de maintenance, les temps de changement de machine, les étapes du processus, les compétences de l'opérateur. , etc. La principale différence avec les modèles ML est que le traitement des données d'entrée nécessite la génération d'une table d'index pour chaque combinaison valide possible de valeurs de caractéristiques des données de base (par exemple, jours, compétences, machines, opérateurs, types de processus, etc.) pour former une liste de partie des solutions réalisables. Par exemple, l'opérateur A utilise la machine M1 le premier jour de la semaine, exécutant l'étape 1 du processus au niveau de compétence S1, ou l'opérateur B utilise la machine M1 le deuxième jour, exécutant l'étape 1 au niveau de compétence S2 ; même pour chaque combinaison possible d'opérateur, de machine, de niveau de compétence, de date, etc., que ces combinaisons se soient réellement produites dans le passé ou non. Il en résulte un très grand ensemble d'enregistrements de données d'entrée fournis au moteur d'optimisation. Le but d'un modèle d'optimisation est de sélectionner une combinaison spécifique de valeurs propres conforme aux contraintes données tout en maximisant (ou minimisant) l'équation objective.
C. Règles de conversion entrée-sortie : C'est également une différence significative entre les deux méthodes. Bien que les modèles de ML et d'optimisation soient basés sur des théories mathématiques avancées, la modélisation mathématique et la programmation de problèmes commerciaux complexes dans les méthodes d'optimisation nécessitent généralement plus d'efforts que le ML, ce qui sera reflété dans l'introduction suivante.
La raison est qu'en ML, avec l'aide de bibliothèques open source comme scikit-learn, de frameworks tels que Pytorch ou Tensorflow, et même de modèles ML/deep learning des fournisseurs de services cloud, les règles de conversion des entrées en sortie sont complètement laissées. au modèle à trouver, qui comprend également la tâche d'effectuer une correction des pertes afin d'en dériver des règles optimales (poids, biais, fonctions d'activation, etc.). La principale responsabilité d'un data scientist est de garantir la qualité et l'exhaustivité des fonctionnalités d'entrée et de leurs valeurs.
Avec les méthodes d'optimisation, ce n'est pas le cas, car les règles sur la façon dont les entrées interagissent et se transforment en sorties doivent être écrites à l'aide d'équations détaillées puis transmises à des solveurs tels que Gurobi, CPLEX, etc., afin de trouver le plan de solution optimal ou réalisable. De plus, la formulation de problèmes commerciaux sous forme d’équations mathématiques nécessite une compréhension approfondie des interrelations dans le processus de modélisation et nécessite que les data scientists travaillent en étroite collaboration avec les analystes commerciaux.
Ci-dessous, illustrons cela avec un diagramme schématique d'un modèle de régression logistique pour une application problème RCA (Root Cause Analysis) :
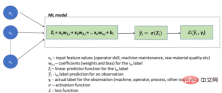
Modèle ML de régression logistique
Notez que dans ce cas, en fonction des données d'entrée La tâche de calculer les règles (Zᵢ) qui génèrent les résultats est laissée au modèle, tandis que les data scientists sont généralement occupés à utiliser des matrices de confusion bien définies, le RMSE et d'autres techniques de mesure pour obtenir des prédictions précises de manière visuelle.
Nous pouvons comparer cela à la manière dont les plans de production sont générés grâce à des méthodes d'optimisation :
(I) La première étape consiste à définir les règles métier (contraintes) qui encapsulent le processus de planification.
Voici un exemple de plan de production :
Tout d'abord, nous définissons quelques variables d'entrée (dont certaines peuvent être des variables de décision, utilisées pour atteindre les objectifs) :
- Bᵦ,p,ᵢ——Variable binaire, indiquant si le lot β (dans le tableau des lots) du produit p (dans le tableau des produits) est programmé le i-ème jour.
- Oₒ,p,ᵢ – Variable binaire indiquant si l'opérateur à l'index o (dans la table des opérateurs) est programmé pour traiter un lot de produit p le jour i.
- Mm,p,ᵢ – Variable binaire indiquant si la machine d'index m (dans la table de la machine) est programmée pour traiter un lot de produit p le jour i.
et quelques coefficients :
- TOₒ, p – le temps qu'il faut à l'opérateur o pour traiter un lot de produit p.
- TMm,p——Le temps qu'il faut à la machine m pour traiter un lot de produit p.
- OAvₒ,ᵢ – Le nombre d'heures disponibles pour l'opérateur index o le jour i.
- MAvm,ᵢ——Le nombre d'heures disponibles pour la machine d'index m le jour i.
Dans ce cas, certaines contraintes (règles) peuvent être mises en œuvre à l'aide des éléments suivants :
a) Dans le plan, un lot spécifique ne peut être démarré qu'une seule fois.
Où, pour chaque lot de produits, Bt est le nombre total de lots, Pr est le nombre total de produits, et D est le nombre de jours dans le plan :
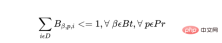
b) Un produit ne peut être que démarré une fois par jour sur un opérateur ou une machine.
Pour chaque jour pour chaque produit, où Op est l'ensemble de tous les opérateurs et Mc est l'ensemble de toutes les machines :
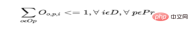
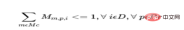
c) Le temps total passé sur le lot (tous les produits) ne doit pas dépasser ce jour-là Heures de disponibilité de l'opérateur et de la machine.
Pour chaque opérateur, il y a les contraintes suivantes :
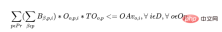
Pour chaque jour de chaque machine, il y a les contraintes suivantes :
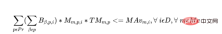
d) Si l'opérateur traite dans les 5 premiers jours du planning un lot de produit, tous les autres lots du même produit doivent être affectés au même opérateur. Cela maintient la continuité et la productivité des opérateurs.
Pour chaque opérateur et chaque produit, pour chaque jour j (à partir du jour 6), il y a des contraintes comme suit :
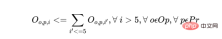
Ceux-ci ci-dessus sont quelques-unes des centaines de contraintes qui doivent être écrites dans le programme afin Les règles métier pour les scénarios de planification de production réels forment des équations mathématiques. Notez que ces contraintes sont des équations linéaires (ou, plus précisément, des équations entières mixtes). Cependant, la différence de complexité entre eux et les modèles ML de régression logistique est toujours très évidente.
(II) Une fois les contraintes déterminées, les objectifs de résultat doivent être définis. Il s'agit d'une étape critique et peut être un processus complexe, comme expliqué dans la section suivante.
(III) Enfin, les variables de décision d'entrée, les contraintes et les objectifs sont envoyés au solveur pour obtenir la solution (échéancier).
Le schéma schématique décrivant le jumeau numérique basé sur la méthode d'optimisation est le suivant :
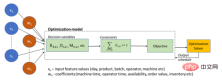
Modèle d'optimisation
D, sortie ou cible : Pour les modèles ML, selon le type de problème (classification, régression , clustering), il peut s'agir de résultats et de mesures très bien établis pour mesurer leur précision. Même si je n'aborderai pas ces questions dans cet article, compte tenu de la richesse des informations disponibles, il convient de noter que les résultats de divers modèles peuvent être évalués avec un haut degré d'automatisation, comme celui des principaux CSP (AWS Sagemaker, Azure). ML, etc.) .
Évaluer si un modèle optimisé génère le résultat correct est plus difficile. Les modèles d'optimisation fonctionnent en essayant de maximiser ou de minimiser une expression informatique appelée « objectif ». Tout comme les contraintes, les objectifs sont conçus en partie par les data scientists en fonction de ce que l'entreprise tente d'atteindre. Plus précisément, cela est réalisé en attachant des conditions de récompense et des conditions de pénalité aux variables de décision, dont l'optimiseur tente de maximiser la somme. Pour les problèmes du monde réel, il faut de nombreuses itérations pour trouver les bonnes pondérations pour différents objectifs afin de trouver un bon équilibre entre des objectifs parfois contradictoires.
Pour illustrer davantage l'exemple de planification de production ci-dessus, nous pourrions tout aussi bien concevoir les deux objectifs suivants :
a) Le calendrier doit être préchargé ; les lots doivent être planifiés dès que possible, et la capacité restante dans le plan doit être à la fin du plan. Nous pouvons le faire en attachant une pénalité d'un jour à un lot, qui augmentera progressivement chaque jour du planning.
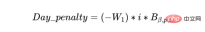
b) D'autre part, nous souhaitons également regrouper les lots d'un même produit afin que la partie ressource (opérateur et machine) soit utilisée de manière optimale, à condition que les lots respectent le délai de livraison et que le groupe ne dépasse pas la capacité de la machine. Par conséquent, nous définissons un Batch_group_bonus qui fournit un bonus plus élevé (d'où l'exponentielle dans l'expression ci-dessous) si les lots sont disposés en groupes plus grands plutôt qu'en groupes plus petits. Il est important de noter que cela peut parfois recouper les objectifs précédents, car certains lots pouvant démarrer aujourd'hui seront démarrés avec d'autres lots qui seront disponibles dans quelques jours, laissant potentiellement certaines ressources non réalisées au début du calendrier utilisé.
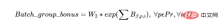
Selon le fonctionnement du solveur, une variable de décision de groupe par lots est souvent requise dans la méthode d'implémentation réelle. Cependant, cela exprime le concept suivant :
Le solveur maximisera l'objectif, qui est :
Objective = Batch_group_bonus + Day_penalty
Laquelle des deux composantes ci-dessus de l'objectif a le plus d'impact sur un jour donné du planning Le maximum dépend des poids W₁, W₂ et des dates du programme, car dans les étapes ultérieures du programme, la valeur de la pénalité journalière deviendra progressivement plus grande (plus la valeur i est élevée). Si la valeur de la pénalité en jours est supérieure à Batch_group_bonus à un moment donné, le solveur de planification trouvera prudent de ne pas planifier le lot ; par conséquent, même s'il y a une capacité de ressources dans le plan, une pénalité nulle sera encourue, ce qui entraînera la planification et l'exécution. une pénalité nette négative, maximisant ainsi le but. Ces problèmes doivent être dépannés et résolus par des data scientists.
Comparaison de la charge de travail relative entre les méthodes ML et les méthodes d'optimisation
Sur la base de la discussion ci-dessus, on peut en déduire que, de manière générale, les projets d'optimisation nécessitent plus d'efforts que les projets ML. L'optimisation nécessite un travail approfondi en science des données à presque chaque étape du processus de développement. Le résumé spécifique est le suivant :
a) Traitement des données d'entrée : En ML et en optimisation, cela est effectué par des data scientists. Le traitement des données ML nécessite la sélection de fonctionnalités pertinentes, la standardisation, la discrétisation, etc. Pour les données non structurées telles que le texte, cela peut inclure des méthodes basées sur le NLP telles que l'extraction de fonctionnalités, la tokenisation, etc. Actuellement, des bibliothèques basées sur plusieurs langages existent pour l'analyse statistique des caractéristiques ainsi que pour les méthodes de réduction de dimensionnalité telles que la PCA.
En matière d'optimisation, chaque entreprise et chaque plan comporte des nuances qui doivent être intégrées au modèle. Les problèmes d'optimisation ne traitent pas de données historiques, mais combinent plutôt tous les changements de données possibles et les caractéristiques identifiées dans un index dont doivent dépendre les variables de décision et les contraintes. Bien que contrairement au ML, le traitement des données nécessite beaucoup de travail de développement.
b) Développement de modèles : Comme mentionné ci-dessus, la formulation de modèles de solutions d'optimisation nécessite beaucoup d'efforts de la part des data scientists et des analystes commerciaux pour formuler des contraintes et des objectifs. Un solveur exécute des algorithmes mathématiques et, bien qu’il soit chargé de résoudre des centaines, voire des milliers d’équations simultanément pour trouver une solution, il n’a aucune expérience commerciale.
En ML, la formation des modèles est hautement automatisée et les algorithmes sont conditionnés sous forme d'API de bibliothèque open source ou par des fournisseurs de services cloud. Des modèles de réseaux neuronaux très complexes et pré-entraînés, basés sur des données spécifiques à l'entreprise, simplifient la tâche de formation jusqu'aux dernières couches. Des outils comme AWS Sagemaker Autopilot ou Azure AutoML peuvent même automatiser l'ensemble du processus de traitement des données d'entrée, de sélection des fonctionnalités, de formation et d'évaluation des différents modèles et de génération de sortie.
c) Tests et traitement de sortie : En ML, la sortie d'un modèle peut être utilisée avec un traitement minimal. Il est généralement facile à comprendre (par exemple, les probabilités des différentes étiquettes), même si certains efforts peuvent être nécessaires pour introduire d'autres aspects, tels que l'interprétabilité des résultats. La visualisation des résultats et des erreurs peut également nécessiter un certain effort, mais ce n'est pas grand-chose comparé au traitement des entrées.
Ici aussi, le problème d'optimisation nécessite des tests manuels itératifs et une validation avec les yeux avertis d'experts en planification pour évaluer les progrès. Même si le solveur tente de maximiser l’objectif, cela n’a souvent pas de sens du point de vue de la qualité du planning. Contrairement au ML, on ne peut pas dire qu’une valeur cible supérieure ou inférieure à un seuil contient un plan correct ou incorrect. Lorsqu'un calendrier s'avère incohérent avec les objectifs de l'entreprise, le problème peut être lié à des contraintes, des variables de décision ou des fonctions objectives, nécessitant une analyse minutieuse pour trouver la cause des anomalies dans des calendriers volumineux et complexes.
De plus, il faut prendre en compte le développement requis pour interpréter la sortie du solveur dans un format lisible par l'homme. Le solveur prend des variables de décision d'entrée, qui sont des valeurs d'index des entités physiques réelles du plan, telles que l'index de groupe de lots, l'index de priorité de lot, l'index d'opérateur et de machine, et renvoie les valeurs sélectionnées. Un traitement inverse est nécessaire pour convertir ces valeurs d'indice de leurs trames de données respectives en une chronologie cohérente qui peut être présentée visuellement et analysée par des experts.
d) Enfin, même en phase opérationnelle, les modèles ML nécessitent beaucoup moins de calculs et de temps pour générer des prédictions observationnelles par rapport à la phase de formation. Cependant, le planning est construit à partir de zéro à chaque fois et nécessite les mêmes ressources pour chaque exécution.
Le chiffre suivant est une illustration approximative de la charge de travail relative de chaque étape des projets de ML et d'optimisation :
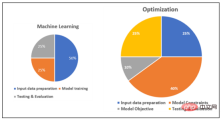
Diagramme schématique comparant la charge de travail relative du ML et de l'optimisation
Le ML et l'optimisation peuvent-ils fonctionner ensemble ?
L'apprentissage automatique et l'optimisation résolvent des problèmes complémentaires pour les entreprises ; par conséquent, les résultats des modèles ML et l'optimisation se renforcent mutuellement et vice versa. Les applications IA/ML telles que la maintenance prédictive et la détection de pannes IoT, la télémaintenance AR/VR et le processus de production RCA susmentionné font partie de la stratégie d’usine connectée du fabricant.
Les applications d'optimisation constituent la base de la planification de la chaîne d'approvisionnement et peuvent être considérées comme liant la stratégie commerciale aux opérations. Ils aident les organisations à réagir et à planifier des événements imprévus. Par exemple, si un problème est détecté dans une ligne de production, les outils RCA (Root Cause Analysis) aideront le responsable de la ligne de production à identifier rapidement les causes possibles et à prendre les mesures nécessaires. Cependant, cela peut parfois conduire à des arrêts inattendus de la machine ou à une réaffectation des instructions d'utilisation. Par conséquent, les plans de production devront peut-être être régénérés en utilisant la capacité réduite disponible.
Certaines techniques de ML peuvent être appliquées à l'optimisation, et vice versa ?
Les expériences des projets ML peuvent être appliquées aux projets d'optimisation vice versa ; Par exemple, pour une fonction objective essentielle à l’optimisation du résultat, il arrive parfois que l’unité commerciale ne soit pas aussi bien définie en termes de modélisation mathématique que les contraintes, qui sont des règles qui doivent être suivies et sont donc généralement bien connues. Par exemple, les objectifs commerciaux sont les suivants :
a) Les lots doivent être classés par ordre prioritaire le plus tôt possible tout en respectant les délais de livraison.
b) Les horaires doivent être préchargés ; ils doivent être planifiés avec un intervalle aussi petit que possible et avec une faible utilisation des ressources.
c) Les lots doivent être regroupés pour utiliser efficacement la capacité.
d) Les opérateurs ayant un niveau de compétence plus élevé pour les produits de grande valeur se voient mieux attribuer de tels lots.
Certains de ces objectifs peuvent avoir des priorités concurrentes qui doivent être correctement équilibrées, ce qui conduit les data scientists, lorsqu'ils rédigent des combinaisons complexes de facteurs d'influence (tels que les bonus et les pénalités), à écrire souvent ce qui semble s'appliquer à la planification la plus courante. scénarios. Cela se fait par essais et erreurs ; mais parfois la logique est difficile à comprendre et à maintenir lorsque des bugs surviennent. Étant donné que les solveurs d’optimisation utilisent souvent des produits tiers, leur code est souvent indisponible pour les data scientists qui créent les modèles qu’ils souhaitent déboguer. Cela rend impossible de voir quelles valeurs ont pris certains bonus et pénalités à un moment donné du processus de génération du calendrier, et ce sont ces valeurs qui font qu'il se comporte correctement, ce qui rend très important l'écriture d'expressions cibles convaincantes.
Ainsi, l'approche ci-dessus permet d'adopter la standardisation des bonus et des pénalités, qui est une pratique de ML largement utilisée. Les valeurs normalisées peuvent ensuite être mises à l'échelle de manière contrôlée à l'aide de paramètres de configuration ou d'autres moyens pour contrôler l'impact de chaque facteur, leurs relations les uns avec les autres et les valeurs des facteurs précédents et suivants au sein de chacun d'eux.
Conclusion
En résumé, l'apprentissage automatique et l'optimisation contrainte sont tous deux des méthodes mathématiques avancées pour résoudre différents problèmes dans les organisations et dans la vie quotidienne. Ils peuvent tous être utilisés pour déployer des jumeaux numériques d’équipements physiques, de processus ou de ressources réseau. Bien que les deux types d'applications suivent des processus de développement de haut niveau similaires, les projets de ML peuvent tirer parti du haut degré d'automatisation disponible dans les bibliothèques et les algorithmes cloud natifs, tandis que l'optimisation nécessite une collaboration étroite entre l'entreprise et les data scientists pour mettre pleinement en œuvre le processus de planification complexe. .de modélisation. De manière générale, les projets d'optimisation nécessitent plus de travail de développement et sont gourmands en ressources. Dans le développement réel, les outils de ML et d’optimisation doivent souvent fonctionner ensemble dans les entreprises, et les deux technologies sont utiles aux data scientists.
Présentation du traducteur
Zhu Xianzhong, rédacteur en chef de la communauté 51CTO, blogueur expert 51CTO, conférencier, professeur d'informatique dans une université de Weifang et vétéran de l'industrie de la programmation indépendante.
Titre original : Modélisation de jumeaux numériques utilisant l'apprentissage automatique et l'optimisation contrainte, auteur : Partha Sarkar
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Les thérapeutes de l'IA sont là: 14 outils révolutionnaires de santé mentale que vous devez savoirApr 30, 2025 am 11:17 AM
Les thérapeutes de l'IA sont là: 14 outils révolutionnaires de santé mentale que vous devez savoirApr 30, 2025 am 11:17 AMBien qu'il ne puisse pas fournir la connexion humaine et l'intuition d'un thérapeute formé, la recherche a montré que de nombreuses personnes sont à l'aise de partager leurs inquiétudes et leurs préoccupations avec des robots d'IA relativement sans visage et anonymes. Que ce soit toujours un bon I
 Appeler l'IA dans l'allée de l'épicerieApr 30, 2025 am 11:16 AM
Appeler l'IA dans l'allée de l'épicerieApr 30, 2025 am 11:16 AML'intelligence artificielle (IA), une technologie des décennies en cours, révolutionne l'industrie de la vente au détail alimentaire. Des gains d'efficacité à grande échelle et des réductions de coûts aux processus rationalisés à travers diverses fonctions commerciales, l'impact de l'IA est indéniable
 Obtenir des pourparlers d'encouragement de l'IA génératrice pour soulever votre espritApr 30, 2025 am 11:15 AM
Obtenir des pourparlers d'encouragement de l'IA génératrice pour soulever votre espritApr 30, 2025 am 11:15 AMParlons-en. Cette analyse d'une percée d'IA innovante fait partie de ma couverture de colonne Forbes en cours sur les dernières personnes en IA, notamment l'identification et l'explication de diverses complexités d'IA percutantes (voir le lien ici). De plus, pour ma comp
 Pourquoi l'hyper-personnalisation alimentée par IA est un must pour toutes les entreprisesApr 30, 2025 am 11:14 AM
Pourquoi l'hyper-personnalisation alimentée par IA est un must pour toutes les entreprisesApr 30, 2025 am 11:14 AMLe maintien d'une image professionnelle nécessite des mises à jour occasionnelles de garde-robe. Bien que les achats en ligne soient pratiques, il n'a pas la certitude des essais en personne. Ma solution? Personnalisation alimentée par AI. J'imagine un assistant d'assistant de conservation des vêtements sélectionnés
 Oubliez Duolingo: la nouvelle fonctionnalité d'IA de Google Translate enseigne les languesApr 30, 2025 am 11:13 AM
Oubliez Duolingo: la nouvelle fonctionnalité d'IA de Google Translate enseigne les languesApr 30, 2025 am 11:13 AMGoogle Translate ajoute une fonction d'apprentissage des langues Selon Android Authority, l'application Expert Assembedebug a constaté que la dernière version de l'application Google Translate contient un nouveau mode de test "Practice" conçu pour aider les utilisateurs à améliorer leurs compétences linguistiques grâce à des activités personnalisées. Cette fonctionnalité est actuellement invisible pour les utilisateurs, mais Assembedebug est en mesure de l'activer partiellement et de visualiser certains de ses nouveaux éléments d'interface utilisateur. Lorsqu'il est activé, la fonction ajoute une nouvelle icône de capuchon de graduation en bas de l'écran marqué d'un badge "bêta" indiquant que la fonction "Practice" sera publiée initialement sous forme expérimentale. L'invite contextuelle connexe montre "Pratiquez les activités adaptées à vous!", Ce qui signifie que Google générera des
 Ils fabriquent TCP / IP pour l'IA, et ça s'appelle NandaApr 30, 2025 am 11:12 AM
Ils fabriquent TCP / IP pour l'IA, et ça s'appelle NandaApr 30, 2025 am 11:12 AMLes chercheurs du MIT développent Nanda, un protocole Web révolutionnaire conçu pour les agents de l'IA. Abréviation des agents en réseau et de l'IA décentralisée, Nanda s'appuie sur le protocole de contexte du modèle d'Anthropic (MCP) en ajoutant des capacités Internet, permettant à l'IA Agen
 L'invite: Deepfake Detection est une entreprise en plein essorApr 30, 2025 am 11:11 AM
L'invite: Deepfake Detection est une entreprise en plein essorApr 30, 2025 am 11:11 AMLa dernière aventure de Meta: une application AI pour rivaliser avec un chatpt rival Meta, la société mère de Facebook, Instagram, WhatsApp et Threads, lance une nouvelle application alimentée par AI. Cette application autonome, Meta AI, vise à rivaliser directement avec le chatppt d'Openai. Levier
 Les deux prochaines années dans la cybersécurité de l'IA pour les chefs d'entrepriseApr 30, 2025 am 11:10 AM
Les deux prochaines années dans la cybersécurité de l'IA pour les chefs d'entrepriseApr 30, 2025 am 11:10 AMNaviguer dans la marée montante des cyberattaques d'IA Récemment, Jason Clinton, CISO pour anthropique, a souligné les risques émergents liés aux identités non humaines - à mesure que la communication de la machine à la machine prolifère, sauvegarde ces "identités"


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Version crackée d'EditPlus en chinois
Petite taille, coloration syntaxique, ne prend pas en charge la fonction d'invite de code

MinGW - GNU minimaliste pour Windows
Ce projet est en cours de migration vers osdn.net/projects/mingw, vous pouvez continuer à nous suivre là-bas. MinGW : un port Windows natif de GNU Compiler Collection (GCC), des bibliothèques d'importation et des fichiers d'en-tête librement distribuables pour la création d'applications Windows natives ; inclut des extensions du runtime MSVC pour prendre en charge la fonctionnalité C99. Tous les logiciels MinGW peuvent fonctionner sur les plates-formes Windows 64 bits.

DVWA
Damn Vulnerable Web App (DVWA) est une application Web PHP/MySQL très vulnérable. Ses principaux objectifs sont d'aider les professionnels de la sécurité à tester leurs compétences et leurs outils dans un environnement juridique, d'aider les développeurs Web à mieux comprendre le processus de sécurisation des applications Web et d'aider les enseignants/étudiants à enseigner/apprendre dans un environnement de classe. Application Web sécurité. L'objectif de DVWA est de mettre en pratique certaines des vulnérabilités Web les plus courantes via une interface simple et directe, avec différents degrés de difficulté. Veuillez noter que ce logiciel

MantisBT
Mantis est un outil Web de suivi des défauts facile à déployer, conçu pour faciliter le suivi des défauts des produits. Cela nécessite PHP, MySQL et un serveur Web. Découvrez nos services de démonstration et d'hébergement.

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

