
Maison >base de données >tutoriel mysql >Exemple d'analyse des principes de création d'index MySQL
Exemple d'analyse des principes de création d'index MySQL

- 王林avant
- 2023-04-17 17:01:031102parcourir
1. Convient à la création d'index
1. Les valeurs des champs ont des restrictions d'unicité
Selon les spécifications d'Alibaba, les champs ayant des caractéristiques uniques dans l'entreprise, même les champs combinés, doivent être intégrés dans un index unique.

Par exemple, le numéro d'étudiant dans la table des étudiants est un champ unique. La création d'un index unique pour ce champ peut rapidement interroger les informations d'un certain étudiant. Si le nom est utilisé, il peut y avoir des situations avec le même. nom, réduisant ainsi la vitesse des requêtes.
2. Champs fréquemment utilisés comme conditions de requête Where
Si un champ est souvent utilisé dans la condition Where de l'instruction Select, il est alors nécessaire de créer un index pour ce champ, en particulier lorsque la quantité de données est importante. , la création d'un index ordinaire suffit. Cela peut grandement améliorer l'efficacité des requêtes.
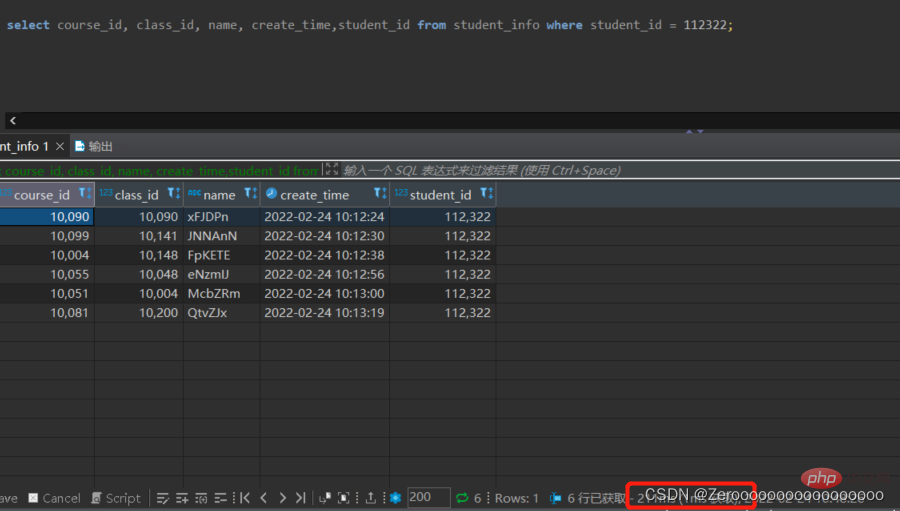
Par exemple, la table de test student_info contient 1 million de données. Supposons que les informations utilisateur de student_id=112322 soient interrogées. Si aucun index n'est créé sur le champ student_id, les résultats de la requête sont les suivants :
select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费211ms
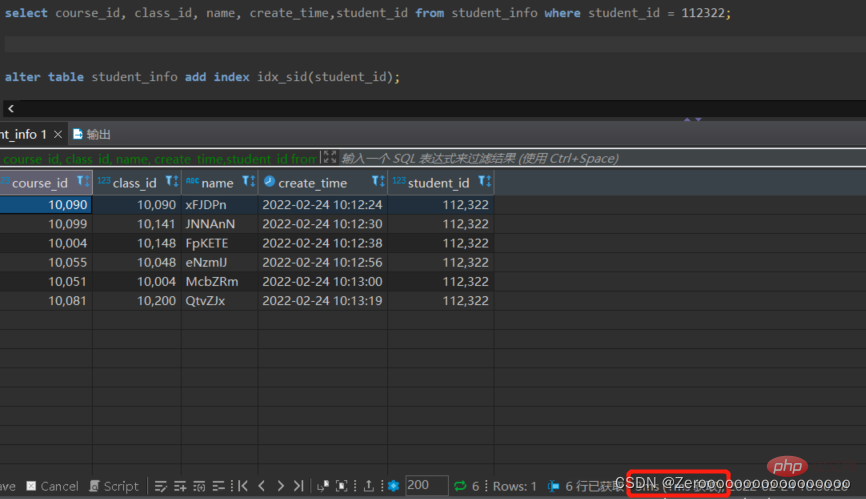
After. en créant un index pour student_id, les résultats de la requête sont les suivants :
alter table student_info add index idx_sid(student_id); select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费3ms
3 Souvent, les colonnes Group by et Order by
Indices permettent de stocker ou de récupérer les données dans un certain ordre, donc lors de l'utilisation de Group by. pour regrouper les données ou utiliser Trier par pour trier les données, vous devez indexer les champs de regroupement ou de tri. S'il y a plusieurs colonnes à trier, un index combiné peut être construit sur ces colonnes.
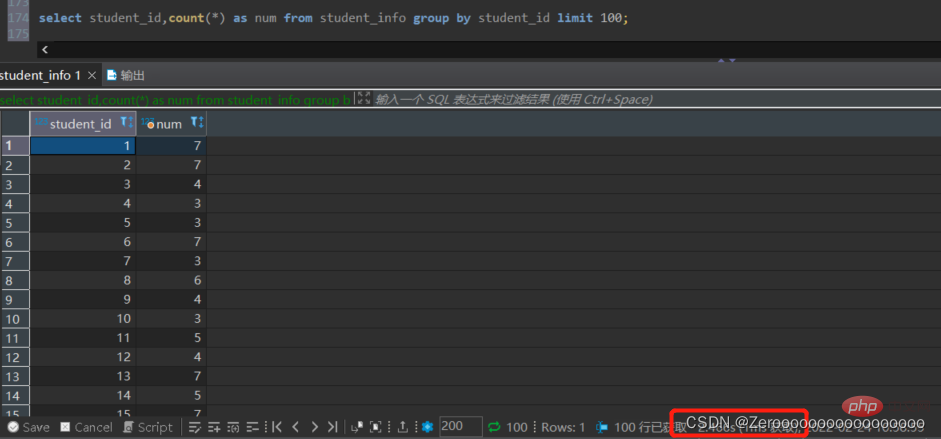
Par exemple, regroupez les cours sélectionnés par les étudiants selon student_id, affichez différents student_id et le nombre de cours, et affichez 100 éléments. Si vous ne créez pas d'index pour student_id, les résultats de la requête sont les suivants :
select student_id,count(*) as num from student_info group by student_id limit 100;#花费2.466s
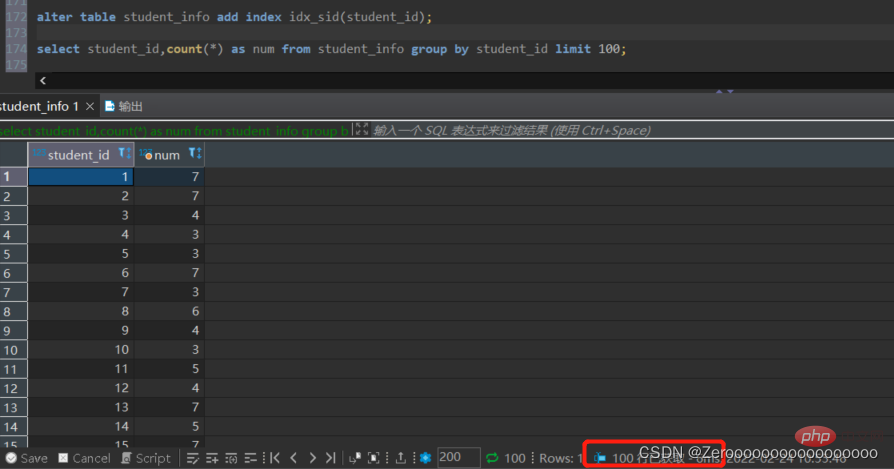
Après avoir créé un index pour student_id, les résultats de la requête sont les suivants :
alter table student_info add index idx_sid(student_id); select student_id,count(*) as num from student_info group by student_id limit 100;#花费6ms
Pour les instructions de requête qui ont à la fois group by et order by, il est recommandé de créer un index conjoint et de placer les champs group by devant le champ order by pour répondre au "principe de correspondance des préfixes les plus à gauche", de sorte que le taux d'utilisation de l'index soit élevé et que le l'efficacité naturelle des requêtes sera élevée ; en même temps, après la version 8.0, la version prend en charge l'index décroissant. Si les champs après order by sont classés par ordre décroissant, vous pouvez envisager de créer directement un index décroissant, ce qui améliorera également l'efficacité des requêtes.
4. La colonne de condition Where de Mettre à jour et Supprimer
Interrogez les données en fonction d'une certaine condition, puis effectuez l'opération Mettre à jour ou Supprimer. Si un index est créé pour le champ Où, la réponse peut être améliorée pour améliorer l'efficacité. . La raison en est que cet enregistrement doit d'abord être récupéré en fonction de la colonne de condition Where, puis mis à jour ou supprimé. Si le champ mis à jour est un champ non-index lors de la mise à jour, l'amélioration de l'efficacité sera plus évidente car aucune maintenance n'est requise pour les mises à jour des champs d'index.
Par exemple, si le champ nom dans la table student_info est sdfasdfas123123, le student_id est modifié en 110119. Sans indexer le champ nom, la situation d'exécution est la suivante :
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费549ms
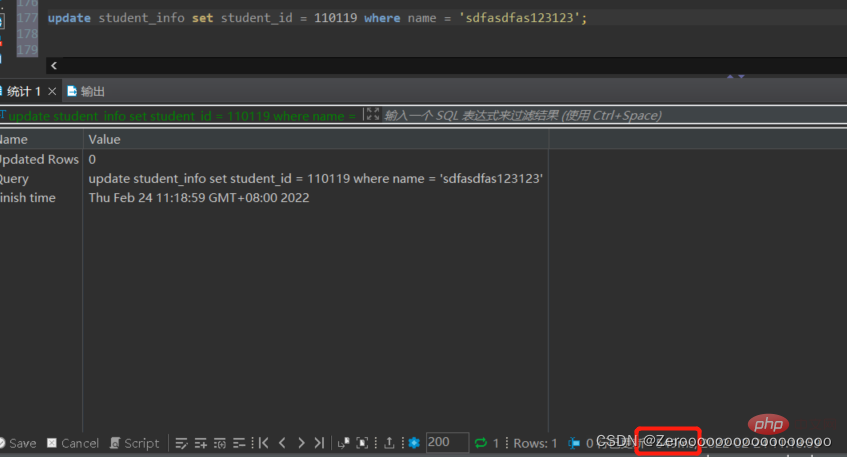
Après avoir ajouté l'index, la situation d'exécution est la suivante :
alter table student_info add index idx_name(name); update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费2ms
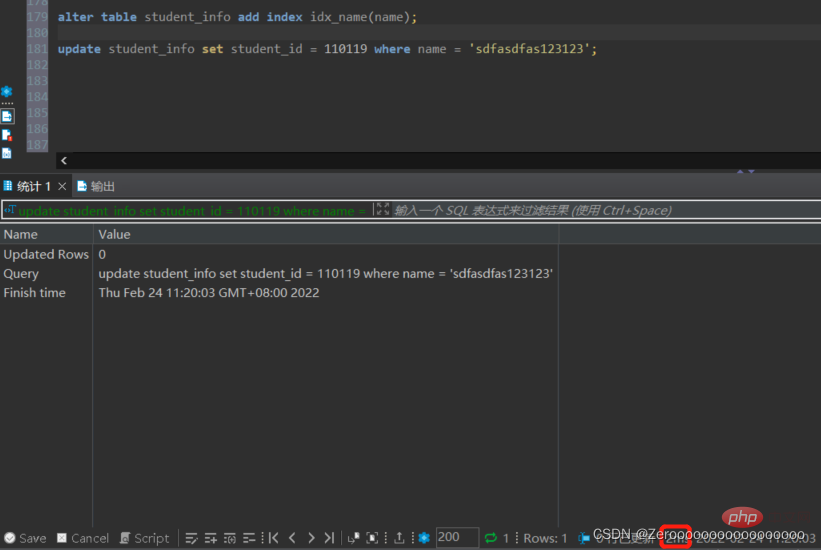
5. Les champs distincts doivent créer des index
Parfois, il est nécessaire de dédupliquer un certain champ en utilisant Distinct, la création d'un index pour ce champ améliorera également l'efficacité des requêtes.
Par exemple, interrogez les différents student_ids dans le planning des cours. Si aucun index n'est créé pour student_id, la situation d'exécution est la suivante :
select distinct(student_id) from student_id;#花费2ms
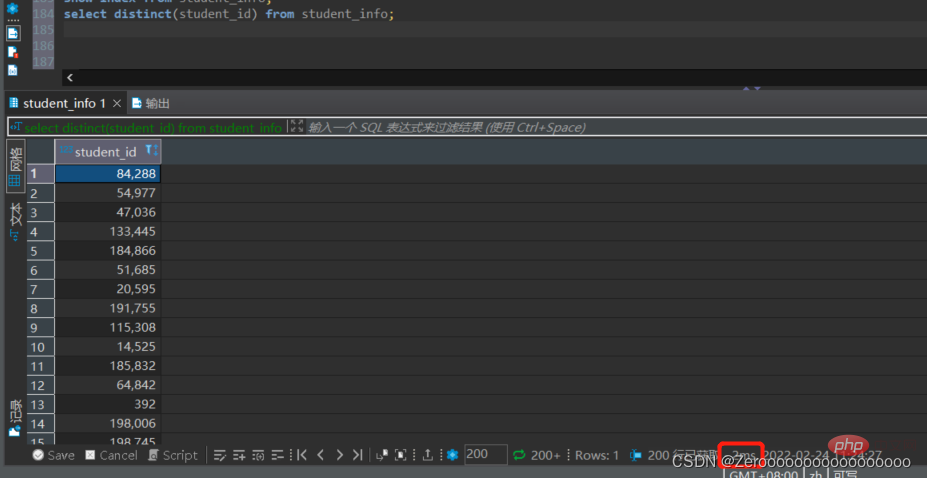
Après la création de l'index, la situation d'exécution est la suivante :
alter table student_info add index idx_sid(student_id); select distinct(student_id) from student_id;#花费0.1ms
6. Lors de l'opération de connexion multi-tables, points à noter lors de la création d'un index
Tout d'abord, la quantité de données dans la table de connexion ne doit pas dépasser 3, car chaque table supplémentaire équivaut à l'ajout d'une boucle imbriquée, et la l'ordre de grandeur augmente très rapidement, affectant sérieusement l'efficacité des requêtes. Deuxièmement, créez un index pour la condition Where, car Where est le filtre pour les conditions de données. Si la quantité de données est très importante, ce sera très effrayant s'il n'y a pas de condition Where pour le filtrage. Enfin, créez un index pour les connectés. champs et modifiez à nouveau les champs. Les types dans plusieurs tables doivent être cohérents.

Par exemple, si vous créez un index uniquement pour student_id, les résultats de la requête sont les suivants :
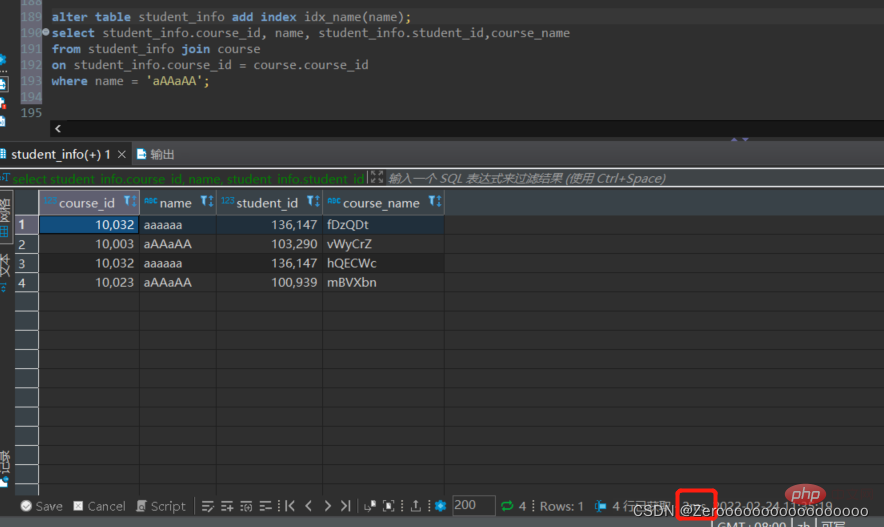
select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费176ms
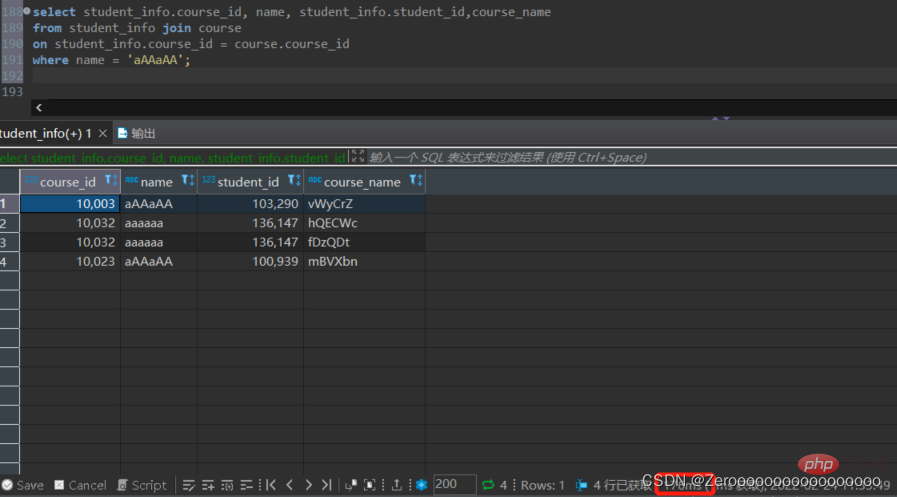
Après avoir créé un index pour le champ nom, les résultats de la requête sont les suivants :
alter table student_info add index idx_name(name); select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费2ms
7、使用列的类型小的创建索引
这里所说的类型小值意思是该类型表示的数据范围的大小。比如在定义表结构的时候要显示的指定列的类型,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,他们占用的存储空间依次递增,能表示的数据范围也是一次递增。如果相对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,例如能使用INT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
数据类型越小,在查询时进行的比较操作越快
数据类型越小,索引占用的空间就越少,在一个数据页内就可以存下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以存储更多的数据在数据页中,提高读写效率。
上述对于主键来说很合适,因为在聚簇索引中既存储了数据,也存储了索引,可以很好的减少磁盘I/O;而对于二级索引来说,还需要一次回表操作才能查到完整的数据,也就能加了一次磁盘I/O。
8、使用字符串前缀创建索引
根据Alibaba开发手册,在字符串上建立索引时,必须指定索引长度,没有必要对全字段建立索引。

比如有一张商品表,表中的商品描述字段较长,在描述字段上建立前缀索引如下:
create table product(id int, desc varchar(120) not null); alter table product add index(desc(12));
区分度的计算可以使用count(distinct left(列名, 索引长度))/count(*)来确定。
9、区分度高的列适合作为索引
列的基数值得时某一列中不重复数据的个数,比如说某个列包含值2,5,3,6,2,7,2,虽然有7条记录,但该列的基数却是5,也就是说,在记录行数一定的情况下,列的基数越大,该列中的值就越分散;列的基数越小,该列中的值就越集中。这里列的基数指标非常重要,直接影响是否能有效利用索引。最好为列的基数大的列建立索引,为基数太小的列建立索引效果反而不好。
可以使用公式select count(distinct col)/count(*) from table 来计算区分度,越接近1区分度越好。
10、使用最频繁的列放到联合索引的左侧
这条就是通常说的最左前缀匹配原则。 通俗来讲就是将Where条件后经常使用的条件字段放在索引的最左边,将使用频率相对低的放到右边。
11、在多个字段都要创建索引的情况下,联合索引由于单值索引
二、不适合创建索引
1、在where中使用不到的字段不要设置索引
通常索引的建立是有代价的,如果建立索引的字段没有出现在where条件(包括group by、order by)中,建议一开始就不要创建索引或将索引删除,因为索引的存在也会占用空间。
2、数据量小的表最好不要使用索引
3、有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如学生表中的性别字段,只有男和女两种值,因此无需建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
4、避免对经常更新的表创建过多的索引
频繁更新的字段不一定要创建索引,因为更新数据的时候,索引也要跟着更新,如果索引太多,更新的时候会造成服务器压力,从而影响效率。
避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时虽然提高了查询速度,同时也会降低更新表的速度。
5、不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
6、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
7、不要定义冗余或重复的索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
8、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
9. Ne définissez pas d'index redondants ou en double
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!