
Maison >Périphériques technologiques >IA >Pourquoi ChatGPT et Bing Chat sont si doués pour créer des histoires
Pourquoi ChatGPT et Bing Chat sont si doués pour créer des histoires

- PHPzavant
- 2023-04-17 08:37:021381parcourir

Pourquoi les chatbots IA inventent-ils des bêtises, et pouvons-nous pleinement faire confiance à leurs résultats ? Pour le savoir, nous avons interrogé plusieurs experts et examiné en profondeur le fonctionnement de ces modèles d'IA.
« Illusion » - un terme biaisé en intelligence artificielle
Les chatbots IA tels que ChatGPT d'OpenAI s'appuient sur un type d'intelligence artificielle appelé « grand modèle de langage » (LLM) pour générer leurs réponses. LLM est un programme informatique formé sur des millions de sources de texte pour lire et générer un langage textuel en « langage naturel », tout comme les humains écrivent ou parlent naturellement. Malheureusement, ils font aussi des erreurs.
Dans la littérature universitaire, les chercheurs en IA appellent souvent ces erreurs des « hallucinations ». À mesure que le sujet est devenu courant, l'étiquette est devenue de plus en plus controversée, car certains pensent qu'elle anthropomorphise les modèles d'IA (suggérant qu'ils ont des caractéristiques humaines), ou les attribue à des modèles d'IA alors qu'elle ne devrait pas impliquer qu'ils ont du pouvoir (ce qui implique). qu'ils puissent faire leurs propres choix). En outre, les créateurs de LLM commerciaux peuvent également utiliser l’illusion comme excuse pour blâmer le modèle d’IA pour des résultats erronés plutôt que d’assumer la responsabilité des résultats eux-mêmes.
Pourtant, l’IA générative est un domaine très nouveau, et nous devons emprunter des métaphores aux idées existantes pour expliquer ces concepts hautement techniques au grand public. Dans ce cas, nous pensons que le mot « confabulation », bien qu’également imparfait, est une meilleure métaphore que la métaphore « hallucination ». En psychologie humaine, la « fiction » fait référence à une lacune dans la mémoire d'une personne, et le cerveau remplit l'expérience oubliée avec un fait fictif convaincant sans tromper intentionnellement les autres. ChatGPT ne fonctionne pas comme le cerveau humain, mais le terme « fiction » est sans doute une meilleure métaphore car il fonctionne sur le principe de combler les lacunes de manière créative (plutôt que de tromper délibérément), ce que nous explorerons ci-dessous.
Le problème fictif
C'est un gros problème lorsque les robots IA produisent de fausses informations qui peuvent avoir des effets trompeurs ou diffamatoires. Récemment, le Washington Post a rapporté qu'un professeur de droit avait découvert que ChatGPT l'avait inclus sur une liste de juristes qui harcelaient sexuellement autrui. Mais cette affaire est fausse et complètement fabriquée par ChatGPT. Le même jour, Ars a également signalé qu’un maire australien avait découvert que l’affirmation de ChatGPT selon laquelle il avait été reconnu coupable de corruption et emprisonné était également complètement fabriquée.
Peu de temps après le lancement de ChatGPT, les gens ont commencé à préconiser la fin des moteurs de recherche. Cependant, dans le même temps, de nombreux cas fictifs de ChatGPT ont commencé à circuler largement sur les réseaux sociaux. Les robots IA ont inventé des livres et des études inexistants, des publications que les professeurs n'ont pas écrites, de faux articles universitaires, de fausses citations juridiques, des fonctionnalités du système Linux inexistantes, des mascottes irréelles et des détails techniques dénués de sens.
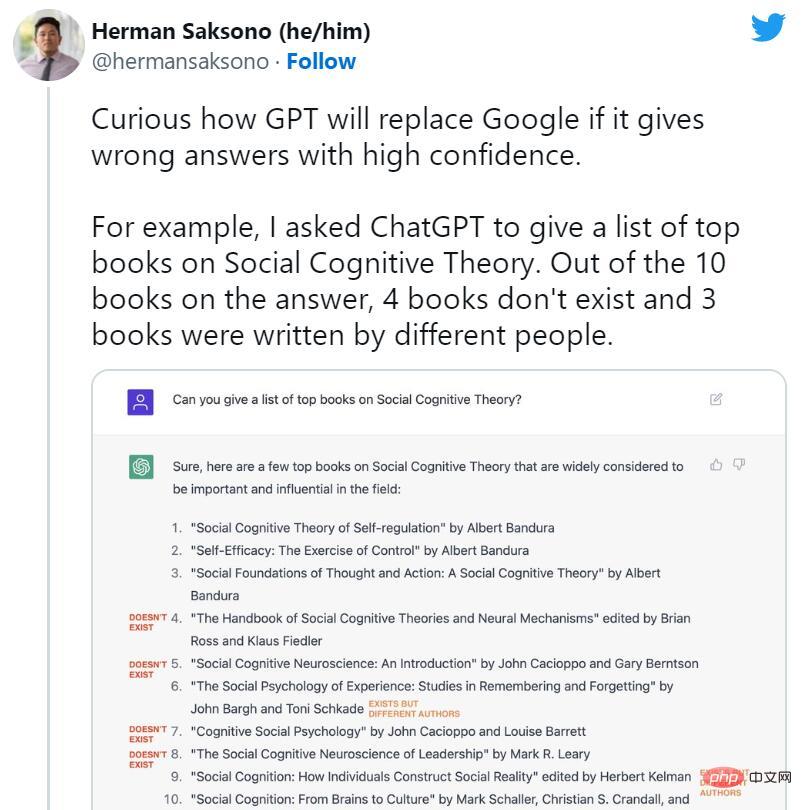
Cependant, malgré la propension de ChatGPT aux mensonges occasionnels, sa suppression de la fiction est exactement la raison pour laquelle nous en parlons aujourd'hui. Certains experts soulignent que ChatGPT est techniquement une amélioration par rapport au GPT-3 classique (son modèle prédécesseur) dans la mesure où il peut refuser de répondre à certaines questions ou vous faire savoir lorsque ses réponses peuvent être inexactes.
Riley Goodside, expert en modèles de langage et ingénieur d'invite chez Scale AI, a déclaré : « Un facteur majeur du succès de ChatGPT est qu'il réussit à supprimer la fiction et à rendre discrets de nombreux problèmes courants. Contrairement à ses prédécesseurs, ChatGPT est nettement moins performant. enclin à inventer des choses. »
S'ils sont utilisés comme outil de brainstorming, les sauts logiques et les fictions de ChatGPT peuvent conduire à des percées créatives. Mais lorsqu’il est utilisé comme référence factuelle, ChatGPT peut faire de réels dégâts, et OpenAI le sait.
Peu de temps après la sortie du modèle, Sam Altman, PDG d'OpenAI, a tweeté : « ChatGPT a des fonctionnalités très limitées, mais suffisamment bon à certains égards pour créer une impression trompeuse de grandeur. Maintenant, s'appuyer sur lui pour quelque chose d'important serait une erreur. C'est un avant-goût du progrès ; nous avons encore beaucoup de travail à faire en termes de robustesse et d'authenticité. » Dans un tweet ultérieur, il a écrit : « Il en sait beaucoup, mais le danger est qu'il soit aveuglément confiant et se trompe. la plupart du temps. «
Que se passe-t-il ici ?
Comment fonctionne ChatGPT
Pour comprendre quelque chose comme ChatGPT ou Bing comment un modèle GPT comme Chat est « romancé », nous devons savoir comment fonctionne le modèle GPT. Bien qu'OpenAI n'ait pas encore publié de détails techniques pour ChatGPT, Bing Chat ou même GPT-4, nous nous attendons à voir des articles de recherche introduisant GPT-3 (leur prédécesseur) en 2020.
Les chercheurs construisent (entraînent) de grands modèles de langage comme GPT-3 et GPT-4 en utilisant un processus appelé « apprentissage non supervisé », ce qui signifie que les données qu'ils utilisent pour entraîner le modèle ne sont pas spécialement annotées ou étiquetées. Dans ce processus, le modèle est alimenté par une grande quantité de texte (des millions de livres, de sites Web, d’articles, de poèmes, de manuscrits et d’autres sources) et tente à plusieurs reprises de prédire le mot suivant dans chaque séquence de mots. Si la prédiction du modèle est proche du mot suivant, le réseau neuronal met à jour ses paramètres pour renforcer le modèle qui a conduit à cette prédiction.
À l'inverse, si la prédiction est incorrecte, le modèle ajuste les paramètres pour améliorer les performances et réessaye. Ce processus d'essais et d'erreurs, bien qu'il s'agisse d'une technique appelée rétropropagation, permet au modèle d'apprendre de ses erreurs et d'améliorer progressivement ses prédictions au cours de l'entraînement.
Par conséquent, GPT apprend l'association statistique entre les mots et les concepts associés dans l'ensemble de données. Certains, comme Ilya Sutskever, scientifique en chef d'OpenAI, pensent que le modèle GPT va plus loin et construit un modèle interne de réalité afin de pouvoir prédire avec plus de précision le prochain meilleur jeton, mais cette idée est controversée. Les détails exacts de la manière dont le modèle GPT propose le prochain jeton dans son réseau neuronal restent incertains.

Dans la vague actuelle de modèles GPT, cette formation de base (maintenant souvent appelée « pré-formation ») n'a lieu qu'une seule fois. Après cela, on peut utiliser le réseau neuronal formé en « mode inférence », ce qui permet à l'utilisateur d'alimenter le réseau formé et d'obtenir les résultats. Lors de l'inférence, la séquence d'entrée du modèle GPT est toujours fournie par un humain, appelée « invite ». L'invite détermine la sortie du modèle, et la modifier, même légèrement, peut modifier radicalement les résultats produits par le modèle.
Par exemple, si vous demandez à GPT-3 « Mary avait un… », la phrase sera généralement complétée par « petit agneau ». En effet, il existe probablement des dizaines de milliers d'exemples de « Mary avait un petit agneau » dans l'ensemble de données de formation de GPT-3, ce qui en fait un résultat raisonnable. Mais si vous ajoutez plus de contexte à l'invite, comme « À l'hôpital, Mary a eu un », les résultats changeront et renverront quelque chose comme « bébé » ou « série de tests ».
C'est ce qui est intéressant avec ChatGPT, car il est configuré comme une conversation avec un agent, pas seulement comme un travail de génération directe de texte. Dans le cas de ChatGPT, l'invite de saisie correspond à l'intégralité de la conversation que vous avez avec ChatGPT, en commençant par votre première question ou déclaration, y compris les instructions spécifiques fournies à ChatGPT avant le début de la conversation simulée. Au cours de ce processus, ChatGPT conserve une mémoire à court terme (appelée « fenêtre contextuelle ») pour tout ce que vous et lui avez écrit, et pendant qu'il vous « parle », il essaie de terminer la tâche de génération de texte de la conversation.
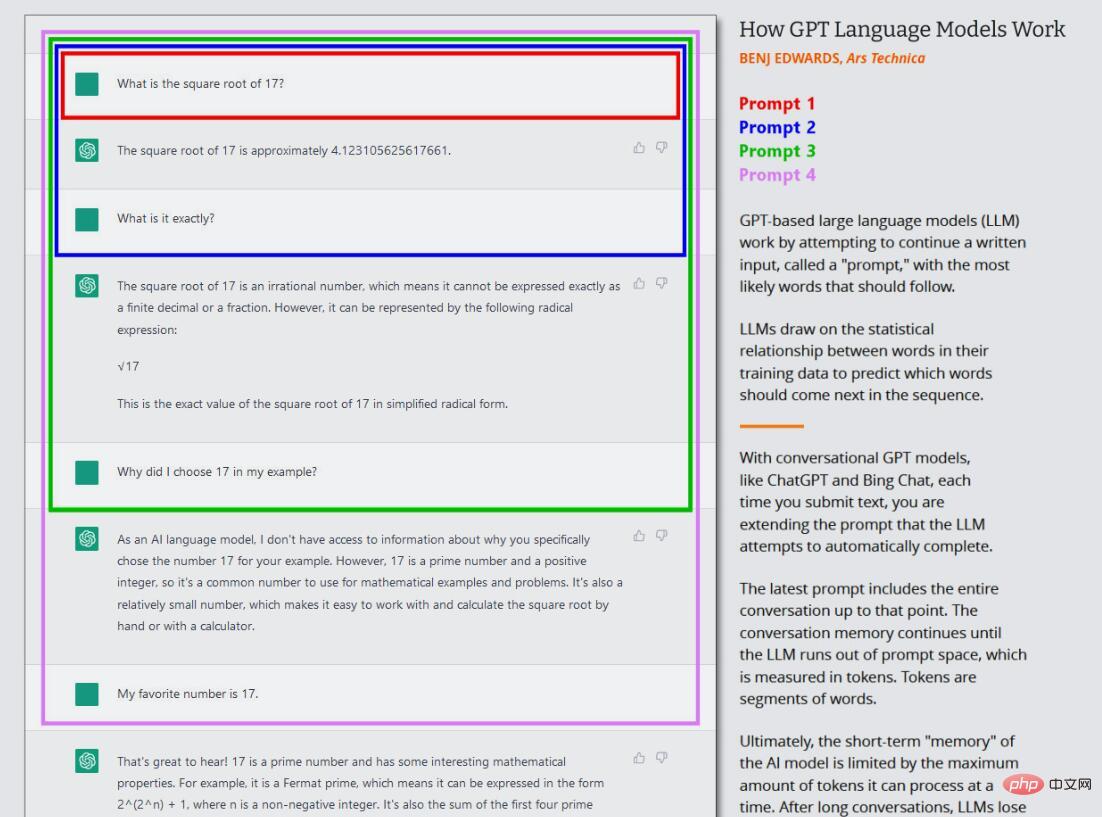
De plus, ChatGPT est différent du GPT-3 ordinaire en ce sens qu'il est également formé sur du texte conversationnel écrit par des humains. OpenAI écrit sur sa page de version initiale de ChatGPT : « Nous avons formé un modèle initial à l'aide d'un réglage fin supervisé : les formateurs d'IA humaine fournissent des conversations dans lesquelles ils agissent en tant que deux parties : l'utilisateur et l'assistant d'IA. Nous fournissons aux formateurs des suggestions d'écriture de modèle. aidez-les à composer leurs propres réponses. Grâce au RLHF, OpenAI est en mesure d'inculquer au modèle l'objectif « d'éviter de répondre à des questions auxquelles on ne peut pas répondre avec précision ». Cela permet à ChatGPT de produire des réponses cohérentes avec moins de fiction que le modèle de base. Mais des informations inexactes peuvent quand même passer.
Pourquoi ChatGPT produit de la fiction
Essentiellement, il n'y a rien dans l'ensemble de données d'origine du modèle GPT pour séparer les faits de la fiction.
Le comportement des LLM reste un domaine de recherche actif. Même les chercheurs qui ont créé ces modèles GPT découvrent encore des propriétés surprenantes de la technologie que personne n’avait prédit lors de leur développement initial. La capacité de GPT à réaliser bon nombre des choses intéressantes que nous voyons aujourd'hui, telles que la traduction linguistique, la programmation et le jeu d'échecs, a autrefois surpris les chercheurs.
Alors quand on demande pourquoi ChatGPT génère des artefacts, il est difficile de trouver une réponse technique exacte. Étant donné que les pondérations des réseaux neuronaux comportent un élément de « boîte noire », il est difficile (voire impossible) de prédire leur sortie précise lorsqu'une invite complexe est reçue. Néanmoins, nous connaissons quelques raisons fondamentales pour lesquelles la fiction se produit.
La clé pour comprendre les capacités fictives de ChatGPT est de comprendre son rôle en tant que machine de prédiction. Lorsque ChatGPT rattrape, il recherche des informations ou des analyses qui n'existent pas dans l'ensemble de données et comble les lacunes avec des mots plausibles. ChatGPT est particulièrement doué pour inventer des choses en raison du grand volume de données qu'il doit traiter et de sa capacité à si bien rassembler le contexte des mots, ce qui l'aide à placer les messages d'erreur de manière transparente dans le texte environnant.
Simon Willison, développeur de logiciels, a déclaré : « Je pense que la meilleure façon de penser à la fiction est de réfléchir à la nature des grands modèles de langage : la seule chose qu'ils savent faire est de choisir le prochain meilleur mot en fonction d'une formation. ensemble, basé sur une probabilité statistique. Le premier provient de sources inexactes dans son ensemble de données de formation, telles que des idées fausses courantes (par exemple, « manger de la dinde vous rendra somnolent »). La seconde découle du fait de faire des déductions sur des situations spécifiques qui n'existent pas dans son ensemble de données de formation ; cela relève de l'étiquette « hallucination » mentionnée plus haut.
Le fait qu'un modèle GPT fasse une supposition sauvage dépend de ce que les chercheurs en IA appellent un attribut de « température », qui est souvent décrit comme un paramètre de « créativité ». Si la créativité est élevée, le modèle fera des suppositions folles ; si elle est faible, il crachera des données de manière déterministe en fonction de son ensemble de données.
Récemment, Mikhail Parakhin, employé de Microsoft, s'est rendu sur Twitter pour parler de la tendance de Bing Chat à avoir des hallucinations et des causes des hallucinations. Il a écrit : « C'est ce que j'ai essayé d'expliquer auparavant : illusion = créativité. Il essaie de produire la continuation de la chaîne avec la probabilité la plus élevée en utilisant toutes les données qu'il traite. C'est généralement correct. Parfois, les gens n'ont jamais fait une telle continuation. »
Parakhin a ajouté que ces sauts créatifs fous sont ce qui rend le LLM amusant. Vous pouvez supprimer les hallucinations, mais vous trouverez cela super ennuyeux. Parce qu'il répond toujours "Je ne sais pas", ou ne renvoie que ce qui se trouve dans les résultats de recherche (ce qui est aussi parfois incorrect). Ce qui manque désormais, c'est le ton : il ne faut pas donner l'impression d'être aussi confiant dans ces situations. «
Lorsqu'il s'agit d'affiner un modèle de langage comme ChatGPT, équilibrer créativité et précision est un défi. D'une part, la capacité à proposer des réponses créatives fait de ChatGPT un outil puissant pour générer de nouvelles idées ou éliminer les goulots d'étranglement des auteurs. D'un autre côté, lorsqu'il s'agit de produire des informations fiables et d'éviter la fiction, trouver le bon équilibre entre les deux est crucial pour le développement d'un modèle de langage, mais crucial pour développer un outil à la fois utile et efficace. digne de confiance.
Il y a aussi le problème de la compression. GPT-3 prend en compte des pétaoctets d'informations pendant la formation, mais le réseau neuronal qui en résulte n'est qu'une fraction de la taille. Dans un article largement lu du New Yorker, l'auteur Ted Chiang l'a qualifié de ". réseau flou JPEG", ce qui signifie que la plupart des données d'entraînement réelles sont perdues. GPT-3 compense cela en apprenant les relations entre les concepts, qu'il peut ensuite utiliser pour reformuler de nouveaux arrangements de ces faits. Tout comme une personne avec une mémoire défectueuse travaillant par intuition, il se trompe parfois. S'il ne connaît pas la réponse, il donne sa meilleure estimation.
Nous ne pouvons pas oublier le rôle des invites dans la fiction : d'une certaine manière, ChatGPT vous donne ce que vous lui donnez. Vous le nourrissez de mensonges, et il aura tendance à être d'accord avec vous et à « penser » dans ce sens. C'est pourquoi il est important de recommencer avec une nouvelle invite lorsque vous changez de sujet ou que vous rencontrez une réponse indésirable. que ce qu'il produit peut changer entre les sessions, même avec la même invite.
Tout cela conduit à ce que OpenAI soit d'accord avec cette conclusion : ChatGPT, tel qu'il est actuellement conçu, n'est pas une source fiable d'informations factuelles et on ne peut pas lui faire confiance. Mitchell, chercheur et scientifique en chef de l'éthique à la société d'IA Hugging Face, estime que "ChatGPT peut être très utile pour certaines choses, comme lorsqu'il s'agit de fermer votre bloc d'écriture ou de trouver des idées créatives. Il n’a pas été construit pour la vérité et ne peut donc pas être la vérité. C'est aussi simple que cela. "
Le mensonge peut-il être corrigé ?
Faire aveuglément confiance aux chatbots IA est une erreur, mais cela pourrait changer à mesure que la technologie sous-jacente s'améliore. ChatGPT a été mis à niveau à plusieurs reprises depuis sa sortie en novembre de l'année dernière. Certaines de ces mises à niveau incluent une précision accrue, et la possibilité de refuser de répondre à des questions dont il ne connaît pas la réponse.
Alors, comment OpenAI prévoit-il de rendre ChatGPT plus précis ? Nous avons contacté OpenAI à plusieurs reprises au cours des derniers mois à propos de ce problème ? n'a obtenu aucune réponse, mais nous pouvons trouver des indices dans les documents publiés par OpenAI et dans les reportages sur l'entreprise essayant de guider ChatGPT pour qu'il s'aligne sur les employés humains.
Comme mentionné précédemment, l'une des raisons pour lesquelles ChatGPT connaît un tel succès est sa formation approfondie utilisant RLHF. OpenAI explique : « Pour rendre nos modèles plus sûrs, plus utiles et plus cohérents, nous utilisons une technologie existante appelée « Apprentissage par renforcement avec retour humain (RLHF). » Selon les conseils soumis par les clients à l'API, notre tagger fournit une démonstration de Le comportement souhaité du modèle et trie plusieurs sorties du modèle. Nous utilisons ensuite ces données pour affiner GPT-3 », explique Sutskever d'OpenAI avec une formation supplémentaire via RLHF. Peut résoudre le problème des hallucinations. Sutskever a déclaré à Forbes dans une interview plus tôt ce mois-ci : "J'espère vraiment qu'en améliorant simplement ce suivi RLHF, cela lui apprendra à ne pas halluciner

D'autres ne sont pas d'accord. Yann LeCun, scientifique en chef de l'intelligence artificielle chez Meta, estime que le LLM actuel utilisant l'architecture GPT ne peut pas résoudre le problème des hallucinations. Mais il existe une méthode émergente qui pourrait apporter une plus grande précision au LLM dans le cadre de l’architecture actuelle. Il explique : « L'une des approches les plus activement étudiées pour ajouter du réalisme dans LLM est l'augmentation de la récupération, en fournissant au modèle des documents externes comme sources et un contexte de support. Avec cette technique, les chercheurs espèrent apprendre au modèle à utiliser des documents externes comme la recherche de Google. les moteurs, comme les chercheurs humains, citent des sources fiables dans leurs réponses et s'appuient moins sur des connaissances factuelles peu fiables acquises lors de la formation du modèle »
Bing Chat et Google Bard y parviennent déjà avec la recherche sur le Web. Bientôt, une version compatible navigateur de ChatGPT sera également disponible. être mis en œuvre. De plus, le plugin ChatGPT est conçu pour compléter les données de formation de GPT-4 en récupérant des informations à partir de sources externes telles que le Web et des bases de données spécialement conçues. Cette amélioration est analogue à la façon dont les personnes possédant une encyclopédie décriront les faits avec plus de précision que les personnes sans encyclopédie.
De plus, il est possible de former un modèle comme GPT-4 pour comprendre quand il invente des choses et s'ajuster en conséquence. Mitchell estime qu '"il y a des choses plus profondes que les gens pourraient faire pour rendre ChatGPT et des choses similaires plus réalistes dès le départ, y compris une gestion des données plus sophistiquée et l'utilisation d'une approche de type PageRank pour aligner les données de formation sur la "confiance". Les scores sont liés. ... et le modèle peut également être affiné pour couvrir le risque lorsqu'il est moins sûr des réponses. "
Ainsi, même si ChatGPT est actuellement en difficulté avec ses problèmes fictifs, il peut y avoir une issue, comme le font De plus en plus de personnes commencent à compter sur ces outils comme assistants de base, et je pense que des améliorations en termes de fiabilité devraient bientôt arriver.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI