
Maison >Périphériques technologiques >IA >Utilisez l'IA pour aider des centaines de millions de personnes aveugles à « revoir le monde » !
Utilisez l'IA pour aider des centaines de millions de personnes aveugles à « revoir le monde » !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-16 18:37:031788parcourir
Dans le passé, redonner la vue aux aveugles était souvent considéré comme un « miracle » médical.
Avec la percée explosive de la technologie intelligente multimodale représentée par la « vision industrielle + compréhension du langage naturel », l'IA a apporté de nouvelles possibilités pour aider les aveugles. De plus en plus de personnes aveugles profiteront de la perception et de la compréhension fournies par l'IA. et des capacités d'interaction, pour « voir le monde » à nouveau autrement.
L'IA aide les aveugles, permettant à davantage de personnes de « voir le monde » à nouveau
De manière générale, le canal permettant aux patients malvoyants qui ne peuvent pas voir de reconnaître le monde extérieur passe par d'autres sens que la vision, tels que L'ouïe, l'odorat et le toucher, ces autres modalités d'information aident les malvoyants à atténuer dans une certaine mesure les problèmes causés par les défauts de vision. Cependant, des recherches scientifiques montrent que parmi les informations externes obtenues par l'homme, la vision représente entre 70 et 80 %.
Par conséquent, construire un système de vision industrielle basé sur l'IA pour aider les patients malvoyants à avoir une perception visuelle et une compréhension visuelle de l'environnement externe est sans aucun doute la solution la plus directe et la plus efficace.
Dans le domaine de la perception visuelle, les modèles d'IA monomodaux actuels ont dépassé les niveaux humains dans les tâches de reconnaissance d'images. Cependant, ce type de technologie ne peut actuellement permettre la reconnaissance et la compréhension que dans le cadre de la modalité visuelle et est difficile à mettre en œuvre. d’autres informations sensorielles. L’apprentissage, la compréhension et le raisonnement intermodaux, en termes simples, signifient que nous pouvons seulement percevoir mais pas comprendre.
À cette fin, David Marr, l'un des fondateurs de la vision computationnelle, a soulevé la question centrale de la recherche sur la compréhension visuelle dans le livre "Vision", estimant que le système visuel doit construire une expression bidimensionnelle ou tridimensionnelle. de l'environnement et être capable d'interagir avec lui Interaction. L’interaction signifie ici apprendre, comprendre et raisonner.
On peut voir qu'une excellente technologie d'IA pour l'assistance à la cécité est en fait un projet systématique qui comprend une détection intelligente, un raisonnement intelligent des intentions de l'utilisateur et une présentation intelligente des informations. Ce n'est qu'ainsi qu'une interface interactive sans barrière d'information peut être construite.
Afin d'améliorer la capacité de généralisation des modèles d'IA et de permettre aux machines de disposer de capacités d'analyse et de compréhension d'images multimodales, des algorithmes multimodaux représentés par « vision industrielle + compréhension du langage naturel » ont commencé à émerger et à se développer rapidement.
Ce modèle d'algorithme d'interactions modales d'informations multiples peut améliorer considérablement les capacités de perception, de compréhension et d'interaction de l'IA. Une fois mature et appliqué dans le domaine de l'assistance à la cécité par l'IA, il pourra bénéficier à des centaines de millions de personnes aveugles et à nouveau. "Voir le monde".
Selon les statistiques de l'OMS, au moins 2,2 milliards de personnes dans le monde sont malvoyantes ou aveugles, et mon pays est le pays qui compte le plus de personnes aveugles au monde, représentant 18 à 20 % du nombre total de personnes aveugles. aveugles dans le monde. Le nombre de nouveaux aveugles chaque année s'élève à 45 dix mille.
L'effet domino provoqué par la tâche visuelle de questions et réponses pour les aveugles
La technologie de perception en perspective à la première personne est d'une grande importance pour l'IA aidant les aveugles. Il n'est pas nécessaire que les aveugles participent au fonctionnement des appareils intelligents. Au lieu de cela, cela peut partir du point de vue réel de la personne aveugle et aider les scientifiques à construire des modèles d'algorithmes plus conformes à la cognition des aveugles. tâche de recherche fondamentale de réponses visuelles aux questions pour les personnes aveugles.
La tâche visuelle de questions et réponses pour les personnes aveugles est le point de départ et l'un des principaux axes de recherche de la recherche universitaire sur l'assistance de l'IA pour la cécité. Cependant, dans les conditions techniques actuelles, la tâche visuelle de questions et réponses pour les aveugles, en tant que type particulier de tâche visuelle de questions et réponses, est confrontée à de plus grandes difficultés pour améliorer la précision par rapport aux tâches visuelles ordinaires de questions et réponses.
D'une part, les types de questions dans les questions-réponses visuelles pour les aveugles sont plus complexes, y compris la détection de cibles, la reconnaissance de texte, la couleur, la reconnaissance d'attributs et d'autres types de questions, comme l'identification de la viande dans le réfrigérateur, la consultation du instructions pour prendre des médicaments et choisir des couleurs de chemises uniques, introduction au contenu du livre, etc.
D'autre part, en raison de la particularité de la personne aveugle en tant que sujet d'interaction perceptuelle, il est difficile pour la personne aveugle de saisir la distance entre le téléphone portable et l'objet lors de la prise de photos, ce qui entraîne souvent des situations de flou, ou bien que l'objet soit photographié, il ne l'est pas dans son intégralité, ou les informations clés ne sont pas prises, ce qui augmente considérablement la difficulté d'une extraction efficace des caractéristiques.
Dans le même temps, la plupart des modèles visuels de questions et réponses existants sont basés sur un entraînement aux données de questions et réponses dans un environnement fermé. Ils sont sévèrement limités par la distribution des échantillons et sont difficiles à généraliser aux scénarios de questions et réponses dans le contexte. monde ouvert. Ils doivent intégrer des connaissances externes pour un raisonnement en plusieurs étapes.

Données de questions et réponses visuelles aveugles
Deuxièmement, avec le développement de la recherche sur les questions et réponses visuelles aveugles, les scientifiques ont découvert au cours du processus de recherche que les questions et réponses visuelles rencontreront des problèmes dérivés causés par les interférences sonores. . Par conséquent, la manière de localiser avec précision le bruit et de mener à bien un raisonnement intelligent est également confrontée à des défis majeurs.
Étant donné que les personnes aveugles n'ont pas de perception visuelle du monde extérieur, elles commettent souvent un grand nombre d'erreurs dans les tâches visuelles de questions et réponses de correspondance image-texte. Par exemple, lorsqu'une personne aveugle fait ses courses dans un supermarché, il est facile pour elle de poser les mauvaises questions en raison de l'apparence et de la sensation similaires des produits, comme prendre une bouteille de vinaigre et demander qui est le fabricant du produit. la sauce soja l'est. Ce type de bruit linguistique entraîne souvent l’échec des modèles d’IA existants, ce qui nécessite que l’IA ait la capacité d’analyser le bruit et les informations disponibles dans des environnements complexes.
Enfin, les systèmes d'assistance aux aveugles par l'IA devraient non seulement répondre aux doutes actuels des personnes aveugles, mais également avoir la capacité de raisonner sur des intentions intelligentes et de présenter des informations intelligentes. La technologie d'interaction intelligente est une direction de recherche importante, et la recherche sur les algorithmes l'est toujours. à ses balbutiements.
L'objectif de recherche de la technologie de raisonnement intentionnel intelligent est de déduire que les utilisateurs malvoyants souhaitent exprimer leurs intentions d'interaction en permettant à la machine d'apprendre en permanence le langage et les habitudes comportementales des utilisateurs malvoyants. Par exemple, grâce à l'action d'une personne aveugle tenant un gobelet d'eau et s'asseyant, la prochaine action consistant à placer le gobelet d'eau sur la table peut être prédite par la personne aveugle posant des questions sur la couleur ou le style des vêtements. prédit qu'une personne pourrait voyager, etc.
La difficulté de cette technologie est que puisque l'expression et les actions d'expression de l'utilisateur sont aléatoires dans le temps et dans l'espace, le modèle psychologique de la prise de décision interactive est également aléatoire, alors comment passer du continu Il est très critique d'en extraire une efficacité informations saisies par les utilisateurs à partir de données comportementales aléatoires et concevoir un modèle multimodal dynamique non déterministe pour obtenir la meilleure présentation des différentes tâches.
L'accent est mis sur la recherche fondamentale sur l'IA pour l'aide à la cécité, et de nombreuses études d'Inspur Information ont été reconnues internationalement.
Il ne fait aucun doute que des avancées majeures dans les domaines de recherche fondamentale ci-dessus sont la clé de la mise en œuvre rapide de l'aide à la cécité par l'IA. technologie. Actuellement, l’équipe de recherche de pointe d’Inspur Information s’efforce de promouvoir le développement ultérieur de la recherche sur l’aide à la cécité par l’IA grâce à de multiples innovations algorithmiques, des modèles de pré-formation et la construction d’ensembles de données de base.
Dans le domaine de la recherche sur les tâches de questions et réponses visuelles aveugles, VizWiz-VQA est un défi mondial multimodal de questions et réponses visuelles aveugles lancé conjointement par des chercheurs de l'Université Carnegie Mellon et d'autres institutions, en utilisant l'aveugle "VizWiz". ensemble de données visuelles pour la formation Le modèle d'IA donne ensuite des réponses aux paires image-texte aléatoires fournies par la personne aveugle. Dans la tâche de questions et réponses visuelles pour les aveugles, l'équipe de recherche Inspur Information Frontier a résolu de nombreux problèmes courants dans la tâche de questions et réponses visuelles pour les aveugles.
Tout d'abord, étant donné que les photos prises par les aveugles sont floues et contiennent des informations moins efficaces, les questions sont généralement plus subjectives et vagues, il est donc difficile de comprendre les demandes des aveugles et de donner des réponses.
L'équipe a proposé un modèle d'alignement de points d'ancrage multimodal à double flux, qui utilise des entités et des attributs clés de la détection visuelle de cibles comme points d'ancrage pour relier des images et des questions afin d'obtenir une amélioration sémantique multimodale.
Deuxièmement, compte tenu du problème selon lequel il est difficile pour les personnes aveugles de garantir la bonne direction lorsqu'elles prennent des photos, grâce à la correction automatique des angles d'image et à l'amélioration sémantique des caractères, combinée à la technologie de détection et de reconnaissance optique des caractères, le le problème de comprendre « quoi » est résolu.
Enfin, les photos prises par les aveugles sont généralement floues et incomplètes, ce qui rend difficile pour les algorithmes généraux de juger du type et du but de l'objet cible. Le modèle doit avoir une capacité de bon sens plus suffisante pour déduire. la véritable intention de l'utilisateur.
À cette fin, l'équipe a proposé un algorithme qui combine un positionnement visuel basé sur les réponses avec une correspondance d'images et de textes de grand modèle, et a proposé une stratégie de formation croisée en plusieurs étapes. Pendant le raisonnement, les modèles de positionnement visuel et de correspondance image-texte à entraînement croisé sont utilisés pour déduire et localiser la zone de réponse en même temps, les caractères régionaux sont déterminés sur la base de l'algorithme de reconnaissance optique de caractères et le texte de sortie est envoyé à ; l'encodeur de texte, et enfin le texte du modèle de correspondance image-texte est Le décodeur a obtenu la réponse que l'aveugle a demandé de l'aide, et la précision finale de l'algorithme multimodal était de 9,5 points de pourcentage en avance sur les performances humaines.
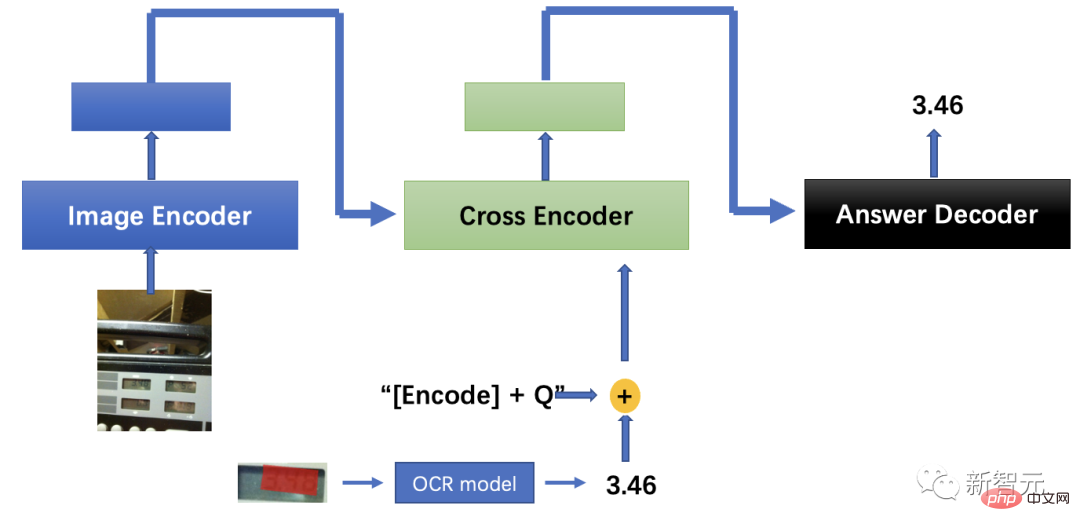
Solution de modèle de réponse visuelle multimodale aux questions
L'un des plus grands obstacles à l'application actuelle de la recherche sur le positionnement visuel est le traitement intelligent du bruit Dans les scènes réelles, les descriptions textuelles sont souvent bruyantes, comme les lapsus humains, ambiguïtés, rhétorique, etc. Des expériences ont montré que le bruit du texte peut entraîner l’échec des modèles d’IA existants.
À cette fin, l'équipe de recherche Inspur Information Frontier a exploré le problème d'inadéquation multimodale causé par les erreurs de langage humain dans le monde réel et a proposé pour la première fois la tâche de raisonnement de débruitage de texte de positionnement visuel FREC, exigeant que le modèle localiser le texte correspondant à la description du bruit et argumenter davantage sur la preuve que le texte est bruyant.
FREC fournit 30 000 images et plus de 250 000 annotations de texte, couvrant une variété de bruits tels que les lapsus, l'ambiguïté, les écarts subjectifs, etc. Il fournit également des étiquettes interprétables telles que la correction du bruit et les preuves bruyantes.
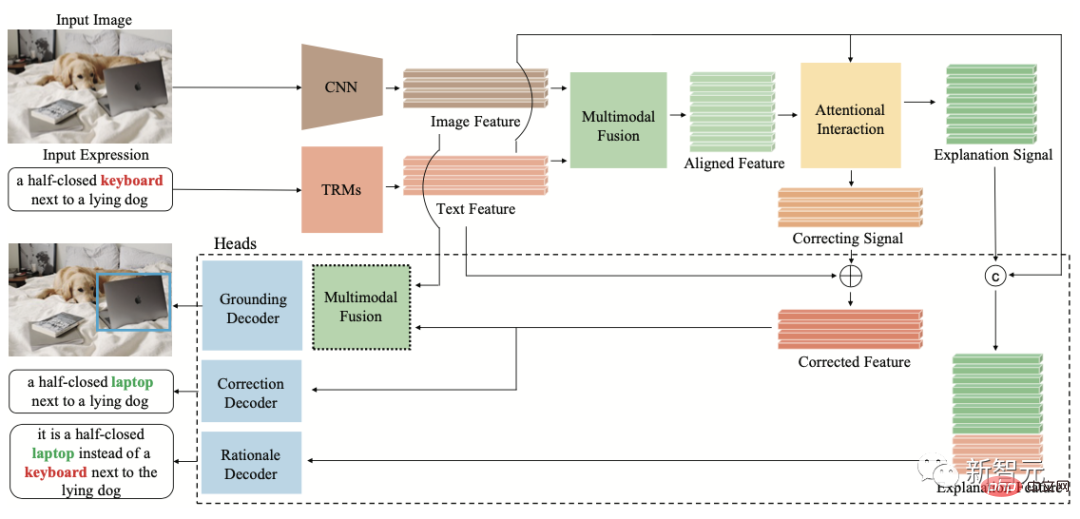
Diagramme de structure du FCTR
Dans le même temps, l'équipe a également construit le premier modèle de positionnement visuel de débruitage interprétable FCTR Dans des conditions de description textuelle bruyante, la précision est de 11 points de pourcentage supérieure à celle du FCTR. le modèle traditionnel.
Ce résultat de recherche a été publié lors de la conférence ACM Multimedia 2022, qui est la plus grande conférence dans le domaine multimédia international et la seule conférence internationale de classe A recommandée par le CCF dans ce domaine.

Adresse papier : https://www.php.cn/link/9f03268e82461f179f372e61621f42d9
Afin d'explorer la capacité de l'IA à interagir avec des pensées basées sur des images et du texte, Inspur Information Front ier Équipe de recherche Il propose une nouvelle direction de recherche pour l'industrie, en proposant une tâche de questions et réponses interactive visuelle d'agent explicable AI-VQA, qui peut élargir le contenu existant des images et des textes en établissant des chaînes logiques pour rechercher dans une vaste base de connaissances.
Actuellement, l'équipe a construit un ensemble de données open source pour AI-VQA, qui contient plus de 144 000 bases de connaissances sur les événements à grande échelle, 19 000 questions de raisonnement cognitif comportemental interactif entièrement annotées manuellement, ainsi que des objets clés, des faits à l'appui. et chemins de raisonnement, etc. Annotation interprétable.
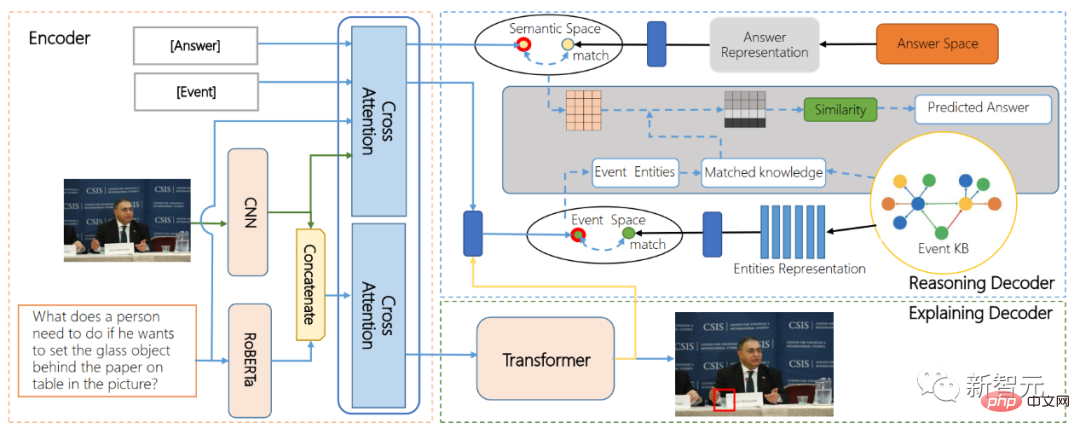
Schéma de structure ARE
Parallèlement, l'ARE (modèle encodeur-décodeur pour raison et explication alternatives) proposé par l'équipe, premier modèle d'algorithme pour comprendre le comportement interactif des agents, réalise pour la première fois un positionnement de comportement interactif de bout en bout. Et le comportement interactif affecte le raisonnement. Basé sur une technologie de fusion multimodale d'images et de textes et un algorithme de récupération de graphiques de connaissances, un modèle visuel de questions et réponses avec des capacités de raisonnement à longue chaîne causale est mis en œuvre. .
La grandeur de la technologie n'est pas seulement de changer le monde, mais plus important encore, de profiter à l'humanité et de rendre possibles davantage de choses impossibles.
Pour les aveugles, être capable de vivre de manière indépendante comme les autres grâce à la technologie de l'IA pour aider à la cécité, plutôt que d'être traité de manière spéciale, reflète la plus grande bonne volonté de la technologie.
Maintenant que l'IA brille dans la réalité, la technologie n'est plus aussi froide qu'une montagne, mais pleine de la chaleur des soins humanistes.
À l'avant-garde de la technologie de l'IA, Inspur Information espère que la recherche sur la technologie de l'intelligence artificielle pourra attirer davantage de personnes pour continuer à promouvoir la mise en œuvre de la technologie de l'intelligence artificielle et permettre à la vague de l'IA multimodale d'aider les aveugles à s'étendre à Anti-fraude par l'IA, diagnostic et traitement de l'IA, alerte précoce en cas de catastrophe par l'IA et d'autres scénarios supplémentaires pour créer plus de valeur pour notre société.
Lien de référence : https://www.php.cn/link/9f03268e82461f179f372e61621f42d9
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI