
Maison >développement back-end >Tutoriel Python >Pratique du trading quantitatif Python : obtenir des données boursières et les analyser
Pratique du trading quantitatif Python : obtenir des données boursières et les analyser

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-15 21:13:012434parcourir
Le trading quantitatif (également appelé trading automatisé) est une méthode d'investissement qui applique des modèles mathématiques pour aider les investisseurs à porter des jugements et à effectuer des transactions sur la base d'instructions envoyées par des programmes informatiques. Il réduit considérablement l'impact des fluctuations émotionnelles des investisseurs. Les principaux avantages du trading quantitatif sont les suivants :
- Détection rapide
- Objectif et rationnel
- Automation
Le cœur du trading quantitatif est le filtrage. Des stratégies sont également créées sur la base de modèles mathématiques ou physiques, transformant le langage mathématique en un langage mathématique. langage informatique. Le processus de trading quantitatif va de l’acquisition des données à l’analyse et au traitement des données.
Acquisition de données
La première étape de l'analyse des données consiste à obtenir des données, c'est-à-dire une collecte de données. Il existe de nombreuses façons d'obtenir des données. De manière générale, les sources de données sont principalement divisées en deux catégories : les sources externes (achats externes, exploration du Web, données open source gratuites, etc.) et les sources internes (données de ventes de l'entreprise, données financières, etc.). .).
Parce que nous ne produisons pas de données, nous ne pouvons obtenir des données que de l’extérieur. La méthode d'accès est la bibliothèque open source tierce tushare.
Utilisez tushare pour obtenir des données boursières historiques
tushare est un package d'interface de données financières Python gratuit et open source. Il met principalement en œuvre le processus de collecte, de nettoyage, de traitement et de stockage de données financières telles que les actions, et peut fournir aux analystes financiers des données rapides, propres et diversifiées, faciles à analyser, afin de réduire leur charge de travail d'acquisition de données.
Installez la bibliothèque tushare, entrez la commande suivante sous Jupiter Notebook :
%pip install tushare
Redémarrez le noyau, puis entrez la commande suivante.
import tushare
print("tushare版本号{}".format(tushare.__version__))tushare版本号1.2.85
Obtenez des données historiques sur les transactions d'actions individuelles (y compris les données de moyenne mobile). Les utilisateurs peuvent obtenir une ligne K quotidienne, une ligne K hebdomadaire, une ligne K mensuelle, ainsi que des données sur 5 minutes, 15 minutes, 30 minutes et Données K-line de 60 minutes via les paramètres. Cette interface ne peut obtenir que des données quotidiennes des trois dernières années et convient à la sélection et à l'analyse de titres en conjonction avec les données de moyenne mobile. Le code Python est le suivant :
importtushareasts
ts.get_hist_data('000001') #一次性获取全部日k线数据
'''
参数说明:
code:股票代码,即6位数字代码,或者指数代码(sh=上证指数 sz=深圳成指 hs300=沪深300指数 sz50=上证50 zxb=中小板 cyb=创业板)
start:开始日期,格式YYYY-MM-DD
end:结束日期,格式YYYY-MM-DD
ktype:数据类型,D=日k线 W=周 M=月 5=5分钟 15=15分钟 30=30分钟 60=60分钟,默认为D
retry_count:当网络异常后重试次数,默认为3
pause:重试时停顿秒数,默认为0
例如:
ts.get_hist_data('000001', ktype='W') #获取周k线数据
ts.get_hist_data('000001', ktype='M') #获取月k线数据
ts.get_hist_data('000001', ktype='5') #获取5分钟k线数据
ts.get_hist_data('000001', ktype='15') #获取15分钟k线数据
ts.get_hist_data('000001', ktype='30') #获取30分钟k线数据
ts.get_hist_data('000001', ktype='60') #获取60分钟k线数据
ts.get_hist_data('sh')#获取上证指数k线数据
ts.get_hist_data('sz')#获取深圳成指k线数据
ts.get_hist_data('hs300')#获取沪深300指数k线数据
ts.get_hist_data('000001',start='2021-01-01',end='2021-03-20') #获取”000001”从2021-01-01到2021-03-20的k线数据
'''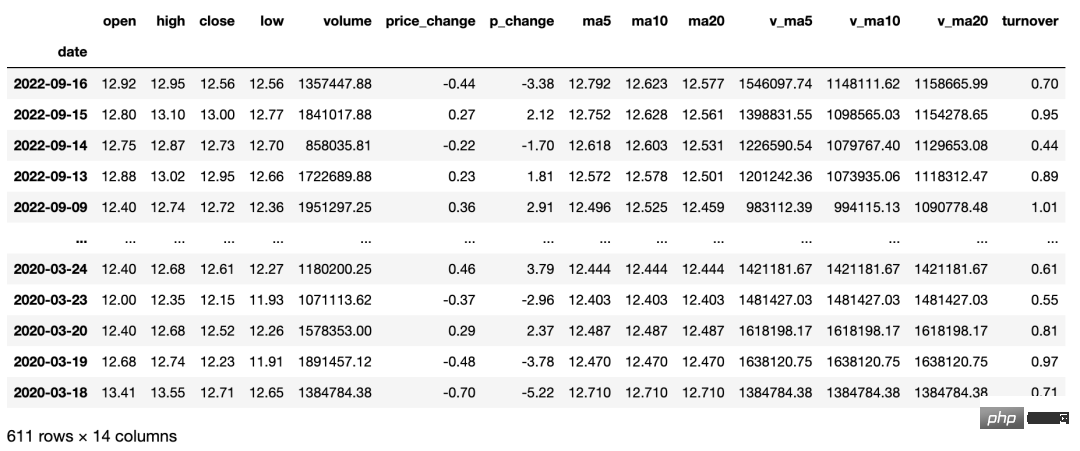
La valeur de retour est expliquée comme suit.
- date : date ;
- ouverture : prix d'ouverture ;
- haut : prix le plus élevé ;
- changement de prix : changement de prix ;
- pchange : augmentation ou diminution ;
- mas : prix moyen sur 5 jours ;
- ma10 : prix moyen sur 10 jours
- v_ma10 : moyenne sur 10 jours Volume moyen ;
- v_ma20 : volume moyen sur 20 jours ;
- turnover : taux de rotation (attention : l'indice ne comporte pas cet élément).
- Utilisez tushare pour obtenir des données en temps réel sur toutes les actions
- Les données de transactions historiques d'actions individuelles sont des données différées. Face à l'évolution des données de prix en temps réel, nous pouvons utiliser les conditions de marché en temps réel les plus pratiques du moment pour saisir rapidement les conditions du marché grâce à la quantification Python et sélectionner les actions exceptionnelles qui répondent aux conditions actuelles.
- Ce qui suit utilise get_today_all() dans la bibliothèque tierce tushare pour obtenir les données en temps réel de toutes les actions (si c'est un jour férié, c'est le jour de bourse précédent). Le code est le suivant :
importtushareasts ts.get_today_all()
L'acquisition de données est le fondement de la recherche de données. Une API rapide, précise et stable réduira considérablement le temps nécessaire aux individus pour obtenir des données, permettant aux chercheurs de consacrer plus d'énergie au traitement et à la modélisation des données. La bibliothèque tushare est également l'un des principaux moyens permettant à l'auteur d'obtenir des données. Elle fournit une source de données stable et puissante pour le travail quantitatif, de sorte que la collecte de données puisse être réalisée simplement avec une seule ligne de code.
Prétraitement des donnéesQu'il s'agisse d'une stratégie quantitative ou d'un simple projet d'apprentissage automatique, le prétraitement des données est une partie très importante. Du point de vue de l'apprentissage quantitatif, le prétraitement des données comprend principalement le nettoyage, le tri, le traitement des valeurs manquantes ou des valeurs aberrantes, l'analyse statistique, l'analyse de corrélation et l'analyse en composantes principales (ACP), etc. Étant donné que les livres précédents collectaient des données de stock régulières, le prétraitement des données à introduire dans ce chapitre consiste à éliminer à l'avance les données de stock qui ne remplissent pas les conditions, puis à optimiser et filtrer les stocks restants. Ce chapitre utilise principalement la bibliothèque Pandas et les lecteurs doivent se concentrer sur la compréhension des idées de filtrage.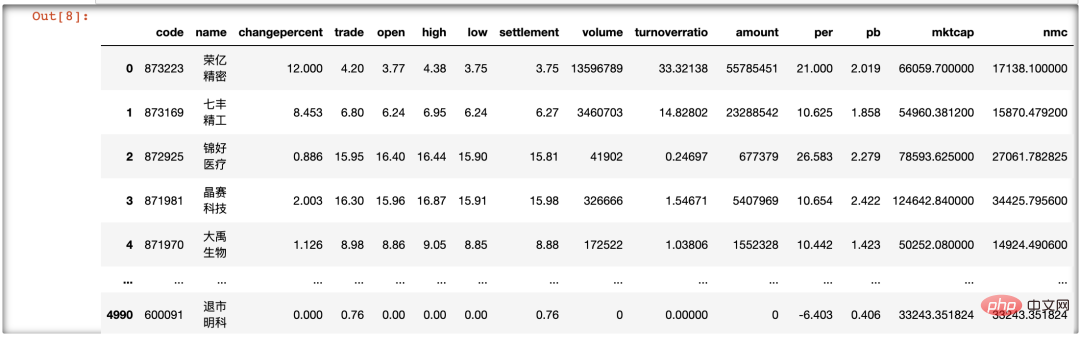
Les actions ST indiquent généralement que les actions de sociétés cotées présentant des conditions financières anormales ou d'autres conditions nécessitent un traitement spécial (traitement spécial) pour leurs transactions. En raison du « traitement spécial », ST est préfixé à l'abréviation, ces stocks sont donc appelés stocks ST.
Mettre ST avant le nom d'une action est un avertissement pour le marché. L'action comporte des risques d'investissement et sert d'avertissement. Cependant, ce type d'action présente des risques et des rendements élevés. Si *ST est ajouté, cela signifie que. l'action présente des risques d'investissement.Nous devons être vigilants quant au risque de radiation.Plus précisément, vers avril 2021, si la société soumet des états financiers à la Commission chinoise de réglementation des valeurs mobilières avec des pertes pour des années consécutives, il y aura un risque de radiation. Les règles de négociation des actions sont également limitées à 5 % de hausse et 5 % de baisse le jour de la cotation.
Nous voulons éviter ce type de "stocks de mines terrestres" (stocks ST), nous pouvons donc utiliser le code suivant pour nettoyer les stocks ST.
import tushareasts
csv_data=ts.get_today_all()
csv_data[~csv_data.name.str.contains('ST')]我们对 csv_data 的 name 列进行操作,筛选出包含 ST 字母的行,并对整个 DataFrame 取反,进而筛选出不含 ST 股票的行。经过观察,我们发现在运行结果中没有 ST 股票,实现了数据的初步清洗。
清洗掉没成交量的股票
首先要明确定义,什么是没有成交量的股票。没有成交量不是成交量为零,而是一支股票单位时间的成交量不活跃。成交量是反映股市上人气聚散的一面镜子。人气旺盛、 买卖踊跃,成交量自然放大:相反人气低迷、买卖不活跃,成交量必定萎缩。成交量是观察庄家大户动态的有效途径。
下面开始清洗没成交量的股票,在原来的基础上增加代码如下:
import tushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data[csv_data["volume"]>15000000]#15万手在以上代码中,我们对 csv_data 的 volume 列进行操作。15 万手是过滤掉不活跃、没成交量的股票,主要以小盘股居多。
其运行结果为:

Index 出现了调行现象,即为去掉成交量小手 15 万手的股票。
清洗掉成交额过小的股票
成交额是成交价格与成交数量的乘积,它是指当天已成交股票的金额总数。成交最的至少取决于市场的投资热情。我们每天看大盘,一个重要的指标就是大 A 股成交量是否超过一万亿元,超过即为成交活跃。
筛选成交额超过 1 亿元的股票,代码如下:
import tushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data[(csv_data["amount"]>1)]筛选股票的数量没有锐减,这是因为成交额-成交价格×成交量。有些股票价格低,成交量巨大,乘积刚刚超过 1亿元;有些股票价格高,成交量相对小一些,乘积仍然超过1亿元。同成交额,2元股票相对于 20 元与 200 元股票,其成交量相差10 倍到 100 倍之多。同成交量,有些股票成交额为 100 亿元,相对于成交额仅有 1亿元的股票,也有百倍之多。
用户可以对 1亿元这个参数进行调参,不过笔者不是特别支持。因为将成交额变大即是对大盘股产生偏重,而前面成交量的筛选也己经对大盘股的成交量进行了偏重筛选,这样双重筛选下来,就会全部变成大盘股,数据偏置严重,没有合理性。预处理的思想也是先将数据进行简单的筛选。笔者认为后期的策略相对于这里的调参更为重要,策略是日后交易的核心。
清洗掉换手率低的股票
换手率=某一段时期内的成交量/流通总股数×100% 。一般情况下,大多数股票每日换手率在1%~2.5%之间(不包括初上市的股票)。70%股票的换手率基本在 3%以下,3%就成为一种分界。
当一支股票的换手率在 3%~7%之间时,该股进入相对活跃状态。当换手率在 7%~10%之间时,则为强势股的出现,股价处于高度活跃中。
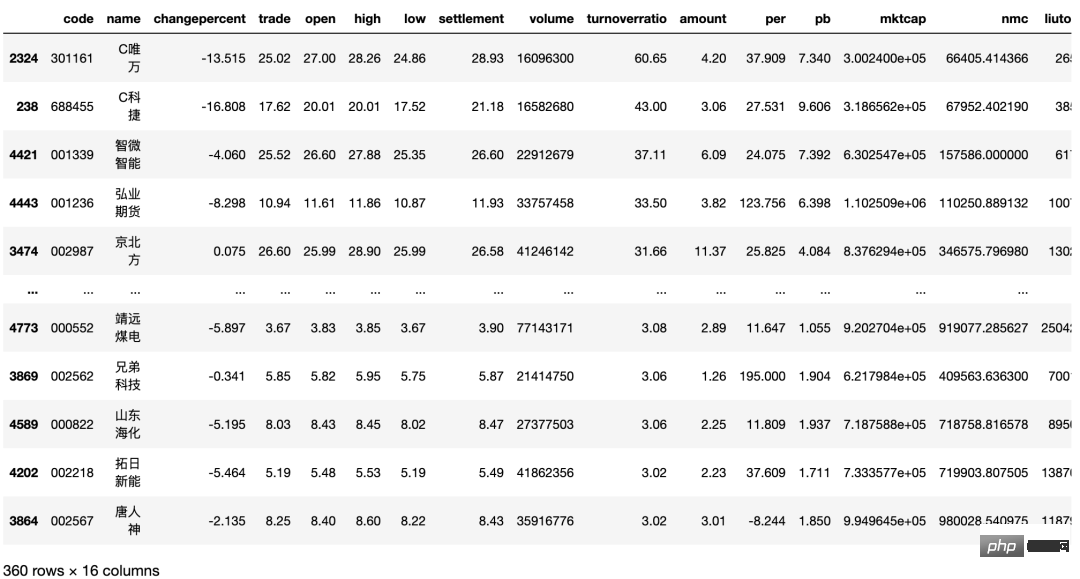
筛选换手率超过3的股票,代码如下:
importtushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data=csv_data[(csv_data["amount"]>1)]
csv_data["liutongliang"]=csv_data["nmc"]/csv_data["trade"]#增加流通盘的列
csv_data["turnoverratio"]=round(csv_data["turnoverratio"],2)#换手率保留2位
csv_data[csv_data["turnoverratio"]>3]筛选股票的数量减半。换手率低于 3%当然也有不错的股票,但是根据正态分布,我们不选取小概率事件。选择换手率较好的股票,意味着该文股票的交投越活跃,人们购买该支股票的意愿越高,该股票属于热门股。
换手率商一般意味股票流通性好,进出市场比较容易,不会出现想买买不到、想卖卖不出的现象,具有我较强的变现能力。然而值得注意的是,换手率较高的股票,往往也是短线资金追逐的对象,投机性较强,股价起伏较大,风险也相对较大。
将换手率降序排列并保存数据
换手率是最重要的一个指标,所以将筛选出来的股票换手率进行降序排列并保存,以备日后取证与研究。
将序排列用 sort_values() 两数,保存用 to_csv() 函数。这两个函数都很常用,也比较简单。代码如下:
import tushare as ts
def today_data():
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data=csv_data[(csv_data["amount"]>1)]
csv_data["liutongliang"]=csv_data["nmc"]/csv_data["trade"]#增加流通盘的列
csv_data["turnoverratio"]=round(csv_data["turnoverratio"],2)#换手率保留2位
csv_data=csv_data[csv_data["turnoverratio"]>3]
csv_data=csv_data.sort_values(by="turnoverratio", ascending=False)
return csv_data经过一系列的数据清洗与筛选,选择出符合要求的股票数据并保存到 Jupter Notebook 中。我们将上述代码进行函数化处理,并命名为 get_data.py。
以后,只要运行如下代码,就会将得到的 csv_data 显示出来:
import get_data get_data.today_data()
模块化后,将去掉大量重复代码,重加专注一个功能,也会增强代码的可读性。
本文摘编自《Python量化交易实战》,经出版方授权发布。(ISBN:9787522602820)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!