
Maison >développement back-end >Tutoriel Python >14 opérations courantes dans Excel avec Python
14 opérations courantes dans Excel avec Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-15 19:07:01941parcourir

Bonjour à tous, je suis une recrue !
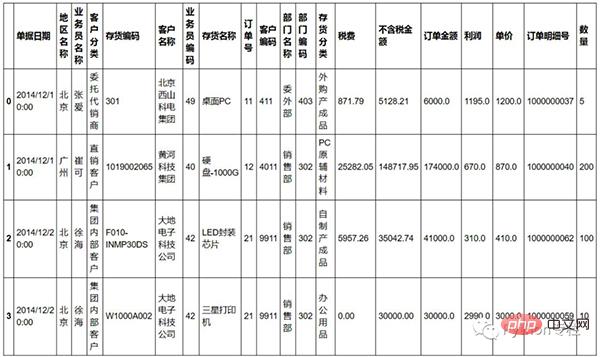
Les données sont des données de ventes trouvées en ligne. Elles ressemblent à ceci :
1. Formule d'association : Vlookup
Vlookup est presque la formule la plus couramment utilisée dans Excel, et est généralement utilisée pour les requêtes liées entre deux. tableaux. J'ai donc d'abord divisé ce tableau en deux tableaux.
df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号', '客户编码', '部门名称', '部门编码']] df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]
Demande : Je souhaite connaître le bénéfice correspondant à chaque commande de df1.
La colonne profit existe dans le tableau de df2, je souhaite donc connaître le profit correspondant à chaque commande de df1. Lorsque vous utilisez Excel, confirmez d'abord que le numéro de détail de la commande est une valeur unique, puis ajoutez une nouvelle colonne dans df1 et écrivez : =vlookup(a2,df2!a:h,6,0), puis déroulez-la vers le bas et elle apparaîtra. ça va. (Je n'écrirai pas Excel pour les 13 restants)
Comment l'implémenter en utilisant python ?
#查看订单明细号是否重复,结果是没。 df1["订单明细号"].duplicated().value_counts() df2["订单明细号"].duplicated().value_counts() df_c=pd.merge(df1,df2,on="订单明细号",how="left")
2. Tableau croisé dynamique
Exigence : je souhaite connaître le bénéfice total et le bénéfice moyen réalisé par les vendeurs dans chaque région.
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])
3. Comparez la différence entre les deux colonnes
Étant donné que les dimensions des données de chaque colonne de ce tableau sont différentes, cela n'a aucun sens de comparer, j'ai donc d'abord fait une différence dans les détails de la commande, puis j'ai comparé.
Exigence : Comparez la différence entre le numéro de détail de la commande et le numéro de détail de la commande 2 et affichez-la.
sale["订单明细号2"]=sale["订单明细号"] #在订单明细号2里前10个都+1. sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1 #差异输出 result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]
4. Supprimer les valeurs en double
Exigences : Supprimer les valeurs en double codées par le vendeur
sale.drop_duplicates("业务员编码",inplace=True) 5. Traitement des valeurs manquantes
Vérifiez d'abord quelles colonnes des données de vente ont des valeurs manquantes.
#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值 sale.info()

Exigence : Remplissez les valeurs manquantes avec 0 ou supprimez les lignes avec les valeurs manquantes codées par le client. En fait, la méthode de traitement des valeurs manquantes est très compliquée. Nous n'introduisons ici que des méthodes de traitement simples. S'il s'agit d'une variable numérique, la méthode la plus couramment utilisée est la moyenne, la médiane ou le mode. Le modèle forestier peut être utilisé pour prédire en fonction d'autres dimensions. Le résultat est renseigné. S'il s'agit d'une variable catégorielle, il est plus précis de la remplir selon la logique métier. Par exemple, l'exigence ici est de renseigner les valeurs manquantesdes noms de clients : elle peut être renseignée en fonction du nom de client correspondant à l'inventaire ayant la fréquence d'apparition la plus élevée dans la classification des stocks.
Ici, nous utilisons une solution simple : remplissez les valeurs manquantes avec 0 ou supprimez les lignes avec les valeurs manquantes codées par le client.
#用0填充缺失值 sale["客户名称"]=sale["客户名称"].fillna(0) #删除有客户编码缺失值的行 sale.dropna(subset=["客户编码"])
6. Filtrage multi-conditions
Demande : Je souhaite connaître les informations sur le vendeur Zhang Ai, qui vend des marchandises dans la région de Pékin avec un montant de commande supérieur à 6 000.
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]
7. Filtrage flou des données
Exigences : Filtrer les informations dont le nom d'inventaire contient "Samsung" ou "Sony".
sale.loc[sale["存货名称"].str.contains("三星|索尼")] 8. Classification et résumé
Exigences : Le bénéfice total de chaque vendeur dans la région de Pékin.
sale.groupby(["地区名称","业务员名称"])["利润"].sum()
9. Calcul conditionnel
Demande : Combien de commandes ont « Samsung » dans le nom de l'inventaire et la taxe est supérieure à 1 000 ? Quel est le montant et le bénéfice moyen de ces commandes ? (Ou valeur minimale, valeur maximale, quartile, différence d'étiquette)
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()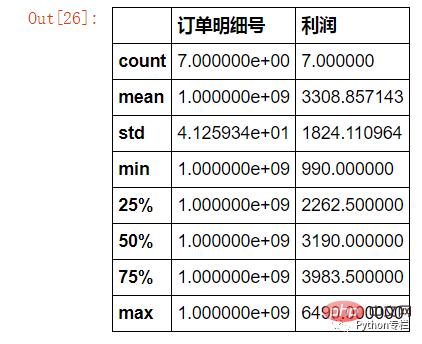
10. Supprimez les espaces entre les données
Exigence : Supprimez les espaces de part et d'autre du nom de l'inventaire.
sale["Inventory Name"].map(lambda s:s.strip(""))
11. Tri des données
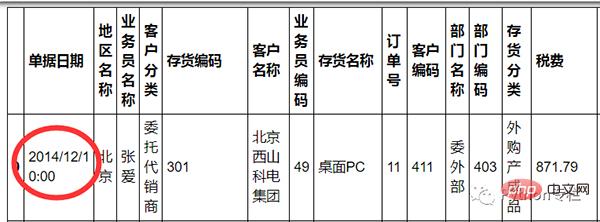
Exigence : trier la date et l'heure.
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True)12. Remplacement des valeurs aberrantes
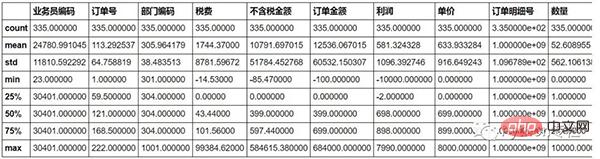
Tout d'abord, utilisez la fonction décrire() pour vérifier simplement s'il y a des valeurs aberrantes dans les données.
#Vous pouvez voir que la taxe en sortie a un nombre négatif. Ce n'est généralement pas le cas et est considéré comme une valeur aberrante.
sale.describe()
Exigence : Remplacer les valeurs aberrantes par 0.
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)
13. Regroupement
Exigence : Regroupez les régions selon la répartition des données de profit : "Faible", "Moyen", "Meilleur", "Très bon"
Tout d'abord, bien sûr, vérifiez le profit Distribution des données, nous utilisons ici des quartiles pour juger.
sale.groupby("地区名称")["利润"].sum().describe()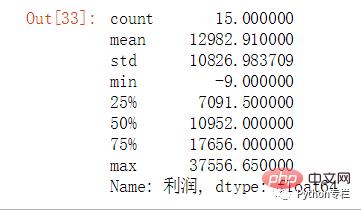
Selon le quartile, le bénéfice total régional est regroupé dans la fourchette [-9,7091] comme « pauvre », et la fourchette (7091,10952) est regroupée en « moyen » (10952,17656 ] le regroupement est meilleur, (17656,37556] est regroupé comme très bon.
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]
#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups) 14. Définir les balises selon la logique métier
Exigences : informations sur le produit avec une marge bénéficiaire des ventes (c'est-à-dire bénéfice/montant de la commande) supérieure à 30 % et marquez-le comme Pour les produits de haute qualité, moins de 5 % sont des produits généraux.
sale.loc[(sale["利润"]/sale["订单金额"])>0.3,"label"]="优质商品" sale.loc[(sale["利润"]/sale["订单金额"])<0.05,"label"]="一般商品"
En fait, il existe de nombreuses opérations couramment utilisées dans Excel, j'en ai répertorié 14 que j'utilise couramment si vous souhaitez implémenter d'autres opérations. , vous pouvez les commenter et en discuter ensemble. De plus, je les connais aussi. Mon écriture en python n'est pas assez concise, j'utilise donc loc (en fait, la requête sera plus concise si vous avez une meilleure façon d'écrire). ces opérations, merci de me le faire savoir dans les commentaires Merci !
Enfin, je voudrais dire que je pense qu'il est préférable de ne pas comparer Excel et Python pour étudier lequel est le plus facile à utiliser. En fait, ce sont deux outils. En tant qu'outil de traitement de données le plus répandu, Excel a été monopolisé. depuis tant d'années et doit être assez excellent en termes de commodité dans le traitement des données, certaines opérations sont en effet plus simples en python, mais il existe également de nombreuses opérations en Excel qui sont plus simples que Python.
Par exemple, une opération très simple : additionnez chaque colonne et affichez-la sur la ligne du bas. Excel ajoute simplement une fonction sum() à chaque colonne, puis la tire vers la gauche pour la résoudre, tandis que python doit la définir. une fonction (Comme python doit déterminer le format, il signalera directement une erreur s'il ne s'agit pas d'une valeur numérique)
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!