
Maison >Périphériques technologiques >IA >Présentation des méthodes d'ensemble dans l'apprentissage automatique
Présentation des méthodes d'ensemble dans l'apprentissage automatique

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-15 13:52:071158parcourir
Imaginez que vous faites des achats en ligne et que vous trouvez deux magasins vendant le même produit avec la même note. Cependant, le premier a été évalué par une seule personne et le second par 100 personnes. À quelle note feriez-vous davantage confiance ? Quel produit choisirez-vous d’acheter au final ? La réponse pour la plupart des gens est simple. Les opinions de 100 personnes sont certainement plus fiables que celles d’une seule. C’est ce qu’on appelle la « sagesse de la foule » et c’est pourquoi l’approche d’ensemble fonctionne.

Méthodes d'ensemble
Habituellement, nous créons uniquement un apprenant (apprenant = modèle de formation) à partir des données de formation (c'est-à-dire que nous formons uniquement un modèle d'apprentissage automatique sur les données de formation). La méthode d’ensemble consiste à laisser plusieurs apprenants résoudre le même problème, puis à les combiner. Ces apprenants sont appelés apprenants de base et peuvent avoir n’importe quel algorithme sous-jacent, tel que des réseaux de neurones, des machines à vecteurs de support, des arbres de décision, etc. Si tous ces apprenants de base sont composés du même algorithme alors ils sont appelés apprenants de base homogènes, tandis que s'ils sont composés d'algorithmes différents alors ils sont appelés apprenants de base hétérogènes. Comparé à un apprenant de base unique, un ensemble possède de meilleures capacités de généralisation, ce qui entraîne de meilleurs résultats.
Lorsque la méthode d'ensemble est composée d'apprenants faibles. C’est pourquoi les apprenants de base sont parfois appelés apprenants faibles. Alors que les modèles d'ensemble ou les apprenants forts (qui sont des combinaisons de ces apprenants faibles) ont un biais/variance plus faible et obtiennent de meilleures performances. La capacité de cette approche intégrée à transformer les apprenants faibles en apprenants forts est devenue populaire parce que les apprenants faibles sont plus facilement disponibles dans la pratique.
Ces dernières années, les méthodes intégrées ont continuellement remporté divers concours en ligne. Outre les compétitions en ligne, les méthodes d'ensemble sont également appliquées à des applications réelles telles que les technologies de vision par ordinateur telles que la détection, la reconnaissance et le suivi d'objets.
Principaux types de méthodes d'ensemble
Comment les apprenants faibles sont-ils générés ?
Selon la méthode de génération de l'apprenant de base, les méthodes d'intégration peuvent être divisées en deux grandes catégories, à savoir les méthodes d'intégration séquentielle et les méthodes d'intégration parallèle. Comme son nom l'indique, dans la méthode d'ensemble séquentiel, les apprenants de base sont générés séquentiellement puis combinés pour faire des prédictions, telles que des algorithmes Boosting tels qu'AdaBoost. Dans la méthode d'ensemble parallèle, les apprenants de base sont générés en parallèle puis combinés pour la prédiction, comme les algorithmes d'ensachage tels que la forêt aléatoire et l'empilement. La figure suivante montre une architecture simple expliquant les approches parallèles et séquentielles.
Selon les différentes méthodes de génération des apprenants de base, les méthodes d'intégration peuvent être divisées en deux grandes catégories : les méthodes d'intégration séquentielle et les méthodes d'intégration parallèle. Comme son nom l'indique, dans la méthode d'ensemble séquentiel, les apprenants de base sont générés dans l'ordre puis combinés pour faire des prédictions, telles que des algorithmes Boosting tels qu'AdaBoost. Dans les méthodes d'ensemble parallèles, les apprenants de base sont générés en parallèle, puis combinés pour la prédiction, comme les algorithmes d'ensachage tels que Random Forest et Stacking. La figure ci-dessous montre une architecture simple expliquant à la fois les approches parallèles et séquentielles.
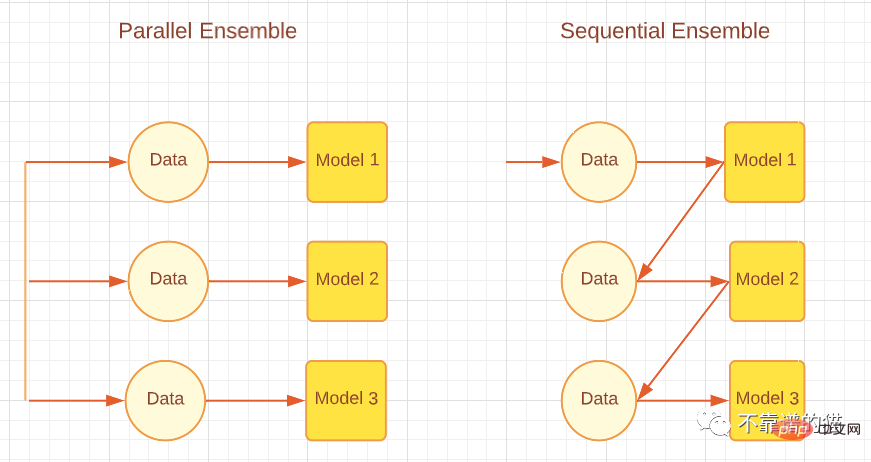
Méthodes d'intégration parallèle et séquentielle
Les méthodes d'apprentissage séquentiel profitent des dépendances entre les apprenants faibles pour améliorer la performance globale de manière résiduelle-décroissante, permettant aux apprenants ultérieurs de prêter plus d'attention aux erreurs des anciens apprenants. En gros (pour les problèmes de régression), la réduction de l’erreur du modèle d’ensemble obtenue par les méthodes de boosting est principalement obtenue en réduisant le biais élevé des apprenants faibles, bien qu’une réduction de la variance soit parfois observée. D’autre part, la méthode des ensembles parallèles réduit l’erreur en combinant des apprenants faibles indépendants, c’est-à-dire qu’elle exploite l’indépendance entre apprenants faibles. Cette réduction des erreurs est due à une réduction de la variance du modèle d'apprentissage automatique. Par conséquent, nous pouvons résumer que le boosting réduit principalement les erreurs en réduisant le biais des modèles d’apprentissage automatique, tandis que le bagging réduit les erreurs en réduisant la variance des modèles d’apprentissage automatique. Ceci est important car la méthode d’ensemble choisie dépendra du fait que les apprenants faibles présentent une variance élevée ou un biais élevé.
Comment regrouper les apprenants faibles ?
Après avoir généré ces soi-disant apprenants de base, nous ne sélectionnons pas les meilleurs de ces apprenants, mais les combinons ensemble pour une meilleure généralisation, la façon dont nous procédons joue un rôle important dans l'approche d'ensemble.
Moyenne : lorsque le résultat est un nombre, la façon la plus courante de combiner les apprenants de base est la moyenne. La moyenne peut être une moyenne simple ou une moyenne pondérée. Pour les problèmes de régression, la moyenne simple sera la somme des erreurs de tous les modèles de base divisée par le nombre total d’apprenants. Le résultat combiné moyen pondéré est obtenu en attribuant des pondérations différentes à chaque apprenant de base. Pour les problèmes de régression, nous multiplions l’erreur de chaque apprenant de base par le poids donné, puis nous la additionnons.
Vote : pour les résultats nominaux, le vote est le moyen le plus courant de combiner les apprenants de base. Le vote peut être de différents types tels que le vote majoritaire, le vote majoritaire, le vote pondéré et le vote soft. Pour les problèmes de classification, un vote à la majorité qualifiée donne à chaque apprenant une voix et il vote pour une étiquette de classe. Quel que soit le label de classe qui obtient plus de 50 % des voix, c'est le résultat prévu de l'ensemble. Cependant, si aucune étiquette de classe n'obtient plus de 50 % des voix, une option de rejet est proposée, ce qui signifie que l'ensemble combiné ne peut faire aucune prédiction. Lors du vote à majorité relative, l'étiquette de classe avec le plus de votes est le résultat de la prédiction, et plus de 50 % des votes ne sont pas nécessaires pour l'étiquette de classe. Cela signifie que si nous avons trois étiquettes de sortie et que toutes les trois obtiennent des résultats inférieurs à 50 %, par exemple 40 %, 30 %, 30 %, alors l'obtention de 40 % des étiquettes de classe est le résultat de prédiction du modèle d'ensemble. . Le vote pondéré, comme la moyenne pondérée, attribue des pondérations aux classificateurs en fonction de leur importance et de la force d'un apprenant particulier. Le vote doux est utilisé pour les sorties de classe avec des probabilités (valeurs comprises entre 0 et 1) plutôt que des étiquettes (binaires ou autres). Le vote doux est divisé en vote doux simple (une simple moyenne de probabilités) et en vote doux pondéré (des poids sont attribués aux apprenants, et les probabilités sont multipliées par ces poids et ajoutées).
Apprentissage : une autre façon de combiner est l'apprentissage, qui est utilisé par la méthode des ensembles d'empilement. Dans cette approche, un apprenant distinct appelé méta-apprenant est formé sur un nouvel ensemble de données pour combiner d'autres apprenants de base/faibles générés à partir de l'ensemble de données d'apprentissage automatique d'origine.
Veuillez noter que qu'il s'agisse de boosting, d'ensachage ou d'empilement, les trois méthodes d'ensemble peuvent être générées en utilisant des apprenants faibles homogènes ou hétérogènes. L’approche la plus courante consiste à utiliser des apprenants faibles homogènes pour le bagging et le boosting, et des apprenants faibles hétérogènes pour l’empilement. La figure ci-dessous fournit une bonne classification des trois principales méthodes d'ensemble.
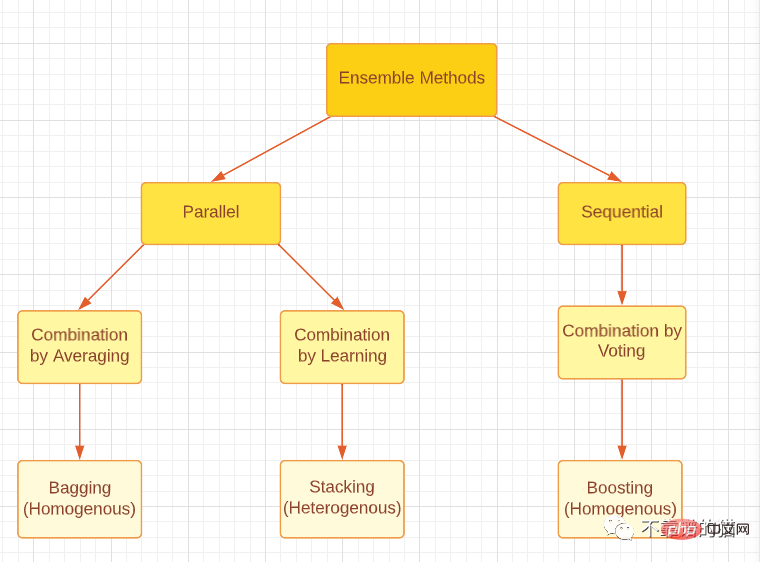
Classer les principaux types de méthodes d'ensemble
Diversité d'ensemble
La diversité d'ensemble fait référence à la différence entre les apprenants de base, ce qui est d'une grande importance pour générer de bons modèles d'ensemble. Il a été théoriquement prouvé que, grâce à différentes méthodes de combinaison, des apprenants de base complètement indépendants (diversifiés) peuvent minimiser les erreurs, tandis que des apprenants complètement (hautement) liés n'apportent aucune amélioration. Il s’agit d’un problème difficile dans la vie réelle, car nous formons tous les apprenants faibles à résoudre le même problème en utilisant le même ensemble de données, ce qui entraîne une forte corrélation. En outre, nous devons veiller à ce que les apprenants faibles ne soient pas de véritables mauvais modèles, car cela pourrait même entraîner une détérioration des performances d’ensemble. D’un autre côté, combiner des apprenants de base forts et précis peut ne pas être aussi efficace que combiner des apprenants faibles avec des apprenants forts. Par conséquent, un équilibre doit être trouvé entre la précision de l’apprenant de base et les différences entre les apprenants de base.
Comment parvenir à une diversité intégrée ?
1. Traitement des données
Nous pouvons diviser notre ensemble de données en sous-ensembles pour les apprenants de base. Si l'ensemble de données d'apprentissage automatique est volumineux, nous pouvons simplement diviser l'ensemble de données en parties égales et les introduire dans le modèle d'apprentissage automatique. Si l'ensemble de données est petit, nous pouvons utiliser l'échantillonnage aléatoire avec remplacement pour générer un nouvel ensemble de données à partir de l'ensemble de données d'origine. La méthode d'ensachage utilise la technique d'amorçage pour générer de nouveaux ensembles de données, qui sont essentiellement un échantillonnage aléatoire avec remplacement. Avec le bootstrap, nous sommes en mesure de créer un certain caractère aléatoire puisque tous les ensembles de données générés doivent avoir des valeurs différentes. Notez cependant que la plupart des valeurs (environ 67% selon la théorie) seront quand même répétées, les ensembles de données ne seront donc pas complètement indépendants.
2. Fonctionnalités d'entrée
Tous les ensembles de données contiennent des fonctionnalités qui fournissent des informations sur les données. Au lieu d'utiliser toutes les fonctionnalités dans un seul modèle, nous pouvons créer des sous-ensembles de fonctionnalités, générer différents ensembles de données et les intégrer dans le modèle. Cette méthode est adoptée par la technique de forêt aléatoire et est efficace lorsqu'il existe un grand nombre de fonctionnalités redondantes dans les données. L'efficacité diminue lorsqu'il y a peu de fonctionnalités dans l'ensemble de données.
3. Paramètres d'apprentissage
Cette technique génère du caractère aléatoire chez l'apprenant de base en appliquant différents paramètres à l'algorithme d'apprentissage de base, c'est-à-dire le réglage des hyperparamètres. Par exemple, en modifiant les termes de régularisation, différents poids initiaux peuvent être attribués aux réseaux neuronaux individuels.
Élagage d'intégration
Enfin, la technologie d'élagage d'intégration peut aider à obtenir de meilleures performances d'intégration dans certains cas. L'élagage d'ensemble signifie que nous combinons uniquement un sous-ensemble d'apprenants au lieu de combiner tous les apprenants faibles. En plus de cela, des intégrations plus petites peuvent économiser des ressources de stockage et de calcul, améliorant ainsi l'efficacité.
Enfin
Cet article n'est qu'un aperçu des méthodes d'ensemble d'apprentissage automatique. J’espère que tout le monde pourra mener des recherches plus approfondies et, plus important encore, pouvoir appliquer ces recherches à la vie réelle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI