
Maison >Périphériques technologiques >IA >Google résout le problème du stockage et de la manipulation des données à n dimensions grâce à une bibliothèque de logiciels open source
Google résout le problème du stockage et de la manipulation des données à n dimensions grâce à une bibliothèque de logiciels open source

- 王林avant
- 2023-04-15 10:52:051565parcourir
De nombreuses applications en informatique et en apprentissage automatique (ML) nécessitent le traitement d'ensembles de données multidimensionnels à travers des systèmes de coordonnées, et un seul ensemble de données peut également devoir stocker des téraoctets ou des pétaoctets de données. D’un autre côté, travailler avec de tels ensembles de données est également un défi car les utilisateurs peuvent lire et écrire des données à intervalles irréguliers et à différentes échelles, effectuant souvent de grandes quantités de travail parallèle.
Pour résoudre les problèmes ci-dessus, Google a développé TensorStore, une bibliothèque logicielle open source C++ et Python, conçue pour stocker et exploiter des données à n dimensions. Jeff Dean, responsable de Google AI, a également tweeté que TensorStore est désormais officiellement open source.
Les principales fonctions de TensorStore incluent :
- Fournir une API unifiée pour lire et écrire plusieurs formats de tableaux, y compris zarr et N5 ;
- Prise en charge native de plusieurs systèmes de stockage, y compris Google Cloud ; Stockage, systèmes de fichiers locaux et réseau, serveurs HTTP et stockage en mémoire ;
- prend en charge la mise en cache et les transactions en lecture/écriture, avec de fortes fonctionnalités d'atomicité, d'isolation, de cohérence et de durabilité (ACID) ; accès simultané à partir de plusieurs processus et machines ;
- Fournit une API asynchrone pour permettre un accès à haut débit au stockage distant à haute latence ;
- Fournit des opérations d'index avancées et entièrement composables et une vue de virtualisation.
- TensorStore a été utilisé pour résoudre des défis d'ingénierie en calcul scientifique et a également été utilisé pour créer de grands modèles d'apprentissage automatique, par exemple pour gérer les paramètres du modèle (points de contrôle) de PaLM lors d'une formation distribuée.
 Adresse GitHub : https://github.com/google/tensorstore
Adresse GitHub : https://github.com/google/tensorstore
API pour l'accès et la manipulation des données
TensorStore fournit une API Python simple pour le chargement et la manipulation de données de grand tableau. Par exemple, le code suivant crée un objet TensorStore qui représente une image 3D de 56 billions de voxels d'un cerveau de mouche et permet d'accéder à des données de patch d'image 100x100 dans un tableau NumPy :
Notamment, le programme n'accède pas les données réelles en mémoire jusqu'à ce qu'elles accèdent à un patch spécifique de 100 x 100, de sorte que des ensembles de données sous-jacentes arbitrairement volumineux puissent être chargés et manipulés sans stocker l'intégralité de l'ensemble de données en mémoire. TensorStore utilise essentiellement la même syntaxe d'indexation et d'opération que le NumPy standard. 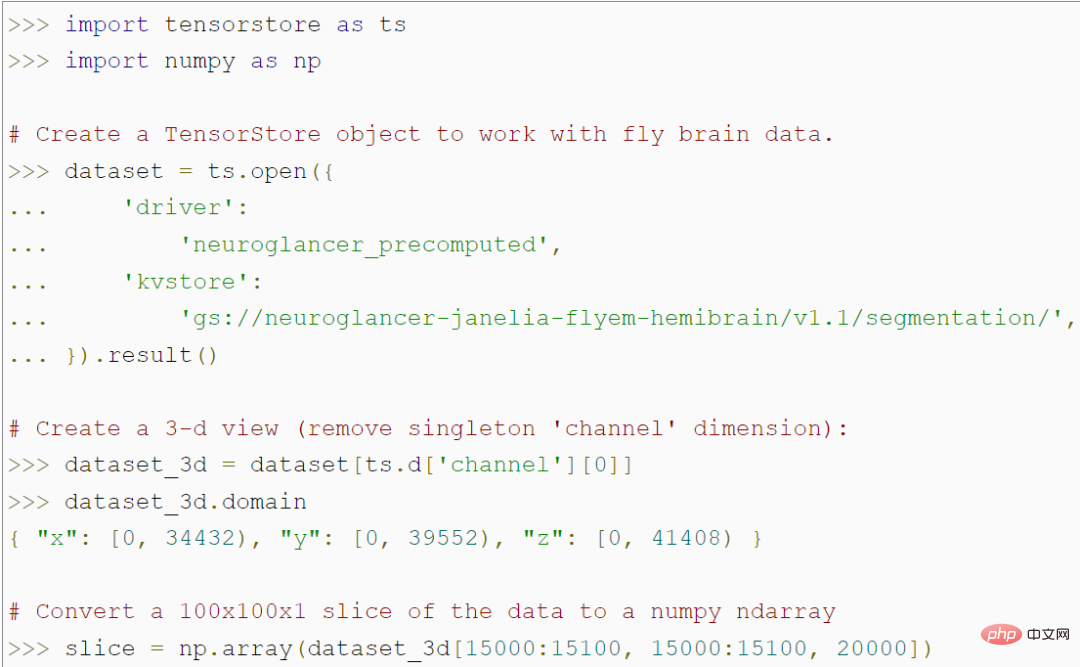
De plus, TensorStore offre une prise en charge étendue des fonctionnalités d'indexation avancées, notamment l'alignement, les vues virtuelles, etc.
Le code suivant montre comment créer un tableau zarr à l'aide de TensorStore et comment l'API asynchrone de TensorStore peut atteindre un débit plus élevé :
Extensions de sécurité et de performances
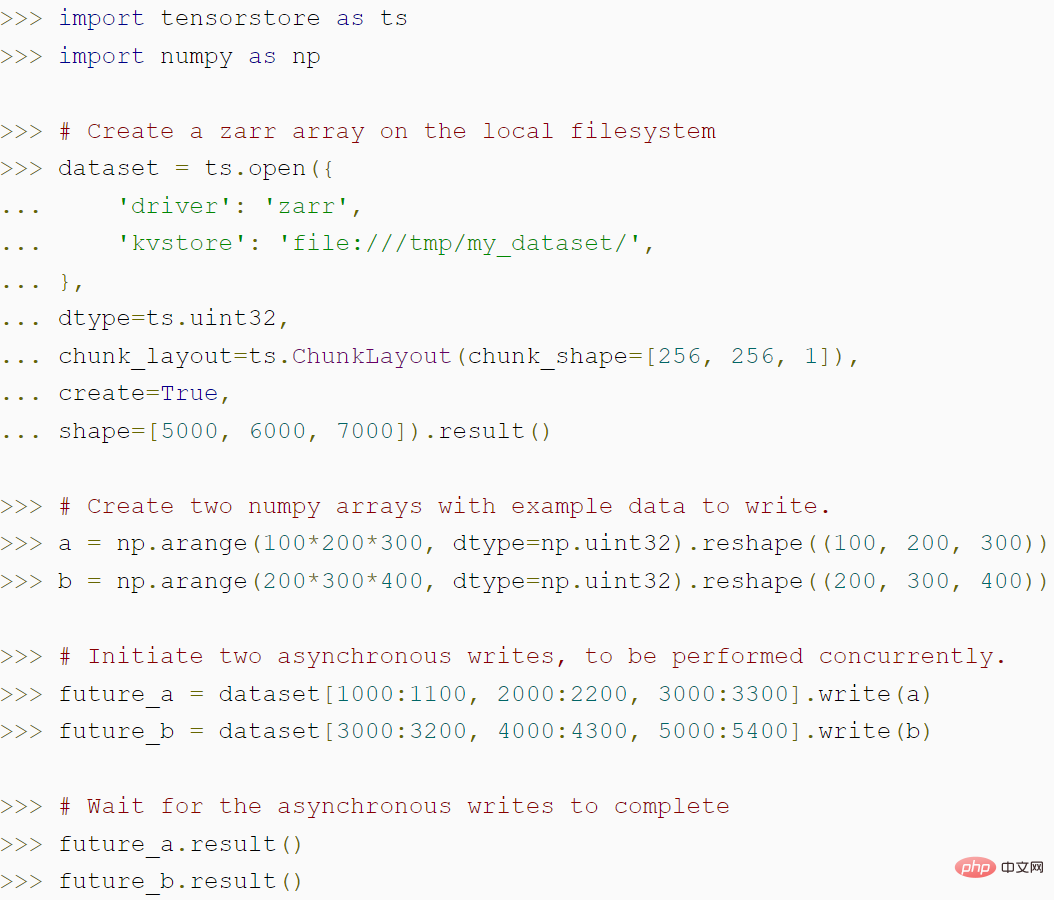
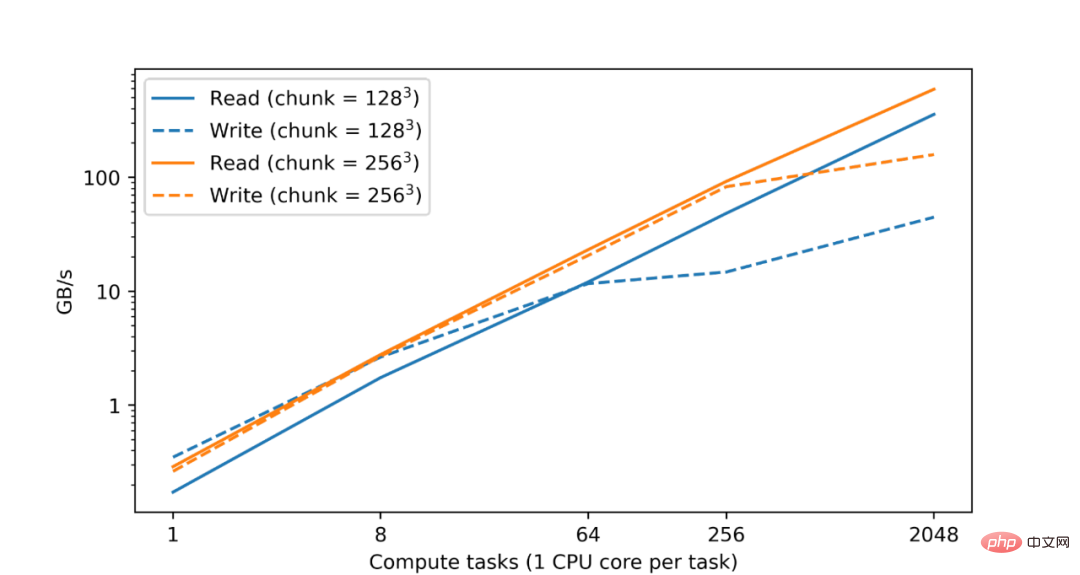
TensorStore fournit également un cache mémoire configurable et une API asynchrone pour permettre aux opérations de lecture et d'écriture de se poursuivre en arrière-plan pendant que le programme effectue d'autres travaux. Pour rendre l'informatique distribuée de TensorStore compatible avec les workflows de traitement des données, Google intègre également TensorStore à des bibliothèques informatiques parallèles telles qu'Apache Beam.
Exemple d'affichage
Exemple 1 Modèle de langage : Ces derniers temps, certains modèles de langage avancés tels que PaLM sont apparus dans le domaine de l'apprentissage automatique. Ces modèles contiennent des centaines de milliards de paramètres et présentent des capacités étonnantes en matière de compréhension et de génération du langage naturel. Cependant, ces modèles posent des défis aux installations informatiques. En particulier, la formation d'un modèle de langage tel que PaLM nécessite que des milliers de TPU fonctionnent en parallèle.
La lecture et l'écriture efficaces des paramètres du modèle sont un problème rencontré dans le processus de formation : par exemple, la formation est distribuée sur différentes machines, mais les paramètres doivent être enregistrés régulièrement dans des points de contrôle. Par exemple, une seule formation ne doit lire que des ensembles de paramètres spécifiques ; pour éviter la surcharge nécessaire au chargement de l'ensemble des paramètres du modèle (qui peut représenter des centaines de Go).
TensorStore peut résoudre les problèmes ci-dessus. Il a été utilisé pour gérer les points de contrôle liés aux grands modèles (multipodes) et a été intégré à des frameworks tels que T5X et Pathways. TensorStore convertit les points de contrôle en stockage au format zarr et choisit la structure de blocs pour permettre la lecture et l'écriture des partitions de chaque TPU en parallèle et indépendamment.

Lorsque le point de contrôle est enregistré, les paramètres sont écrits au format zarr et la grille de blocs est encore divisée pour diviser la grille de paramètres sur le TPU. L'hôte écrit des blocs zarr en parallèle pour chaque partition attribuée au TPU de l'hôte. Grâce à l'API asynchrone de TensorStore, la formation se poursuit même si les données sont toujours en cours d'écriture sur un stockage persistant. Lors de la récupération à partir d'un point de contrôle, chaque hôte lit uniquement les blocs de partition attribués à cet hôte.
Exemple 2 Cartographie 3D du cerveau : La connectomique résolue par les synapses vise à cartographier le câblage des cerveaux animaux et humains au niveau des connexions synaptiques individuelles. Pour y parvenir, il faut imager le cerveau à une résolution extrêmement élevée (à l’échelle nanométrique) sur un champ de vision de quelques millimètres ou plus, ce qui génère des pétaoctets de données. Cependant, même aujourd’hui, les ensembles de données sont confrontés à des problèmes de stockage, de traitement, etc. Même un seul échantillon de cerveau peut nécessiter des millions de gigaoctets d’espace.
Google a utilisé TensorStore pour résoudre les défis informatiques associés aux ensembles de données connectomiques à grande échelle. Plus précisément, TensorStore a commencé à gérer certains ensembles de données connectomiques et utilise Google Cloud Storage comme système de stockage d'objets sous-jacent.
Actuellement, TensorStore a été utilisé pour l'ensemble de données du cortex cérébral humain H01, et les données d'imagerie originales sont de 1,4 Po (environ 500 000 * 350 000 * 5 000 pixels). Les données brutes sont ensuite subdivisées en blocs indépendants de 128x128x16 pixels et stockées dans un format "Neuroglancer précalculé", facilement manipulable par TensorStore.

TensorStore peut être utilisé pour accéder et manipuler facilement les données sous-jacentes (reconstruction du cerveau de mouche)
Les amis qui souhaitent commencer peuvent utiliser la méthode suivante pour installer le package TensorStore PyPI :
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tensorstore</span>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI