
Maison >développement back-end >Tutoriel Python >Dix techniques alternatives de traitement des données pour les Pandas
Dix techniques alternatives de traitement des données pour les Pandas

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-15 09:19:022459parcourir
Les techniques compilées dans cet article sont différentes des techniques courantes compilées dans 10 Pandas auparavant. Vous ne les utilisez peut-être pas souvent, mais parfois, lorsque vous rencontrez des problèmes très difficiles, ces techniques peuvent vous aider à les résoudre rapidement.

1. Type catégoriel
Par défaut, les colonnes avec un nombre limité d'options se verront attribuer le type d'objet. Mais ce n'est pas un choix efficace en termes de mémoire. Nous pouvons indexer ces colonnes et utiliser uniquement des références aux objets et non aux valeurs réelles. Pandas fournit un Dtype appelé Catégorique pour résoudre ce problème.
Par exemple, il s'agit d'un grand ensemble de données avec des chemins d'images. Chaque ligne comporte trois colonnes : ancre, positive et négative.
Si vous utilisez Catégorique pour les colonnes catégorielles, vous pouvez réduire considérablement l'utilisation de la mémoire.
# raw data +----------+------------------------+ |class |filename| +----------+------------------------+ | Bathroom | Bathroombath_1.jpg| | Bathroom | Bathroombath_100.jpg| | Bathroom | Bathroombath_1003.jpg | | Bathroom | Bathroombath_1004.jpg | | Bathroom | Bathroombath_1005.jpg | +----------+------------------------+ # target +------------------------+------------------------+----------------------------+ | anchor |positive|negative| +------------------------+------------------------+----------------------------+ | Bathroombath_1.jpg| Bathroombath_100.jpg| Dinningdin_540.jpg| | Bathroombath_100.jpg| Bathroombath_1003.jpg | Dinningdin_1593.jpg | | Bathroombath_1003.jpg | Bathroombath_1004.jpg | Bedroombed_329.jpg| | Bathroombath_1004.jpg | Bathroombath_1005.jpg | Livingroomliving_1030.jpg | | Bathroombath_1005.jpg | Bathroombath_1007.jpg | Bedroombed_1240.jpg | +------------------------+------------------------+----------------------------+
La valeur de la colonne du nom de fichier sera copiée fréquemment. Par conséquent, l’utilisation de la mémoire peut être considérablement réduite en utilisant Catégorique.
Lisons l'ensemble de données cible et voyons la différence de mémoire :
triplets.info(memory_usage="deep") # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 anchor 525000 non-null category # 1 positive 525000 non-null category # 2 negative 525000 non-null category # dtypes: category(3) # memory usage: 4.6 MB # without categories triplets_raw.info(memory_usage="deep") # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 anchor 525000 non-null object # 1 positive 525000 non-null object # 2 negative 525000 non-null object # dtypes: object(3) # memory usage: 118.1 MB
La différence est très grande et augmente de manière non linéaire à mesure que le nombre de répétitions augmente.
2. Conversion ligne-colonne
Nous rencontrons souvent le problème de la conversion ligne-colonne en SQL, et Pandas en a parfois besoin. Jetons un coup d'œil à l'ensemble de données du concours Kaggle. Fichier recensement_start .csv :
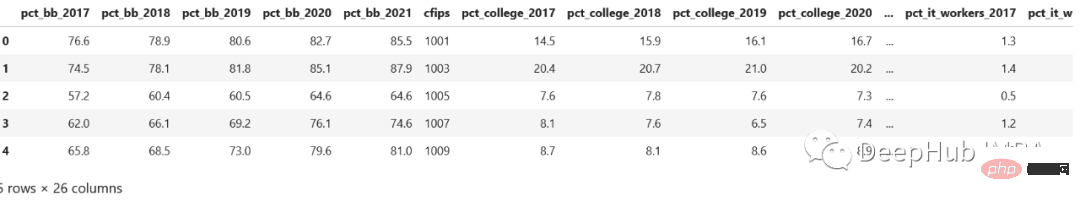
Comme vous pouvez le voir, ceux-ci sont enregistrés par année. Ce serait bien mieux s'il y avait une colonne year et pct_bb, et chaque ligne avait des valeurs correspondantes, n'est-ce pas.
cols = sorted([col for col in original_df.columns
if col.startswith("pct_bb")])
df = original_df[(["cfips"] + cols)]
df = df.melt(id_vars="cfips",
value_vars=cols,
var_name="year",
value_name="feature").sort_values(by=["cfips", "year"])Regardez le résultat, est-ce bien mieux ainsi :

3 apply() est très lent
Nous l'avons introduit la dernière fois, il est préférable de ne pas utiliser cette méthode car elle traverse chaque ligne et appelez la méthode spécifiée. Mais si nous n’avons pas d’autre choix, existe-t-il un moyen d’augmenter la vitesse ?
Vous pouvez utiliser des packages comme Swifter ou Pandarallew pour paralléliser le processus.
Swifter
import pandas as pd import swifter def target_function(row): return row * 10 def traditional_way(data): data['out'] = data['in'].apply(target_function) def swifter_way(data): data['out'] = data['in'].swifter.apply(target_function)
Pandaralllel
import pandas as pd from pandarallel import pandarallel def target_function(row): return row * 10 def traditional_way(data): data['out'] = data['in'].apply(target_function) def pandarallel_way(data): pandarallel.initialize() data['out'] = data['in'].parallel_apply(target_function)
Grâce au multi-threading, la vitesse de calcul peut être améliorée. Bien sûr, s'il y a un cluster, il est préférable d'utiliser dask ou pyspark
4.
Données entières standard Le type ne prend pas en charge les valeurs nulles, il est donc automatiquement converti en nombre à virgule flottante. Ainsi, si vos données nécessitent des valeurs nulles dans des champs entiers, envisagez d'utiliser le type de données Int64 car il utilisera pandas.NA pour représenter les valeurs nulles.
5. Csv, compression ou parquet ?
Choisissez le plus possible du parquet. Parquet conservera le type de données, il n'est donc pas nécessaire de spécifier des types lors de la lecture des données. Les fichiers Parquet sont compressés à l'aide de Snappy par défaut, ils occupent donc peu d'espace disque. Ci-dessous, vous pouvez voir quelques comparaisons
|file|size | +------------------------+---------+ | triplets_525k.csv| 38.4 MB | | triplets_525k.csv.gzip |4.3 MB | | triplets_525k.csv.zip|4.5 MB | | triplets_525k.parquet|1.9 MB | +------------------------+---------+
La lecture du parquet nécessite des packages supplémentaires, tels que pyarrow ou fastparquet. chatgpt a dit que pyarrow est plus rapide que fastparquet, mais lorsque j'ai testé sur un petit ensemble de données, fastparquet était plus rapide que pyarrow, mais il est recommandé d'utiliser pyarrow ici, car pandas 2.0 l'utilise également par défaut.
6, value_counts ()
Le calcul des fréquences relatives, y compris l'obtention de la valeur absolue, le comptage et la division par le total, est complexe, mais avec value_counts, cette tâche peut être accomplie plus facilement et la méthode offre la possibilité d'inclure ou d'exclure options de valeur nulle.
df = pd.DataFrame({"a": [1, 2, None], "b": [4., 5.1, 14.02]})
df["a"] = df["a"].astype("Int64")
print(df.info())
print(df["a"].value_counts(normalize=True, dropna=False),
df["a"].value_counts(normalize=True, dropna=True), sep="nn")

N'est-ce pas beaucoup plus simple
7 Modin
Remarque : Modin est encore en phase de test.
pandas est monothread, mais Modin peut accélérer votre flux de travail en mettant à l'échelle les pandas, et il fonctionne particulièrement bien sur des ensembles de données plus volumineux où les pandas peuvent devenir très lents ou gourmands en mémoire à cause du MOO.
!pip install modin[all]
import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")Ce qui suit est le schéma d'architecture du site officiel du modin Si vous souhaitez l'étudier :

import pandas as pd
regex = (r'(?P<title>[A-Za-z's]+),'
r'(?P<author>[A-Za-zs']+),'
r'(?P<isbn>[d-]+),'
r'(?P<year>d{4}),'
r'(?P<publisher>.+)')
addr = pd.Series([
"The Lost City of Amara,Olivia Garcia,978-1-234567-89-0,2023,HarperCollins",
"The Alchemist's Daughter,Maxwell Greene,978-0-987654-32-1,2022,Penguin Random House",
"The Last Voyage of the HMS Endeavour,Jessica Kim,978-5-432109-87-6,2021,Simon & Schuster",
"The Ghosts of Summer House,Isabella Lee,978-3-456789-12-3,2000,Macmillan Publishers",
"The Secret of the Blackthorn Manor,Emma Chen,978-9-876543-21-0,2023,Random House Children's Books"
])
addr.str.extract(regex)

9、读写剪贴板
这个技巧有人一次也用不到,但是有人可能就是需要,比如:在分析中包含PDF文件中的表格时。通常的方法是复制数据,粘贴到Excel中,导出到csv文件中,然后导入Pandas。但是,这里有一个更简单的解决方案:pd.read_clipboard()。我们所需要做的就是复制所需的数据并执行一个方法。
有读就可以写,所以还可以使用to_clipboard()方法导出到剪贴板。
但是要记住,这里的剪贴板是你运行python/jupyter主机的剪切板,并不可能跨主机粘贴,一定不要搞混了。
10、数组列分成多列
假设我们有这样一个数据集,这是一个相当典型的情况:
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3],
"b": [4, 5, 6],
"category": [["foo", "bar"], ["foo"], ["qux"]]})
# let's increase the number of rows in a dataframe
df = pd.concat([df]*10000, ignore_index=True)

我们想将category分成多列显示,例如下面的

先看看最慢的apply:
def dummies_series_apply(df):
return df.join(df['category'].apply(pd.Series)
.stack()
.str.get_dummies()
.groupby(level=0)
.sum())
.drop("category", axis=1)
%timeit dummies_series_apply(df.copy())
#5.96 s ± 66.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)sklearn的MultiLabelBinarizer
from sklearn.preprocessing import MultiLabelBinarizer
def sklearn_mlb(df):
mlb = MultiLabelBinarizer()
return df.join(pd.DataFrame(mlb.fit_transform(df['category']), columns=mlb.classes_))
.drop("category", axis=1)
%timeit sklearn_mlb(df.copy())
#35.1 ms ± 1.31 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)是不是快了很多,我们还可以使用一般的向量化操作对其求和:
def dummies_vectorized(df):
return pd.get_dummies(df.explode("category"), prefix="cat")
.groupby(["a", "b"])
.sum()
.reset_index()
%timeit dummies_vectorized(df.copy())
#29.3 ms ± 1.22 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)

使用第一个方法(在StackOverflow上的回答中非常常见)会给出一个非常慢的结果。而其他两个优化的方法的时间是非常快速的。
总结
我希望每个人都能从这些技巧中学到一些新的东西。重要的是要记住尽可能使用向量化操作而不是apply()。此外,除了csv之外,还有其他有趣的存储数据集的方法。不要忘记使用分类数据类型,它可以节省大量内存。感谢阅读!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!