
Maison >développement back-end >Tutoriel Python >Système de reconnaissance faciale Python avec un taux de reconnaissance hors ligne allant jusqu'à 99 %, open source~
Système de reconnaissance faciale Python avec un taux de reconnaissance hors ligne allant jusqu'à 99 %, open source~

- 王林avant
- 2023-04-14 14:55:032294parcourir

Dans le passé, la reconnaissance faciale incluait principalement des technologies et des systèmes tels que la collecte d'images faciales, le prétraitement de la reconnaissance faciale, la confirmation d'identité et la recherche d'identité. Désormais, la reconnaissance faciale s'est lentement étendue à la détection des conducteurs, au suivi des piétons et même au suivi dynamique des objets dans ADAS.
Il ressort de cela que le système de reconnaissance faciale est passé du simple traitement d'image au traitement vidéo en temps réel. De plus, l'algorithme est passé des méthodes statistiques traditionnelles telles que Adaboots et PCA aux méthodes d'apprentissage en profondeur telles que CNN et RCNN et leurs modifications. Aujourd'hui, un nombre considérable de personnes ont commencé à étudier la reconnaissance faciale 3D, et ce type de projet est actuellement soutenu par le monde universitaire, l'industrie et le pays.
Tout d’abord, jetons un coup d’œil à l’état actuel de la recherche. Comme le montrent les tendances de développement ci-dessus, la principale direction de recherche actuelle consiste à utiliser des méthodes d'apprentissage en profondeur pour résoudre la reconnaissance faciale vidéo.
Chercheurs principaux :
Comme suit : le professeur Shan Shiguang de l'Institut de technologie informatique, Académie chinoise des sciences, le professeur Li Ziqing de l'Institut de biométrie, Académie chinoise des sciences, le professeur Su Guangda de l'Université Tsinghua, le professeur Tang Xiaoou de l'Université chinoise de Hong Kong, Ross B. Girshick, etc.
Principaux projets open source :
Moteur de reconnaissance faciale SeetaFace. Le moteur a été développé par le groupe de recherche sur la reconnaissance faciale dirigé par le chercheur Shan Shiguang de l'Institut de technologie informatique de l'Académie chinoise des sciences. Le code est implémenté sur la base du C++ et ne repose sur aucune fonction de bibliothèque tierce. La licence open source est BSD-2 et peut être utilisée gratuitement par le monde universitaire et l'industrie.
API/SDK du logiciel principal :
- face++. Face++.com est une plate-forme de services cloud qui fournit gratuitement la détection des visages, la reconnaissance des visages, l'analyse des attributs du visage et d'autres services. Face++ est une nouvelle plate-forme cloud de technologie faciale appartenant à Beijing Megvii Technology Co., Ltd. Dans la compétition des chevaux noirs, Face++ a remporté le championnat annuel et a reçu un investissement Lenovo Star.
- skybiométrie. Il comprend principalement la détection des visages, la reconnaissance des visages et le regroupement des visages.
Principales bibliothèques d'images de reconnaissance faciale :
Les meilleures bibliothèques d'images de visage actuellement divulguées incluent LFW (Labelled Faces in the Wild) et YFW (Youtube Faces in the Wild). L'ensemble de données expérimentales actuel est essentiellement dérivé de LFW et la précision de la reconnaissance faciale des images actuelles a atteint 99 %. Fondamentalement, la base de données d'images existante a été épuisée. Voici un résumé de la base de données d'images faciales existante :

De nos jours, de plus en plus d'entreprises font de la reconnaissance faciale en Chine, et ses applications sont également très larges. Parmi eux, Hanwang Technology détient la part de marché la plus élevée. Les orientations de recherche et la situation actuelle des principales entreprises sont les suivantes :
- Hanwang Technology : Hanwang Technology fait principalement face à l'authentification par reconnaissance, qui est principalement utilisée dans les systèmes de contrôle d'accès, les systèmes de présence, etc.
- iFlytek : iFlytek, avec le soutien de l'équipe du professeur Tang Xiaoou de l'Université chinoise de Hong Kong, a développé une technologie de reconnaissance faciale basée sur le processus gaussien – Gussian face. Le taux de reconnaissance de cette technologie sur LFW est actuellement de 98,52 %. l'entreprise Le taux de reconnaissance de DEEPID2 sur LFW a atteint 99,4%.
- Université du Sichuan Zhisheng : Le point culminant actuel de la recherche de l'entreprise est la reconnaissance faciale 3D, et elle s'est étendue à l'industrialisation des caméras intégrales 3D, etc.
- SenseTime : principalement une entreprise engagée à mener des percées dans la technologie de base de l'"apprentissage profond" de l'intelligence artificielle et à créer des solutions industrielles pour l'intelligence artificielle et l'analyse des mégadonnées. Actuellement, elle est engagée dans la reconnaissance faciale, la reconnaissance de texte, la reconnaissance du corps humain et la reconnaissance des véhicules. , Il a une forte compétitivité dans des domaines tels que la reconnaissance d'objets et le traitement d'images. En reconnaissance faciale, il existe 106 points clés pour la reconnaissance du visage.
Le processus de reconnaissance faciale
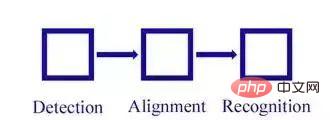
La reconnaissance faciale est principalement divisée en quatre parties : détection de visage, alignement de visage, vérification de visage et identification de visage).
Détection de visage (détection de visage) :
Détectez le visage dans l'image et encadrez le résultat avec un cadre rectangulaire. Dans openCV, il existe un classificateur Harr qui peut être utilisé directement.
Alignement du visage :
Corrigez la posture du visage détecté pour rendre le visage aussi « positif » que possible. La correction peut améliorer la précision de la reconnaissance faciale. Les méthodes de correction incluent la correction 2D et la correction 3D. La méthode de correction 3D peut permettre une meilleure reconnaissance des faces latérales.
Lors de la correction du visage, il y a une étape de détection de l'emplacement des points caractéristiques. Ces emplacements de points caractéristiques sont principalement tels que le côté gauche du nez, le dessous des narines, la position de la pupille, le dessous de la lèvre supérieure. , etc. Une fois que vous connaissez ces caractéristiques. Après avoir cliqué sur la position, effectuez une déformation basée sur la position et le visage peut être "corrigé". Comme le montre l'image ci-dessous :
Voici une technologie développée par MSRA en 2014 : Joint Cascade Face Detection and Alignment (ECCV14). Cet article effectue directement à la fois la détection et l'alignement en 30 ms.
Vérification faciale :
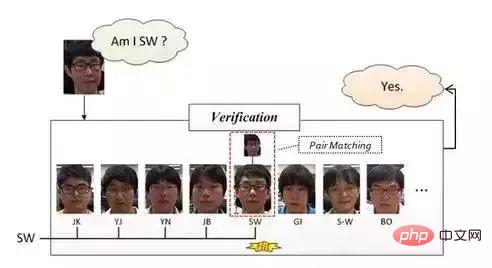
Vérification faciale, la vérification faciale est basée sur la correspondance de paires, donc la réponse qu'elle obtient est "oui" ou "non". Dans l'opération spécifique, une image test est donnée, puis la correspondance par paire est effectuée une par une. Si la correspondance réussit, cela signifie que l'image test et le visage correspondant sont les visages de la même personne.
Cette méthode est (devrait) généralement utilisée dans les systèmes de reconnaissance faciale dans les petits bureaux. La méthode de fonctionnement spécifique est à peu près le processus suivant : saisir les photos du visage des employés une par une hors ligne (un employé en saisit généralement plusieurs). visage) Zhang), une fois que la caméra a capturé l'image lorsque l'employé glisse son visage pour s'enregistrer, il effectue d'abord la détection du visage, puis effectue la correction du visage, puis effectue la vérification du visage comme mentionné ci-dessus. Une fois que le résultat de la correspondance est « oui », cela signifie que la personne dont le visage est scanné appartient à ce bureau, et la vérification du visage est terminée à cette étape.
Lors de la saisie des visages des employés hors ligne, nous pouvons faire correspondre le visage avec le nom de la personne, de sorte qu'une fois la vérification du visage réussie, nous puissions savoir qui est la personne.
L'avantage du système mentionné ci-dessus est qu'il a de faibles coûts de développement et qu'il convient aux petits bureaux. L'inconvénient est qu'il ne peut pas être bloqué lors de la capture, et qu'il nécessite également que la posture du visage soit relativement droite (nous possédons ce système). , mais je n'en ai jamais fait l'expérience). La figure ci-dessous donne une explication schématique :
Identification/reconnaissance faciale :
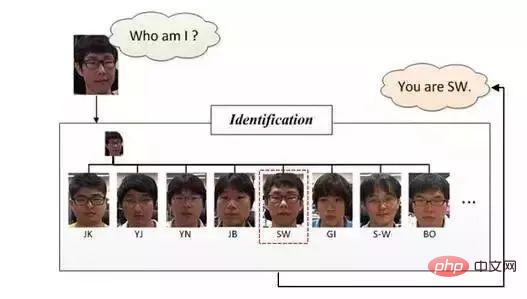
Identification faciale ou Reconnaissance faciale, la reconnaissance faciale est comme le montre la figure ci-dessous, elle veut répondre "Qui suis-je ?", par rapport au correspondance de paires utilisée dans la vérification du visage, elle utilise davantage de méthodes de classification au stade de la reconnaissance. Il classe en fait les images (visages) après avoir effectué les deux étapes précédentes, à savoir la détection des visages et la correction des visages.
Selon l'introduction des quatre concepts ci-dessus, nous pouvons comprendre que la reconnaissance faciale comprend principalement trois grands modules indépendants :
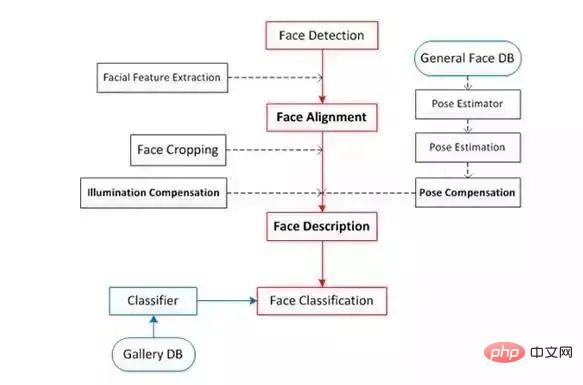
Nous allons diviser les étapes ci-dessus en détail et obtenir le diagramme de processus suivant :
Classification de la reconnaissance faciale
Maintenant, avec le développement de la technologie de reconnaissance faciale, la technologie de reconnaissance faciale est principalement divisée en trois catégories : l'une est la méthode de reconnaissance basée sur l'image et l'autre est la reconnaissance basée sur la vidéo. La troisième méthode est la méthode des trois -méthode de reconnaissance faciale dimensionnelle.
Méthode de reconnaissance basée sur l'image :
Ce processus est un processus de reconnaissance d'image statique, qui utilise principalement le traitement d'image. Les principaux algorithmes incluent PCA, EP, méthode du noyau, Bayesian Framwork, SVM, HMM, Adaboot et d'autres algorithmes. Mais en 2014, la reconnaissance faciale a réalisé des avancées majeures grâce à la technologie d'apprentissage profond, représentée par 97,25 % de deepface et 97,27 % de face++. Cependant, l'ensemble d'entraînement de deep face est de 4 millions d'ensembles, Gussian de Tang Xiaoou. Université chinoise de Hong Kong L'ensemble d'entraînement du visage est de 2w.
Méthode de reconnaissance en temps réel basée sur la vidéo :
Ce processus peut être vu dans le processus de suivi de la reconnaissance faciale, qui nécessite non seulement de trouver la position et la taille du visage dans la vidéo, mais doit également déterminer la correspondance entre différents visages entre les images.
DeepFace
Articles de référence (données) :
1. DeepFace : Combler l'écart par rapport aux performances au niveau humain dans la vérification des visages
2. http://blog.csdn.net/zouxy09/article/details/8781543
3. Blog de dérivation du réseau neuronal convolutif. http://blog.csdn.net/zouxy09/article/details/9993371/
4. Note sur le réseau neuronal à convolution
5. Article de blog sur le réseau neuronal pour la reconnaissance des chiffres manuscrits
6. / blog.csdn.net/Hao_Zhang_Vision/article/details/52831399?locationNum=2&fps=1
DeepFace a été proposé par FaceBook, et DeepID et FaceNet sont apparus plus tard. De plus, DeepFace peut être vu dans DeepID et FaceNet, on peut donc dire que DeepFace est le fondement de CNN en matière de reconnaissance faciale. À l'heure actuelle, l'apprentissage profond a également obtenu de très bons résultats en matière de reconnaissance faciale. Nous commençons donc ici à apprendre de DeepFace.
Dans le processus d'apprentissage de DeepFace, non seulement les méthodes utilisées par DeepFace seront introduites, mais également d'autres algorithmes principaux actuellement utilisés dans cette étape seront introduits pour donner une description simple et complète de la technologie de reconnaissance faciale d'image existante.
Cadre de base de DeepFace
1. Processus de base de reconnaissance faciale
détection de visage -> alignement du visage -> vérification du visage -> identification du visage
2. Détection de visage (détection de visage)
2.1 Technologie existante :
Classificateur de cheveux :
La détection de visage (détection) disposait déjà d'un classificateur de cheveux qui peut être utilisé directement dans opencv, basé sur l'algorithme de Viola-Jones.
Algorithme Adaboost (classificateur en cascade) :
1. Document de référence : Détection de visage robuste en temps réel.
2. Blog chinois de référence : http://blog.csdn.net/cyh_24/article/details/39755661
3 Blog : http://blog.sina.com.cn/s/blog_7769660f01019ep0.html
. 2.2 Méthode utilisée dans l'article
Cet article utilise la méthode de détection de visage basée sur des points de détection (fiducial Point Detector).
- Sélectionnez d'abord 6 points de référence, 2 centres des yeux, 1 point du nez et 3 points sur la bouche.
- Utilisez SVR pour apprendre les points de référence grâce aux fonctionnalités LBP.
L'effet est le suivant :

3. Alignement du visage (alignement du visage)
Alignement 2D :
- Effectuez un recadrage bidimensionnel de l'image après détection, redimensionnez, faites pivoter et traduisez l'image en six emplacements d’ancrage. Découpez la partie du visage.
Alignement 3D :
- Trouvez un modèle 3D et utilisez ce modèle 3D pour recadrer le visage 2D en un visage 3D. 67 points de base, puis triangulation de Delaunay, ajout de triangles au niveau du contour pour éviter les discontinuités.
- Convertissez le visage triangulé en une forme 3D
- Le visage triangulé devient un réseau triangulaire 3D profond
- Déviez le réseau triangulé pour que l'avant du visage soit tourné vers l'avant
- Enfin redressé L'effet du visage humain
est aussi suit :
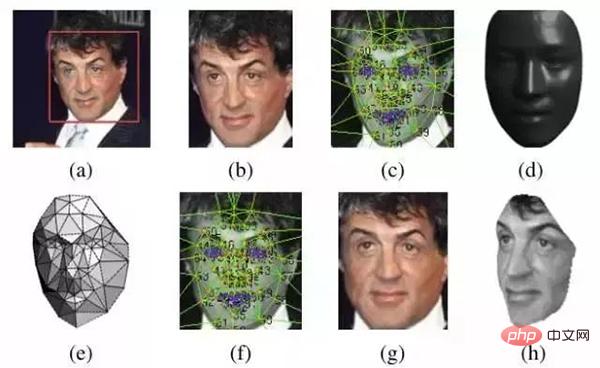
L'alignement 2D ci-dessus correspond à l'image (b), et l'alignement 3D correspond à (c) ~ (h).
4 Vérification faciale (vérification faciale)
4.1 Technologie existante
LBP && Bayésien commun :
Combiné les deux méthodes de LBP de haute dimension et de Bayésien commun.
- Article : Le visage bayésien revisité : une formulation conjointe
Série DeepID :
Fusionner sept modèles bayésiens conjoints à l'aide de SVM, avec une précision de 99,15 %
- Article : Représentation du visage par apprentissage profond par identification-vérification conjointe
4.2 Méthode dans l'article
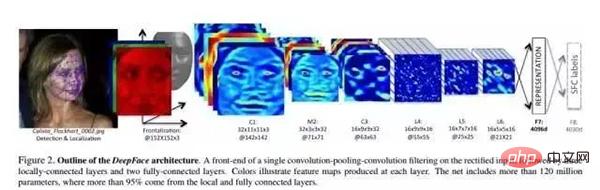
Dans l'article, un réseau de neurones profonds (DNN) est formé via une tâche de reconnaissance faciale multi-classe. La structure du réseau est illustrée dans la figure ci-dessus.
Paramètres structurels :
Après l'alignement 3D, les images formées sont toutes des images 152×152, qui sont entrées dans la structure de réseau ci-dessus. Les paramètres de cette structure sont les suivants :
- Conv : 32 11×11×3. volumes Kernel
- max-pooling : 3×3, stride=2
- Conv : 16 noyaux de convolution 9×9
- Local-Conv : 16 noyaux de convolution 9×9, Local signifie que les paramètres du noyau de convolution ne sont pas partagés
- Local- Conv : 16 noyaux de convolution 7×7, les paramètres ne sont pas partagés
- Local-Conv : 16 noyaux de convolution 5×5, les paramètres ne sont pas partagés
- Entièrement connecté : 4096 Dimension
- Softmax : 4030 dimension
Extrait faible- caractéristiques de niveau :
Le processus est le suivant :
- Étape de pré-traitement : saisissez le visage à 3 canaux, effectuez une correction 3D, puis normalisez à 152 * 152 pixels. Taille : 152 * 152*3.
- Grâce à la convolution couche C1 : C1 contient 32 filtres 11*11*3 (c'est-à-dire le noyau de convolution) et 32 cartes de caractéristiques sont obtenues - 32*142*142*3 .
- Grâce à la couche d'interrogation maximale M2 : la taille de la fenêtre coulissante de M2 est de 3*3, la taille du pas glissant est de 2 et les trois canaux sont interrogés indépendamment.
- Grâce à une autre couche de convolution C3 : C3 contient 16 noyaux de convolution tridimensionnels de 9*9*16.
Le réseau à 3 couches ci-dessus sert à extraire des fonctionnalités de bas niveau, telles que des fonctionnalités de bord simples et des fonctionnalités de texture. La couche Max-polling rend le réseau convolutionnel plus robuste aux transformations locales. Si l'entrée est une face corrigée, cela rend le réseau plus robuste aux petites erreurs d'étiquetage.
Cependant, une telle couche d'interrogation fera perdre au réseau certaines informations sur la structure détaillée du visage et l'emplacement précis de minuscules textures. Par conséquent, le papier ajoute uniquement la couche Max-polling après la première couche convolutive. Ces couches précédentes sont appelées niveaux de prétraitement adaptatif frontal. Cependant, pour de nombreux calculs où cela est nécessaire, ces couches ont très peu de paramètres. Ils étendent simplement l’image d’entrée en un simple ensemble de fonctionnalités locales.
Couches suivantes :
L4, L5 et L6 sont toutes des couches connectées localement. Tout comme la couche convolutionnelle utilise des filtres, un ensemble différent de filtres est formé et appris à chaque position de l'image caractéristique. Étant donné que différentes régions ont des propriétés statistiques différentes après correction, l'hypothèse de stabilité spatiale du réseau convolutif ne peut pas être établie.
Par exemple, comparée à la zone située entre le nez et la bouche, la zone située entre les yeux et les sourcils présente un aspect très différent et est très différenciée. En d’autres termes, en utilisant l’image rectifiée d’entrée, la structure du DNN est personnalisée.
L'utilisation de couches de connexion locales n'affecte pas la charge de calcul lors de l'extraction des fonctionnalités, mais elle affecte le nombre de paramètres de formation. Simplement parce qu’il existe une très grande bibliothèque de faces étiquetées, nous pouvons nous permettre trois grandes couches connectées localement. L'unité de sortie de la couche de connexion locale est affectée par un grand patch d'entrée, et l'utilisation (paramètres) de la couche de connexion locale peut être ajustée en conséquence (aucun poids n'est partagé)
Par exemple, la sortie de la couche L6 est affectée par un effet 74*74*3 du patch d'entrée, dans le visage corrigé, il est difficile d'avoir un partage statistique de paramètres entre des patchs aussi grands.
Couche supérieure :
Enfin, les deux couches supérieures du réseau (F7, F8) sont entièrement connectées : chaque unité de sortie est connectée à toutes les entrées. Ces deux couches peuvent capturer la corrélation entre les caractéristiques des régions distantes de l’image du visage. Par exemple, la corrélation entre la position et la forme des yeux et la position et la forme de la bouche (cette partie contient également des informations) peut être obtenue à partir de ces deux couches. La sortie de la première couche F7 entièrement connectée est notre vecteur d’expression original des traits du visage.
En termes d'expression de fonctionnalités, ce vecteur de fonctionnalités est très différent de la description de fonctionnalités traditionnelle basée sur LBP. Les méthodes traditionnelles utilisent généralement des descriptions de caractéristiques locales (histogrammes de calcul) et servent d'entrée au classificateur.
La sortie de la dernière couche F8 entièrement connectée entre dans un softmax K-way (K est le nombre de catégories), qui génère une distribution de probabilité des étiquettes de catégorie. Soit Ok représente la k-ème sortie d'une image d'entrée après son passage dans le réseau, c'est-à-dire que la probabilité de l'étiquette de classe de sortie k peut être exprimée par la formule suivante :
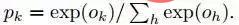
Le but de la formation est de maximiser la probabilité de la catégorie de sortie correcte (l'identifiant du visage). Ceci est réalisé en minimisant la perte d'entropie croisée pour chaque échantillon d'apprentissage. Soit k représente l'étiquette de la catégorie correcte de l'entrée donnée, alors la perte d'entropie croisée est :
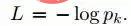
La perte d'entropie croisée est minimisée en calculant le gradient de la perte d'entropie croisée L sur les paramètres et en utilisant la méthode de diminution du gradient stochastique.
Le dégradé est calculé par rétropropagation standard de l'erreur. Il est intéressant de noter que les fonctionnalités produites par ce réseau sont très rares. Plus de 75 % des éléments de fonctionnalité de niveau supérieur sont nuls. Ceci est principalement dû à l’utilisation de la fonction d’activation ReLU. Cette fonction non linéaire à seuil souple est utilisée dans toutes les couches convolutives, les couches connectées localement et les couches entièrement connectées (à l'exception de la dernière couche F8), ce qui entraîne des caractéristiques hautement non linéaires et clairsemées après la cascade globale.
La parcimonie est également liée à l'utilisation de la régularisation des abandons, qui définit les éléments de fonctionnalités aléatoires à 0 pendant l'entraînement. Nous n'avons utilisé l'abandon que dans la couche F7 entièrement connectée. En raison du vaste ensemble de formation, nous n'avons pas trouvé de surapprentissage significatif pendant le processus de formation.
Étant donné l'image I, son expression caractéristique G(I) est calculée via le réseau feedforward de chaque couche L peut être considérée comme une série de fonctions :

Normalisation :
Au dernier niveau. , nous normalisons les éléments de la fonctionnalité entre 0 et 1 pour réduire la sensibilité de la fonctionnalité aux changements d'éclairage. Chaque élément du vecteur de caractéristiques est divisé par la valeur maximale correspondante dans l'ensemble d'apprentissage. Effectuez ensuite la normalisation L2. Puisque nous utilisons la fonction d'activation ReLU, notre système est moins invariant à l'échelle de l'image.
Pour le vecteur de sortie 4096-d :
- Normalisez d'abord chaque dimension, c'est-à-dire que pour chaque dimension du vecteur de résultat, elle doit être divisée par la valeur maximale de la dimension dans l'ensemble de l'entraînement.
- Chaque vecteur est normalisé L2.
2. Vérification
2.1 Distance du chi carré
Dans ce système, le vecteur de caractéristiques DeepFace normalisé présente les similitudes suivantes avec les caractéristiques traditionnelles basées sur l'histogramme (telles que LBP) :
- Toutes les valeurs sont égales. négatif
- très clairsemé
- Les valeurs des éléments caractéristiques sont toutes comprises entre l'intervalle [0, 1]
La formule de calcul de la distance du chi carré est la suivante :
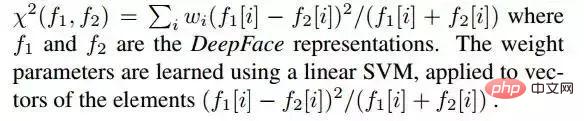
2.2 Réseau siamois
Le L'article mentionne également la méthode d'apprentissage métrique de bout en bout, une fois l'apprentissage (formation) terminé, le réseau de reconnaissance faciale (jusqu'à F7) est réutilisé sur les deux images d'entrée, et les deux vecteurs de caractéristiques obtenus sont directement utilisés pour prédire si les deux images d'entrée appartiennent au même personnel. Ceci est divisé en les étapes suivantes :
a. Calculer la différence absolue entre deux entités
b, une couche entièrement connectée, mappée sur une seule unité logique (sortie identique/différente).
3. Évaluation expérimentale
3.1 Ensemble de données
- Social Face Classification Dataset (SFC) : 4,4 millions de visages/4030 personnes
- LFW : 13323 visages/5749 personnes
- restreint : uniquement des marqueurs oui/non
- sans restriction : d'autres paires d'entraînement peuvent également être suivies Pour
- non supervisé : Pas de formation sur LFW
- Youtube Face (YTF) : 3425vidéos/1595 personnes
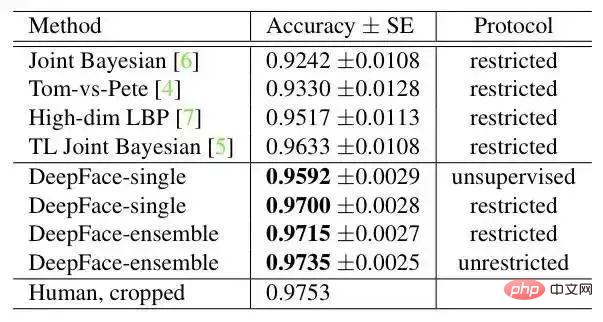
résultat sur LFW :
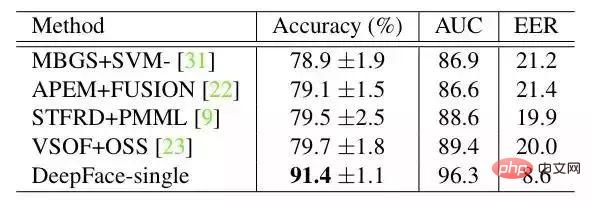
résultat sur YTF :
DeepFace et la méthode suivante la plus grande La différence est que DeepFace utilise une méthode d’alignement avant d’entraîner le réseau neuronal. L'article estime que la raison pour laquelle les réseaux neuronaux peuvent fonctionner est qu'une fois le visage aligné, les caractéristiques de la zone du visage sont fixées sur certains pixels. À ce stade, le réseau neuronal convolutif peut être utilisé pour apprendre les caractéristiques.
Le modèle présenté dans cet article utilise la dernière méthode de reconnaissance faciale basée sur l'apprentissage profond dans la boîte à outils C++ dlib. Basé sur le niveau de référence de la bibliothèque de tests de données de visages extérieurs Labeled Faces in the Wild, il atteint une précision de 99,38 %.
Plus d'algorithmes
http://www.gycc.com/trends/face%20recognition/overview/
dlib : http://dlib.net/Bibliothèque de tests de données Visages étiquetés dans la nature : http://vis-www.cs.umass.edu/lfw/
Le modèle fournit un outil de ligne de commande simple face_recognition qui permet aux utilisateurs d'utiliser directement des dossiers d'images pour les opérations de reconnaissance faciale via des commandes.
Capturez les traits du visage en images
Capturez tous les visages en une seule image
Recherchez et traitez les caractéristiques des visages en images
Trouvez la position et le contour des yeux, du nez, de la bouche et du menton de chaque personne.
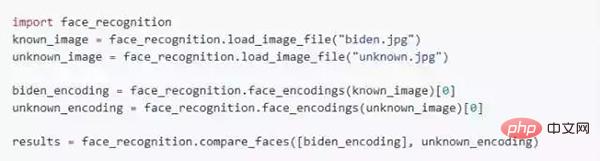
import face_recognition
image = face_recognition.load_image_file("your_file.jpg")
face_locations = face_recognition.face_locations(image)
Capturer les traits du visage a un objectif très important, et bien sûr, il peut également être utilisé pour la beauté numérique d'images Maquillage numérique du visage (comme Meitu Xiuxiu)
maquillage numérique : https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py
Reconnaître les visages sur les images
Identifier qui apparaît sur la photo
Étapes d'installation
Cette méthode prend en charge Python3/python2 Nous l'avons testée uniquement sous macOS et Linux. Nous ne savons pas si elle est applicable à Windows.
Installez ce module en utilisant pip3 de pypi (ou pip2 de Python 2)
Remarque importante : il peut y avoir des problèmes lors de la compilation du dlib. Vous pouvez corriger l'erreur en installant le dlib à partir des sources (pas de pip), voir le manuel d'installation. Comment faire. installez dlib à partir des sources
https://gist.github.com/ageitgey/629d75c1baac34dfa5ca2a1928a7aeaf
Terminez l'installation en installant manuellement dlib et en exécutant pip3 install face_recognition.
Comment utiliser l'interface de ligne de commande
Lorsque vous installez face_recognition, vous pouvez obtenir un simple programme de ligne de commande appelé face_recognition, qui peut vous aider à reconnaître une photo ou tous les visages d'un dossier de photos.
Tout d'abord, vous devez fournir un dossier contenant une photo, et vous savez déjà qui est la personne sur la photo. Chaque personne doit avoir un fichier photo, et le nom du fichier doit porter le nom de cette personne.
Ensuite, vous devez fournir un dossier contenant une photo. vous devez préparer un autre dossier contenant les photos sur lesquelles vous souhaitez reconnaître les visages ;
Ensuite, il vous suffit d'exécuter la commande face_recognition, et le programme peut identifier la personne dans les photos de visages inconnus via le dossier des visages connus
 ;
;
Une ligne de sortie est requise pour chaque visage. Les données sont le nom du fichier plus le nom de la personne reconnue, séparés par des virgules.
Si vous souhaitez simplement connaître le nom de chaque personne sur la photo sans le nom du fichier, vous pouvez procéder comme suit :

Module Python
Vous pouvez terminer l'opération de reconnaissance faciale en introduisant face_recognition :
API documentation : https://face-recognition.readthedocs.io.
Reconnaître automatiquement tous les visages dans les images
Veuillez vous référer à cet exemple : https://github.com/ageitgey/face_recognition/blob/master/examples/ find_faces_in_picture. py
Reconnaître les visages sur les images et donner des noms
Veuillez vous référer à cet exemple : https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.py
Cas du code Python
Tous les exemples sont dans Ceci est ici.
https://github.com/ageitgey/face_recognition/tree/master/examples
·Trouver des visages sur une photo
https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py · 识别照片中的面部特征Identify specific facial features in a photograph https://github.com/ageitgey/face_recognition/blob/master/examples/find_facial_features_in_picture.py · 使用数字美颜Apply (horribly ugly) digital make-up https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py ·基于已知人名找到并识别出照片中的未知人脸Find and recognize unknown faces in a photograph based on photographs of known people https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.pypython人脸
D'accord, aujourd'hui, c'est tout pour le partage~
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!