
Maison >développement back-end >Tutoriel Python >Tests automatisés : plusieurs modèles de programmation courants en Python
Tests automatisés : plusieurs modèles de programmation courants en Python

- 王林avant
- 2023-04-13 21:04:012968parcourir

Ce chapitre met à jour le contenu lié aux "Spécifications de la syntaxe et types de données Python", principalement pour permettre à chacun de comprendre quels types de modes de programmation Python possède, de maîtriser la syntaxe de base de Python et de savoir comment afficher et les bases de la commande. Paramètres de ligne.Application, après avoir compris les types de données de Python, vous pouvez effectuer plus d'opérations connexes.
Modèles de programmation courants
①Programmation de commandes interactives Python.
②Programmation de scripts Python.
③Traitement de l'encodage chinois.
1. Mode de programmation de commandes interactives
Le mode de programmation de commandes interactives est un mode d'exécution de lecture ligne par ligne typique.
Lorsque le programme ne comporte qu'une seule ligne ou moins, ce mode de programmation est une méthode d'application typique.
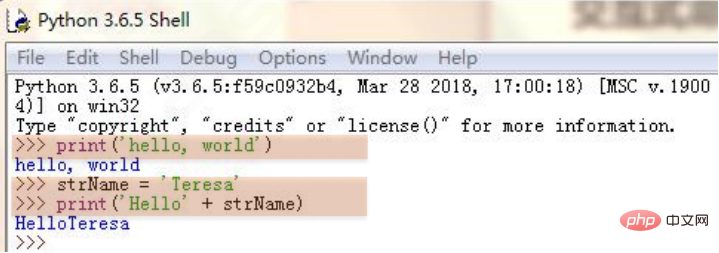
La figure ci-dessous utilise l'éditeur PythonIDLE pour la programmation, et le mode de programmation de cet éditeur est un symbole d'encodage de commande interactif typique.
>>> est l'invite pour saisir des commandes interactives. Chaque fois que vous appuyez sur Entrée après la saisie, la commande sera exécutée par l'analyseur Python.
2. Mode de programmation de script
Lorsque nous devons écrire des sections de code plus complexes ou plus volumineuses, la programmation impérative n'est pas assez pratique.
Par conséquent, Python propose un mode de programmation de script. Vous pouvez créer un fichier de script avec le suffixe *.py et écrire une grande quantité de code dans le fichier, ce qui facilite la maintenance et la mise à jour du code. Vous pouvez ensuite utiliser des commandes interactives ou des outils IDE pour l'exécuter.
3. Programmation de caractères
String est un type de données. Cependant, il existe un problème d’encodage particulier avec les chaînes.
Étant donné que les ordinateurs ne peuvent traiter que des nombres, si vous souhaitez traiter du texte, vous devez d'abord convertir le texte en nombres avant le traitement.
Supplément : Historique du développement du codage de caractères
Les premiers ordinateurs ont été conçus en utilisant 8 bits comme octet. Par conséquent, le plus grand entier pouvant être représenté par un octet est 255 (binaire 11111111 = décimal 255), si vous le souhaitez. pour représenter un entier plus grand, vous devez utiliser plus d'octets. Par exemple, l'entier maximum pouvant être représenté par deux octets est 65 535 et l'entier maximum pouvant être représenté par 4 octets est 4 294 967 295.
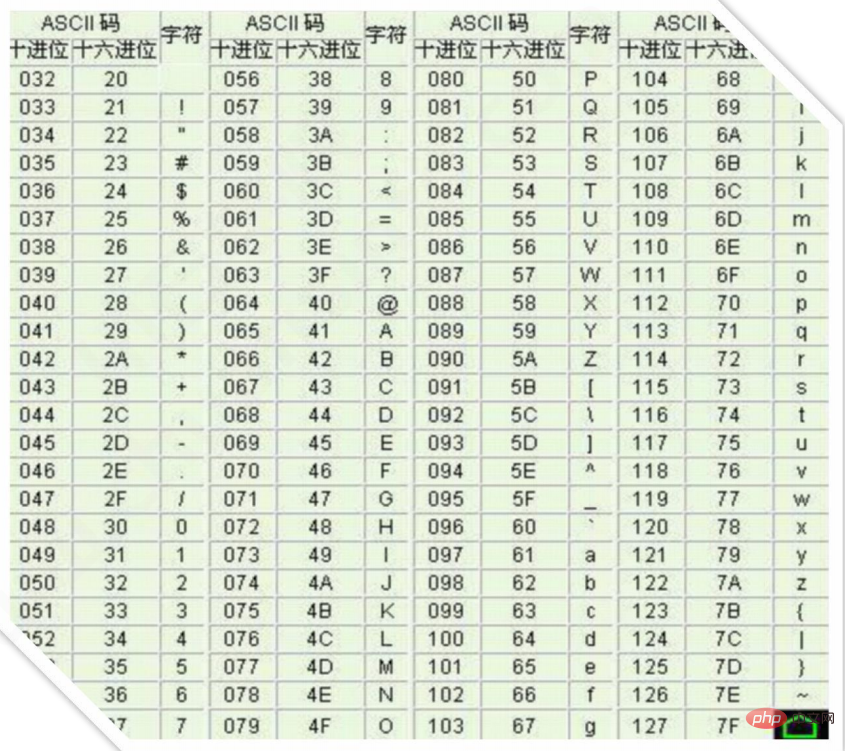
Depuis que l'ordinateur a été inventé par les Américains, seuls 127 caractères ont été initialement codés dans l'ordinateur, qui sont des lettres anglaises majuscules et minuscules, des chiffres et certains symboles. Cette table de codage est appelée codage ASCII, comme le codage de la lettre majuscule A. . est 65 et le codage de la lettre minuscule z est 122.
Extension : jeu de caractères unicode
La raison pour laquelle Python3 peut bien résoudre le problème des caractères chinois tronqués est qu'il encode toutes les chaînes en Unicode.
Quantity Unicode unifie toutes les langues en un seul ensemble de codes, il n'y aura donc pas de caractères tronqués.
Quantity Unicode est également en constante évolution, mais le plus couramment utilisé est d'utiliser deux octets pour représenter un caractère (si vous rencontrez un caractère très rare, vous avez besoin de 4 octets). La plupart des systèmes d'exploitation et la plupart des langages de programmation que nous voyons prennent désormais en charge l'Unicode.
L'encodage ASCII est de 1 octet, tandis que l'encodage Unicode est généralement de 2 octets.
Extension : jeu de caractères UTF-8
Un nouveau problème surgit : S'il est unifié en codage Unicode, le problème de code tronqué disparaîtra. Cependant, si le texte que vous écrivez est essentiellement entièrement en anglais, le codage Unicode nécessite deux fois plus d'espace de stockage que le codage ASCII, ce qui est très peu économique en termes de stockage et de transmission.
La naissance de la solution : L'encodage UTF-8 qui convertit l'encodage Unicode en "encodage à longueur variable" est réapparu.
● L'encodage UTF-8 encode un caractère Unicode en 1 à 6 octets selon différentes tailles de nombres. Les lettres anglaises couramment utilisées sont codées en 1 octet, les caractères chinois font généralement 3 octets et seuls de très rares caractères sont codés. en 4 à 6 octets.
Quantity Si le texte que vous souhaitez transmettre contient un grand nombre de caractères anglais, l'utilisation de l'encodage UTF-8 peut économiser de l'espace.
Quantity L'encodage UTF-8 présente un avantage supplémentaire, c'est-à-dire que l'encodage ASCII peut en fait être considéré comme faisant partie de l'encodage UTF-8. Par conséquent, un grand nombre d'anciens logiciels qui ne prennent en charge que l'encodage ASCII peuvent continuer à fonctionner sous UTF-8. 8 encodage.
Remarque : Le codage Unicode est utilisé uniformément dans la mémoire de l'ordinateur.
Codage des caractères Python3
Dans la version Python3, les chaînes sont codées en Unicode, ce qui signifie que les chaînes Python prennent en charge plusieurs langues.
Pour l'encodage d'un seul caractère, Python fournit la fonction ord() pour obtenir la représentation entière décimale d'un seul caractère, et la fonction chr() convertit l'encodage en caractère correspondant.
Exemple :
>>> ord(‘A’) 65 >>> ord(‘中’) 20013 >>> chr(66) ‘B’ >>> chr(25991) ‘文’
Le code source Python est également un fichier texte, donc lorsque votre code source contient du chinois, vous devez spécifier l'encodage UTF-8 lors de l'enregistrement du code source. Lorsque l'interpréteur Python lit le code source, pour qu'il soit lu en encodage UTF-8, nous écrivons généralement cette ligne au début du fichier.
#-*- coding:utf-8 *-
Le commentaire est de dire à l'interpréteur Python de lire le code source selon l'encodage UTF-8, sinon la sortie chinoise que vous écrivez dans le code source risque d'être tronquée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!