
Maison >Périphériques technologiques >IA >Cette méthode de formation clairsemée pour les grands modèles avec une grande précision et une faible consommation de ressources a été trouvée.
Cette méthode de formation clairsemée pour les grands modèles avec une grande précision et une faible consommation de ressources a été trouvée.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-13 19:01:011501parcourir
Récemment, l'article d'Alibaba Cloud Machine Learning PAI « Parameter-Efficient Sparsity for Large Language Models Fine-Tuning » sur la formation éparse de grands modèles a été accepté par l'IJCAI 2022, la plus grande conférence sur l'intelligence artificielle.
L'article propose un algorithme d'entraînement clairsemé efficace en termes de paramètres PST En analysant l'indice d'importance des poids, il est conclu qu'il présente deux caractéristiques : un rang et une structure faibles. Sur la base de cette conclusion, l'algorithme PST introduit deux ensembles de petites matrices pour calculer l'importance des poids. Par rapport au besoin initial d'une matrice aussi grande que le poids pour enregistrer et mettre à jour l'indice d'importance, la quantité de paramètres qui doivent être. mis à jour pour une formation clairsemée est considérablement réduit. Comparé aux algorithmes d'entraînement clairsemés couramment utilisés, l'algorithme PST peut atteindre une précision de modèle clairsemée similaire tout en ne mettant à jour que 1,5 % des paramètres.
Contexte
Ces dernières années, les grandes entreprises et les instituts de recherche ont proposé une variété de grands modèles. Les paramètres de ces grands modèles vont de dizaines de milliards à des milliards, et même des dizaines de milliards sont déjà apparus. modèle. Ces modèles nécessitent une grande quantité de ressources matérielles pour être formés et déployés, ce qui les rend difficiles à mettre en œuvre. Par conséquent, comment réduire les ressources nécessaires à la formation et au déploiement de grands modèles est devenu un problème urgent.
La technologie de compression de modèle peut réduire efficacement les ressources requises pour le déploiement du modèle. En supprimant certains poids, les calculs du modèle peuvent être convertis de calculs denses en calculs clairsemés, réduisant ainsi l'utilisation de la mémoire et accélérant les calculs. Dans le même temps, par rapport à d'autres méthodes de compression de modèle (élagage/quantification structuré), la parcimonie peut atteindre un taux de compression plus élevé tout en garantissant la précision du modèle, et est plus adaptée aux grands modèles avec un grand nombre de paramètres.
Challenge
Les méthodes d'entraînement clairsemées existantes peuvent être divisées en deux catégories, l'une est l'algorithme clairsemé sans données basé sur le poids ; l'autre est l'algorithme clairsemé basé sur les données. L'algorithme clairsemé basé sur le poids est illustré dans la figure ci-dessous, comme l'élagage de magnitude [1], qui évalue l'importance du poids en calculant la norme L1 du poids, et génère le résultat clairsemé correspondant sur cette base. L'algorithme clairsemé basé sur le poids est efficace dans le calcul et ne nécessite pas la participation de données d'entraînement, mais l'indice d'importance calculé n'est pas suffisamment précis, affectant ainsi la précision du modèle clairsemé final.
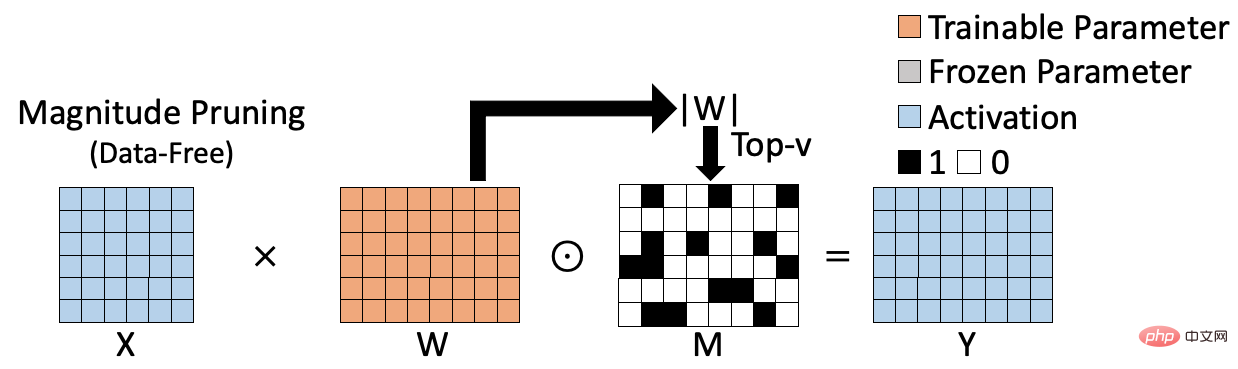
L'algorithme clairsemé basé sur des données est présenté dans la figure ci-dessous, comme l'élagage de mouvement[2], qui calcule le produit du poids et le gradient correspondant comme indicateur pour mesurer l'importance du poids. Ce type de méthode prend en compte le rôle des poids sur des ensembles de données spécifiques et peut donc évaluer plus précisément l'importance des poids. Cependant, en raison de la nécessité de calculer et de sauvegarder l'importance de chaque poids, ce type de méthode nécessite souvent un espace supplémentaire pour stocker l'indice d'importance (S sur la figure). Dans le même temps, par rapport aux méthodes clairsemées basées sur la pondération, le processus de calcul est souvent plus complexe. Ces défauts deviennent plus évidents à mesure que la taille du modèle augmente.
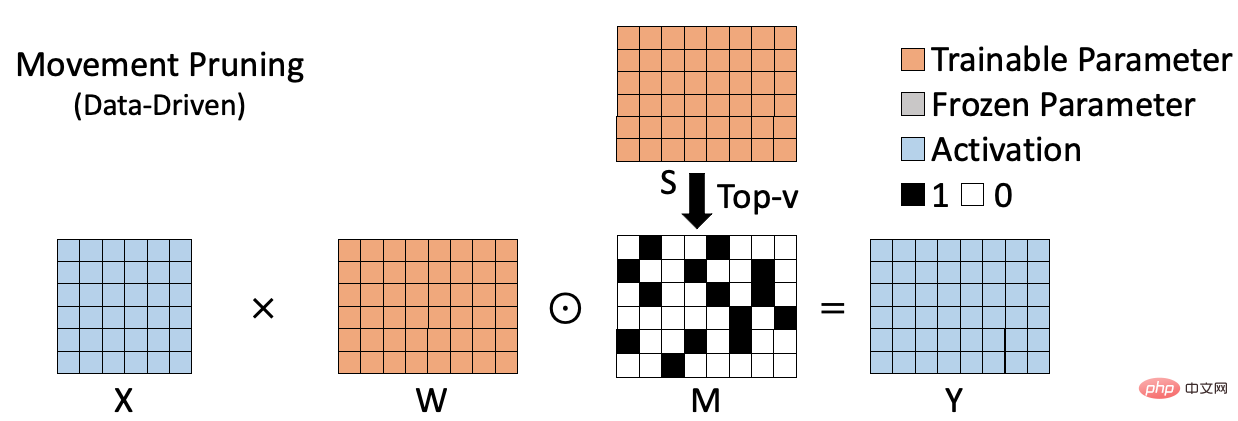
Pour résumer, les algorithmes clairsemés précédents sont soit efficaces mais pas assez précis (algorithme basé sur le poids), soit précis mais pas assez efficaces (algorithme basé sur les données). Par conséquent, nous espérons proposer un algorithme clairsemé efficace capable d’effectuer avec précision et efficacité une formation clairsemée sur de grands modèles.
Break
Le problème avec les algorithmes clairsemés basés sur des données est qu'ils introduisent généralement des paramètres supplémentaires de la même taille que les poids pour connaître l'importance des poids, ce qui nous fait commencer à réfléchir à la manière de réduire les paramètres supplémentaires introduits. pour calculer l'importance des poids sexe. Tout d'abord, afin de maximiser l'utilisation des informations existantes pour calculer l'importance des poids, nous concevons l'indice d'importance des poids comme la formule suivante :
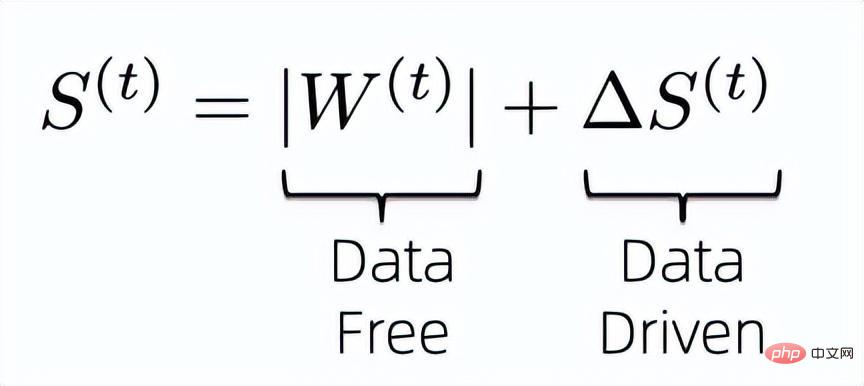
C'est-à-dire que nous combinons les données sans données et sans données. indicateurs pilotés pour déterminer conjointement l’importance des pondérations finales du modèle. On sait que l'indice d'importance sans données précédent ne nécessite pas de paramètres supplémentaires à enregistrer et est efficace dans le calcul, nous devons donc résoudre comment compresser les paramètres de formation supplémentaires introduits par l'indice d'importance basé sur les données ultérieur.
Basé sur l'algorithme clairsemé précédent, l'indice d'importance basé sur les données peut être conçu comme

, on commence donc à analyser la redondance de l'indicateur d'importance calculé par cette formule. Tout d’abord, sur la base de travaux antérieurs, il est connu que les poids et les gradients correspondants ont des propriétés évidentes de bas rang [3, 4], nous pouvons donc en déduire que l’indice d’importance a également des propriétés de bas rang, nous pouvons donc introduire deux propriétés de bas rang Une petite matrice pour représenter la matrice d'indicateurs d'importance d'origine qui est aussi grande que les pondérations.
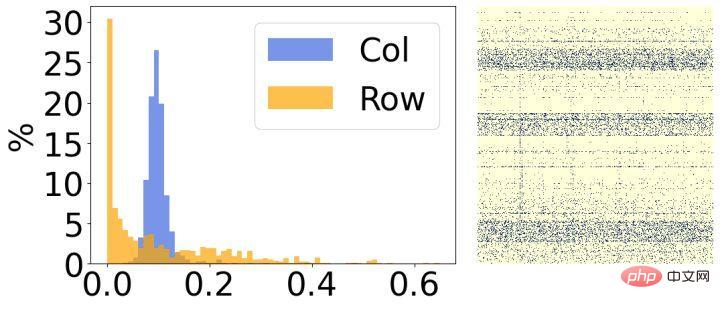
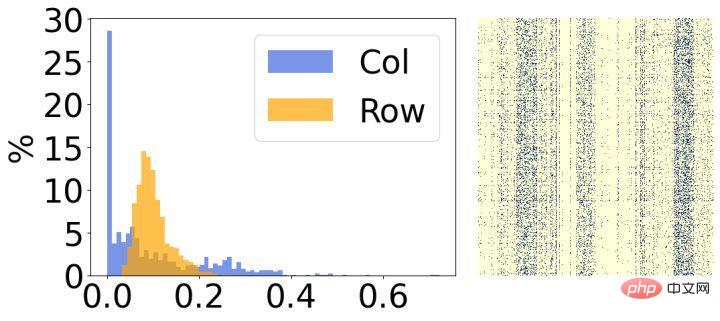
Deuxièmement, nous avons analysé les résultats après la rareté du modèle et avons constaté qu'ils présentaient des caractéristiques structurelles évidentes. Comme le montre la figure ci-dessus, le côté droit de chaque image est le résultat de visualisation du poids clairsemé final, et le côté gauche est un histogramme qui compte le taux de parcimonie correspondant de chaque ligne/colonne. On peut voir que la plupart des poids dans 30 % des lignes de l’image de gauche ont été supprimés, et inversement, la plupart des poids dans 30 % des colonnes de l’image de droite ont été supprimés. Sur la base de ce phénomène, nous introduisons deux petites matrices structurées pour évaluer l'importance de chaque ligne/colonne de poids.
Sur la base de l'analyse ci-dessus, nous avons constaté que l'indice d'importance basé sur les données a un rang et une structure faibles, nous pouvons donc le convertir dans la représentation suivante :
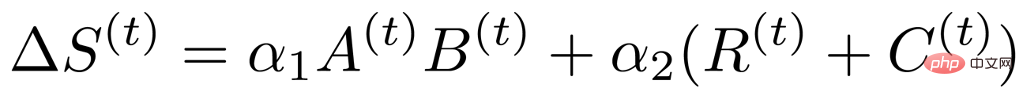
où A et B représentent un rang faible, R et C représentent les propriétés structurelles. Grâce à une telle analyse, la matrice de l'indice d'importance, qui était à l'origine aussi grande que le poids, a été décomposée en quatre petites matrices, réduisant ainsi considérablement les paramètres d'entraînement impliqués dans un entraînement clairsemé. Dans le même temps, afin de réduire davantage les paramètres d'entraînement, nous avons décomposé la mise à jour du poids en deux petites matrices U et V basées sur la méthode précédente, de sorte que la formule finale de l'indice d'importance devient la forme suivante :
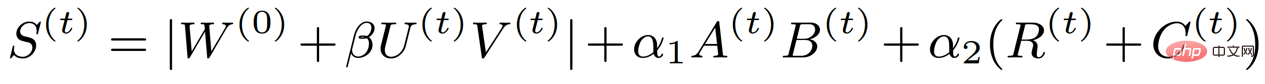
Correspondant algorithme Le diagramme du cadre est le suivant :
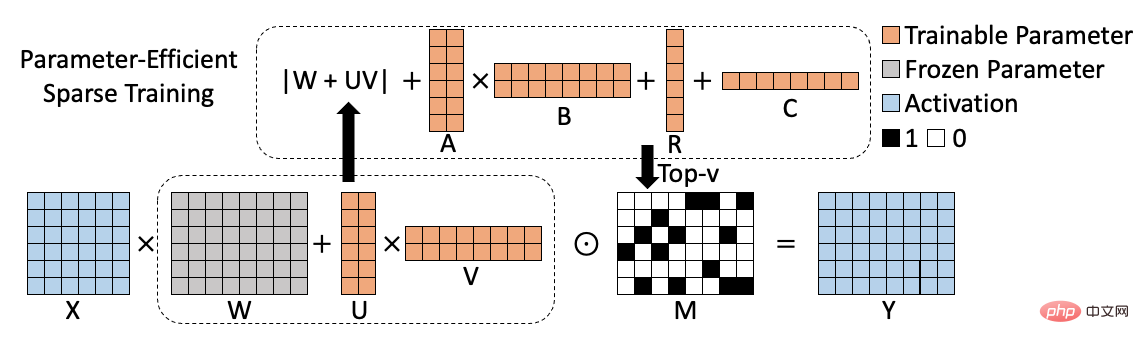
Les résultats expérimentaux finaux de l'algorithme PST sont les suivants. Nous le comparons avec l'élagage de magnitude et l'élagage de mouvement sur les tâches NLU (BERT, RoBERTa) et NLG (GPT-2). À 90 % sous le taux de parcimonie, PST peut atteindre une précision de modèle comparable à l'algorithme précédent sur la plupart des ensembles de données, mais ne nécessite que 1,5 % des paramètres d'entraînement.
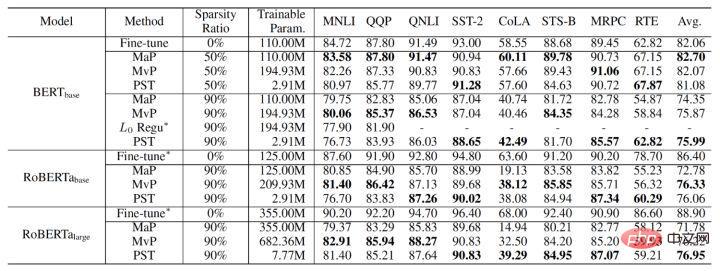

La technologie PST a été intégrée à la bibliothèque de compression de modèles d'Alibaba Cloud Machine Learning PAI et à la fonction de formation clairsemée de grands modèles de la plateforme Alicemind. Il a permis d'accélérer les performances de l'utilisation de grands modèles au sein du groupe Alibaba. Sur les dizaines de milliards de PLUG de grands modèles, PST peut accélérer 2,5 fois sans réduire la précision du modèle et réduire l'utilisation de la mémoire de 10 fois par rapport à la formation éparse d'origine. À l'heure actuelle, Alibaba Cloud Machine Learning PAI est largement utilisé dans diverses industries, fournissant des services de développement d'IA à liaison complète, réalisant des solutions d'IA indépendantes et contrôlables pour les entreprises et améliorant considérablement l'efficacité de l'ingénierie d'apprentissage automatique.
Nom de l'article : Sparsity efficace des paramètres pour le réglage fin des grands modèles linguistiques
Auteurs de l'article : Yuchao Li , Fuli Luo , Chuanqi Tan , Mengdi Wang , Songfang Huang , Shen Li , Junjie Bai
Paper Lien PDF :https://arxiv.org/pdf/2205.11005.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI