
Maison >Problème commun >Introduction à OpenAI et Microsoft Sentinel
Introduction à OpenAI et Microsoft Sentinel

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-13 12:07:111834parcourir
Bienvenue dans notre série sur OpenAI et Microsoft Sentinel ! Les grands modèles de langage, ou LLM, tels que la famille GPT3 d'OpenAI, envahissent l'imagination du public avec des cas d'utilisation innovants tels que le résumé de texte, les conversations de type humain, l'analyse et le débogage de code, et bien d'autres exemples. Nous avons vu ChatGPT écrire des scénarios et des poèmes, composer de la musique, rédiger des essais et même traduire du code informatique d'une langue à une autre.
Et si nous pouvions exploiter cet incroyable potentiel pour aider les intervenants dans les centres d'opérations de sécurité ? Eh bien, bien sûr que nous pouvons – et c’est facile ! Microsoft Sentinel inclut déjà un connecteur intégré pour les modèles OpenAI GPT3 que nous pouvons implémenter dans nos playbooks d'automatisation optimisés par Azure Logic Apps. Ces flux de travail puissants sont faciles à écrire et à intégrer dans les opérations SOC. Aujourd'hui, nous allons examiner le connecteur OpenAI et explorer certains de ses paramètres configurables à l'aide d'un cas d'utilisation simple : décrire une politique MITRE ATT&CK liée aux événements Sentinel.
Avant de commencer, abordons quelques prérequis :
- Si vous n'avez pas encore d'instance Microsoft Sentinel, vous pouvez en créer une à l'aide de votre compte Azure gratuit et suivre le guide de démarrage rapide Mise en route avec Sentinel.
- Nous utiliserons les données préenregistrées du Microsoft Sentinel Training Lab pour tester notre playbook.
- Vous aurez également besoin d'un compte OpenAI personnel avec une clé API pour la connexion GPT3.
- Je recommande également fortement de consulter l'excellent blog d'Antonio Formato sur la gestion des événements avec ChatGPT et Sentinel, où Antonio présente un manuel polyvalent très utile qui est devenu la référence pour presque toutes les implémentations de modèles OpenAI dans Sentinel à ce jour.
Nous commencerons par un playbook de base de déclenchement d'incident (Sentinel > Automatisation > Créer > Playbook avec déclencheur d'incident).
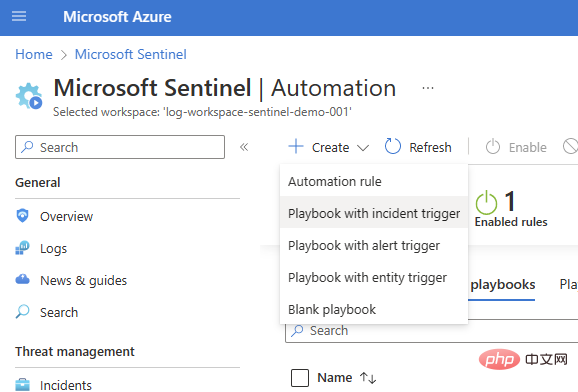
Sélectionnez votre abonnement et votre groupe de ressources, ajoutez un nom de script et accédez à l'onglet Connexions. Vous devriez voir Microsoft Sentinel avec une ou deux options d'authentification - j'utilise Managed Identity dans cet exemple - mais si vous n'avez pas encore de connexion, vous pouvez également ajouter une connexion Sentinel dans Logic Apps Designer .
Affichez et créez le playbook, après quelques secondes, la ressource sera déployée avec succès et nous amènera au canevas Logic App Designer :
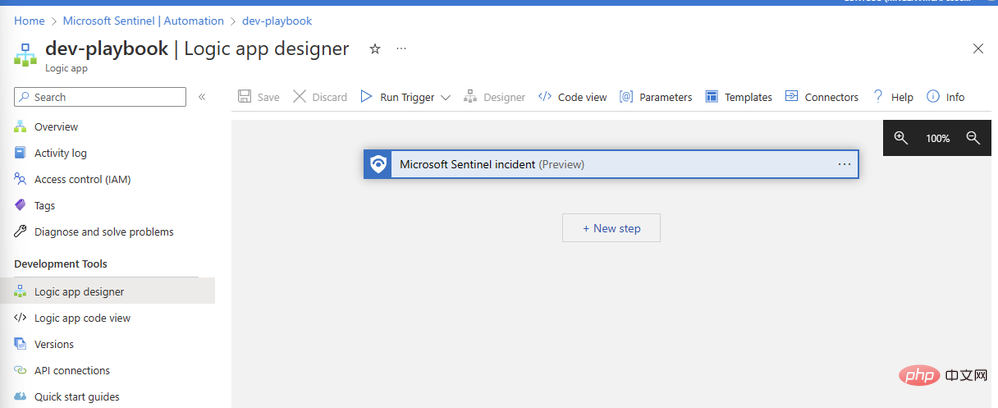
Ajoutons notre connecteur OpenAI. Cliquez sur Nouvelle étape et tapez « OpenAI » dans la zone de recherche. Vous verrez le connecteur dans le volet supérieur et deux actions en dessous : "Créer une image" et "GPT3 Complétez votre astuce" :
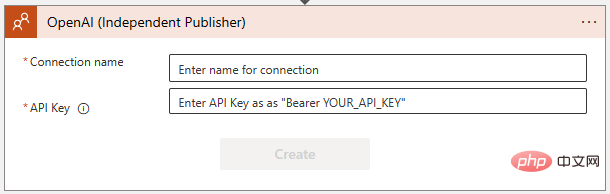
Sélectionnez "GPT3 Complétez votre astuce". Il vous sera ensuite demandé de créer une connexion à l'API OpenAI dans la boîte de dialogue suivante. Si vous ne l'avez pas déjà fait, créez une clé sur https://platform.openai.com/account/api-keys et assurez-vous de la conserver dans un endroit sûr !
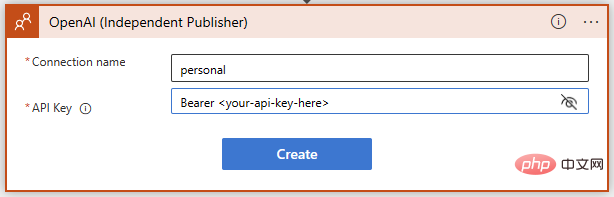
Assurez-vous de suivre exactement les instructions lors de l'ajout de la clé API OpenAI - cela nécessite le mot "Bearer", suivi d'un espace, puis de la clé elle-même :
Succès ! Nous avons maintenant la complétion du texte GPT3 prête pour notre invite. Nous voulons que le modèle d'IA interprète les stratégies et techniques de MITRE ATT&CK liées aux événements Sentinel, écrivons donc une invite simple utilisant du contenu dynamique pour insérer les stratégies d'événements de Sentinel.
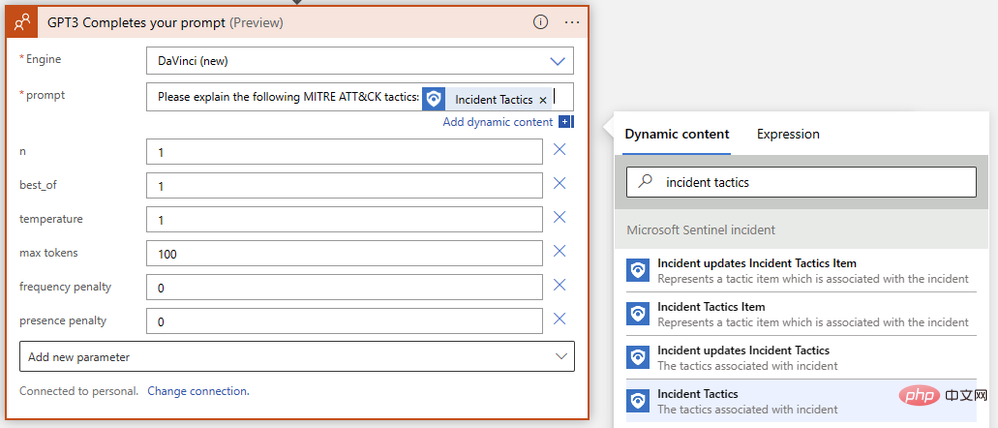
Nous avons presque terminé ! Enregistrez votre application logique et accédez à Microsoft Sentinel Events pour tester son exécution. J'ai des données de test de Microsoft Sentinel Training Lab dans mon instance, je vais donc exécuter ce playbook sur des événements déclenchés par des alertes de règles de boîte de réception malveillantes.
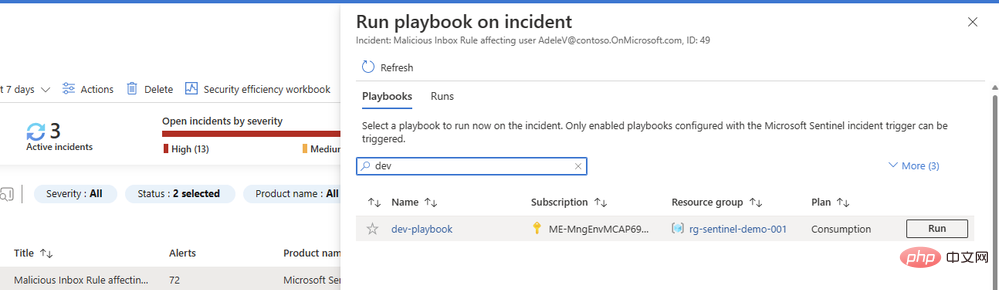
Vous vous demandez peut-être pourquoi nous n'avons pas configuré une deuxième action dans notre playbook pour ajouter un commentaire ou une tâche avec un résultat. Nous y arriverons - mais nous voulons d'abord nous assurer que nos invites renvoient un bon contenu du modèle d'IA. Revenez au Playbook et ouvrez la présentation dans un nouvel onglet. Vous devriez voir un élément dans votre historique de courses, avec un peu de chance avec une coche verte :
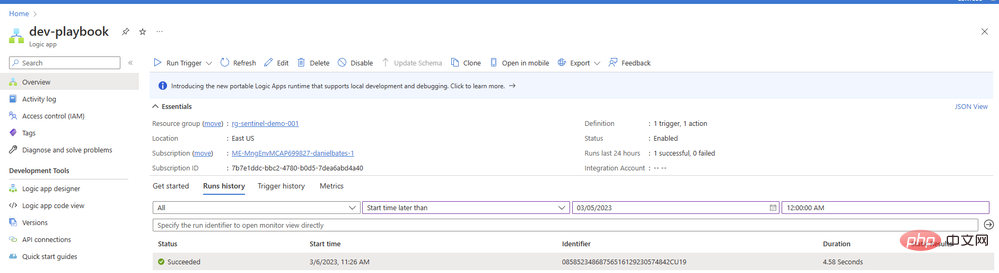
Cliquez sur l'élément pour voir les détails de l'application logique en cours d'exécution. Nous pouvons étendre n'importe quel bloc d'opération pour afficher les paramètres d'entrée et de sortie détaillés :
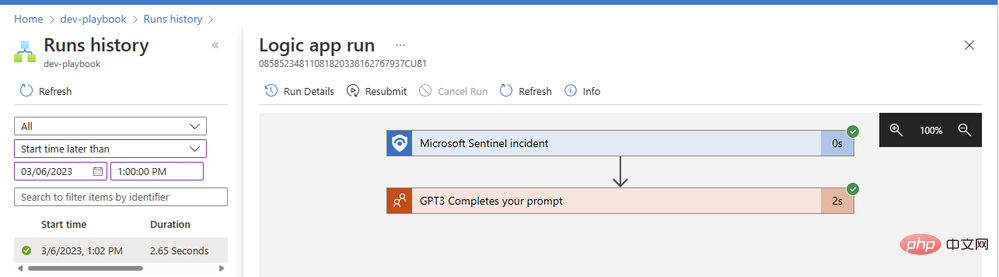
Notre opération GPT3 s'est terminée avec succès en seulement deux secondes. Cliquons sur le bloc d'action pour le développer et voir tous les détails de ses entrées et sorties :
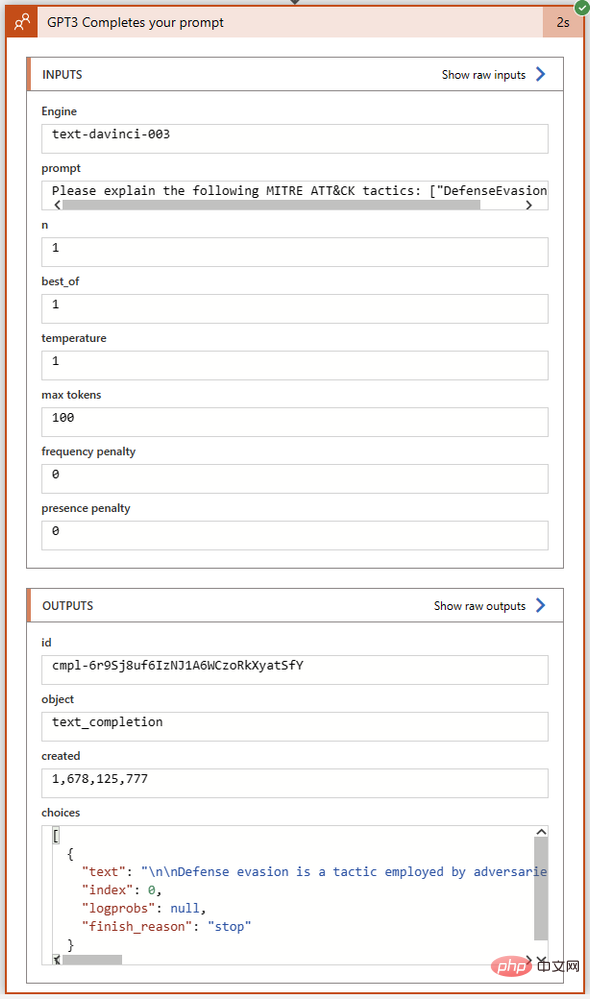
Examinons de plus près le champ Sélectionner dans la section Sorties. C'est ici que GPT3 renvoie le texte de son achèvement ainsi que l'état d'achèvement et les éventuels codes d'erreur. J'ai copié le texte intégral de la sortie Choices dans Visual Studio Code :
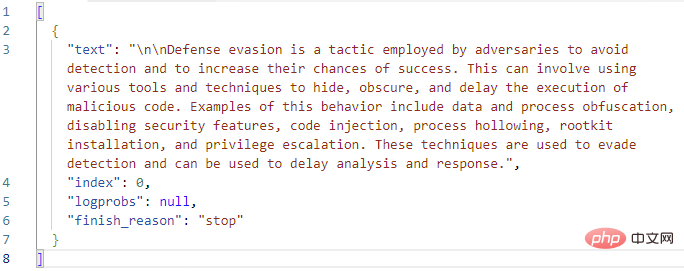
Ça a l'air bien jusqu'à présent ! GPT3 élargit correctement la définition MITRE de « l’évasion de la défense ». Avant d'ajouter une action logique au playbook pour créer un commentaire d'événement avec ce texte de réponse, examinons à nouveau les paramètres de l'action GPT3 elle-même. Il y a un total de neuf paramètres dans l'action de complétion de texte OpenAI, sans compter la sélection du moteur et les astuces :
Que signifient-ils et comment les ajuster pour obtenir les meilleurs résultats ? Pour nous aider à comprendre l'impact de chaque paramètre sur les résultats, allons sur OpenAI API Playground. Nous pouvons coller l'invite exacte dans le champ de saisie où l'application logique s'exécutera, mais avant de cliquer sur Soumettre, nous voulons nous assurer que les paramètres correspondent. Voici un tableau rapide comparant les noms des paramètres entre Azure Logic App OpenAI Connector et OpenAI Playground :
| Azure Logic App Connector | OpenAI Playground | Explication |
| Engine | Model | générera le modèle terminé. On peut sélectionner Leonardo da Vinci (nouveau), Leonardo da Vinci (ancien), Curie, Babbage ou Ada dans le connecteur OpenAI, correspondant respectivement à 'text-davinci-003', 'text-davinci-002', 'text -curie -001' , 'text-babbage-001' et 'text-ada-001' dans Playground. |
| n | NA | Combien de complétions sont générées pour chaque invite. Cela équivaut à ressaisir l'invite plusieurs fois dans le Playground. |
| Meilleur | (idem) | Générez plusieurs complétions et renvoyez la meilleure. À utiliser avec prudence – cela coûte beaucoup de jetons ! |
| La température | (idem) | définit le caractère aléatoire (ou la créativité) de la réponse. Défini sur 0 pour une exécution rapide et répétée hautement déterministe où le modèle renverra toujours son choix le plus sûr. Réglez-le sur 1 pour un maximum de réponses créatives avec plus de caractère aléatoire, ou quelque part entre les deux si vous le souhaitez. |
| Max Tokens | Longueur Max | Longueur maximale de la réponse ChatGPT, donnée en jetons. Un jeton est approximativement égal à quatre caractères. ChatGPT utilise la tarification des jetons ; au moment de la rédaction, 1 000 jetons coûtent 0,002 $. Le coût d'un appel d'API inclura la longueur du jeton suggérée ainsi que la réponse. Par conséquent, si vous souhaitez conserver le coût par réponse le plus bas, soustrayez la longueur du jeton suggérée de 1 000 pour limiter la réponse. |
| Pénalité de fréquence | (Idem) | Nombre allant de 0 à 2. Plus la valeur est élevée, moins le modèle est susceptible de répéter la ligne textuellement (il essaiera de trouver des synonymes ou des reformulations de la ligne). |
| Il y a une pénalité | (idem) | Un chiffre entre 0 et 2. Plus la valeur est élevée, moins le modèle est susceptible de répéter les sujets déjà mentionnés dans la réponse. |
| TOP | (idem) | Une autre façon de mettre en place la réponse "créativité" si vous n'utilisez pas la température. Ce paramètre limite les jetons de réponse possibles en fonction de la probabilité ; lorsqu'il est défini sur 1, tous les jetons sont pris en compte, mais des valeurs plus petites réduisent l'ensemble des réponses possibles aux X % supérieurs. |
| Utilisateur | N/A | identifiant unique. Nous n'avons pas besoin de définir ce paramètre car notre clé API est déjà utilisée comme chaîne d'identification. |
| Stop | Séquence d'arrêt | Jusqu'à quatre séquences mettront fin à la réponse du modèle. |
Utilisons les paramètres OpenAI API Playground suivants pour correspondre aux opérations de notre application logique :
- Modèle : text-davinci-003
- Température : 1
- Longueur maximale : 100
C'est ce que nous obtenons du résultat du moteur GPT3 .
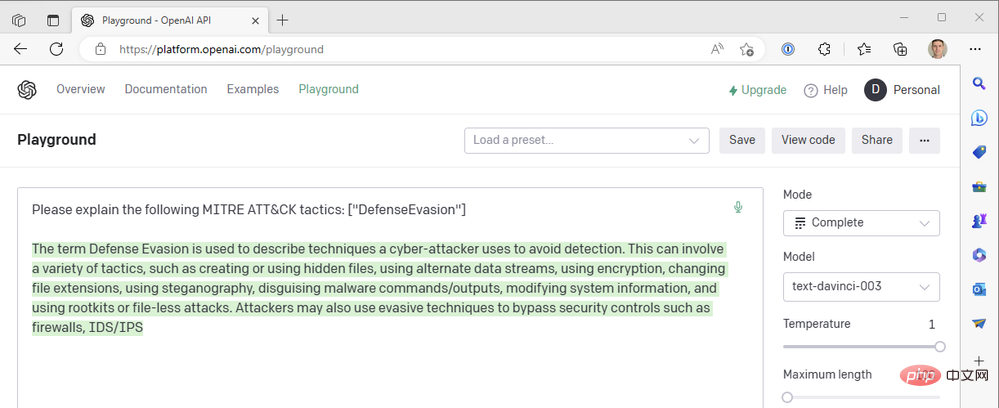
Il semble que la réponse soit tronquée au milieu de la phrase, nous devrions donc augmenter le paramètre de longueur maximale. Sinon, cette réponse semble plutôt bonne. Nous utilisons la valeur de température la plus élevée possible. Que se passe-t-il si nous abaissons la température pour obtenir une réponse plus certaine ? Prenons par exemple une température de zéro :
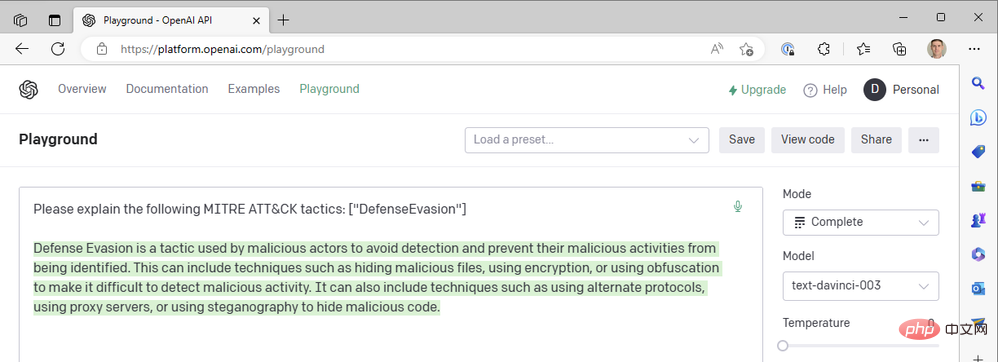
À température=0, peu importe le nombre de fois que nous régénérons cette invite, nous obtenons presque exactement le même résultat. Cela fonctionne bien lorsque nous demandons à GPT3 de définir des termes techniques ; il ne devrait pas y avoir beaucoup de différence dans ce que signifie « évasion défensive » en tant que tactique MITRE ATT&CK. Nous pouvons améliorer la lisibilité des réponses en ajoutant une pénalité de fréquence pour réduire la tendance du modèle à réutiliser les mêmes mots (« technique like »). Augmentons la pénalité de fréquence jusqu'à un maximum de 2 :
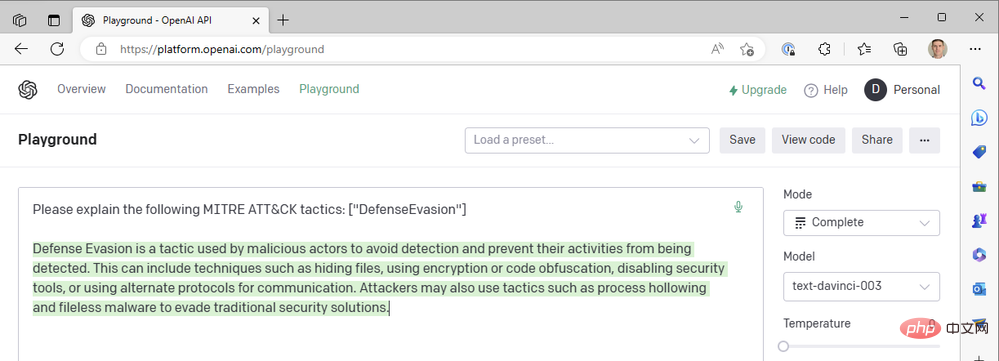
Jusqu'à présent, nous n'avons utilisé que les derniers modèles Da Vinci pour faire avancer les choses rapidement. Que se passe-t-il si nous passons à l’un des modèles OpenAI les plus rapides et les moins chers, comme Curie, Babbage ou Ada ? Changeons le modèle en « text-ada-001 » et comparons les résultats :
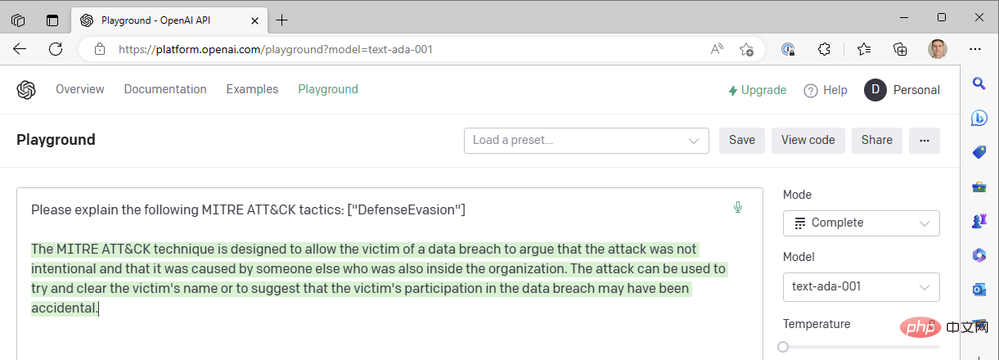
Eh bien… pas tout à fait. Essayons Babbage :
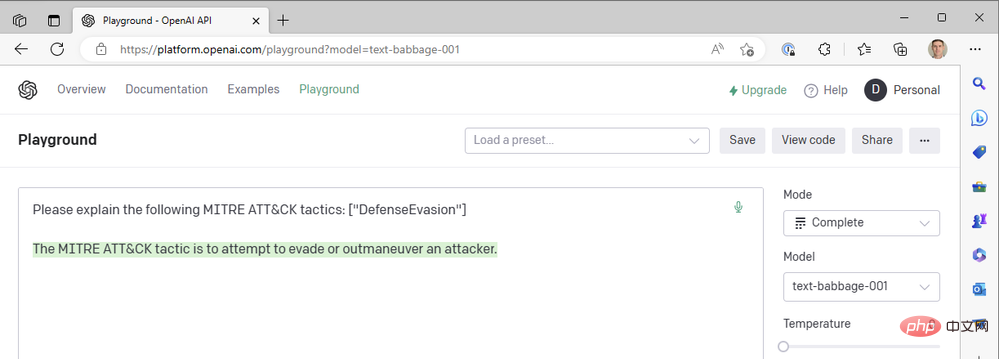
Babbage ne semble pas non plus renvoyer les résultats que nous recherchons. Peut-être que Curie serait mieux lotie ?
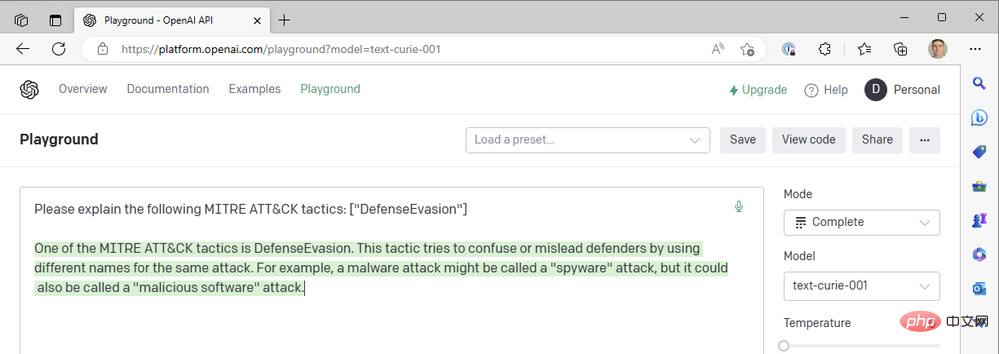
Malheureusement, Curie ne répondait pas non plus aux normes fixées par Léonard de Vinci. Ils sont certainement rapides, mais notre cas d'utilisation consistant à ajouter du contexte aux événements de sécurité ne repose pas sur des temps de réponse inférieurs à la seconde : la précision du résumé est plus importante. Nous continuons à utiliser la combinaison réussie des modèles Da Vinci, des punitions à basse température et à haute fréquence.
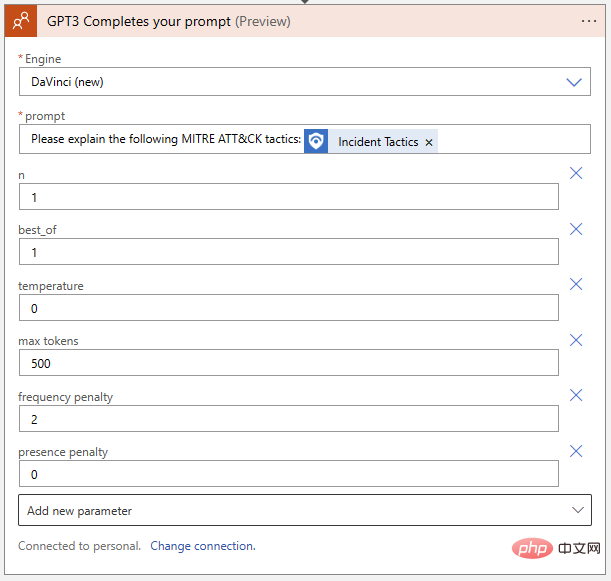
De retour à notre Logic App, transférons les paramètres que nous avons découverts du Playground vers le OpenAI Action Block :
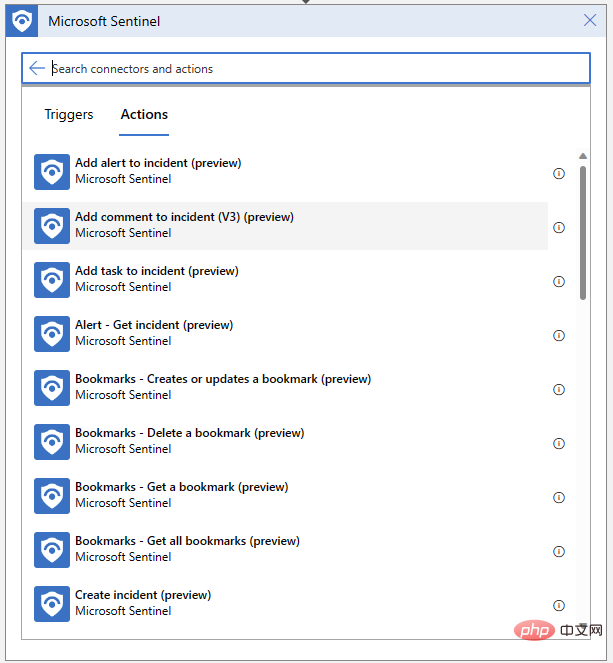
Notre Logic App devra également pouvoir écrire des commentaires pour nos événements. Cliquez sur "Nouvelle étape" et sélectionnez "Ajouter un commentaire à l'événement" depuis le connecteur Microsoft Sentinel :
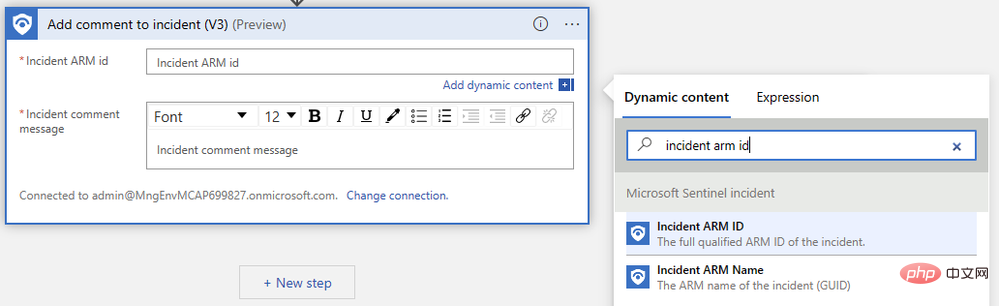
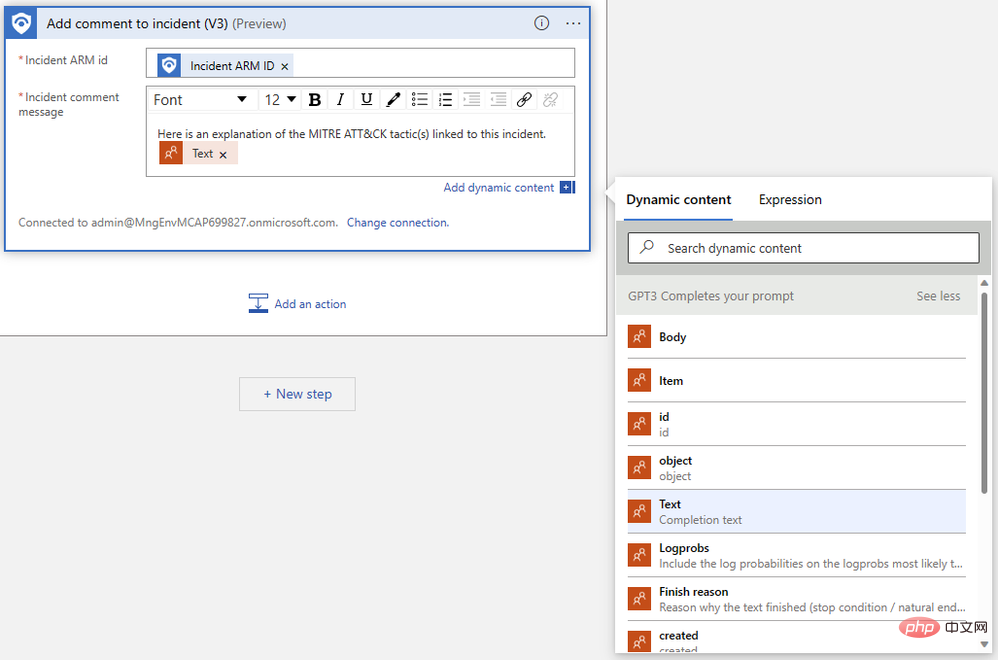
Il nous suffit de préciser l'identifiant ARM de l'événement et de rédiger notre message de commentaire. Tout d'abord, recherchez "Event ARM ID" dans le menu contextuel du contenu dynamique :
Ensuite, recherchez le "Texte" que nous avons généré à l'étape précédente. Vous devrez peut-être cliquer sur Voir plus pour voir le résultat. Le Logic App Designer enveloppe automatiquement notre action de commentaire dans un bloc logique « Pour chaque » pour gérer les cas où plusieurs complétions sont générées pour la même invite.
Notre application logique terminée devrait ressembler à ceci :
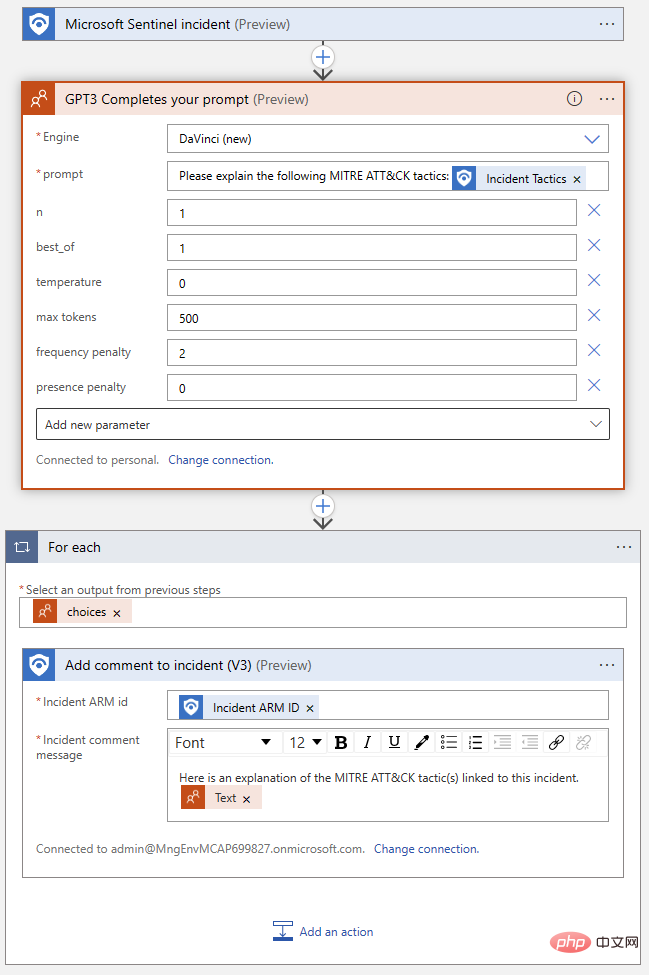
Testons-la à nouveau ! Revenez à cet événement Microsoft Sentinel et exécutez le playbook. Nous devrions obtenir une autre réussite dans l’historique d’exécution de notre application logique et un nouveau commentaire dans notre journal d’activité des événements.
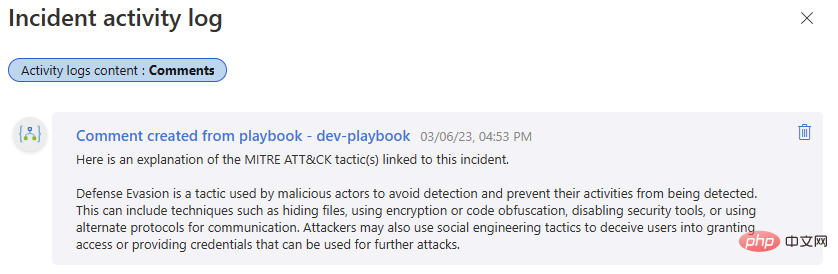
Si vous êtes restés en contact avec nous jusqu'à présent, vous pouvez désormais intégrer OpenAI GPT3 à Microsoft Sentinel, ce qui peut ajouter de la valeur à vos enquêtes de sécurité. Restez à l'écoute pour notre prochain article, où nous discuterons d'autres façons d'intégrer les modèles OpenAI avec Sentinel, débloquant ainsi des flux de travail qui peuvent vous aider à tirer le meilleur parti de votre plateforme de sécurité !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!