
Maison >Périphériques technologiques >IA >Comprendre l'algorithme de hachage et les scénarios d'application dans un seul article
Comprendre l'algorithme de hachage et les scénarios d'application dans un seul article

- 王林avant
- 2023-04-13 11:55:021895parcourir
1. Qu'est-ce qu'un algorithme de hachage
Le hachage et le hachage proviennent tous deux du mot hachage, le premier est une translittération et le second est une traduction libre. Il s'agit d'un algorithme qui peut mapper une valeur binaire de n'importe quelle longueur en une valeur binaire de longueur fixe. La valeur binaire de longueur fixe mappée est appelée valeur de hachage. Un excellent algorithme de hachage doit répondre aux exigences suivantes :
ne peut pas déduire inversement les données d'origine de la valeur de hachage ;
est très sensible aux données d'entrée, et un bit différent rendra la valeur de hachage
; La probabilité de conflit de hachage doit être très faible ;
Le processus de calcul de l'algorithme de hachage doit être suffisamment simple et efficace, même si les données originales sont très longues, la valeur de hachage peut être obtenue rapidement
2. l'algorithme de hachage
2.1 Cryptage sécurisé
Les algorithmes de cryptage de hachage les plus courants sont MD5 (algorithme de résumé de message MD5, algorithme de résumé de message MD5) et SHA (algorithme de hachage sécurisé, algorithme de hachage sécurisé).
Le mot de passe en clair ne peut pas être déduit du texte chiffré de la valeur de hachage, et la probabilité de conflit de hachage est relativement faible. Ces deux points garantissent la fiabilité de l'algorithme de hachage en tant que méthode de cryptage sécurisée.
Pourquoi les algorithmes de hachage ne peuvent-ils pas complètement éviter les collisions de hachage, mais peuvent seulement les minimiser ?
Le principe du nid de pigeons nous dit que si 11 pigeons volent dans 10 cages à pigeons, alors il doit y avoir 2 pigeons ou plus dans une cage à pigeons. Ensuite, la valeur de hachage est de longueur fixe, ce qui détermine que la valeur de hachage peut être épuisée, mais en théorie les données originales sont infinies, il est donc possible de provoquer un conflit de hachage.
Ce scénario d'application utilise les fonctionnalités 1 et 3 de l'algorithme de hachage, dont 3 garantissent que le mot de passe est très difficile à déchiffrer dans le sens direct (en prenant MD5 comme exemple, la longueur de la valeur de hachage est de 128 bits, et il y a 2 ^ 128 différents (la valeur de hachage est très difficile à déchiffrer).
Il n'y a pas de sécurité absolue dans le domaine de la sécurité. Bien que MD5 soit difficile à déchiffrer, il existe encore des moyens de le déchiffrer. Par exemple, l'utilisation de la correspondance par table arc-en-ciel peut facilement déchiffrer les mots de passe courants.
Nous utiliserons donc généralement un algorithme de hachage salé pour un cryptage sécurisé. La méthode de salage doit rester strictement confidentielle, ce qui augmente considérablement la difficulté et le coût du piratage.
2.2 Drapeau unique
Lorsque nous vérifions si deux fichiers sont identiques, nous ne pouvons pas simplement juger par le nom du fichier. Car l’existence de fichiers portant le même nom est trop courante.
Nous pouvons extraire des données binaires d'un fichier volumineux selon des règles spécifiques et utiliser un algorithme de hachage pour obtenir une valeur de hachage comme identifiant unique du fichier. De cette façon, les mêmes fichiers doivent avoir la même valeur de hachage, c'est-à-dire le même identifiant unique ; différents fichiers ont une forte probabilité d'avoir des identifiants uniques de valeurs de hachage différents
Même si nous rencontrons un conflit de hachage, nous pouvons le faire ; comparez toutes les données binaires des deux fichiers en détail pour déterminer davantage s'il s'agit du même fichier. La probabilité que cet événement se produise est trop faible. Cependant, cette solution garantit à la fois efficacité et fiabilité.
Ce scénario d'application utilise les fonctionnalités 2 et 3 de l'algorithme de hachage.
2.3 Vérification des données
Dans le protocole de téléchargement P2P, nous téléchargerons différentes parties du même film à partir de différentes machines, puis assemblerons le film sur notre propre machine. S'il y a une erreur dans le processus de téléchargement d'une partie du film ou si le contenu est falsifié, cela peut provoquer des erreurs de téléchargement ou des virus.
Donc, nous hachons d'abord toutes les parties et les enregistrons dans le fichier de départ. Une fois toutes les parties téléchargées, nous hachons toutes les parties pour obtenir la valeur de hachage, puis la comparons avec celle du fichier de départ pour vérifier si le fichier est complet.
Ce scénario d'application utilise les fonctionnalités 2 et 4 de l'algorithme de hachage.
2.4 Fonction de hachage
Ce scénario a déjà été introduit lorsque nous avons parlé de tables de hachage. Dans ce scénario, les exigences pour la fonctionnalité 1 ne sont pas très élevées. L'exigence pour la fonctionnalité 2 est que les valeurs de hachage doivent être réparties aussi uniformément que possible. La fonctionnalité 3 peut également accepter les conflits dans une certaine mesure, qui peuvent être résolus par. L'utilisation de la méthode d'adressage ouverte et de la méthode Zipper est plus exigeante et doit rechercher les performances.
2.5 Équilibrage de charge
Il existe de nombreux algorithmes d'équilibrage de charge, tels que l'interrogation, l'interrogation aléatoire, pondérée, etc., mais l'objectif est d'implémenter un algorithme d'équilibrage de charge persistant de session, c'est-à-dire tous les algorithmes d'équilibrage de charge du même client lors d'une session Les requêtes sont toutes acheminées vers le même serveur.
Nous pouvons hacher l'adresse IP ou l'ID de session du client, et modulo la valeur de hachage obtenue avec le nombre de serveurs. La valeur finale obtenue est le serveur qui doit être acheminé, afin que l'objectif de cohérence de session puisse être atteint.
2.6 Partage de données
Lorsque nous devons traiter des données massives, un seul serveur ne peut pas charger et calculer une quantité aussi massive de données, nous devons alors distribuer uniformément les données massives sur N serveurs pour un calcul parallèle. Comment diviser les données. Que diriez-vous de le diviser équitablement entre N serveurs ?
Nous effectuons un calcul de hachage sur les données et utilisons la valeur de hachage obtenue modulo le nombre de serveurs N. Les données avec le même résultat seront attribuées au même serveur et transmises à ce serveur pour traitement. N serveurs traitent des données massives en parallèle, et fusionnent enfin les résultats.
2.7 Stockage distribué
Stockez des données massives dans un cache distribué ou une base de données distribuée L'idée de l'emprunt est similaire au partage de données ci-dessus. Cependant, que faire lorsque le nombre de serveurs initialement défini n'est pas suffisant ?
Cela ne peut pas être résolu en ajoutant simplement quelques machines. Cela détruirait le fonctionnement modulo de la valeur de hachage, entraînerait une pénétration du cache et provoquerait un effet d'avalanche. De même, le même problème peut survenir lorsqu’un défaut machine est supprimé. À l’heure actuelle, nous devons utiliser un algorithme de hachage cohérent pour résoudre ce problème.
L'algorithme de hachage cohérent consiste simplement à construire un anneau de hachage avec 2 ^ 32 nœuds sur l'anneau et à hacher l'adresse IP du serveur et les fichiers vers les nœuds correspondants. Le premier serveur que tous les fichiers rencontrent dans le sens des aiguilles d'une montre est le serveur sur lequel ils sont stockés. De cette façon, lorsqu'un serveur est ajouté ou supprimé, le nombre de fichiers affectés peut être contrôlé et ne provoquera pas une avalanche mondiale.
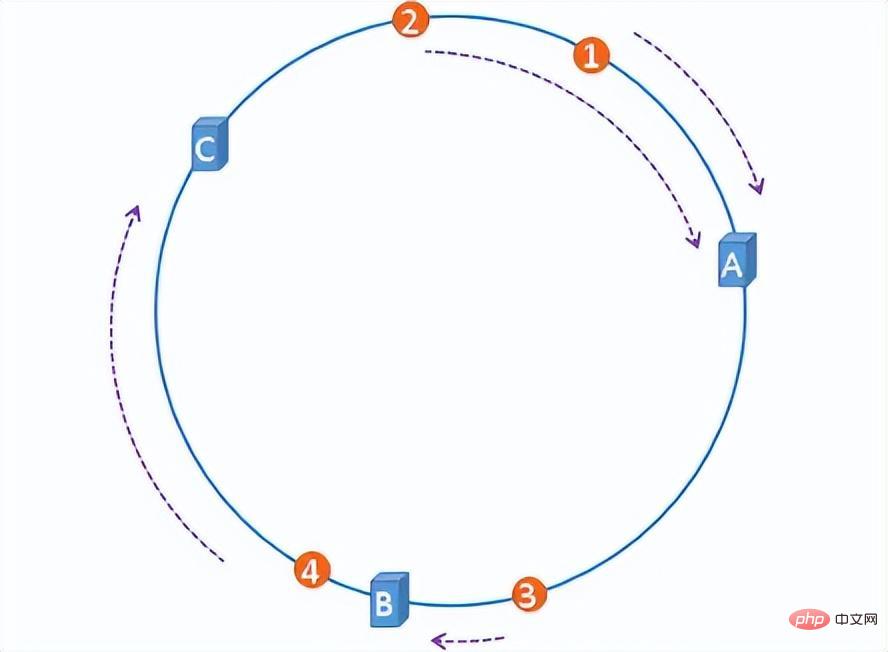
hash ring
Cependant, avec une certaine probabilité, lorsque l'adresse IP du serveur est mappée sur l'anneau de hachage, l'anneau de hachage sera biaisé, ce qui rendra la distribution des fichiers sur le serveur extrêmement inégale et se dégradera. a Il est facile de provoquer un effet d'avalanche lors de l'ajout ou de la suppression de serveurs.
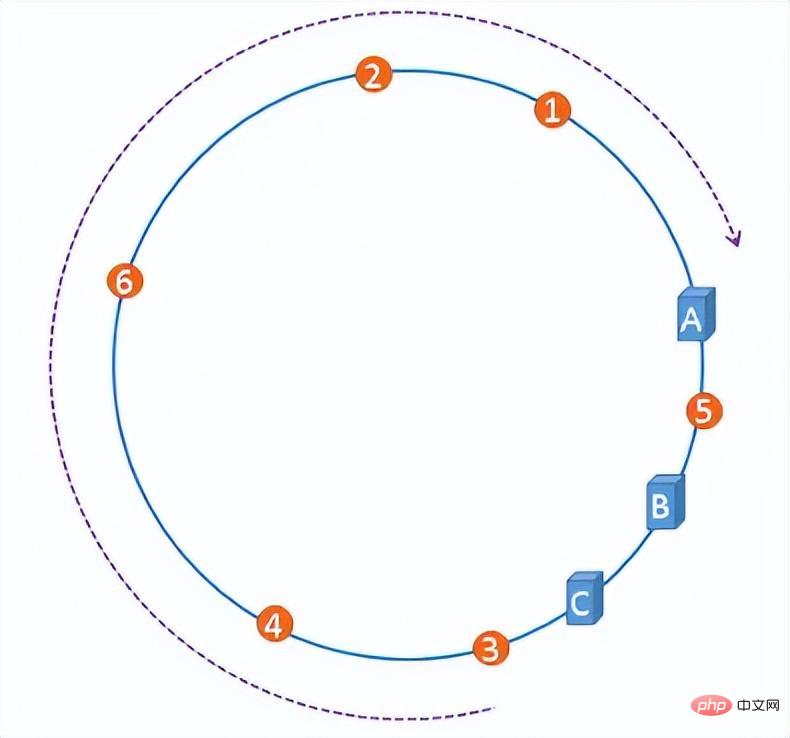
L'asymétrie de l'anneau de hachage
Nous pouvons ajouter artificiellement un certain nombre de nœuds virtuels à ces serveurs afin que tous les nœuds de serveur soient répartis uniformément sur l'anneau de hachage.
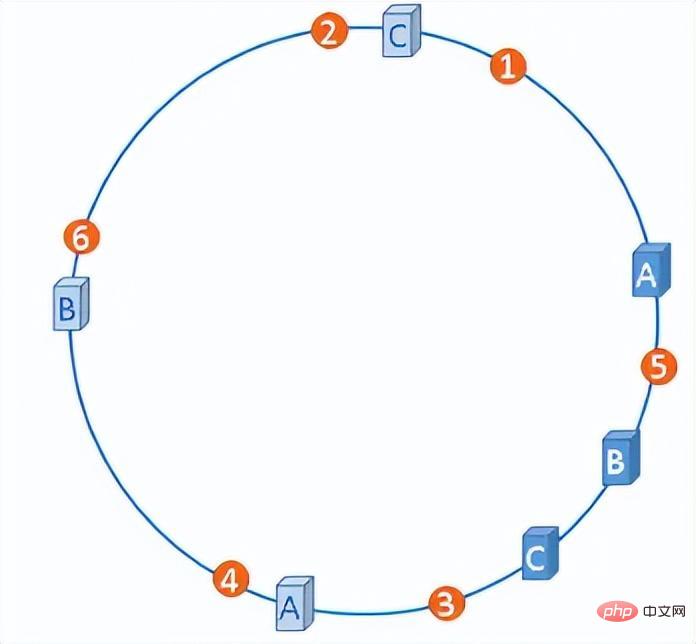
Anneau de hachage avec nœuds virtuels
3. Résumé
Les scénarios d'utilisation de l'algorithme de hachage sont bien plus que ceux ci-dessus, et il existe également des contrôles CRC.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI