
Maison >Périphériques technologiques >IA >L'apprentissage par renforcement est-il exagéré ?
L'apprentissage par renforcement est-il exagéré ?

- PHPzavant
- 2023-04-13 09:31:021172parcourir
Traducteur | Li Rui
Critique | Sun Shujuan
D'accordImaginez que vous vous préparez à jouer aux échecs avec vos amis, mais ce n'est pas un humain , mais un programme informatique qui ne comprendles règles du jeu. Mais cette application comprend qu'elle s'efforce d'atteindre un objectif, qui est de gagner dans le jeu.
Parce que le programme informatique ne connaît pas les règles, les mouvementsavec lesquels vous commencez à jouer aux échecs sont aléatoires. Certaines de ces astuces n'ont aucun sens et il vous sera facile de gagner. Supposons ici que vous aimez tellement jouer aux échecs avec cet ami que vous êtes accro à ce jeu.
Mais leprogramme informatique finira par gagner car il apprendra progressivement des moyens et des astuces pour vous vaincrecompte. Bien que ce scénario hypothétique puisse sembler tiré par les cheveux, il devrait vous donner une compréhension de base du fonctionnement général de l'apprentissage par renforcement (un domaine de l'apprentissage automatique).
Dans quelle mesure l'apprentissage par renforcement est-il intelligent ? 
Cependant
, "Deep Blue"n'est pas un adversaire ordinaire. Jouer aux échecs avec ce programme de calcul , c'est comme jouer aux échecs avec un vieux homme de mille ans, qui joue aux échecs non-stop tous sa vie . Mais "Deep Blue" est doué pour jouer à un jeu spécifique, pas pour d'autres activités intellectuelles comme jouer d'un instrument, écrire un livre, mener des expériences scientifiques, élever des enfants ou réparer des voitures. Ce n'est certainement pas destiné à minimiser
les réalisationsde "Deep Blue" . Contrairement à , l'idée selon laquelle les ordinateurs peuvent surpasser les humains en termes de capacités intellectuelles nécessite un examen attentif, en commençant par une analyse du fonctionnement de l'apprentissage par renforcement . Comment fonctionne l'apprentissage par renforcementComme mentionné
sur , l'apprentissage par renforcement est un sous-ensemble de l'apprentissage automatique qui implique comment un agent intelligent agit dans un environnement pour maximiser le concept de récompenses cumulées. En termes simples, les apprentissage par renforcementles robots sont entraînés avec un mécanisme de récompense et de punition, ils seront récompensés pour avoir effectué actions correctes, et les mauvaises actions seront punies pour les mauvaises actions. Apprentissage par renforcement les robots ne « pensent » comment prendre de meilleures actions, ils rendent simplement toutes les actions possibles pour maximiser les chances de succès. Le principal inconvénient de l'apprentissage par renforcement est qu'il nécessite l'utilisation d'une grande quantité de ressources pour atteindre ses objectifs. Le succès de l’apprentissage par renforcement dans le jeu de Go illustre ce point. Il s'agit d'un jeu populaire à deux joueurs où le but est d'occuper le maximum de surface du plateau en utilisant vos pièces tout en évitant de perdre des pièces. AlphaGo Master est un programme informatique qui bat les joueurs humains dans le jeu de Go. Il consomme beaucoup d'argent et de main d'œuvre, notamment de nombreux ingénieurs, une expérience de jeu très riche, ainsi que 256 GPU et 128 000 CPU. Dans le processus d'apprentissage pour gagner le jeu, beaucoup de ressources et d'énergie doivent être investies. Cela soulève la question suivante : est-il raisonnable de concevoir une IA qui ne peut pas penser intuitivement ? La recherche sur l'IA ne devrait-elle pas tenter d'imiter l'intelligence humaine ? L'IA pour Le système se comporte comme un être humain et son utilisation pour résoudre des problèmes complexes nécessite un développement ultérieur. D’un autre côté, l’argument contre l’apprentissage par renforcement est que la recherche sur l’IA devrait se concentrer sur la capacité des machines à faire des choses que seuls les humains et les animaux sont actuellement capables de faire. De ce point de vue, la comparaison entre intelligence artificielle et intelligence humaine est pertinente. Apprentissage par renforcement quantiqueL'apprentissage par renforcement est un domaine émergent qui serait capable de résoudre certains des problèmes ci-dessus. L'apprentissage par renforcement quantique (QRL) est une méthode d'accélération du calcul. Premièrement, l'apprentissage par renforcement quantique (QRL) est censé accélérer l'apprentissage en optimisant les phases d'exploration (découverte de la stratégie) et d'exploitation (sélection de la meilleure stratégie). Certaines applications actuelles et l'informatique quantique proposée améliorent les recherches dans les bases de données, factorisent de grands nombres en nombres premiers, etc. Bien que l'apprentissage par renforcement quantique (QRL) n'ait pas émergé de manière révolutionnaire, il promet de résoudre certains des défis majeurs de l'apprentissage par renforcement conventionnel. Business case for Reinforcement Learning Le pouvoir de l'apprentissage par renforcement est peut-être limité, mais il ne peut être surestimé. De plus, à mesure que les projets de recherche et de développement sur l’apprentissage par renforcement augmentent, les cas d’utilisation potentiels augmentent également dans presque tous les secteurs de l’économie. L'adoption à grande échelle de l'apprentissage par renforcement repose sur plusieurs facteurs, notamment la conception optimale des algorithmes, la configuration de l'environnement d'apprentissage et la disponibilité de la puissance de calcul. Titre original : L'apprentissage par renforcement est-il surfait ?, Auteur : Alek Sandras ŠulženkoInconvénients de l'apprentissage par renforcement
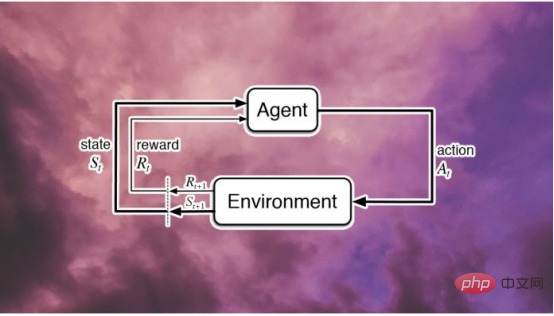
Comme mentionné ci-dessus, la recherche et le développement en matière d’apprentissage par renforcement sont cruciaux. Voici quelques exemples pratiques d'apprentissage par renforcement issus d'une enquête McKinsey & Company qui peuvent :
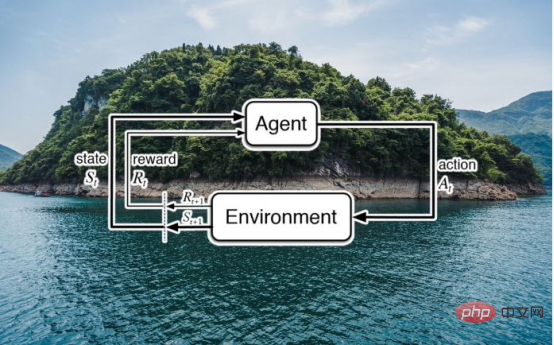
Réflexions sur l'apprentissage par renforcement
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI