
Maison >développement back-end >Tutoriel Python >Six fonctions magiques intégrées en Python
Six fonctions magiques intégrées en Python

- 王林avant
- 2023-04-13 08:04:051977parcourir

La vie est courte, les novices apprennent Python !
Je suis un débutant, aujourd'hui, nous allons partager 6 fonctions magiques intégrées à la fois. Dans de nombreux manuels informatiques, elles sont également généralement présentées comme des fonctions d'ordre supérieur. Dans mon travail quotidien, je les utilise souvent pour rendre le code plus rapide et plus facile à comprendre.
Fonction Lambda
La fonction Lambda est utilisée pour créer des fonctions anonymes, c'est-à-dire des fonctions sans noms. Ce n'est qu'une expression et le corps de la fonction est beaucoup plus simple que def. Les fonctions anonymes sont utilisées lorsque nous devons créer une fonction qui effectue une seule opération et peut être écrite sur une seule ligne.
lambda [arg1 [,arg2,.....argn]]:expression
Le corps d'un lambda est une expression, pas un bloc de code. Seule une logique limitée peut être encapsulée dans des expressions lambda. Par exemple :
lambda x: x+2
Si nous voulons également appeler la fonction définie par def à tout moment, nous pouvons attribuer la fonction lambda à un tel objet fonction.
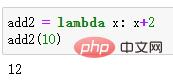
add2 = lambda x: x+2 add2(10)
Résultat de sortie :
En utilisant la fonction Lambda, le code peut être beaucoup simplifié. Voici un autre exemple.
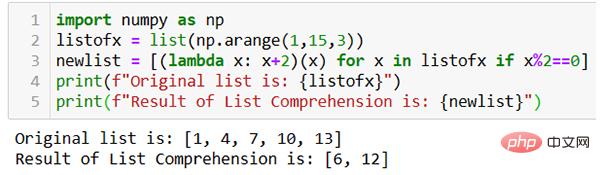
Comme le montre l'image ci-dessus, la nouvelle liste de résultats est générée avec une ligne de code à l'aide de la fonction lambda.
Fonction Map
La fonction map() mappera une fonction à tous les éléments d'une liste d'entrée.
map(function,iterable)
Par exemple, nous créons d'abord une fonction pour renvoyer un mot d'entrée en majuscule, puis appliquons cette fonction à tous les éléments de la liste des couleurs.
def makeupper(word): return word.upper() colors=['red','yellow','green','black'] colors_uppercase=list(map(makeupper,colors)) colors_uppercase
Résultat de sortie :

De plus, nous pouvons également utiliser la fonction anonyme lambda pour coopérer avec la fonction map, qui peut être plus rationalisée.
colors=['red','yellow','green','black'] colors_uppercase=list(map(lambda x: x.upper(),colors)) colors_uppercase
Si nous n'utilisons pas la fonction Map, nous devons utiliser une boucle for.
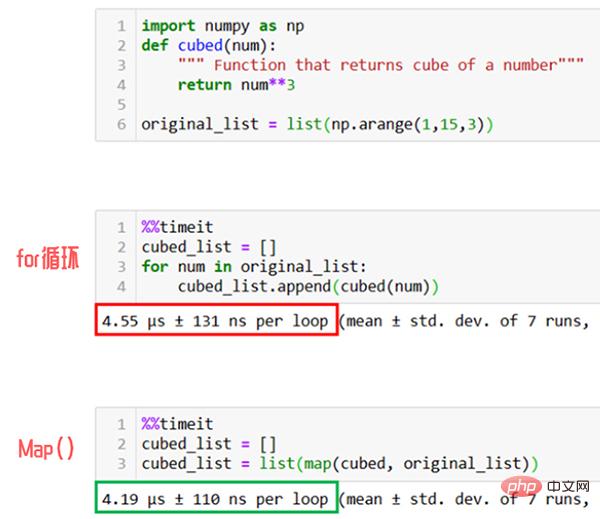
Comme le montre la figure ci-dessus, en utilisation réelle, la fonction Map sera 1,5 fois plus rapide que la méthode de boucle for permettant de lister séquentiellement les éléments.
Fonction Réduire
Reduce() est une fonction très utile lorsque vous devez effectuer des calculs sur une liste et renvoyer le résultat. Par exemple, lorsque vous devez calculer le produit de tous les éléments d’une liste d’entiers, vous pouvez utiliser la fonction réduire. [1]
La plus grande différence entre elle et une fonction est que la fonction de mappage (fonction) dans réduire() reçoit deux paramètres, tandis que map reçoit un paramètre.
reduce(function, iterable[, initializer])
Ensuite, nous utilisons un exemple pour démontrer le processus d'exécution de code de réduire().
from functools import reduce def add(x, y) : # 两数相加 return x + y numbers = [1,2,3,4,5] sum1 = reduce(add, numbers) # 计算列表和
Le résultat sum1 = 15 est obtenu et le processus d'exécution du code est montré dans l'animation ci-dessous.
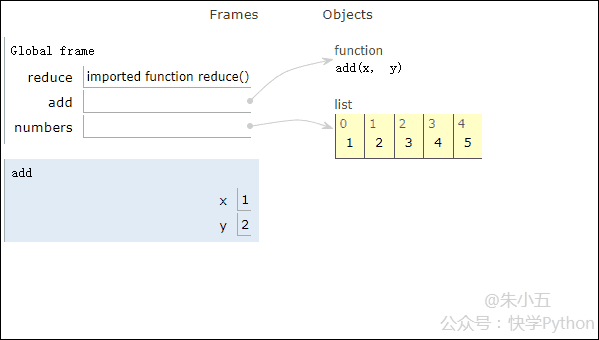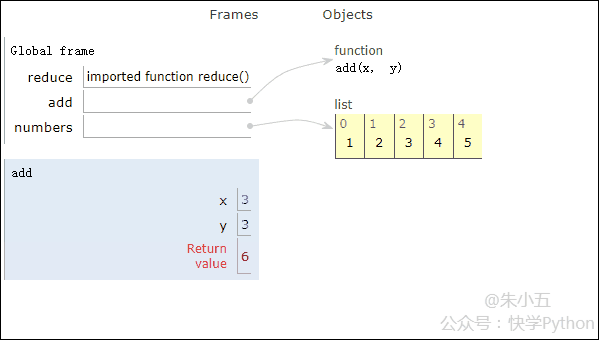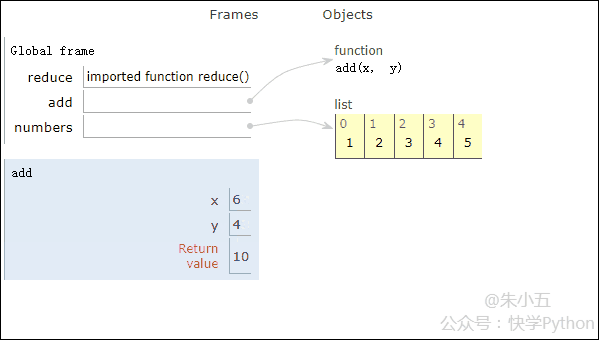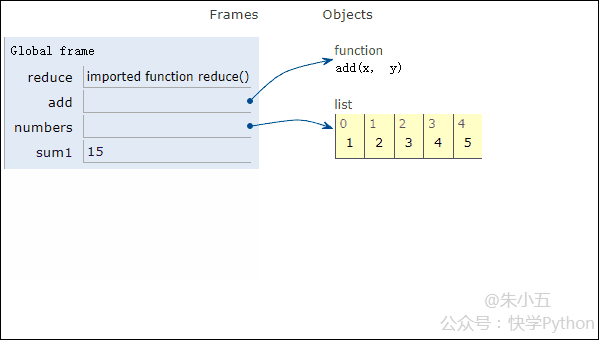
▲Animation du processus d'exécution de code
Combiné avec la figure ci-dessus, nous verrons que réduire applique une fonction d'addition add() à une liste [1,2,3,4,5], et le mappage la fonction reçoit Avec deux paramètres, réduire() continue d'accumuler le résultat avec l'élément suivant de la liste.
De plus, nous pouvons également utiliser la fonction anonyme lambda pour coopérer avec la fonction de réduction, qui peut être plus rationalisée.
from functools import reduce numbers = [1,2,3,4,5] sum2 = reduce(lambda x, y: x+y, numbers)
La sortie sum2= 15 est cohérente avec le résultat précédent.
Remarque : réduire() a été déplacé vers le module functools depuis Python 3. Les objets de données traversables (tels que des listes, des tuples ou des chaînes) sont combinés dans une séquence d'index, répertoriant les données et les indices de données en même temps, généralement utilisées dans les boucles. Sa syntaxe est la suivante :
enumerate(iterable, start=0)
Ses deux paramètres, l'un est une séquence, un itérateur ou autre objet prenant en charge l'itération ; l'autre est la position de départ de l'indice, commençant à 0 par défaut, vous pouvez également personnaliser le point de départ de le compteur Numéro de départ.
colors = ['red', 'yellow', 'green', 'black'] result = enumerate(colors)
Si nous avons une liste de couleurs qui stocke les couleurs, nous obtiendrons un objet énumération après l'avoir exécuté. Il peut être utilisé directement dans une boucle for ou converti en liste. L'utilisation spécifique est la suivante.
for count, element in result:
print(f"迭代编号:{count},对应元素:{element}")
Zip 函数
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表[3]。
我们还是用两个列表作为例子演示:
colors = ['red', 'yellow', 'green', 'black'] fruits = ['apple', 'pineapple', 'grapes', 'cherry'] for item in zip(colors,fruits): print(item)
输出结果:
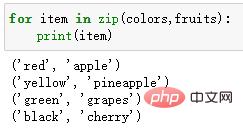
当我们使用zip()函数时,如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
prices =[100,50,120] for item in zip(colors,fruits,prices): print(item)

Filter 函数
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表,其语法如下所示[4]。
filter(function, iterable)
比如举个例子,我们可以先创建一个函数来检查单词是否为大写,然后使用filter()函数过滤出列表中的所有奇数:
def is_odd(n): return n % 2 == 1 old_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] new_list = filter(is_odd, old_list) print(newlist)
输出结果:

今天分享的这6个内置函数,在使用 Python 进行数据分析或者其他复杂的自动化任务时非常方便。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!