
Maison >développement back-end >Tutoriel Python >Obtenez facilement l'historique des transactions Binance en utilisant Python
Obtenez facilement l'historique des transactions Binance en utilisant Python

- PHPzavant
- 2023-04-12 22:16:192339parcourir

Étant donné que certaines stratégies nécessitent un certain niveau de données techniques, tandis que d'autres peuvent ne prendre qu'une heure de votre temps, le processus n'est pas toujours simple et des éléments tels que l'infrastructure, la disponibilité et la connectivité peuvent varier en fonction des données. Les types varient considérablement.
Mais pourquoi cet article concerne-t-il uniquement l'obtention de données de « transaction », pourquoi utilisons-nous l'API Binance ? Vous avez peut-être des questions sur le contenu de mon article.
Fréquence et équilibrage des données
Je dirais que les points de terminaison des données de trading sont principalement disponibles dans 99,99% des échanges. Il est fin, fournit suffisamment de détails (dans certains cas très spécifiques) pour backtester les stratégies de trading haute fréquence (HFT) et peut être utilisé comme base de bougies OHLC (1S à 24H ou plus si vous le souhaitez).
Les données de trading sont universelles et permettent un grand nombre d'expérimentations utilisant des stratégies à différentes fréquences.
Pourquoi choisir Binance ?
C’est simplement parce que c’est l’un des échanges sur lesquels j’ai tendance à revenir en arrière en raison du volume considérable.
L'encodage que nous allons faire
Nous allons créer un script Python qui reçoit une paire de symboles, une date de début et une date de fin comme arguments de ligne de commande. Il génère un fichier CSV contenant toutes les transactions sur le disque. Le processus peut être expliqué en détail à travers les étapes suivantes :
1 Analysez le symbole, les arguments Starting_date et Ending_date.
2. Obtenez la première transaction survenue à la date de début pour obtenir le premier trade_id de la transaction.
3. Boucle pour obtenir 1000 transactions par requête (limite de l'API Binance) jusqu'à ce que la date de fin soit atteinte.
4. Enfin, enregistrez les données sur le disque. Pour l'exemple, nous l'avons enregistré au format CSV, mais vous disposez d'autres options et ne l'enregistrez pas nécessairement au format CSV.
5. Nous utiliserons les pandas, les requêtes, l'heure, le système et la date/heure. Dans l'extrait de code, la validation de l'erreur ne sera pas affichée car elle n'ajoute aucune valeur à la description.
Heure de codage
Le script utilisera les paramètres suivants :
1 symbole : le symbole de la paire de trading, défini par Binance. Cela peut être interrogé ici ou copié à partir de l'URL de l'application Web Binance (à l'exclusion du caractère _).

-starting_date etending_date : explicites. Le format attendu est mm/jj/aaaa ou %m/%d/%Y en utilisant l'argot Python.
Pour obtenir les paramètres, nous utiliserons la fonction intégrée sys (rien d'extraordinaire ici) et pour analyser la date, nous utiliserons la bibliothèque datetime.

Nous ajouterons un jour et soustrairons une microseconde afin que la partie horaire de fin_date soit toujours à 23:59:59.999, ce qui rend l'obtention de l'intervalle du même jour plus pratique.
Récupération de transactions
En utilisant l'API de Binance et en utilisant le point de terminaison aggTrades, nous pouvons obtenir jusqu'à 1000 transactions en une seule requête, avec jusqu'à une heure entre elles si nous utilisons les paramètres de début et de fin.
Après quelques échecs en utilisant la récupération par intervalles (à un moment ou à un autre, la liquidité deviendrait folle et je perdrais des transactions précieuses), j'ai décidé d'essayer la stratégie from_id.
Sera le point final sélectionné par aggTrades car il renvoie des transactions compressées. De cette façon, nous ne perdrons aucune information précieuse.
Obtenez des offres totales compressées. Les transactions exécutées en même temps à partir du même ordre au même prix regrouperont la quantité.
La stratégie from_id est la suivante :
Nous voulons obtenir la date_de_départ de la première transaction en envoyant l'intervalle de dates au point final. Après cela, nous obtiendrons 1 000 transactions à partir du premier ID de transaction récupéré. Nous vérifierons ensuite si la dernière transaction a eu lieu après notre date_de fin.
Si tel est le cas, nous avons parcouru toutes les périodes et pouvons enregistrer les résultats dans un fichier. Sinon, nous mettons à jour la variable from_id pour obtenir le dernier ID de transaction et recommençons la boucle.
Obtenez le premier numéro de transaction
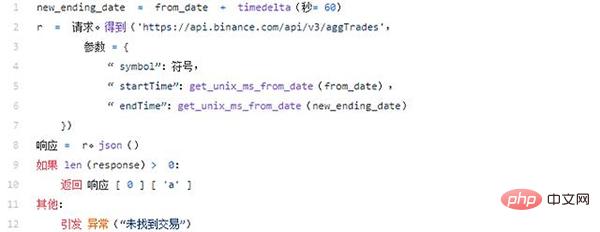
Tout d'abord, nous créons une new_end_date. C'est parce que nous utilisons aggTrades en passant des paramètres startTime et endTime.
Maintenant, il ne nous reste plus qu'à connaître le premier numéro de transaction de la période, nous ajouterons donc 60 secondes. Dans les paires de devises à faible liquidité, ce paramètre peut être modifié, car il n'est pas garanti que les transactions auront lieu le premier jour de la demande.
Ensuite, analysez la date à l'aide de notre fonction d'assistance pour convertir la date en représentation milliseconde Unix à l'aide de la fonction calendrier.timegm. La fonction timegm est la fonction préférée car elle conserve les dates en UTC.

La réponse à la demande est une liste d'objets commerciaux triés par date au format suivant :

Donc, puisque nous avons besoin du premier identifiant de transaction, nous renverrons cette réponse[0][" une "]valeur.
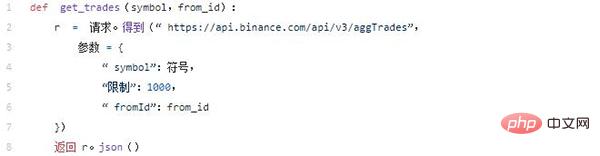
Boucle principale
Maintenant que nous avons le premier identifiant de transaction, nous pouvons récupérer 1 000 transactions à la fois jusqu'à ce que la date de fin soit atteinte. Le code suivant sera appelé dans notre boucle principale. Il exécutera notre requête en utilisant le paramètre from_id, en ignorant les paramètres startDate et endDate.
Maintenant, c'est notre boucle principale qui exécutera la requête et créera notre DataFrame.
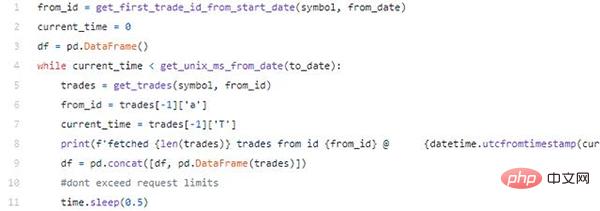
Nous vérifions si current_time contient la date de transaction la plus récemment récupérée supérieure à to_date, si c'est le cas nous :
- Récupérons la transaction en utilisant le paramètre from_id
- Mettons à jour les paramètres from_id et current_time avec les informations extraites du dernière transaction
- Imprimer de jolis messages de débogage
- pd.concat Ces transactions sont comparées à notre transaction précédente DataFrame
- Utilisez sleep pour que Binance ne nous donne pas de réponse HTTP 429
Nettoyez et enregistrez
Après avoir assemblé le DataFrame, nous devons effectuer un simple nettoyage des données. Nous supprimerons les transactions avec garniture en double et les transactions survenues après to_date (nous avons ce problème car nous obtenons la plupart des 1 000 transactions, nous sommes donc censés exécuter certaines transactions après la date de fin cible).
Nous pouvons encapsuler notre fonction trim :

et effectuer notre nettoyage des données :

Nous pouvons maintenant l'enregistrer dans un fichier en utilisant la méthode to_csv :


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!