
Maison >Périphériques technologiques >IA >Reconnaissance vocale à l'aide du modèle Whisper d'OpenAI
Reconnaissance vocale à l'aide du modèle Whisper d'OpenAI

- 王林avant
- 2023-04-12 17:28:032103parcourir
La reconnaissance vocale est un domaine de l'intelligence artificielle qui permet aux ordinateurs de comprendre la parole humaine et de la convertir en texte. La technologie est utilisée dans des appareils comme Alexa et diverses applications de chatbot. La chose la plus courante que nous faisons est la transcription vocale, qui peut être convertie en transcriptions ou sous-titres.

Les développements récents de modèles de pointe tels que wav2vec2, Conformer et Hubert ont considérablement fait progresser le domaine de la reconnaissance vocale. Ces modèles utilisent des techniques qui apprennent à partir de l’audio brut sans avoir besoin de données étiquetées par l’homme, ce qui leur permet d’utiliser efficacement de grands ensembles de données de parole non étiquetée. Ils ont également été étendus pour utiliser jusqu'à 1 000 000 d'heures de données de formation, bien au-delà des 1 000 heures traditionnelles utilisées dans les ensembles de données académiques supervisés, mais les modèles pré-entraînés de manière supervisée sur plusieurs ensembles de données et domaines se sont avérés plus performants. ensembles de données, de sorte que l'exécution de tâches telles que la reconnaissance vocale nécessite encore un réglage fin, ce qui limite leur plein potentiel. Pour résoudre ce problème, OpenAI a développé Whisper, un modèle qui utilise des méthodes de supervision faibles.
Cet article expliquera les types d'ensembles de données utilisés pour la formation et les méthodes de formation du modèle, et comment utiliser Whisper
Introduction au modèle Whisper
Utilisation de l'ensemble de données :
Le modèle Whisper est sur un ensemble de données de 680 000 heures de formation sur les données audio labellisées, qui comprennent 117 000 heures de parole dans 96 langues différentes et 125 000 heures de données de traduction de « n'importe quelle langue » vers l'anglais. Le modèle exploite le texte généré sur Internet par d'autres systèmes de reconnaissance automatique de la parole (ASR) plutôt que créé par des humains. L'ensemble de données comprend également un détecteur de langue formé sur VoxLingua107, une collection de courts clips vocaux extraits de vidéos YouTube et étiquetés en fonction de la langue du titre et de la description de la vidéo, avec des étapes supplémentaires pour supprimer les faux positifs.
Modèle :
La structure principale utilisée est la structure codeur-décodeur.
Rééchantillonnage : 16 000 Hz
Méthode d'extraction des caractéristiques : Calculez la représentation du spectrogramme Log Mel à 80 canaux en utilisant une fenêtre de 25 ms et une foulée de 10 ms.
Normalisation des fonctionnalités : l'entrée est globalement mise à l'échelle entre -1 et 1 et a une moyenne approximativement nulle sur l'ensemble de données pré-entraîné.
Encodeur/Décodeur : L'encodeur et le décodeur de ce modèle adoptent des transformateurs.
Processus d'encodeur :
L'encodeur traite d'abord la représentation d'entrée à l'aide d'une tige contenant deux couches convolutives (largeur de filtre 3), en utilisant la fonction d'activation GELU.
La foulée de la deuxième couche convolutive est de 2.
Ensuite, ajoutez l'intégration de la position sinusoïdale à la sortie de la tige, puis appliquez le bloc transformateur de l'encodeur.
Les transformateurs utilisent des blocs résiduels pré-activés et la sortie de l'encodeur est normalisée à l'aide d'une couche de normalisation.
Schéma fonctionnel du modèle :

Processus de décodage :
Dans le décodeur, l'intégration de la position d'apprentissage et la liaison de la représentation des marques d'entrée et de sortie sont utilisées.
L'encodeur et le décodeur ont la même largeur et le même nombre de blocs Transformers.
Formation
Pour améliorer les propriétés de mise à l'échelle du modèle, il est entraîné sur différentes tailles d'entrée.
Formez le modèle avec FP16, la mise à l'échelle dynamique des pertes et le parallélisme des données.
En utilisant AdamW et l'écrêtage des normes de gradient, le taux d'apprentissage linéaire diminue jusqu'à zéro après l'échauffement des 2048 premières mises à jour.
Utilisez une taille de lot de 256 et entraînez le modèle pour 220 mises à jour, ce qui équivaut à deux à trois passes avant sur l'ensemble de données.
Étant donné que le modèle n'a été formé que pendant quelques époques, le surajustement n'était pas un problème significatif et aucune technique d'augmentation ou de régularisation des données n'a été utilisée. Cela repose plutôt sur la diversité au sein de grands ensembles de données pour promouvoir la généralisation et la robustesse.
Whisper a démontré une bonne précision sur les ensembles de données précédemment utilisés et a été testé par rapport à d'autres modèles de pointe.
Avantages :
- Whisper a été formé sur des données réelles ainsi que sur des données utilisées sur d'autres modèles et avec une faible supervision.
- La précision du modèle est testée par rapport à des auditeurs humains et ses performances sont évaluées.
- Il détecte les zones non exprimées et applique la technologie PNL pour saisir correctement les signes de ponctuation dans les transcriptions.
- Le modèle est évolutif et permet d'extraire des transcriptions de signaux audio sans diviser la vidéo en morceaux ou en lots, réduisant ainsi le risque de sons manquants.
- Le modèle atteint une plus grande précision sur divers ensembles de données.
Résultats comparatifs de Whisper sur différents ensembles de données, par rapport à wav2vec, il a atteint le taux d'erreur de mot le plus bas jusqu'à présent

Le modèle n'a pas été testé sur l'ensemble de données Timit, donc afin de vérifier son taux d'erreur sur les mots, nous allons montrer ici comment utiliser Whisper pour auto-vérifier l'ensemble de données Timit, c'est-à-dire utiliser Whisper pour créer notre propre application de reconnaissance vocale.
Utilisation du modèle Whisper pour la reconnaissance vocale
TIMIT Reading Speech Corpus est une collection de données vocales spécifiquement utilisées pour la recherche sur la parole acoustique ainsi que pour le développement et l'évaluation de systèmes de reconnaissance vocale automatique. Il comprend des enregistrements de 630 locuteurs des huit principaux dialectes de l'anglais américain, chacun lisant dix phrases phonétiquement riches. Le corpus comprend des transcriptions orthographiques, phonétiques et de mots alignées dans le temps, ainsi que des fichiers de formes d'onde vocales de 16 bits et 16 kHz pour chaque voix. Le corpus a été développé par le Massachusetts Institute of Technology (MIT), SRI International (SRI) et Texas Instruments (TI). Les transcriptions du corpus TIMIT ont été vérifiées manuellement, avec des sous-ensembles de tests et de formation spécifiés pour équilibrer la couverture phonétique et dialectale.
Installation :
!pip install git+https://github.com/openai/whisper.git !pip install jiwer !pip install datasets==1.18.3
La première commande installera toutes les dépendances requises par le modèle Whisper. jiwer est utilisé pour télécharger le package de taux d'erreur de texte. Les ensembles de données sont fournis par hugface. Vous pouvez télécharger l'ensemble de données Timit.
Importer la bibliothèque
import whisper from pytube import YouTube from glob import glob import os import pandas as pd from tqdm.notebook import tqdm
Charger l'ensemble de données Timit
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")Calculer le taux d'erreur Word sous différentes tailles de modèle
Considérant la nécessité de filtrer les données anglaises et les données non anglaises, nous choisissons d'utiliser ici un modèle multilingue à la place spécifiquement pour le modèle de conception anglaise.
Mais l'ensemble de données TIMIT est en anglais pur, nous devons donc appliquer le même processus de détection et de reconnaissance de la langue. De plus, l'ensemble de données TIMIT a été divisé en ensembles de formation et de vérification, et nous pouvons l'utiliser directement.
Pour utiliser Whisper, nous devons d'abord comprendre les paramètres, la taille et la vitesse des différents modèles.

Loading model
model = whisper.load_model('tiny')tiny peut être remplacé par le nom du modèle mentionné ci-dessus.
La fonction qui définit le détecteur de langue
def lan_detector(audio_file):
print('reading the audio file')
audio = whisper.load_audio(audio_file)
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
if max(probs, key=probs.get) == 'en':
return True
return FalseLa fonction qui convertit la parole en texte
def speech2text(audio_file): text = model.transcribe(audio_file) return text["text"]
En exécutant la fonction ci-dessus avec différentes tailles de modèle, les taux d'erreur de mots obtenus par l'entraînement et les tests Timit sont les suivants :
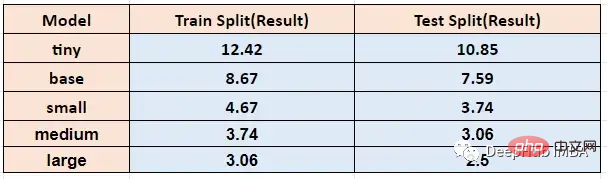
Transcrit de u2b Speech
Par rapport à d'autres modèles de reconnaissance vocale, Whisper peut non seulement reconnaître la parole, mais également interpréter la ponctuation et l'intonation du discours d'une personne et insérer des signes de ponctuation appropriés. Nous utiliserons la vidéo d'u2b pour les tests ci-dessous.
Ici, nous avons besoin d'un package pytube, qui peut facilement nous aider à télécharger et extraire l'audio
def youtube_audio(link):
youtube_1 = YouTube(link)
videos = youtube_1.streams.filter(only_audio=True)
name = str(link.split('=')[-1])
out_file = videos[0].download(name)
link = name.split('=')[-1]
new_filename = link+".wav"
print(new_filename)
os.rename(out_file, new_filename)
print(name)
return new_filename,linkAprès avoir obtenu le fichier wav, nous pouvons appliquer la fonction ci-dessus pour en extraire du texte.
Résumé
Le code de cet article est ici
https://drive.google.com/file/d/1FejhGseX_S1Ig_Y5nIPn1OcHN8DLFGIO/view
Il existe de nombreuses opérations qui peuvent être effectuées avec Whisper, vous pouvez l'essayer vous-même en fonction sur le code de cet article.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI