
Maison >Périphériques technologiques >IA >Quatre techniques de validation croisée que vous devez apprendre en apprentissage automatique
Quatre techniques de validation croisée que vous devez apprendre en apprentissage automatique

- 王林avant
- 2023-04-12 16:31:122001parcourir
Introduction
Envisagez de créer un modèle sur un ensemble de données, mais il échoue sur des données invisibles.
Nous ne pouvons pas simplement adapter un modèle à nos données d’entraînement et attendre qu’il fonctionne parfaitement sur des données réelles et invisibles.
Ceci est un exemple de surapprentissage, notre modèle a extrait tous les modèles et bruits dans les données d'entraînement. Pour éviter que cela ne se produise, nous avons besoin d'un moyen de garantir que notre modèle a capturé la majorité des modèles et ne capte pas chaque élément de bruit dans les données (faible biais et faible variance). L'une des nombreuses techniques permettant de résoudre ce problème est la validation croisée.
Comprendre la validation croisée
Supposons que dans un ensemble de données spécifique, nous ayons 1000 enregistrements et que train_test_split() soit exécuté dessus. En supposant que nous disposions de 70 % de données d'entraînement et de 30 % de données de test random_state = 0, ces paramètres donnent une précision de 85 %. Maintenant, si nous définissons random_state = 50, disons que la précision s'améliore à 87 %.
Cela signifie que si nous continuons à choisir des valeurs de précision pour différents random_state, des fluctuations se produiront. Pour éviter cela, une technique appelée validation croisée entre en jeu.
Types de validation croisée
Leave One Out Cross Validation (LOOCV)
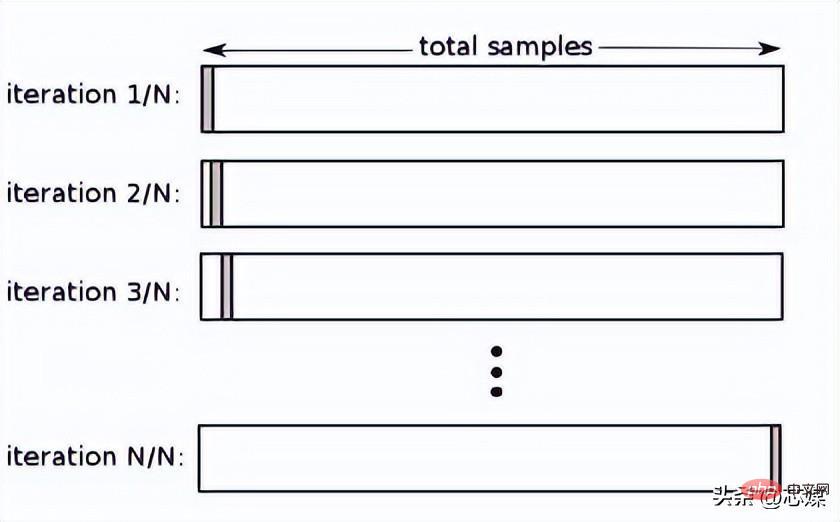
Dans LOOCV, nous sélectionnons 1 point de données comme test et toutes les données restantes seront les données d'entraînement lors de la première itération. Dans la prochaine itération, nous sélectionnerons le point de données suivant comme test et le reste comme données d'entraînement. Nous répéterons cela pour l'ensemble de l'ensemble de données afin que le dernier point de données soit sélectionné comme test lors de l'itération finale.
Normalement, pour calculer le R² de validation croisée pour une procédure itérative de validation croisée, vous calculez les scores R² pour chaque itération et prenez leur moyenne.
Bien que cela conduise à des estimations fiables et impartiales des performances du modèle, sa réalisation est coûteuse en termes de calcul.
2. Validation croisée K-fold

Dans K-fold CV, nous divisons l'ensemble de données en k sous-ensembles (appelés plis), puis nous préparons la formation, mais partons un sous-ensemble (k-1) pour l'évaluation du modèle entraîné.
Supposons que nous ayons 1000 enregistrements et que notre K=5. Cette valeur K signifie que nous avons 5 itérations. Le nombre de points de données pour la première itération à prendre en compte pour les données de test est de 1 000/5 = 200 dès le début. Ensuite, pour la prochaine itération, les 200 points de données suivants seront considérés comme des tests, et ainsi de suite.
Pour calculer la précision globale, nous calculons la précision pour chaque itération puis prenons la moyenne.
La précision minimale que nous pouvons obtenir à partir de ce processus sera la précision la plus faible produite sur toutes les itérations, et de même, la précision maximale sera la précision la plus élevée produite sur toutes les itérations.
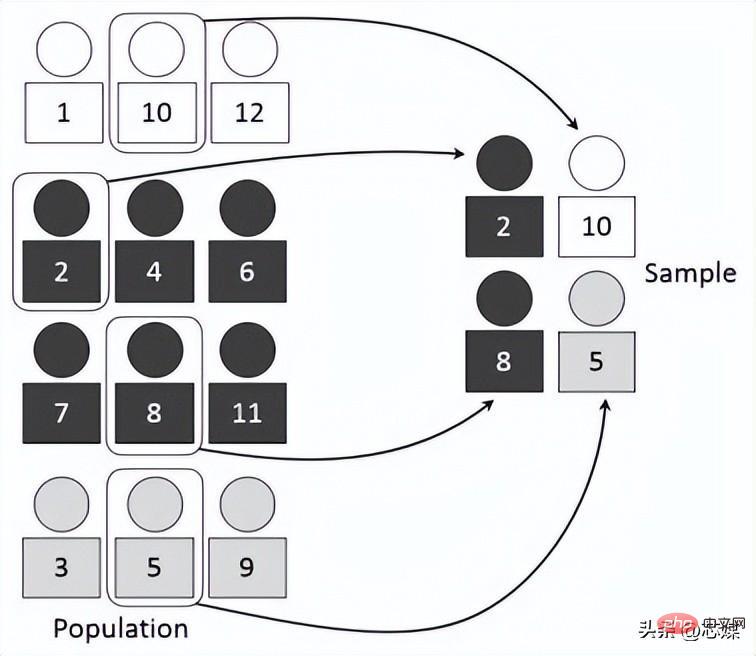
3 Le rapport entre est le même à chaque pli que dans l'ensemble de données complet. Supposons que nous ayons 1 000 enregistrements, qui contiennent 600 oui et 400 non. Par conséquent, dans chaque expérience, cela garantit que les échantillons aléatoires intégrés à la formation et aux tests sont remplis de telle manière qu'au moins certaines instances de chaque classe seront présentes dans les divisions de formation et de test.
4.
Validation croisée des séries chronologiques
Dans le CV des séries chronologiques, il existe une série d'ensembles de tests, chaque ensemble de tests contient une observation. L'ensemble d'entraînement correspondant contient uniquement les observations survenues avant l'observation qui a formé l'ensemble de test. Par conséquent, les observations futures ne peuvent pas être utilisées pour construire des prédictions. La précision de la prédiction est calculée en faisant la moyenne de l'ensemble de test. Ce processus est parfois appelé « évaluation de l'origine de la prévision glissante », car « l'origine » sur laquelle la prévision est basée est reportée dans le temps.
Conclusion
Dans l'apprentissage automatique, nous ne voulons généralement pas de l'algorithme ou du modèle qui fonctionne le mieux sur l'ensemble d'entraînement. Au lieu de cela, nous voulons un modèle qui fonctionne bien sur l'ensemble de test et un modèle qui fonctionne systématiquement bien compte tenu des nouvelles données d'entrée. La validation croisée est une étape critique pour garantir que nous pouvons identifier de tels algorithmes ou modèles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI