
Maison >développement back-end >Tutoriel Python >Techniques d'accélération parallèle simples et faciles à utiliser en Python
Techniques d'accélération parallèle simples et faciles à utiliser en Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-12 14:25:151821parcourir
1. Introduction

Lorsque nous utilisons Python quotidiennement pour effectuer diverses tâches de calcul et de traitement de données, si nous voulons obtenir des effets d'accélération de calcul évidents, le moyen le plus simple et le plus clair est de trouver un moyen d'exécuter les tâches sur un seul process par défaut, étendu pour utiliser une exécution multi-processus ou multi-thread.
Pour ceux d'entre nous qui sont engagés dans l'analyse de données, il est particulièrement important de réaliser des opérations d'accélération équivalentes de la manière la plus simple, afin d'éviter de passer trop de temps à écrire des programmes. Dans l'article d'aujourd'hui, M. Fei, je vais vous apprendre à utiliser les fonctions pertinentes de joblib, une bibliothèque très simple et facile à utiliser, pour obtenir rapidement des effets d'accélération du calcul parallèle.
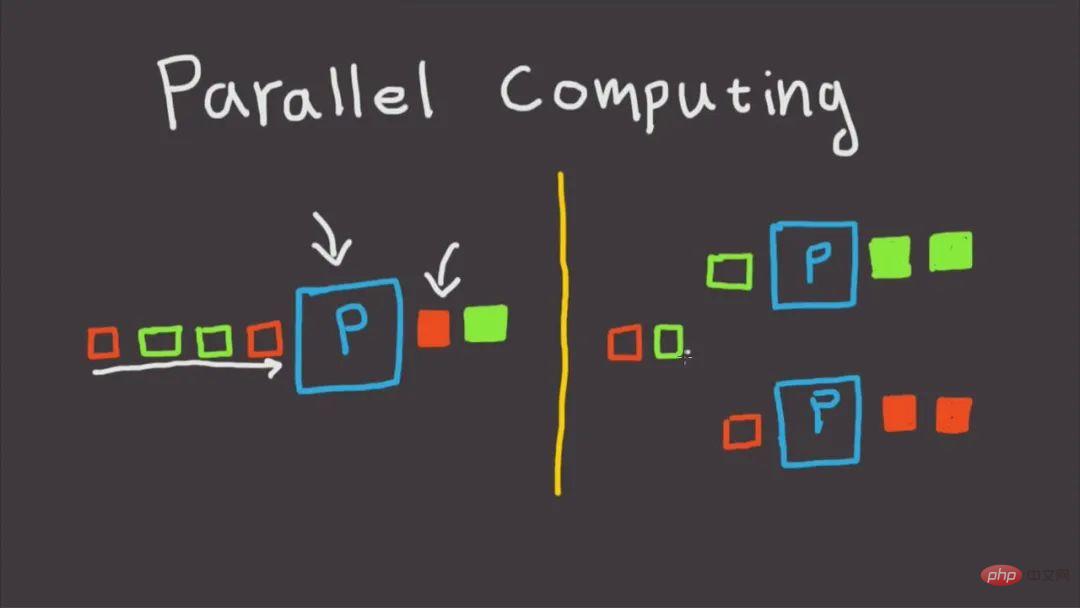
2. Utiliser joblib pour le calcul parallèle
En tant que bibliothèque Python tierce largement utilisée (par exemple, joblib est largement utilisée dans le cadre du projet scikit-learn pour l'accélération parallèle de nombreux algorithmes d'apprentissage automatique), nous pouvons utilisez pip install joblib pour l'installer. Une fois l'installation terminée, apprenons les méthodes courantes de calcul parallèle dans joblib :
2.1 Utiliser Parallèle et retardé pour l'accélération parallèle
Pour réaliser le calcul parallèle dans joblib, il vous suffit d'utiliser son Parallèle et retardé Cette méthode est très simple et pratique à utiliser. Démontrons-la directement avec un petit exemple :
L'idée dejoblib pour implémenter le calcul parallèle est de combiner un ensemble de sous-tâches de calcul série générées via des boucles dans un de manière multi-processus ou multi-thread, et tout ce que nous avons à faire pour les tâches informatiques personnalisées est de les encapsuler sous forme de fonctions, par exemple :
import time def task_demo1(): time.sleep(1) return time.time()
Il nous suffit ensuite de définir les paramètres pertinents pour Parallel(). comme le formulaire suivant, et connect Bouclez le processus de dérivation de liste de création de sous-tâches, dans lequel delay() est utilisé pour envelopper la fonction de tâche personnalisée, puisconnected() est utilisé pour transmettre les paramètres requis par la fonction de tâche. Le paramètre est utilisé pour définir le nombre de travailleurs pour exécuter des tâches parallèles en même temps, donc dans cet exemple, vous pouvez voir que la barre de progression augmente par groupes de 4, et vous pouvez voir que la surcharge de temps finale atteint également le parallèle effet d'accélération :
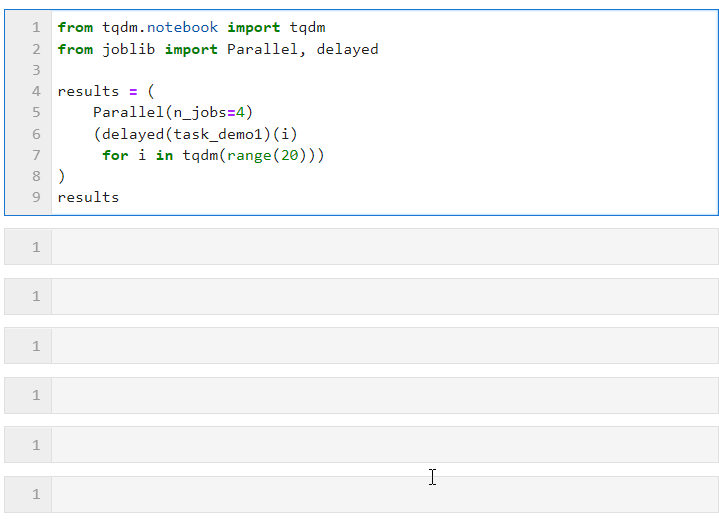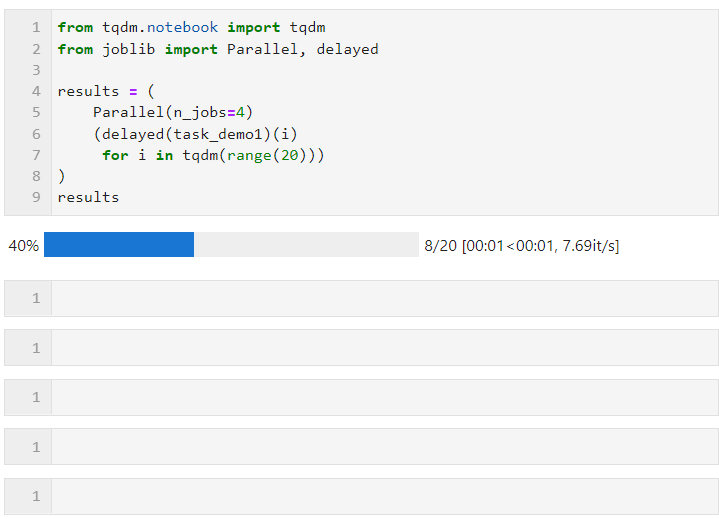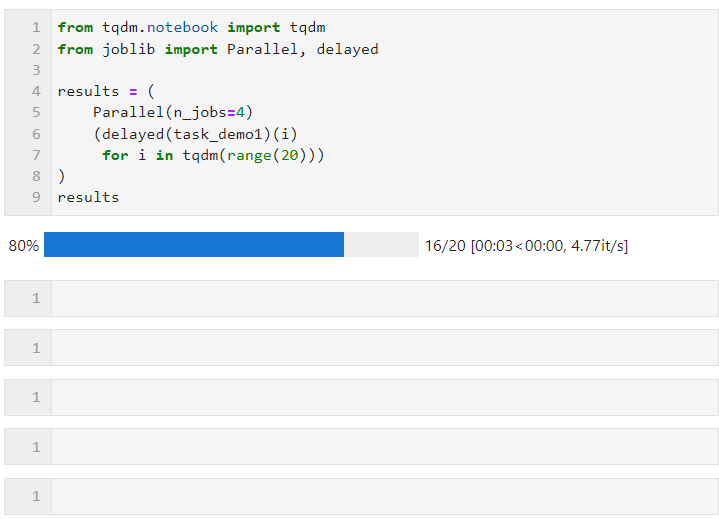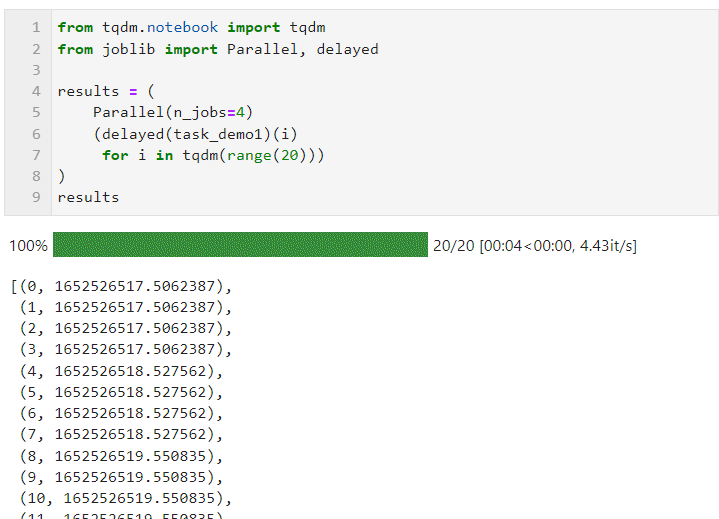
La situation spécifique peut être parallèle (en fonction de la tâche informatique et du nombre de cœurs de processeur de la machine). Ajustez les paramètres. Les paramètres de base sont :
- backend : est utilisé pour définir le mode parallèle. . Le mode multi-processus a deux options : « loky » (plus stable) et « multiprocessing », et le mode multi-threading a les options « threading ». La valeur par défaut est « loky ».
- n_jobs : Utilisé pour définir le nombre de travailleurs pour exécuter des tâches parallèles en même temps. Lorsque le mode parallèle est multi-processus, n_jobs peut être configuré en fonction du nombre de cœurs logiques du processeur de la machine s'il dépasse. le nombre, cela équivaut à activer tous les cœurs. Vous pouvez également le définir sur -1 pour activer rapidement tous les cœurs logiques. Si vous ne souhaitez pas que toutes les ressources du processeur soient occupées par des tâches parallèles, vous pouvez définir un nombre négatif plus petit. conservez les cœurs inactifs appropriés. Par exemple, définissez-le sur -2 pour activer tous les cœurs -1 cœur. Réglez sur -3 pour activer tous les cœurs - 2 cœurs.
Par exemple, dans l'exemple suivant, sur ma machine à 8 cœurs logiques, deux cœurs sont réservés au calcul parallèle :
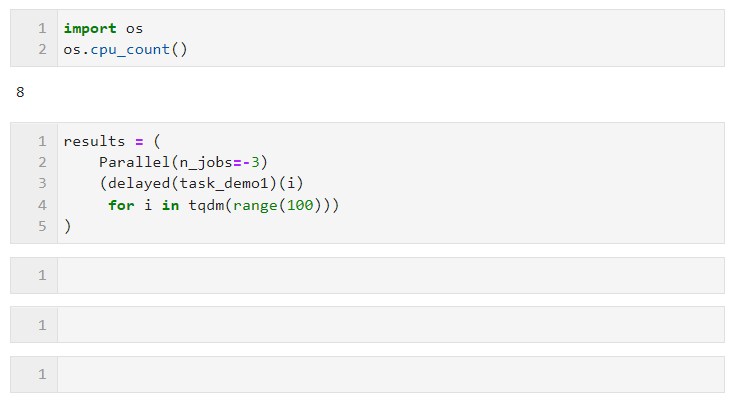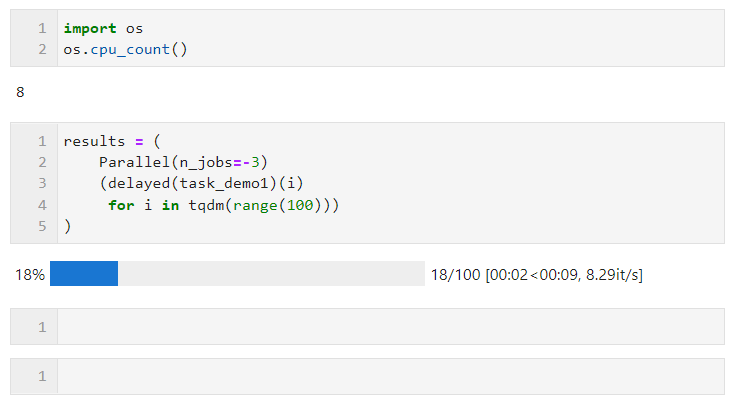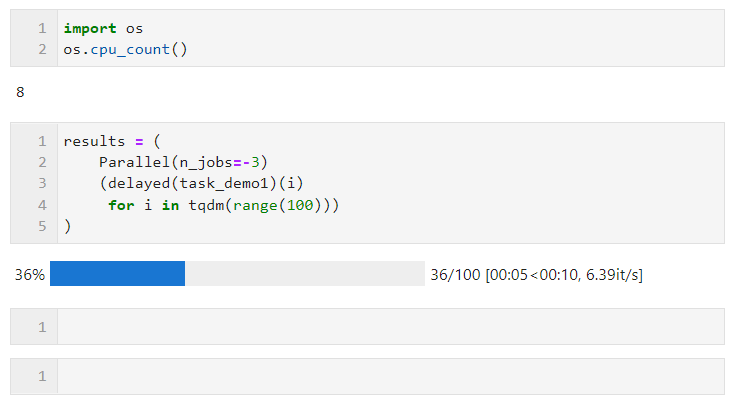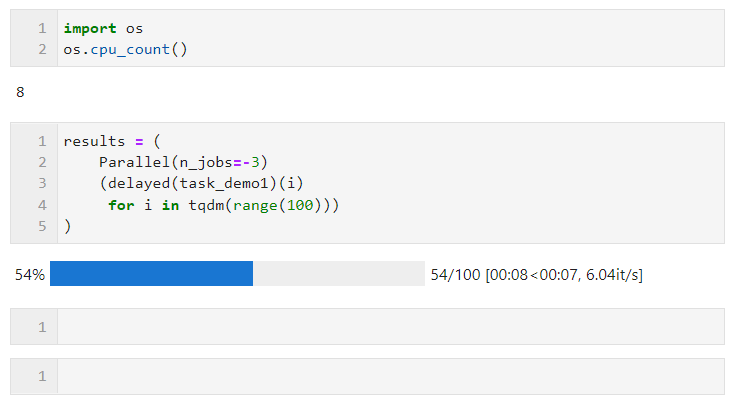
Concernant le choix de la méthode parallèle, dû à l'interpréteur global en multi-threading en Python Restrictions de verrouillage : si votre tâche nécessite beaucoup de calculs, il est recommandé d'utiliser la méthode multi-processus par défaut pour l'accélération. Si votre tâche est gourmande en E/S, comme la lecture et l'écriture de fichiers, les requêtes réseau, etc., le multithreading est préférable. manière et peut définir n_jobs sur une valeur élevée. À titre d'exemple simple, vous pouvez voir que grâce au parallélisme multithread, nous avons complété 1 000 requêtes en 5 secondes, ce qui est beaucoup plus rapide que les 17 secondes monothread pour 100 requêtes (cet exemple). À titre de référence seulement, veuillez ne pas visiter les sites Web d'autres personnes trop fréquemment lorsque vous apprenez et essayez) :
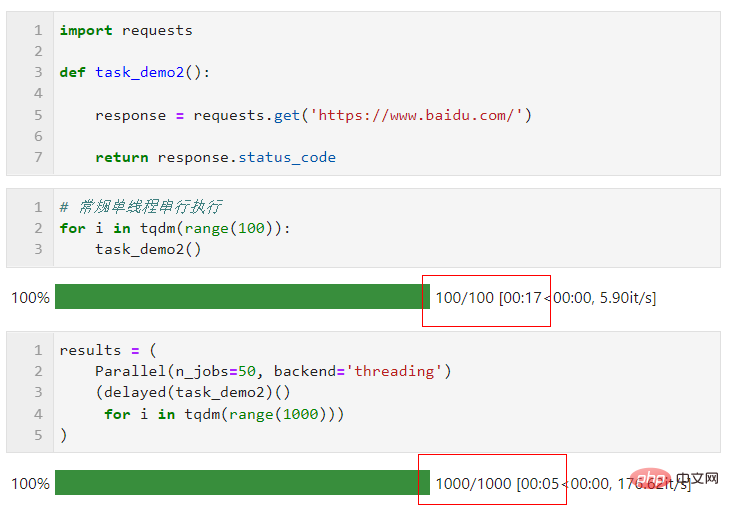
Vous pouvez faire bon usage de joblib pour accélérer votre travail quotidien en fonction de vos tâches réelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!