
Maison >Périphériques technologiques >IA >Réseau contradictoire génératif à convolution profonde en pratique
Réseau contradictoire génératif à convolution profonde en pratique

- 王林avant
- 2023-04-12 14:22:12933parcourir
Traducteur | Zhu Xianzhong
Critique | Sun Shujuan

Red Vineyard (Auteur : Vincent van Gogh)
Selon le rapport du « New York Times », 90 % de l'énergie des centres de données est gaspillée. c'est parce que l'entreprise La plupart des données collectées ne sont jamais analysées ou utilisées sous quelque forme que ce soit. Plus précisément, cela s’appelle « Dark Data ».
Les « données sombres » font référence aux données obtenues via diverses opérations de réseau informatique mais qui ne sont en aucun cas utilisées pour obtenir des informations ou prendre des décisions. La capacité d'une organisation à collecter des données peut dépasser son débit d'analyse. Dans certains cas, les organisations peuvent même ne pas savoir que des données sont collectées. IBM estime qu'environ 90 % des données générées par les capteurs et la conversion analogique-numérique ne sont jamais utilisées. — Définition Wikipédia des « données sombres »
Du point de vue de l'apprentissage automatique, l'une des principales raisons pour lesquelles ces données ne sont pas utiles pour tirer des informations est le manque d'étiquettes. Cela rend les algorithmes d’apprentissage non supervisés très attractifs pour exploiter le potentiel de ces données.
Generative Adversarial Network
En 2014, Ian Goodfello et al. ont proposé une nouvelle méthode pour estimer les modèles génératifs à travers un processus contradictoire. Cela implique la formation simultanée de deux modèles indépendants : un modèle générateur qui tente de modéliser la distribution des données et un discriminateur qui tente de classer l'entrée comme données d'entraînement ou fausses données via le générateur.
Cet article pose une étape très importante dans le domaine de l'apprentissage automatique moderne et ouvre une nouvelle voie pour l'apprentissage non supervisé. En 2015, l'article GAN à convolution profonde publié par Radford et al a réussi à générer des images 2D en appliquant les principes des réseaux convolutifs, continuant ainsi à s'appuyer sur cette idée dans l'article. À travers cet article, j'ai essayé d'expliquer les composants clés abordés dans l'article ci-dessus et de les implémenter à l'aide du framework PyTorch.
Quels sont les aspects accrocheurs du GAN ?
Afin de comprendre l’importance des GAN ou DCGAN (Deep Convolutional Generative Adversarial Networks), comprenons d’abord ce qui les rend si populaires.
1. Étant donné que la plupart des données réelles ne sont pas étiquetées, les propriétés d'apprentissage non supervisées des GAN les rendent idéales pour de tels cas d'utilisation.
2. Les générateurs et les discriminateurs agissent comme de très bons extracteurs de fonctionnalités pour les cas d'utilisation avec des données étiquetées limitées, ou génèrent des données supplémentaires pour améliorer la formation du modèle quadratique, car ils peuvent générer de faux échantillons au lieu d'utiliser des techniques d'augmentation.
3. Les GAN offrent une alternative aux techniques du maximum de vraisemblance. Leur processus d’apprentissage contradictoire et leur fonction de coût non heuristique les rendent très attractifs pour l’apprentissage par renforcement.
4. La recherche sur le GAN est très attractive et ses résultats ont suscité un large débat sur l'impact du ML/DL. Par exemple, Deepfake est une application du GAN qui superpose le visage d'une personne sur une personne cible, ce qui est de nature très controversée car elle a le potentiel d'être utilisée à des fins néfastes.
5. Enfin et surtout, travailler avec ce genre de réseau est cool et toutes les nouvelles recherches dans ce domaine sont fascinantes.
Architecture globale
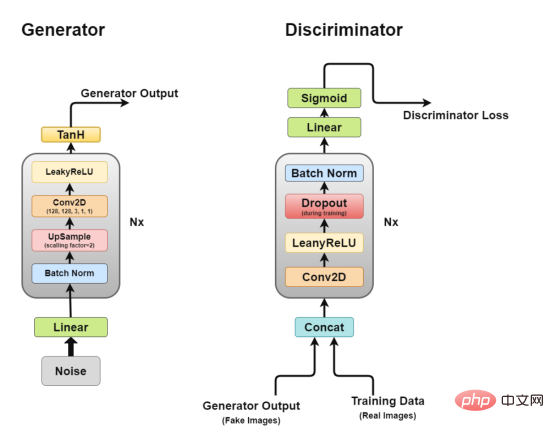 Architecture du GAN à convolution profonde
Architecture du GAN à convolution profonde
Comme nous en avons discuté plus tôt, nous travaillerons via DCGAN, qui tente de mettre en œuvre l'idée de base du GAN, un réseau convolutif pour générer des images réalistes.
DCGAN se compose de deux modèles indépendants : un générateur (G) qui essaie de modéliser des vecteurs de bruit aléatoires en entrée et essaie d'apprendre la distribution des données pour générer de faux échantillons, et un autre discriminateur (D) qui récupère les données d'entraînement (échantillons réels) et les données générées (faux échantillons) et essayez de les classer. La lutte entre ces deux modèles est ce que nous appelons un processus d’entraînement contradictoire, dans lequel la perte de l’une des parties est le gain de l’autre.
Générateur
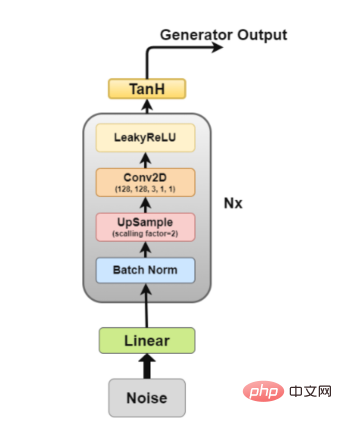 Schéma d'architecture du générateur
Schéma d'architecture du générateur
Le générateur est la partie qui nous intéresse le plus car c'est un générateur qui génère de fausses images pour tenter de tromper le discriminateur.
Maintenant, regardons l'architecture du générateur plus en détail.
- Couche linéaire : le vecteur de bruit est entré dans la couche entièrement connectée et sa sortie est transformée en un tenseur 4D.
- Couche de normalisation par lots : stabilise l'apprentissage en normalisant l'entrée à une moyenne nulle et à une variance unitaire. Cela évite les problèmes de formation tels que la disparition ou l'explosion des gradients et permet aux gradients de circuler à travers le réseau.
- Couche de suréchantillonnage : selon mon interprétation de l'article, il mentionnait l'utilisation du suréchantillonnage, puis l'application d'une simple couche convolutive par-dessus, au lieu d'utiliser une couche de transposition convolutive pour le suréchantillonnage. Mais j'ai vu certaines personnes utiliser la transposition par convolution, donc la stratégie d'application spécifique dépend de vous.
- Couche convolutive 2D : lorsque nous suréchantillonnons une matrice, nous la passons à travers la couche convolutive avec un pas de 1 et utilisons le même remplissage, lui permettant d'apprendre des données suréchantillonnées.
- Couche ReLU : Cet article mentionne l'utilisation de ReLU au lieu de LeakyReLU comme générateur car il permet au modèle de saturer et de couvrir rapidement l'espace colorimétrique de la distribution d'entraînement.
- Couche d'activation TanH : cet article recommande d'utiliser la fonction d'activation TanH pour calculer la sortie du générateur, mais n'explique pas pourquoi. S’il fallait deviner, c’est parce que les propriétés de TanH permettent au modèle de converger plus rapidement.
Parmi eux, les couches 2 à 5 constituent le bloc générateur de base, qui peut être répété N fois pour obtenir la forme d'image de sortie souhaitée.
Ce qui suit est le code clé de la façon dont nous l'implémentons dans PyTorch (pour le code source complet, voir l'adresse https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
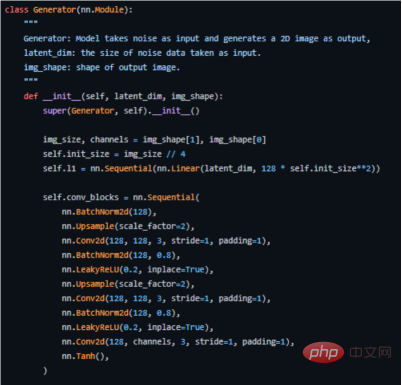
Utilisez le générateur du framework PyTorch pour implémenter le code clé
Discriminateur
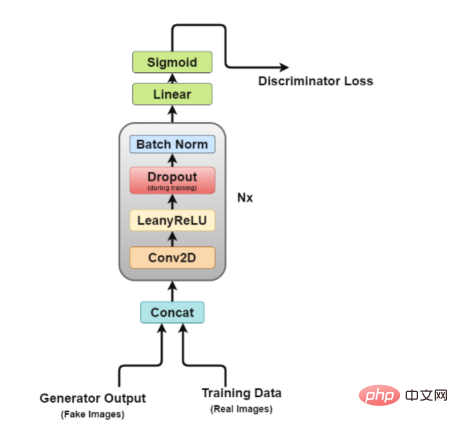
Schéma d'architecture du discriminateur
Il est facile de voir sur la figure que le discriminateur ressemble plus à un réseau de classification d'images, juste faire quelques petits ajustements. Par exemple, au lieu d'utiliser des couches de regroupement pour le sous-échantillonnage, il utilise une couche convolutive spéciale appelée couche convolutive stride, qui lui permet d'apprendre son propre sous-échantillonnage.
Maintenant, examinons de plus près l'architecture du discriminateur.
- Couche Concat : Cette couche combine des images fausses et réelles en un seul lot pour alimenter le discriminateur, mais cela peut également être fait séparément, juste pour obtenir la perte du générateur.
- Couche convolutive : nous utilisons ici la convolution de foulée, ce qui nous permet de sous-échantillonner les images et d'apprendre les filtres en une seule séance d'entraînement.
- Couche LeakyReLU : Comme le mentionne l'article, il a été constaté que Leakyrelus est très utile pour le discriminateur car il permet une formation plus facile par rapport à la fonction de sortie maximale du papier GAN d'origine.
- Couche Dropout : utilisée uniquement pour l'entraînement, permet d'éviter le surajustement. Le modèle a tendance à mémoriser des données d'images réelles, auquel cas la formation peut échouer car le discriminateur ne peut plus être « trompé » par le générateur.
- Couche de normalisation par lots : le document mentionne qu'il applique une normalisation par lots à la fin de chaque bloc discriminateur (sauf le premier). La raison mentionnée dans l'article est que l'application d'une normalisation par lots sur chaque couche peut entraîner des oscillations d'échantillon et une instabilité du modèle.
- Couche linéaire : un calque entièrement connecté qui prend un vecteur remodelé à partir d'un calque de normalisation par lots 2D appliqué.
- Couche d'activation sigmoïde : Puisque nous traitons de la classification binaire de la sortie du discriminateur, le choix logique de la couche Sigmoïde est fait.
Dans cette architecture, les couches 2 à 5 forment le bloc de base du discriminateur, et le calcul peut être répété N fois pour rendre le modèle plus complexe pour chaque donnée d'entraînement.
Voici comment nous l'implémentons dans PyTorch (pour le code source complet, voir l'adresse https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
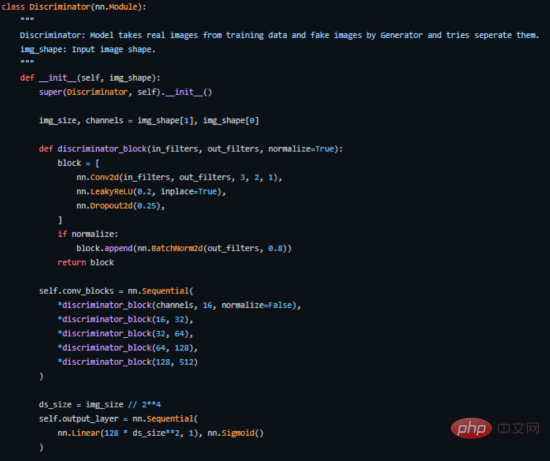
Section de code clé du discriminateur implémentée dans PyTorch
Formation contradictoire
Nous formons le discriminateur (D) pour maximiser la probabilité d'attribuer la bonne étiquette aux échantillons d'entraînement et aux échantillons du générateur (G), qui peut être fait en minimisant log(D(x)). Nous entraînons simultanément G à minimiser log(1 − D(G(z))), où z représente le vecteur de bruit. En d'autres termes, D et G utilisent tous deux la fonction de valeur V (G, D) pour jouer au jeu minimax à deux joueurs suivant :
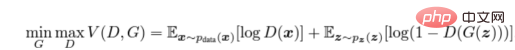
Formule de calcul de la fonction de coût contradictoire
Dans un environnement d'application pratique, l'équation ci-dessus peut ne pas fournir suffisamment de gradients pour que G puisse bien apprendre. Dans les premiers stades de l’apprentissage, lorsque G est médiocre, D peut rejeter les échantillons avec une grande confiance car ils sont significativement différents des données d’entraînement. Dans ce cas, la fonction log(1 − D(G(z))) atteint la saturation. Au lieu d'entraîner G pour minimiser log(1 − D(G(z))), nous entraînons G pour maximiser logD(G(z)). Cette fonction objectif génère les mêmes points fixes pour G et D dynamiques, mais fournit des calculs de gradient plus solides au début de l'apprentissage. ——article arxiv
Étant donné que nous entraînons deux modèles en même temps, cela peut être délicat, et les GAN sont notoirement difficiles à entraîner, l'un des problèmes connus dont nous discuterons plus tard est appelé effondrement du mode modèles .
Le document recommande d'utiliser l'optimiseur Adam avec un taux d'apprentissage de 0,0002. Un taux d'apprentissage aussi faible indique que les GAN ont tendance à diverger très rapidement. Il utilise également un élan de premier et deuxième ordre avec des valeurs de 0,5 et 0,999 pour accélérer davantage l'entraînement. Le modèle est initialisé avec une distribution pondérée normale avec une moyenne de zéro et un écart type de 0,02.
Ce qui suit montre comment nous implémentons une boucle de formation pour cela (le code source complet est disponible sur https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
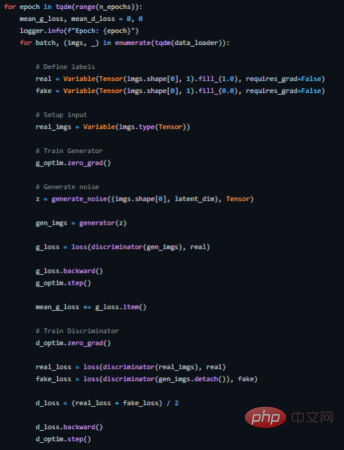
Boucle de formation du DCGAN
Mode Collapse
Idéalement, nous voulons que le générateur produise une variété de sorties. Par exemple, s'il génère des visages, il doit générer un nouveau visage pour chaque entrée aléatoire. Cependant, si le générateur produit une sortie suffisamment plausible pour tromper le discriminateur, il peut produire la même sortie encore et encore.
Finalement, le générateur suroptimisera un seul discriminateur et effectuera une rotation entre un petit ensemble de sorties, une situation appelée « effondrement de mode ».
Les méthodes suivantes peuvent être utilisées pour corriger la situation.
- Perte de Wasserstein : la perte de Wasserstein atténue l'effondrement du mode en vous permettant d'entraîner le discriminateur à l'optimalité sans vous soucier de la disparition des gradients. Si le discriminateur ne reste pas bloqué sur un minimum local, il apprendra à rejeter la sortie stable du générateur. Les générateurs doivent donc essayer de nouvelles choses.
- GAN déroulés : les GAN déroulés utilisent une fonction de perte de générateur qui contient non seulement la classification du discriminateur actuel, mais également la sortie des futures versions du discriminateur. Par conséquent, le générateur ne peut pas être sur-optimisé pour un seul discriminateur.
Applications
- Changeur de style : les applications de retouche de visage font fureur en ce moment. Parmi eux, le vieillissement du visage, les pleurs et la déformation du visage des célébrités ne sont que quelques-unes des applications devenues très populaires sur les réseaux sociaux.
- Jeux vidéo : la génération de textures d'objets 3D et la génération de scènes basées sur des images ne sont que quelques-unes des applications qui aident l'industrie du jeu vidéo à développer plus rapidement des jeux plus importants.
- Industrie cinématographique : les CGI (images générées par ordinateur) sont devenues une partie importante des films modèles, et grâce au potentiel apporté par les GAN, les cinéastes peuvent désormais rêver plus grand que jamais.
- Génération de parole : certaines entreprises utilisent les GAN pour améliorer les applications de synthèse vocale en les utilisant pour générer une parole plus réaliste.
- Restauration d'images : utilisez les GAN pour débruiter et restaurer les images endommagées, coloriser les images historiques et améliorer les anciennes vidéos en générant des images manquantes pour augmenter les fréquences d'images.
Conclusion
En bref, l'article sur le GAN et le DCGAN mentionné ci-dessus est tout simplement un article historique, car il ouvre une nouvelle voie dans l'apprentissage non supervisé. La méthode de formation contradictoire qui y est proposée fournit une nouvelle méthode pour former des modèles qui simulent étroitement le processus d'apprentissage du monde réel. Il sera donc très intéressant de voir comment ce domaine évolue.
Enfin, vous pouvez trouver le code source complet d'implémentation de l'exemple de projet dans cet article sur mon Dépôt de code source GitHub.
Présentation du traducteur
Zhu Xianzhong, rédacteur en chef de la communauté 51CTO, professeur d'informatique dans une université de Weifang et vétéran de l'industrie de la programmation indépendante.
Titre original : Implementing Deep Convolutional GAN, auteur : Akash Agnihotri
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI