
Maison > Article > Périphériques technologiques > Comment allons-nous mener les recherches d’informations à l’avenir ?
Comment allons-nous mener les recherches d’informations à l’avenir ?

- WBOYavant
- 2023-04-12 14:10:071605parcourir
Invité | Organisé par Dou Zhicheng
| Organisé par Zhang Feng
| Xu Jiecheng
Les moteurs de recherche existent depuis plus de 20 ans, et leur forme et leur structure n'ont pas beaucoup changé. Avec le développement continu de la technologie Internet, l'environnement de recherche à l'avenir deviendra plus complexe et diversifié, et la manière dont les utilisateurs obtiennent des informations subira également de nombreux changements. Diverses formes de saisie telles que le langage naturel, la voix et la vision remplaceront inévitablement les simples mots-clés. Plusieurs sorties de contenu modal telles que les réponses, les connaissances de haut niveau, les résultats d'analyse et le contenu généré remplaceront la simple liste de résultats ; la méthode d'interaction peut également passer d'un seul cycle de récupération à plusieurs cycles d'interaction en langage naturel.
Donc, dans le nouvel environnement de recherche, quelles caractéristiques la future technologie de recherche intelligente présentera-t-elle ? Récemment, lors de la AISummit Global Artificial Intelligence Technology Conference organisée par 51CTO, Dou Zhicheng, doyen adjoint de la Hillhouse School of Artificial Intelligence de l'Université Renmin de Chine, a prononcé un discours d'ouverture - "Nouvelle génération Technologie de recherche intelligente", a partagé avec le public les tendances de développement et les caractéristiques principales de la nouvelle génération de technologie de recherche intelligente, et a également effectué une analyse détaillée de technologies telles que la recherche interactive, multimodale et interprétable et la grande dé-centrée sur les modèles. recherche indexée. Cet article a édité et organisé le contenu du discours de M. Dou Zhicheng, dans l'espoir de vous apporter une nouvelle inspiration :
Les principales caractéristiques de la recherche future
Nous pensons que la recherche future peut avoir au moins ces cinq caractéristiques :
- Conversationnel, les gens et les moteurs de recherche sont un moyen de multiples cycles d'interaction via le langage naturel.
- La personnalisation enverra des résultats différents en fonction des besoins des différents utilisateurs, plutôt que de renvoyer les mêmes résultats à tout le monde à l'emporte-pièce.
- Multimodal, Le contenu renvoyé et la méthode de saisie ne peuvent pas se limiter à l'utilisation de texte comme support ou méthode.
- Riche connaissance, Les informations renvoyées par la recherche ne se présentent pas seulement sous la forme d'une liste de résultats, mais peuvent se présenter sous diverses formes d'affichage, affichées de différentes manières de connaissances et d'entités.
- Déindexation, index inversé ou index dense doivent également de toute urgence apporter de grands changements.
Conversationnel
Le mode couramment utilisé par les moteurs de recherche de nos jours consiste à saisir un ou deux mots dans une case pour effectuer une recherche. L’avenir de la recherche pourrait impliquer que nous interagissions avec les moteurs de recherche de manière conversationnelle.
Dans la méthode de récupération de mots-clés utilisée par les moteurs de recherche traditionnels, nous espérons décrire toutes les informations de base que nous recherchons à l'aide de mots-clés, c'est-à-dire que nous supposons qu'une seule requête peut exprimer pleinement et précisément le besoin de ces informations. Mais lorsqu’on exprime une information plus complexe, les mots-clés sont en réalité difficiles à répondre aux besoins. La recherche conversationnelle peut exprimer pleinement les besoins d'information à travers plusieurs cycles d'interaction, ce qui est plus conforme à la méthode progressive d'interaction d'informations entre les personnes lors de la communication.
Si vous souhaitez réaliser ce type de recherche interactive, cela posera de grands défis au système ou à l'algorithme. Il est nécessaire que le moteur de recherche comprenne avec précision l'intention de l'utilisateur à partir de plusieurs cycles d'interaction en langage naturel, et au final. en même temps, il doit également comprendre l'intention de l'utilisateur. Faire correspondre l'intention avec les informations souhaitées par l'utilisateur.
Par rapport à la recherche par mot-clé traditionnelle, la recherche conversationnelle nécessite une compréhension plus complexe des requêtes (par exemple, elle doit résoudre des problèmes tels que les omissions et les coréférences dans la requête actuelle) pour restaurer la véritable intention de recherche de l'utilisateur. Le moyen le plus simple consiste à regrouper toutes les requêtes historiques et à les coder à l'aide d'un modèle de langage pré-entraîné.
Bien que la méthode de dialogue d'épissage simple soit simple, elle peut introduire du bruit. Toutes les requêtes historiques ne sont pas utiles pour comprendre la requête actuelle, nous sélectionnons donc uniquement le contexte qui en dépend, ce qui peut également résoudre le problème de longueur. .
Modèle de récupération conversationnelle COTED
Sur la base des idées ci-dessus, nous avons proposé le modèle de récupération conversationnelle dense COTED, qui comprend principalement les trois parties suivantes :
1 En identifiant les dépendances dans les requêtes conversationnelles, nous pouvons supprimer le bruit. dans les conversations pour mieux prédire l’intention de l’utilisateur.
2. L'amélioration des données (imitant diverses situations de bruit) et la fonction de perte de débruitage basée sur l'apprentissage contrastif permettent efficacement au modèle d'apprendre à ignorer le contexte non pertinent et de le combiner avec la fonction de perte de correspondance finale pour effectuer un apprentissage multitâche.
3. Réduisez la difficulté d'apprentissage de l'apprentissage multitâche du modèle grâce à l'apprentissage de cours et, en fin de compte, améliorez les performances du modèle.
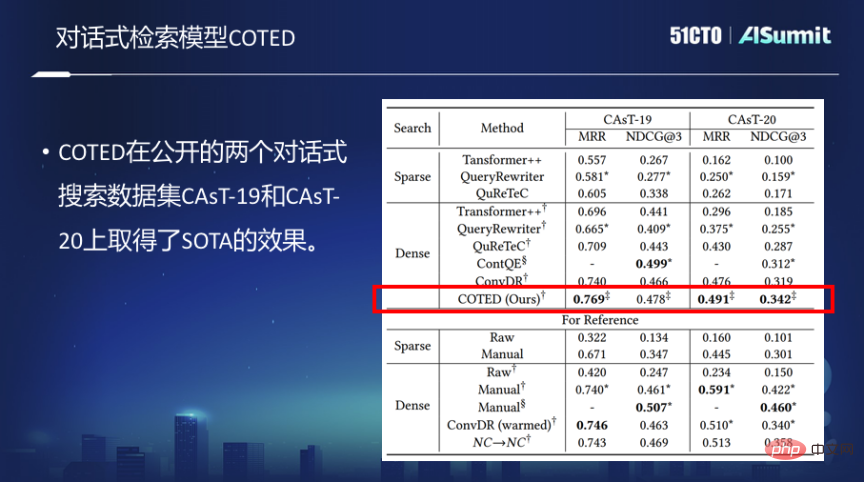
Cependant, les données suffisantes pour la formation du modèle de recherche conversationnelle sont en réalité très limitées. Dans le cas d'un nombre limité d'échantillons, la formation du modèle de recherche conversationnelle est très difficile.
Comment résoudre ce problème ? Le point de départ est de savoir si les journaux des moteurs de recherche peuvent être migrés pour la formation des moteurs de recherche conversationnels. Sur la base de cette idée, les journaux de recherche Web à grande échelle sont convertis en journaux de recherche conversationnelle, puis un modèle de recherche conversationnelle est formé sur les données converties. Mais cette méthode s'accompagne également de deux problèmes évidents :
Premièrement, la recherche Web traditionnelle utilise la recherche par mots clés. La recherche conversationnelle est une méthode de conversation en langage naturel. Les formulaires de requête sont différents et ne peuvent pas être utilisés. Deuxièmement, il y a beaucoup de bruit dans la requête elle-même et les données utilisateur contenues dans le journal de recherche doivent être nettoyées, filtrées et converties avant de pouvoir être utilisées dans la recherche conversationnelle.
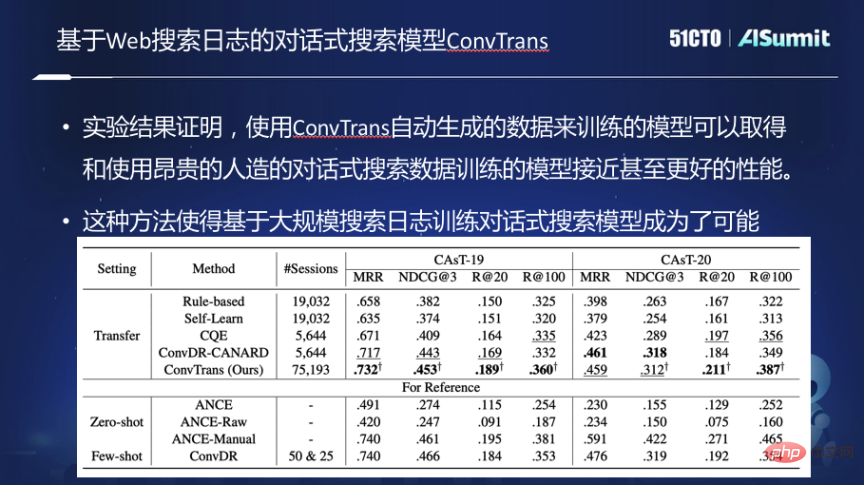
Modèle de formation à la recherche conversationnelle ConvTrans
Afin de résoudre ces problèmes, nous avons créé un modèle de formation à la recherche conversationnelle ConvTrans et implémenté les fonctions suivantes.
Premièrement, les journaux des moteurs de recherche Web traditionnels sont organisés dans un graphique, et le graphique est construit en établissant des connexions entre requêtes et requêtes, requêtes et documents. Sur la base du graphique, un modèle de réécriture de requête en deux étapes basé sur T5 est utilisé pour réécrire une requête par mot-clé sous la forme d'une question. Après la réécriture, chaque requête du graphique utilisera le langage naturel pour exprimer la nouvelle requête, puis concevra un algorithme d'échantillonnage pour effectuer une marche aléatoire sur le graphique afin de générer une session de conversation, puis entraînera le modèle de conversation sur la base de ces données.
Les expériences montrent que les modèles de recherche conversationnelle entraînés avec ces données d'entraînement générées automatiquement peuvent obtenir le même effet que l'utilisation de données artificielles ou étiquetées manuellement coûteuses, et à mesure que l'échelle des données d'entraînement générées automatiquement augmente, les performances continueront de s'améliorer. Cette approche permet de former des modèles de recherche conversationnelle basés sur des journaux de recherche à grande échelle.
Bien que le modèle de recherche conversationnelle ait fait un grand pas en avant dans la recherche, cette méthode conversationnelle est toujours passive. Les moteurs de recherche ont toujours accepté passivement les entrées des utilisateurs et ont renvoyé des résultats en fonction des entrées. pour demander aux utilisateurs ce qu'ils recherchent. Mais dans le processus de communication entre les gens, lorsqu'on vous pose une question, vous prenez parfois l'initiative de poser quelques questions pour obtenir des éclaircissements.
Par exemple, dans la recherche Bing, si la requête est « Maux de tête », ce sera un mal de tête. Il vous demandera « Que voulez-vous savoir sur cette maladie » « Que voulez-vous savoir sur cette maladie », comme ses symptômes, son traitement, son diagnostic, ses causes ou ses déclencheurs. Parce que Headaches lui-même est une requête très large, dans ce cas, le système espère clarifier davantage les informations que vous souhaitez trouver.
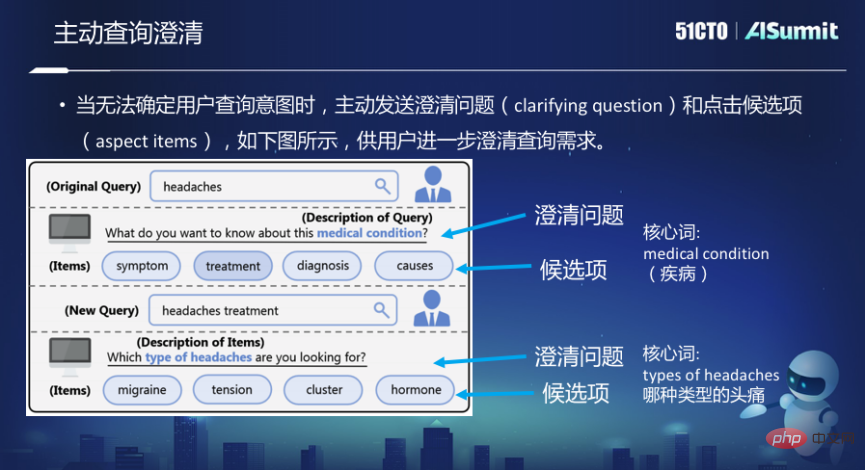
Il y a deux problèmes ici. Le premier est l'élément candidat, quel élément spécifique vous souhaitez que l'utilisateur clarifie. La seconde est de clarifier la question. Le moteur de recherche prend l’initiative de poser cette question à l’utilisateur. Le mot central est la partie la plus cruciale pour clarifier le problème.
Dans cet aspect de l'exploration, le premier consiste à générer des candidats à la clarification lorsqu'une requête est donnée via les journaux de requêtes et les bases de connaissances. Deuxièmement, certains mots essentiels de cette question de clarification peuvent être prédits à partir des résultats de recherche basés sur des règles. Dans le même temps, certaines données sont également étiquetées et un modèle supervisé est utilisé pour classer les étiquettes de texte. Troisièmement, formez davantage un modèle génératif de bout en bout basé sur ces données annotées.
Personnalisation
La personnalisation signifie que la recherche future sera centrée sur l'utilisateur. Les moteurs de recherche d'aujourd'hui, quelle que soit la personne qui effectue la recherche, renvoient les mêmes résultats. Cela ne répond pas aux besoins spécifiques d’information des utilisateurs.
Le modèle actuel de recherche personnalisée consiste d'abord à apprendre les connaissances et les informations que l'utilisateur connaît grâce à son historique, puis à effectuer une désambiguïsation d'entité personnalisée sur la requête. Deuxièmement, la correspondance personnalisée est améliorée grâce à des entités de requête sans ambiguïté.
De plus, nous avons également exploré la construction de modèles multi-intérêts des utilisateurs basés sur des catégories de produits. On suppose que les utilisateurs peuvent avoir leurs propres préférences pour certaines marques (spécifications, modèles) dans toutes les catégories, mais cette préférence ne peut pas être établie. simplement déterminé par un ou deux vecteurs qui vont et viennent pour décrire. Un graphique de connaissances doit être construit sur la base de l'historique d'achats de l'utilisateur, et différents intérêts pour différentes catégories doivent être appris grâce au graphique de connaissances, et finalement des résultats de recherche personnalisés plus précis peuvent être poussés.
Vous pouvez également utiliser la même méthode personnalisée pour créer un chatbot. L'idée principale est d'apprendre les intérêts personnalisés et les modèles linguistiques de l'utilisateur à travers les conversations historiques de l'utilisateur, de former un modèle de dialogue personnalisé et d'imiter (agent) le discours de l'utilisateur. .
Multimodalité
De nos jours, les moteurs de recherche ont en fait de nombreuses limitations lors du traitement des informations multimodales. À l’avenir, les informations obtenues par les utilisateurs pourraient non seulement consister en du texte et des pages Web, mais également inclure des images, des vidéos et des informations structurelles plus complexes. Les futurs moteurs de recherche ont donc encore beaucoup de travail à faire pour acquérir des informations multimodales.
Les moteurs de recherche actuels présentent encore de nombreux défauts lorsqu'il s'agit de comprendre ou d'effectuer une récupération multimodale, c'est-à-dire lorsqu'ils donnent une description textuelle et trouvent l'image correspondante. Si des recherches similaires sont migrées vers les téléphones mobiles, les limitations seront encore plus grandes.
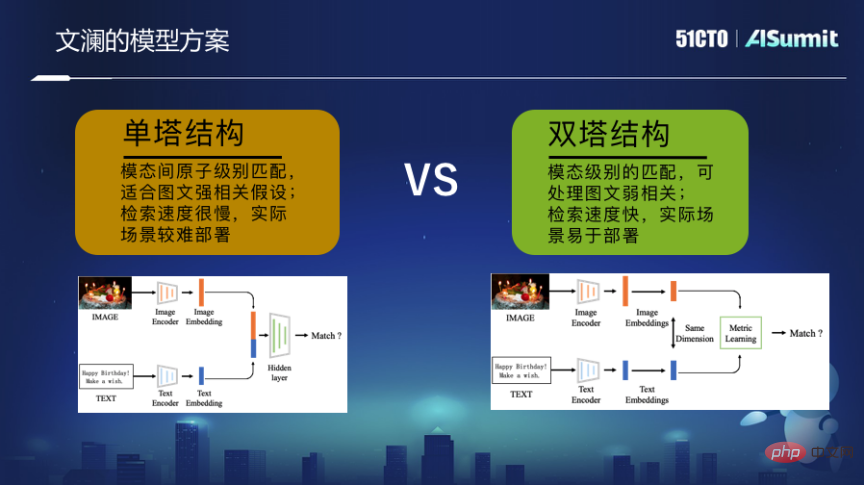
Le soi-disant multimodal signifie que le langage, les images, les images, les vidéos et d'autres modalités sont mappés dans un espace unifié. Cela signifie que vous pouvez utiliser du texte pour trouver des images, des images pour trouver du texte et des images pour trouver. Rechercher des photos, etc.
En réponse, nous avons créé un modèle de pré-formation multimodal à grande échelle - Wenlan. Il se concentre sur la formation basée sur des informations apportées par des corrélations faiblement supervisées d'images Internet massives et de textes proches. En utilisant le mode double tour, la formation finale est un encodeur d'image et un encodeur de texte. Ces deux encodeurs utilisent le processus d'apprentissage d'optimisation de correspondance de bout en bout pour permettre au vecteur de représentation final d'être mappé sur un espace unifié, plutôt que sur l'espace unifié. le grain fin de l'image et le grain fin du texte sont assemblés.
Ce type de capacité de recherche multimodale offre non seulement aux utilisateurs plus d'espace de bout en bout lors de l'utilisation des moteurs de recherche Web, mais peut également prendre en charge de nombreuses applications, telles que la création, qu'il s'agisse de médias sociaux. qu'elle soit culturelle ou créative, vous pouvez l'utiliser pour la soutenir.
Rich Knowledge
Le corps principal des moteurs de recherche actuels est toujours constitué de pages Web, mais à l'avenir, l'unité de traitement des moteurs de recherche n'est pas seulement des pages Web, mais devrait être basée sur des connaissances, y compris les résultats renvoyés devraient également être des connaissances de haut niveau, plutôt qu’une liste page par page. Souvent, les utilisateurs souhaitent réellement utiliser les moteurs de recherche pour répondre à certains besoins d'informations complexes. Ils espèrent donc que les moteurs de recherche les aideront à analyser les résultats, plutôt que de laisser les gens les analyser un par un.
Sur la base de cette idée, nous avons construit un moteur d'analyse, qui équivaut à fournir une analyse de texte approfondie basée sur un moteur de recherche pour aider les utilisateurs à obtenir des connaissances de haut niveau de manière efficace et rapide. Aidez les utilisateurs à lire et à comprendre des documents à grande échelle, et à extraire, extraire et résumer les informations et connaissances clés qu'ils contiennent. Enfin, grâce à un processus d'analyse interactif, les utilisateurs peuvent parcourir et analyser les connaissances de haut niveau extraites, puis les fournir. utilisateurs avec une aide à la décision.
Par exemple, si un utilisateur souhaite retrouver des informations liées à la brume, il peut directement saisir « brume ». Le modèle de connaissances riches est différent des résultats renvoyés par les moteurs de recherche traditionnels. Il peut renvoyer une chronologie pour indiquer à l'utilisateur la répartition des informations sur la brume sur la chronologie, etc. Il résumera également les sous-thèmes sur la brume et ce que les institutions ont . Lesquels, quels personnages sont là. Bien entendu, il peut également fournir une liste détaillée de résultats à la manière d’un moteur de recherche.
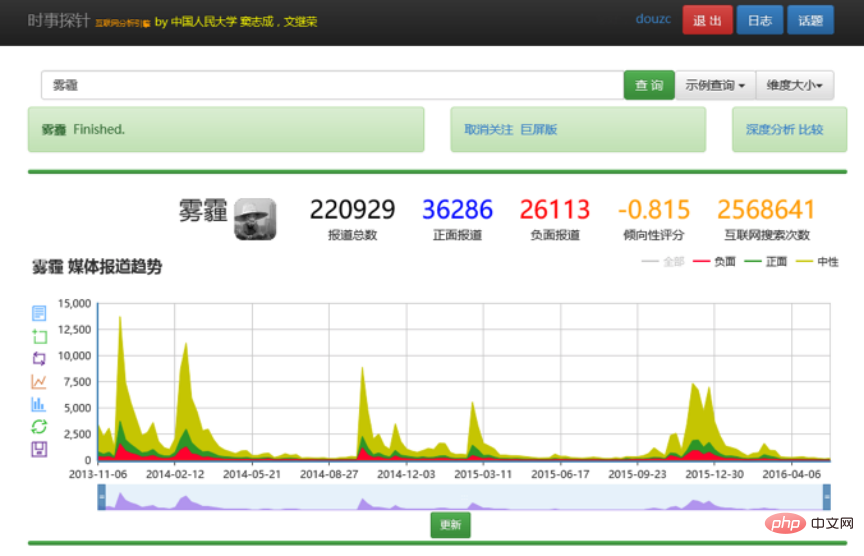
Cette capacité à fournir directement des analyses et des analyses interactives peut mieux aider les utilisateurs à obtenir des informations complexes. Ce qui est proposé aux utilisateurs n'est plus une simple liste de résultats de recherche. Bien sûr, ce type d'analyse interactive des connaissances multidimensionnelles n'est qu'une méthode d'affichage, et d'autres méthodes pourront être utilisées à l'avenir. Par exemple, l'une des choses que nous faisons actuellement consiste à passer de la récupération à la génération de contenu (raisonnable).
Déindexation
De nos jours, les moteurs de recherche adoptent largement une approche par étapes avec l'indexation comme noyau, en explorant le contenu requis à partir d'un grand nombre de pages Web Internet, puis en créant un index, qui est un index inversé ou un index vectoriel dense. . Après la requête de l'utilisateur, un rappel est d'abord effectué, puis un tri affiné est effectué en fonction des résultats du rappel.
Ce modèle présente de nombreux inconvénients, car il doit être divisé en étapes. S'il y a un problème dans une étape, par exemple, le résultat souhaité n'est pas trouvé dans l'étape de rappel, aussi bon soit-il dans la phase de rappel. étape de tri, il ne pourra pas donner de bons résultats.
Dans les futurs moteurs de recherche, cette structure pourrait être rompue. La nouvelle idée est d'utiliser un grand modèle pour remplacer le schéma d'index actuel, et toutes les requêtes peuvent être satisfaites via le modèle. Cela élimine le besoin d'utiliser des index et renvoie directement les résultats souhaités via ce modèle.
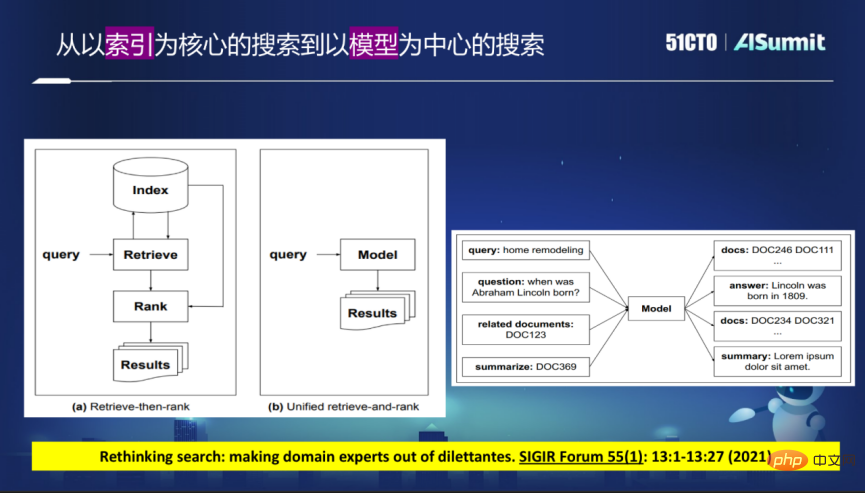
Sur cette base, une liste de résultats peut être directement fournie, ou la réponse demandée par l'utilisateur peut être directement fournie, et la réponse peut même être une image pour mieux intégrer les différentes modalités. Supprimer l'index et renvoyer les résultats directement via le modèle signifie que le modèle peut renvoyer directement ou renvoyer directement l'identifiant du document. L'identifiant du document doit être intégré dans le modèle pour construire une recherche centrée sur le modèle.
Résumé
De nos jours, les moteurs de recherche utilisent largement le modèle simple de mots-clés en entrée et de liste de documents en sortie. Il est déjà difficile de répondre aux besoins complexes des individus en matière d'acquisition d'informations. Le moteur de recherche du futur sera conversationnel, personnalisé, centré sur l’utilisateur et capable de briser les stéréotypes. Dans le même temps, il peut traiter des informations multimodales, traiter des connaissances et restituer des connaissances. En termes d'architecture, à l'avenir, nous allons définitivement briser le modèle centré sur l'index existant qui utilise un index inversé ou un index vectoriel dense, et passer progressivement à un modèle centré sur le modèle.
Présentation de l'invité
Dou Zhicheng, Doyen adjoint de l'École d'intelligence artificielle Hillhouse, Université Renmin de Chine, chef de projet de la direction "Récupération et extraction intelligentes d'informations" de l'Intelligence artificielle Zhiyuan de Pékin Institut de recherche. En 2008, il a rejoint Microsoft Research Asia et s'est engagé dans des travaux liés à la recherche sur Internet, développant une riche expérience dans la recherche et le développement de technologies de recherche d'informations. Il a commencé à enseigner à l'Université Renmin de Chine en 2014. Ses principaux domaines de recherche sont la recherche intelligente d'informations et le traitement du langage naturel. Il a remporté le prix de nomination du meilleur article à la Conférence internationale sur la recherche d'information (SIGIR 2013), le prix du meilleur article à la Conférence asiatique sur la recherche d'information (AIRS 2012) et le prix du meilleur article à la Conférence académique nationale sur la recherche d'information ( CCIR 2018, CCIR 2021). Il est président du comité de programme de SIGIR 2019 (article court), président du comité de programme de la conférence d'évaluation de la recherche d'informations NTCIR-16 et secrétaire général adjoint du comité d'experts en Big Data de la Fédération informatique de Chine. . Au cours des deux dernières années, il s'est principalement concentré sur le classement de recherche personnalisé et diversifié, les modèles de recherche interactifs et conversationnels, les méthodes de pré-formation pour la recherche d'informations, l'interprétabilité des modèles de recherche et de recommandation, la recherche de produits personnalisée, etc.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L’intelligence artificielle ou l’automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI