
Maison >Périphériques technologiques >IA >Exploration et pratique de l'optimisation du classement approximatif de la recherche Meituan
Exploration et pratique de l'optimisation du classement approximatif de la recherche Meituan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-12 11:31:092005parcourir
Auteur : Xiaojiang Suogui, Li Xiang, etc.
Le classement approximatif est un module important du système de recherche et de promotion dans l'industrie. Dans l'exploration et la pratique de l'optimisation de l'effet de classement approximatif, l'équipe de classement de recherche Meituan a optimisé le classement approximatif sous deux aspects : la liaison de classement fin et l'optimisation conjointe de l'effet et des performances sur la base de scénarios commerciaux réels, améliorant ainsi l'effet du classement approximatif.
1. Introduction
Comme nous le savons tous, dans les domaines d'application industrielle à grande échelle tels que la recherche, la recommandation et la publicité, afin d'équilibrer performances et effets, les systèmes de tri adoptent généralement une architecture en cascade [1,2] , comme le montre la figure 1 ci-dessous. En prenant le système de classement de recherche Meituan comme exemple, l'ensemble du classement est divisé en niveaux de tri grossier, tri fin, réarrangement et tri mixte ; le tri grossier se situe entre le rappel et le tri fin, et il est nécessaire de filtrer un élément de cent niveaux ; défini à partir d'un ensemble d'éléments candidats de mille niveaux. Donnez-le à la couche d'aviron fine.

Figure 1 Entonnoir de tri
En regardant le module de classement approximatif du point de vue du lien complet du classement de recherche Meituan, il existe actuellement plusieurs défis dans l'optimisation de la couche de classement approximatif :
- Biais de sélection des échantillons : dans le système de tri en cascade, le tri grossier est loin du lien d'affichage du résultat final, ce qui entraîne une grande différence entre l'espace échantillon d'entraînement hors ligne du modèle de tri grossier et l'espace échantillon à prédire, et il existe un sérieux biais de sélection de l’échantillon.
- Liaison entre le tri grossier et le tri fin : Le tri grossier se situe entre le rappel et le tri fin nécessite plus d'acquisition et d'utilisation d'informations de lien ultérieures pour améliorer l'effet.
- Contraintes de performances : L'ensemble des candidats pour la prédiction de classement grossier en ligne est beaucoup plus élevé que celui du modèle de classement fin. Cependant, l'ensemble du système de recherche actuel a des exigences strictes en matière de performances, ce qui conduit à la nécessité de se concentrer sur la prédiction. performances pour un classement approximatif.
Cet article se concentrera sur les défis ci-dessus pour partager l'exploration et la pratique pertinentes de l'optimisation de la couche de classement approximatif de la recherche Meituan. Parmi eux, nous résoudrons le problème du biais de sélection d'échantillons dans le problème de liaison de classement fin. Cet article est principalement divisé en trois parties : la première partie présentera brièvement l'itinéraire d'évolution de la couche de classement approximatif du classement de recherche Meituan, la deuxième partie présente l'exploration et la pratique connexes de l'optimisation du classement approximatif, dont la première consiste à utiliser les connaissances ; distillation et apprentissage comparatif pour établir un lien entre le tri grossier et le tri grossier pour optimiser l'effet du tri grossier. La deuxième tâche consiste à considérer les performances du tri grossier et l'optimisation des effets du tri grossier. Tous les travaux associés ont été entièrement en ligne. l'effet est significatif ; la dernière partie est le résumé et les perspectives. J'espère que le contenu est utile et inspirant pour tout le monde.
2. Itinéraire d'évolution du classement approximatif
L'évolution de la technologie de classement approximatif de Meituan Search est divisée en les étapes suivantes :
- 2016 : basée sur la pertinence, la qualité et le taux de conversion. pondération linéaire. Cette méthode est simple mais la capacité d'expression des caractéristiques est faible. Les poids sont déterminés manuellement et il y a beaucoup de marge d'amélioration dans l'effet de tri.
- 2017 : Classement prédictif ponctuel utilisant un modèle LR simple basé sur l'apprentissage automatique.
- 2018 : En utilisant le modèle à deux tours basé sur le produit interne vectoriel, les mots de requête, les utilisateurs, les fonctionnalités contextuelles et les fonctionnalités du commerçant sont saisis respectivement des deux côtés. Après un calcul approfondi du réseau, les vecteurs d'utilisateurs et de mots de requête sont saisis respectivement. générés respectivement et les vecteurs marchands, puis calculez le produit interne pour obtenir les scores estimés pour le tri. Cette méthode permet de calculer et d'enregistrer les vecteurs marchands à l'avance, de sorte que la prédiction en ligne est rapide, mais la capacité de croiser les informations des deux côtés est limitée.
- 2019 : Afin de résoudre le problème selon lequel le modèle à deux tours ne peut pas bien modéliser les fonctionnalités croisées, la sortie du modèle à deux tours est utilisée comme fonctionnalité et fusionnée avec d'autres fonctionnalités croisées via le modèle d’arbre GBDT.
- 2020 à aujourd'hui : En raison de l'amélioration de la puissance de calcul, j'ai commencé à explorer le modèle approximatif de bout en bout NN et à continuer à itérer le modèle NN.
À ce stade, les modèles à gros grains couramment utilisés dans l'industrie comprennent le modèle à deux tours, comme Tencent [3] et iQiyi [4] et le modèle interactif NN, comme Alibaba [1, 2]. Ce qui suit présente principalement le travail d'optimisation connexe de Meituan Search dans le processus de mise à niveau du classement approximatif vers le modèle NN, qui comprend principalement deux parties : l'optimisation de l'effet de classement approximatif et l'optimisation conjointe des effets et des performances.
3. Pratique d'optimisation du tri grossier
Avec de nombreux travaux d'optimisation des effets [5,6] mis en œuvre dans le modèle NN de tri fin de Meituan Search, nous avons également commencé à explorer l'optimisation du modèle NN de tri grossier. Considérant que le tri grossier a des contraintes de performances strictes, il n'est pas applicable de réutiliser directement le travail d'optimisation du tri fin en tri grossier. Ce qui suit présentera l'optimisation de l'effet de liaison du tri fin en migrant les capacités de tri du tri fin vers le tri grossier, ainsi que l'optimisation du compromis entre l'effet et les performances de la recherche automatique basée sur la structure du réseau neuronal.
3.1 Optimisation de l'effet de liaison du tri fin
Le modèle de tri grossier est limité par les contraintes de performance de notation, ce qui fait que la structure du modèle est plus simple que le modèle de tri fin et que le nombre de fonctionnalités est beaucoup plus petit que celui du modèle de tri fin. modèle de tri fin, donc l'effet de tri est pire que l'arrangement fin. Afin de compenser la perte d'effet causée par la structure simple et le peu de fonctionnalités du modèle de classement approximatif, nous avons essayé la méthode de distillation des connaissances [7] pour relier le classement fin afin d'optimiser le classement approximatif.
La distillation des connaissances est une méthode courante dans l'industrie pour simplifier la structure du modèle et minimiser la perte d'effet. Elle adopte un paradigme enseignant-étudiant : un modèle avec une structure complexe et une forte capacité d'apprentissage est utilisé comme modèle d'enseignant, et un modèle avec une structure relativement simple est utilisé comme modèle Étudiant, utilisant le modèle Enseignant pour aider à la formation du modèle Étudiant, transférant ainsi les « connaissances » du modèle Enseignant au modèle Étudiant pour améliorer l'effet de l'Étudiant. modèle. Le diagramme schématique de la distillation en rangées fines et de la distillation en rangées grossières est présenté dans la figure 2 ci-dessous. Le schéma de distillation est divisé en trois types suivants : distillation des résultats en rangées fines, distillation des scores de prédiction des rangées fines et distillation de représentation des caractéristiques. L'expérience pratique de ces schémas de distillation dans le classement approximatif de recherche Meituan sera présentée ci-dessous.

Figure 2 Schéma du tri fin, distillation, tri grossier
3.1.1 Distillation de la liste des résultats du tri fin
Le tri grossier est le pré-module du tri fin, et son objectif est de filtrer dans un premier temps le meilleur qualité L'ensemble des candidats entre dans le classement fin. Du point de vue de la sélection des échantillons de formation, en plus des éléments pour lesquels les comportements réguliers des utilisateurs (cliquez, passez une commande, payez) sont utilisés comme échantillons positifs, et les éléments pour lesquels l'exposition n'a pas été effectuée. Les échantillons positifs et négatifs construits à partir des résultats de tri du modèle de tri fin peuvent non seulement atténuer dans une certaine mesure le biais de sélection des échantillons du modèle de tri grossier, mais également transférer. les capacités de tri du modèle de tri fin au tri grossier. Ce qui suit présentera l'expérience pratique de l'utilisation des résultats du tri fin pour distiller le modèle de tri grossier dans le scénario de recherche Meituan.
Stratégie 1 : Sur la base des échantillons positifs et négatifs renvoyés par les utilisateurs, sélectionnez au hasard un petit nombre d'échantillons non exposés au bas du tri fin pour compléter le tri grossier des échantillons négatifs, comme le montre la figure 3. Ce changement a un Recall@150 hors ligne (Veuillez vous référer à l'annexe pour l'explication de l'indicateur) +5PP et un CTR en ligne +0,1 %.

Figure 3 Exemple négatif de résultat de tri supplémentaire
Stratégie 2 : Un échantillonnage aléatoire est effectué directement dans l'ensemble après un tri fin pour obtenir des échantillons d'entraînement, et la position du tri fin est utilisée comme étiquette pour construire une paire. L'entraînement est effectué comme le montre la figure 4 ci-dessous. Par rapport à la stratégie 1, l'effet hors ligne est Recall@150 +2PP et le CTR en ligne est de +0,06 %.

Figure 4 Trier recto et verso pour former une paire d'échantillons
Stratégie 3 : Sur la base de la sélection de l'ensemble d'échantillons de la stratégie 2, l'étiquette est construite en classifiant les positions de tri affinées, et puis, selon la classification, l'étiquette du fichier construit une paire pour la formation. Par rapport à la stratégie 2, l'effet hors ligne est Recall@150 +3PP et le CTR en ligne est de +0,1 %.
3.1.2 Distillation des scores de prédiction de classement fin
L'utilisation précédente de la distillation des résultats de classement est une manière relativement grossière d'utiliser les informations de classement fines. Sur cette base, nous ajoutons en outre la distillation des scores de prédiction [8] et espérons que le brut. Sortie du modèle de classement Les scores sont alignés autant que possible sur la distribution des scores produite par le modèle de classement fin, comme le montre la figure 5 ci-dessous :

Figure 5 Perte auxiliaire de construction de score de prédiction de classement fin
En termes de mise en œuvre spécifique, nous utilisons un paradigme de distillation en deux étapes pour distiller le modèle de classification grossière basé sur le modèle de classification fine pré-entraîné. La perte de distillation utilise l'erreur quadratique minimale de la sortie du modèle de classification grossière et la classification fine. sortie du modèle et ajoute un paramètre Lambda. Le paramètre Lambda est utilisé pour contrôler l'impact de la perte de distillation sur la perte finale, comme indiqué dans la formule (1). En utilisant la méthode précise de distillation fractionnée, l'effet hors ligne est Recall@150 +5PP et l'effet en ligne est CTR +0,05 %.
3.1.3 Distillation de la représentation des fonctionnalités
L'industrie utilise la distillation des connaissances pour obtenir un classement précis afin de guider la modélisation approximative de la représentation du classement. Il a été vérifié qu'il s'agit d'un moyen efficace d'améliorer l'effet du modèle [7]. l'utilisation de méthodes traditionnelles pour distiller la représentation présente les défauts suivants : le premier est que la relation de tri entre le tri grossier et le tri fin ne peut pas être distillée. Comme mentionné ci-dessus, la distillation du résultat du tri a amélioré les effets à la fois hors ligne et en ligne dans notre scénario ; que l'utilisation traditionnelle de KL en tant que schéma de distillation des connaissances pour la mesure de la représentation, la divergence traite chaque dimension de la représentation indépendamment et ne peut pas distiller efficacement des informations hautement pertinentes et structurées [9]. les stratégies traditionnelles de distillation des connaissances pour la distillation des représentations peuvent ne pas être en mesure de bien capturer ces connaissances structurées.
Nous appliquons une technologie d'apprentissage contrastif au modèle de classement grossier, de sorte que le modèle de classement grossier puisse également distiller la relation d'ordre lors de la distillation de la représentation du modèle de classement fin. Nous utilisons 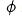 pour représenter le modèle brut et
pour représenter le modèle brut et 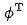 pour représenter le modèle fin. Supposons que q soit une requête dans l'ensemble de données,
pour représenter le modèle fin. Supposons que q soit une requête dans l'ensemble de données, 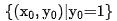 est un exemple positif sous cette requête, et
est un exemple positif sous cette requête, et 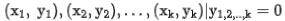 est les k exemples négatifs correspondants sous cette requête.
est les k exemples négatifs correspondants sous cette requête.
Nous saisissons 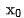 respectivement dans les réseaux de classement grossier et de classement fin pour obtenir leurs représentations correspondantes
respectivement dans les réseaux de classement grossier et de classement fin pour obtenir leurs représentations correspondantes  En même temps, nous saisissons
En même temps, nous saisissons 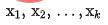 dans le réseau de classement grossier pour obtenir le modèle de classement grossier encodant Le. représentation finale
dans le réseau de classement grossier pour obtenir le modèle de classement grossier encodant Le. représentation finale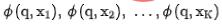 . Pour la sélection de paires d'exemples négatifs pour l'apprentissage comparatif, nous adoptons la solution de la stratégie 3 pour diviser l'ordre du tri fin en bacs. Les paires de représentation du tri fin et du tri grossier dans le même bac sont considérées comme des exemples positifs, et le tri grossier. et le tri fin entre différents bacs sont considérés comme des exemples positifs. La paire de représentations est considérée comme un exemple négatif, puis InfoNCE Loss est utilisé pour optimiser cet objectif :
. Pour la sélection de paires d'exemples négatifs pour l'apprentissage comparatif, nous adoptons la solution de la stratégie 3 pour diviser l'ordre du tri fin en bacs. Les paires de représentation du tri fin et du tri grossier dans le même bac sont considérées comme des exemples positifs, et le tri grossier. et le tri fin entre différents bacs sont considérés comme des exemples positifs. La paire de représentations est considérée comme un exemple négatif, puis InfoNCE Loss est utilisé pour optimiser cet objectif :
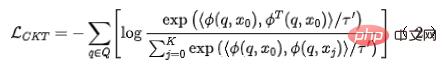
où représente le produit scalaire de deux vecteurs et est le coefficient de température. En analysant les propriétés de la perte InfoNCE, il n'est pas difficile de constater que la formule ci-dessus est essentiellement équivalente à une limite inférieure qui maximise l'information mutuelle entre la représentation grossière et la représentation fine. Par conséquent, cette méthode maximise essentiellement la cohérence entre la représentation fine et la représentation grossière au niveau de l’information mutuelle, et peut distiller plus efficacement des connaissances structurées.

Figure 6 Transfert d'informations raffiné par apprentissage comparatif
Basé sur la formule ci-dessus (1), complétant la distillation de représentation d'apprentissage contrastive Perte, l'effet hors ligne Recall@150 +14PP, CTR en ligne +0,15 %. Pour plus de détails sur les travaux connexes, veuillez vous référer à notre article [10] (en cours de soumission).
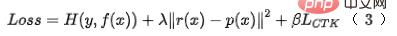
3.2 Optimisation conjointe de l'effet et des performances
Comme mentionné précédemment, l'ensemble des candidats au classement approximatif pour la prédiction en ligne est relativement important compte tenu des contraintes de performances des liens complets du système, le classement approximatif doit prendre en compte l'efficacité de la prédiction. Les travaux mentionnés ci-dessus sont tous basés sur le paradigme du simple DNN + distillation pour l'optimisation, mais il y a deux problèmes :
- Actuellement, il est limité par les performances en ligne et n'utilise que des fonctionnalités simples, sans introduire d'intersections plus riches. il reste encore de la place pour améliorer encore les performances du modèle.
- La distillation avec une structure de modèle grossier fixe perdra l'effet de distillation, ce qui entraînera une solution sous-optimale [11].
Selon notre expérience pratique, l'introduction directe de fonctionnalités croisées dans la couche brute ne peut pas répondre aux exigences de latence en ligne. Par conséquent, afin de résoudre les problèmes ci-dessus, nous avons exploré et mis en œuvre une solution de modélisation de classement approximatif basée sur la recherche d'architecture de réseau neuronal. Cette solution optimise simultanément l'effet et les performances du modèle de classement approximatif et sélectionne la meilleure combinaison de fonctionnalités et le modèle qui répond. les exigences de retard de classement grossier. Structure, le schéma d'architecture global est présenté dans la figure 7 ci-dessous :

Figure 7 Caractéristiques et structure du modèle basées sur le NAS
Sélectionnez Ensuite, nous recherchons l'architecture du réseau neuronal. (NAS) et présentez-le Une brève introduction à ces deux points techniques clés de la modélisation de l'efficacité :
- Recherche d'architecture de réseau neuronal : Comme le montre la figure 7 ci-dessus, nous utilisons une méthode de modélisation basée sur ProxylessNAS [12]. En plus des paramètres de réseau, l'ensemble de la formation du modèle ajoute des paramètres de masques de fonctionnalités et des paramètres d'architecture de réseau, ces paramètres sont différenciables et appriss avec la cible du modèle. Dans la partie sélection des fonctionnalités, nous introduisons un paramètre de masque basé sur la distribution de Bernoulli pour chaque fonctionnalité, voir la formule (4), où le paramètre θ de la distribution de Bernoulli est mis à jour par rétropropagation, et enfin l'importance de chaque fonctionnalité est obtenue. Dans la partie sélection de la structure, la représentation Mixop à couche L est utilisée. Chaque groupe de Mixop comprend N unités structurelles de réseau facultatives. Dans l'expérience, nous avons utilisé des perceptrons multicouches avec différents nombres d'unités neuronales de couche cachée, où N = {1024, 512, 256, 128, 64}, et nous avons également ajouté des unités structurelles avec un numéro d'unité caché de 0 pour sélectionner des réseaux de neurones avec différents nombres de couches.

- Modélisation de l'efficacité : afin de modéliser l'indicateur d'efficacité dans l'objectif du modèle, nous devons utiliser un objectif d'apprentissage différentiable pour représenter la consommation de temps du modèle. La consommation de temps du modèle approximatif est principalement divisée en. la consommation de temps des fonctionnalités et la structure du modèle prennent du temps.
Pour les fonctionnalités chronophages, le délai attendu de chaque fonctionnalité fi peut être modélisé comme indiqué dans la formule (5), où 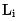 est le retard de chaque fonctionnalité enregistré par le serveur.
est le retard de chaque fonctionnalité enregistré par le serveur.
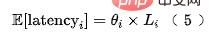
Dans les situations réelles, les fonctionnalités peuvent être divisées en deux catégories. Une partie est la fonctionnalité de transmission transparente en amont, dont le retard provient principalement du délai de transmission en amont ; l'autre type de fonctionnalité provient de l'acquisition locale (lecture de KV) ; Ou calculer), alors le retard de chaque combinaison de fonctionnalités peut être modélisé comme :
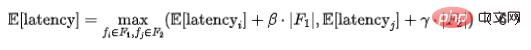
où 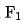 et
et 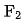 représentent le nombre d'ensembles de fonctionnalités correspondants,
représentent le nombre d'ensembles de fonctionnalités correspondants, 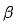 et
et 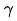 la concurrence d'extraction des fonctionnalités du système modèle.
la concurrence d'extraction des fonctionnalités du système modèle.
Pour la modélisation du retard de la structure du modèle, veuillez vous référer à la partie droite de la figure 7 ci-dessus. Puisque l'exécution de ces Mixops est effectuée séquentiellement, nous pouvons calculer de manière récursive le retard de la structure du modèle et la consommation de temps de l'ensemble du modèle. partie. Il peut être exprimé par la dernière couche de Mixop. Le diagramme schématique est présenté dans la figure 8 ci-dessous :

Figure 8 Diagramme de calcul du retard du modèle
Figure 8 Le côté gauche est un réseau approximatif équipé. avec sélection de l'architecture réseau, où représente le poids de la ème unité neuronale de la ème couche. Sur la droite se trouve un diagramme schématique du calcul du retard du réseau. Par conséquent, la consommation de temps de l'ensemble de la partie prédiction du modèle peut être exprimée par la dernière couche du modèle, comme le montre la formule (7) :
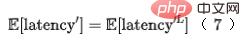
Enfin, nous introduisons l'indice d'efficacité dans le modèle, et le résultat final la perte de formation du modèle est comme le montre la formule (8) ci-dessous, où f représente le réseau de classement fin, 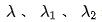 représente le facteur d'équilibre et
représente le facteur d'équilibre et 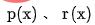 représente respectivement le résultat de notation du classement approximatif et du classement fin.
représente respectivement le résultat de notation du classement approximatif et du classement fin.
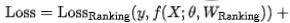

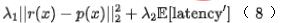
Utilisation de la modélisation de la recherche d'architecture de réseau neuronal pour optimiser conjointement l'effet et les performances de prédiction du modèle de classement approximatif, Rappel hors ligne@150 +11PP, et enfin sans augmenter le délai en ligne, l'indicateur en ligne CTR + 0,12 % ; des travaux détaillés peuvent être trouvés dans [13], qui a été accepté par KDD 2022.
4. Résumé
À partir de 2020, nous avons mis en œuvre le modèle MLP pour la couche de classement grossier grâce à un grand nombre d'optimisations de performances techniques. En 2021, nous continuerons à itérer le modèle de classement approximatif basé sur le MLP. modèle pour améliorer le classement grossier.
Tout d'abord, nous nous sommes inspirés du schéma de distillation couramment utilisé dans l'industrie pour relier le classement fin et optimiser le classement approximatif. Nous avons mené un grand nombre d'expériences à partir de trois niveaux : distillation des résultats du classement fin, distillation des scores de prédiction du classement fin, et distillation de la représentation des fonctionnalités. Sans augmenter le nombre de mises en ligne. En cas de retard, l'effet du modèle de mise en page approximatif est amélioré. Deuxièmement, considérant que les méthodes de distillation traditionnelles ne peuvent pas bien gérer les informations structurées dans les scénarios de tri, nous avons développé un schéma auto-développé pour transférer les informations de tri fin vers un tri grossier basé sur un apprentissage contrastif.
Enfin, nous avons en outre considéré que l'optimisation approximative est essentiellement un compromis entre effet et performance. Nous avons adopté l'idée de modélisation multi-objectifs pour optimiser simultanément l'effet et les performances, et avons mis en œuvre une technologie de recherche automatique pour l'architecture de réseau neuronal. pour résoudre le problème et laisser le modèle sélectionner automatiquement les ensembles de fonctionnalités et les structures de modèle avec la meilleure efficience et efficacité. À l'avenir, nous continuerons à itérer sur la technologie des couches brutes sous les aspects suivants :
- Modélisation multi-objectifs du tri grossier : Le tri grossier actuel est essentiellement un modèle mono-objectif Nous essayons actuellement d'appliquer la modélisation multi-objectifs de la couche de tri fin au tri grossier.
- Allocation dynamique de la puissance de calcul à l'échelle du système liée au tri grossier : Le tri grossier peut contrôler la puissance de calcul de rappel et la puissance de calcul du tri fin Pour différents scénarios, la puissance de calcul requise par le modèle est différente, donc. l'allocation dynamique de puissance de calcul peut réduire la consommation d'énergie de calcul du système sans réduire les effets en ligne. À l'heure actuelle, nous avons obtenu certains effets en ligne dans cet aspect.
5. Annexe
Les indicateurs de tri hors ligne traditionnels sont principalement basés sur les indicateurs NDCG, MAP et AUC. Pour le tri approximatif, son essence est davantage axée sur les tâches de rappel ciblant la sélection d'ensembles, de sorte que l'indice de tri traditionnel n'est pas propice. pour mesurer l'effet itératif du modèle de tri approximatif. Nous faisons référence à l'indicateur de rappel dans [6] comme mesure de l'effet hors ligne du tri grossier, c'est-à-dire en utilisant les résultats du tri fin comme vérité terrain pour mesurer le degré d'alignement des résultats TopK du tri grossier et du tri fin. La définition spécifique de l'indicateur de rappel est la suivante :
La signification physique de cette formule est de mesurer le chevauchement entre les K premiers articles en tri grossier et les K premiers articles en tri fin. l'essence de la sélection approximative d'un ensemble de tri.
6. Introduction de l'auteur
Xiao Jiang, Suo Gui, Li Xiang, Cao Yue, Pei Hao, Xiao Yao, Dayao, Chen Sheng, Yun Sen, Li Qian, etc., tous issus de la plateforme Meituan/algorithme de recommandation de recherche. Département .
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI