
Maison >développement back-end >Tutoriel Python >Permettez-moi de partager un module de visualisation Python populaire, facile et rapide pour démarrer ! !
Permettez-moi de partager un module de visualisation Python populaire, facile et rapide pour démarrer ! !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-12 11:28:151385parcourir

Qu'est-ce qu'Altaïr ?
Altair est appelé une bibliothèque de visualisation statistique car elle peut comprendre de manière globale les données, comprendre et analyser les données via la classification et l'agrégation, la transformation des données, l'interaction des données, la composition graphique, etc., et son processus d'installation est également très simple, directement via la commande pip à exécuter, comme suit :
pip install altair pip install vega_datasets pip install altair_viewer
Si vous utilisez le gestionnaire de paquets conda pour installer le module Altair, le code est le suivant :
conda install -c conda-forge altair vega_datasets
Première expérience avec Altair
Essayons simplement de dessiner un histogramme, créez d'abord un DataFrame Ensemble de données, le code est le suivant :
df = pd.DataFrame({"brand":["iPhone","Xiaomi","HuaWei","Vivo"],
"profit(B)":[200,55,88,60]})Vient ensuite le code pour dessiner l'histogramme :
import altair as alt import pandas as pd import altair_viewer chart = alt.Chart(df).mark_bar().encode(x="brand:N",y="profit(B):Q") # 展示数据,调用display()方法 altair_viewer.display(chart,inline=True)
output
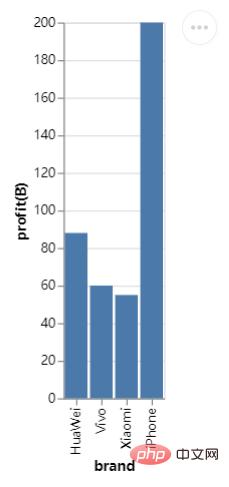
Du point de vue de l'ensemble de la structure syntaxique, utilisez d'abord alt.Chart() pour spécifier les données défini à utiliser, puis utilisez la méthode d'instance mark_*() pour dessiner le style de graphique, et enfin spécifiez les données représentées par l'axe X et l'axe Y. Vous pourriez être curieux de savoir ce que N et Q représentent respectivement. est l'abréviation du type de variable. Remplacer En d'autres termes, le module Altair doit comprendre les types de variables impliqués dans le dessin des graphiques. Ce n'est qu'ainsi que les graphiques dessinés peuvent avoir l'effet que nous attendons.
Le N représente une variable nominale (Nominal). Par exemple, les marques de téléphones portables sont toutes des noms propres, tandis que Q représente une variable numérique (Quantitative), qui peut être divisée en données discrètes (discrètes) et données continues (continues). ), en plus des données de séries chronologiques, l'abréviation est T et les variables ordinales (O), par exemple, la note d'un commerçant lors du processus d'achat en ligne comporte 1 à 5 étoiles.
Enregistrer le graphique
Pour enregistrer le dernier graphique, nous pouvons appeler directement la méthode save() pour enregistrer l'objet et enregistrer l'objet sous forme de fichier HTML. Le code est le suivant :
chart.save("chart.html")Il peut également être enregistré sous. un fichier JSON Du point de vue du code, c'est très simple.
chart.save("chart.json")Bien sûr, nous pouvons également l'enregistrer sous forme de fichier au format image, comme le montre la figure ci-dessous :
Opérations avancées d'Altair
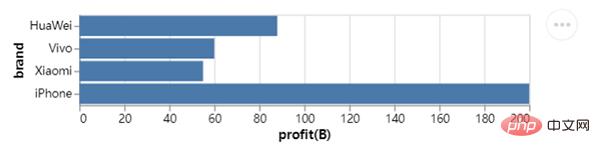
Nous dériverons et développerons davantage en fonction de ce qui précède, par exemple, nous veut dessiner Un graphique à barres horizontales, les données de l'axe X et de l'axe Y sont échangées, le code est le suivant :
chart = alt.Chart(df).mark_bar().encode(x="profit(B):Q", y="brand:N")
chart.save("chart1.html")output
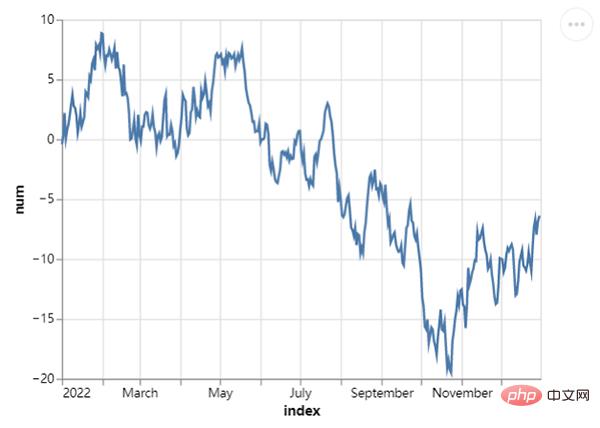
En même temps, on essaie aussi de tracer une ligne chart, appelant le code de la méthode mark_line() Comme suit :
## 创建一组新的数据,以日期为行索引值
np.random.seed(29)
value = np.random.randn(365)
data = np.cumsum(value)
date = pd.date_range(start="20220101", end="20221231")
df = pd.DataFrame({"num": data}, index=date)
line_chart = alt.Chart(df.reset_index()).mark_line().encode(x="index:T", y="num:Q")
line_chart.save("chart2.html")output
Nous pouvons également dessiner un diagramme de Gantt, qui est généralement davantage utilisé dans la gestion de projet. L'axe X ajoute l'heure et la date, tandis que l'axe X ajoute l'heure et la date. L'axe Y représente l'avancement du projet, le code est le suivant :
project = [{"project": "Proj1", "start_time": "2022-01-16", "end_time": "2022-03-20"},
{"project": "Proj2", "start_time": "2022-04-12", "end_time": "2022-11-20"},
......
]
df = alt.Data(values=project)
chart = alt.Chart(df).mark_bar().encode(
alt.X("start_time:T",
axis=alt.Axis(format="%x",
formatType="time",
tickCount=3),
scale=alt.Scale(domain=[alt.DateTime(year=2022, month=1, date=1),
alt.DateTime(year=2022, month=12, date=1)])),
alt.X2("end_time:T"),
alt.Y("project:N", axis=alt.Axis(labelAlign="left",
labelFontSize=15,
labelOffset=0,
labelPadding=50)),
color=alt.Color("project:N", legend=alt.Legend(labelFontSize=12,
symbolOpacity=0.7,
titleFontSize=15)))
chart.save("chart_gantt.html")output
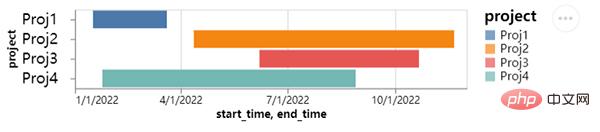
Sur l'image ci-dessus, nous pouvons voir plusieurs projets sur lesquels travaille l'équipe. Chaque projet a un degré d'avancement différent. Bien entendu, la durée des différents projets est également différente. La même chose est très intuitive lorsqu'elle est affichée sur un graphique.
Ensuite, nous dessinons le nuage de points, en appelant la méthode mark_circle(), le code est le suivant :
df = data.cars()
## 筛选出地区是“USA”也就是美国的乘用车数据
df_1 = alt.Chart(df).transform_filter(
alt.datum.Origin == "USA"
)
df = data.cars()
df_1 = alt.Chart(df).transform_filter(
alt.datum.Origin == "USA"
)
chart = df_1.mark_circle().encode(
alt.X("Horsepower:Q"),
alt.Y("Miles_per_Gallon:Q")
)
chart.save("chart_dots.html")output
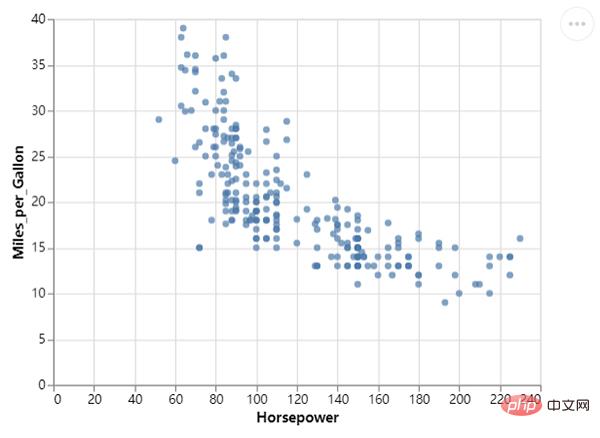
Bien sûr, nous pouvons l'optimiser davantage pour rendre le graphique plus beau, ajouter un peu de couleur , le code est le suivant :
chart = df_1.mark_circle(color=alt.RadialGradient("radial",[alt.GradientStop("white", 0.0),
alt.GradientStop("red", 1.0)]),
size=160).encode(
alt.X("Horsepower:Q", scale=alt.Scale(zero=False,padding=20)),
alt.Y("Miles_per_Gallon:Q", scale=alt.Scale(zero=False,padding=20))
)output
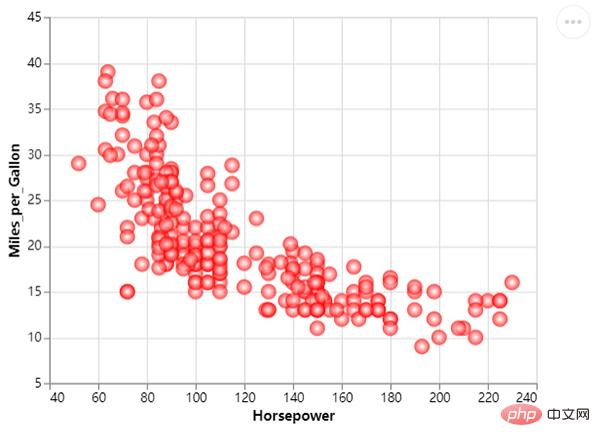
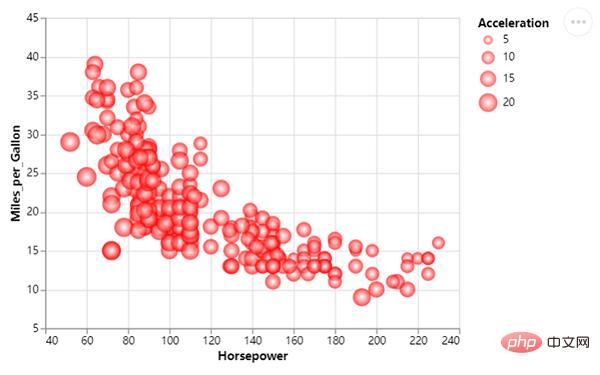
Nous modifions la taille des points de dispersion. Les tailles des différents points de dispersion représentent différentes valeurs, le code est le suivant :
chart = df_1.mark_circle(color=alt.RadialGradient("radial",[alt.GradientStop("white", 0.0),
alt.GradientStop("red", 1.0)]),
size=160).encode(
alt.X("Horsepower:Q", scale=alt.Scale(zero=False, padding=20)),
alt.Y("Miles_per_Gallon:Q", scale=alt.Scale(zero=False, padding=20)),
size="Acceleration:Q"
)output
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!