
Maison >Périphériques technologiques >IA >Pratique de la technologie vocale de Zuoyebang
Pratique de la technologie vocale de Zuoyebang

- 王林avant
- 2023-04-12 08:55:051272parcourir
Invité | Wang Qiangqiang
Compilation | Liu Yuyao
Lors de la précédente conférence mondiale sur la technologie de l'intelligence artificielle AISummit organisée par 51CTO, M. Wang Qiangqiang, chef de l'équipe de discours de Zuoyebang, a présenté au public la « Pratique de la technologie vocale de Zuoyebang ». Le discours d'ouverture a expliqué la pratique de Zuoyebang en matière de technologie vocale sous trois aspects : la synthèse vocale, l'évaluation de la parole et la reconnaissance vocale. Le contenu a couvert la mise en œuvre de bout en bout et l'utilisation efficace des données dans la reconnaissance vocale, la correction des erreurs de prononciation vocale dans des scénarios à forte concurrence. et La différenciation factorielle et la capacité anti-interférence du modèle sont améliorées.
Afin de permettre à davantage d'étudiants intéressés par la technologie vocale de comprendre la tendance de développement actuelle et les pratiques technologiques de pointe de la technologie vocale, le contenu du discours du professeur Wang Qiangqiang est maintenant compilé comme suit, dans l'espoir de vous inspirer.
1. Synthèse vocale
Synthèse vocale à petit volume de données
Pour la technologie de synthèse vocale traditionnelle, si vous souhaitez synthétiser complètement la voix d'une personne, cela prendra dix heures ou plus d'enregistrement. C’est un grand défi pour les flûtes à bec, et peu de personnes peuvent maintenir une bonne prononciation pendant aussi longtemps. Grâce à la technologie de synthèse vocale à faible volume de données, il suffit d'utiliser des dizaines de phrases et quelques minutes de discours prononcées par l'enregistreur pour obtenir un effet de synthèse vocale complet.
La technologie de synthèse vocale pour petits volumes de données est grossièrement divisée en deux catégories. La première catégorie concerne les situations où l'annotation et la parole ne correspondent pas. Il existe deux méthodes de traitement principales : l'une est l'apprentissage auto-supervisé, qui utilise l'apprentissage d'un algorithme auto-supervisé pour obtenir la correspondance entre l'unité de modélisation et l'audio, puis utilise l'annotation d'une personne spécifique sur le corpus est Finetune pour obtenir un meilleur effet de synthèse ; la seconde consiste à identifier le corpus non étiqueté via ASR et à utiliser TTS pour synthétiser des fonctions doubles et des méthodes d'apprentissage doubles afin d'améliorer progressivement l'effet de synthèse de TTS.
Pour la mise en correspondance de texte et d'audio, les principales méthodes de traitement sont également divisées en deux types : l'une consiste à construire un modèle de pré-formation multilingue avec un corpus annoté. L'autre est basé sur cette solution. Plusieurs locuteurs dans la même langue sont pré-entraînés avec des données annotées, et Finetune est effectué en utilisant les données du locuteur cible pour obtenir l'effet souhaité.
Cadre technologique de synthèse vocale
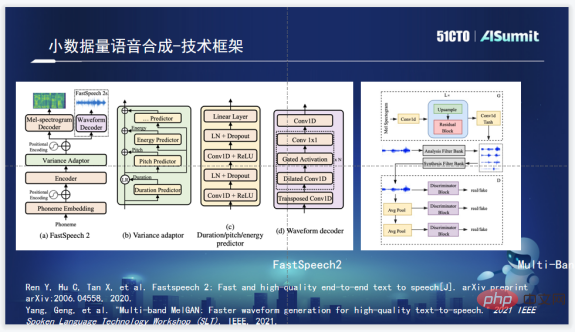
Le cadre technologique de synthèse vocale de Zuoyebang utilise FastSpeech2 dans la partie phonème. FastSpeech2 a le principal avantage d'une vitesse de synthèse rapide. En même temps, FastSpeech2 intègre également Duration, Pitch et Energy Predictor, ce qui peut nous fournir un plus grand espace d'opérabilité quant au choix du vocodeur, les devoirs aident l'équipe vocale à choisir Multi ; -Band MelGAN est utilisé car Multi-Band MelGAN a de bons effets de synthèse et est très rapide.
Synthèse vocale multi-locuteurs
Après avoir déterminé le cadre de base, la prochaine chose à faire est la synthèse vocale multi-locuteurs. Une idée courante pour la synthèse vocale multi-locuteurs consiste à ajouter des informations d'intégration de haut-parleur à l'encodeur, à apprendre les informations d'un locuteur spécifique, puis à utiliser le modèle pour entraîner un modèle de synthèse vocale multi-locuteurs. Enfin, utilisez des haut-parleurs spécifiques pour effectuer un réglage fin simple. Cette solution peut compresser dix heures d'enregistrement à environ une heure, mais en pratique, il est encore difficile de collecter des enregistrements d'une heure pouvant répondre aux normes de formation du modèle. L’objectif de la synthèse vocale à petites données est essentiellement d’utiliser moins de sons pour synthétiser un son relativement bon.
Par conséquent, l'équipe vocale de Zuoyebang a tiré les leçons de la solution gagnante du concours M2VOC et a finalement choisi la combinaison de l'intégration de haut-parleurs basée sur D-Vector et ECAPA, et a effectué une triple mise à niveau, y compris la mise à niveau de l'intégration de haut-parleurs ; utilisé par FastSpeech2 dans Conformer ; et ajoute des informations sur le haut-parleur à LayerNorm.
2. Évaluation de la parole
Cadre technologique d'évaluation de la parole

Le cadre technique de base de l'évaluation de la parole de Zuoyebang utilise essentiellement la notation GOP pour juger la prononciation des mots ou des phrases par l'utilisateur. Mais en termes de modèles, il a été mis à niveau vers Conformer et CGC+attention-based, un processus complet de formation de modèles de bout en bout. GOP dépend beaucoup des sons et des phonèmes, c'est-à-dire du degré d'alignement des unités de modélisation, donc lors de la formation du modèle, nous avons ajouté les informations d'alignement du corpus obtenues via le modèle GMM. Grâce à un modèle entièrement certifié et à des informations correspondantes alignées, un modèle très efficace peut être formé. La combinaison des points forts des deux garantit que le score du GOP est relativement précis.
Problèmes et points faibles du système d'évaluation
Les scénarios d'évaluation sont naturellement sensibles à la latence, donc la latence et le réseau sont les deux problèmes majeurs dans la mise en œuvre du système d'évaluation GOP. Si la latence est élevée et les performances en temps réel médiocres, l’expérience utilisateur globale en sera grandement affectée. De plus, s'il y a un problème avec le réseau et que l'environnement réseau de l'utilisateur fluctue, couplé au retard du réseau, il est facile que le temps de coloration perçu par l'utilisateur dépasse une seconde, ce qui provoquera un sentiment de stagnation très évident, affectant sérieusement l'ensemble de l'effet de cours.
Direction de la solution - Algorithme
Pour les problèmes ci-dessus, le problème du retard et de la mémoire excessive peut être résolu de manière algorithmique via Chunk Mask. Chunk recherche jusqu'à deux images en avant et jusqu'à cinq images en arrière, et le problème de retard est résolu.
Lorsque le véritable algorithme a été testé en pratique, son délai dur n'était que d'environ 50 millisecondes, ce qui signifie que le mot sera activé en 50 millisecondes, ce qui est très rapide dans la perception humaine. Ainsi, au moins au niveau de l’algorithme, le problème du hard delay est résolu. C'est le premier niveau de travail que nous effectuons.
Orientation de la solution : Terminal intégré et plate-forme cloud
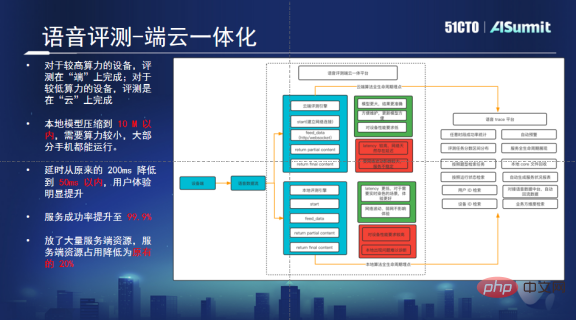
Un terminal intégré et une plate-forme cloud peuvent résoudre les problèmes causés par une concurrence élevée et une transmission réseau. Cette plateforme peut déterminer automatiquement si le téléphone mobile de l’utilisateur dispose d’une puissance de calcul suffisante. S’il y en a suffisamment, les avis locaux seront prioritaires. Si la puissance de calcul n'est pas suffisante, la requête sera envoyée au cloud et le cloud effectuera l'évaluation. En cas de problème localement, son cycle de vie est également contrôlé.
Grâce à cette solution, nous avons résolu les problèmes causés par la haute concurrence instantanée. Puisqu'une partie de la puissance de calcul est transférée vers l'extrémité, le cloud n'a besoin de conserver que 20 % des machines d'origine pour parvenir à un fonctionnement normal, ce qui permet d'économiser beaucoup. de ressource. De plus, après avoir localisé l'algorithme, le problème du retard a également été résolu, ce qui peut fournir un bon support pour les tâches d'évaluation à grande échelle et offrir aux utilisateurs une meilleure expérience audiovisuelle.
Correction des erreurs de prononciation
La demande de correction des erreurs de prononciation est due à des problèmes contextuels et à la rareté des ressources pédagogiques. De même, ce problème peut être résolu à l'aide de la technologie d'évaluation. En optimisant la technologie d'évaluation, nous pouvons déterminer si la prononciation est correcte et identifier les problèmes de prononciation.
En termes de sélection technologique, bien que le système d'évaluation soit un système d'évaluation stable basé sur le GOP, le système GOP repose fortement sur l'alignement des unités audio et de modélisation. Si l'heure de démarrage est inexacte, l'écart sera plus important et. la différenciation sera réduite. Par conséquent, le plan initial n’est pas adapté à ce type de scénario de correction sonore. De plus, l'idée du GOP est d'utiliser des connaissances d'experts pour corriger et guider la prononciation. L'absence et l'ajout de prononciation lors de la correction de la prononciation seront très pénibles à gérer pour le GOP et nécessiteront trop de support manuel. Cela nécessite une solution plus flexible, c'est pourquoi nous avons finalement choisi la solution ASR pour la correction des erreurs de prononciation.
Le grand avantage de la solution ASR est que le processus de formation est simple et ne nécessite pas trop d'informations d'alignement. Même si la prononciation est erronée, elle n’aura pas beaucoup d’impact sur la discrimination des phonèmes contextuels. L'ASR gère les lectures supplémentaires et les lectures manquées et présente des avantages théoriques et techniques naturels. Nous avons donc finalement choisi un modèle ASR pur de bout en bout comme base technique pour notre correction des erreurs de prononciation.
Parallèlement, Zuoyebang a également réalisé un travail d'optimisation et d'innovation sur cette base. Premièrement, des informations textuelles a priori sont ajoutées à la formation du modèle via le module Attention ; deuxièmement, les erreurs sont simulées par remplacement aléatoire pour entraîner le modèle afin qu'il ait des capacités de correction d'erreurs ; troisièmement, parce que le modèle n'est pas suffisamment différencié, les erreurs sont superposées ; , et certaines erreurs mineures ne seront pas jugées fausses. Grâce à la solution ci-dessus, le taux de fausses alarmes a finalement été considérablement réduit, tout en garantissant que la perte du taux de rappel n'était pas particulièrement importante, et que le taux de précision du diagnostic a également été amélioré.
3. Reconnaissance vocale
Cadre technologique de reconnaissance vocale
Le cadre technologique de reconnaissance vocale de Zuoyebang est un cadre de reconnaissance vocale de bout en bout Par rapport à la solution HMM-GMM/DNN originale, il présente des avantages très évidents : premièrement, il. évite Il existe de nombreuses opérations de regroupement et d'alignement complexes ; deuxièmement, le processus de formation est légèrement plus simple ; troisièmement, le cadre de bout en bout ne nécessite pas de génération manuelle de dictionnaires de prononciation ; quatrièmement, les informations sur les phonèmes et les informations de séquence peuvent être apprises ; en même temps, ce qui équivaut à apprendre l'acoustique ensemble Modèle, modèle de langage.
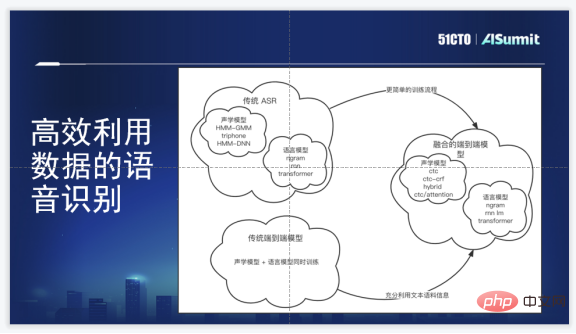
Bien sûr, ses inconvénients sont également évidents. Il est difficile pour le modèle de bout en bout d'utiliser davantage de données vocales ou textuelles au début, et le coût d'étiquetage du corpus est très élevé. Notre exigence est que la sélection interne doit atteindre l'objectif d'avoir un modèle de génération de bout en bout, suivre les derniers algorithmes et être capable de fusionner les informations du modèle de corpus.
Algorithme du système de reconnaissance vocale
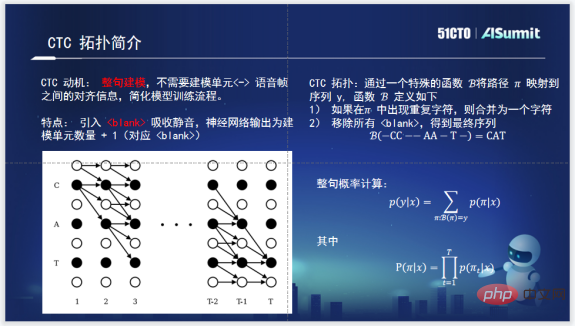
En ce qui concerne CTC-CRF, vous devez d'abord connaître CTC. CTC est né pour modéliser la phrase entière. Après l'émergence du CTC, la formation du modèle acoustique de la phrase entière ne nécessite plus d'alignement entre les phonèmes et l'audio. La topologie de CTC, d'une part, introduit un Blank pour absorber le silence, qui peut absorber le silence en dehors de la véritable unité de modélisation efficace. D'un autre côté, lorsqu'il calcule la probabilité de la phrase entière, il utilise un algorithme de programmation dynamique basé sur π pour maintenir le chemin de la phrase entière dans une échelle relativement raisonnable, ce qui peut réduire considérablement la quantité de calcul. Il s’agit d’un travail très révolutionnaire de la part de CTC.

Le système de reconnaissance vocale CTC-CRF utilisé en interne par Zuoyebang. Comprenez la formule et ajustez la probabilité de la phrase entière via CRF. La probabilité de la phrase entière est une séquence dont l'entrée est X et la sortie est π (π est représenté par la topologie de CTC ci-dessus), elle est donc appelée CTC-CRF.
La chose la plus importante à propos du CRF est la fonction potentielle et toute la planification de la fonction potentielle. La fonction potentielle est la probabilité conditionnelle que l'entrée soit X et la sortie soit πt, plus la probabilité d'une phrase entière. Elles correspondent en fait aux nœuds et aux arêtes de CRF.
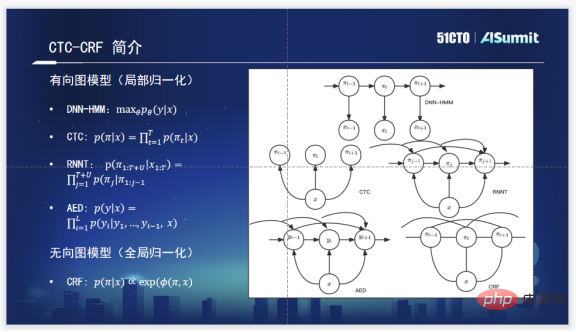
CTC-CRF est quelque peu différent des idées de modèles acoustiques couramment utilisées. Les modèles acoustiques couramment utilisés comprennent les quatre DNN-HMM, CTC, RNNT et AED suivants. Le modèle de probabilité conditionnelle de base de
RNNT est la probabilité de l'entrée X et de la sortie Y. L'objectif d'ajustement est maxθ et ses paramètres pour maximiser cette probabilité.
CTC est illustré dans la figure. Une hypothèse de CTC est évidente, à savoir l'hypothèse d'indépendance conditionnelle. Il n'y a aucun lien entre ses états et la relation de probabilité conditionnelle entre eux n'est pas prise en compte.
RNNT considère les probabilités conditionnelles de l'état actuel et de tous les états historiques, comme le montre clairement la figure. Il en va de même pour l’AED, qui prend en compte la probabilité conditionnelle de l’état actuel et de l’état historique.
Mais CTC-CRF n'est pas réellement un modèle de normalisation locale basé sur une probabilité conditionnelle. C'est un modèle de normalisation de phrases entières et un modèle de normalisation globale. Nous voyons donc que cela dépend non seulement de l'histoire, mais aussi du futur. Il peut en fait prendre en compte les informations probabilistes de la phrase entière. C'est leur plus grande différence théorique.
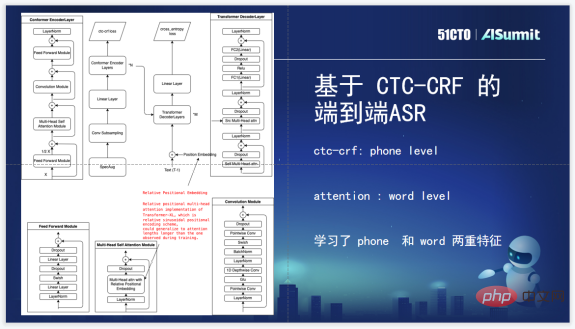
Nous utilisons d'abord CTC-CRF dans la couche Loss, qui est un encodeur et un décodeur standard actuellement utilisés, puis ajoutons CTC-CRF et Loss pour entraîner le modèle acoustique, un processus de modèle acoustique de bout en bout. La couche Perte utilise la perte CTC-CRF au lieu de la perte CTC d'origine. CTC-CRF est modélisé au niveau du téléphone, mais ici, à Attention, notre Attention est conçue en pensant à la modélisation au niveau Word. Les fonctionnalités de niveau Téléphone et Word sont utilisées pour entraîner le modèle.
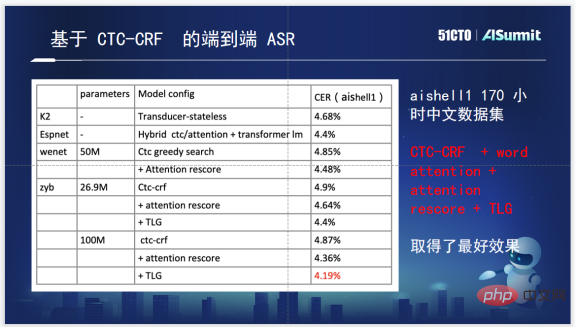
Enfin, concernant les effets spécifiques, ce sont les effets de plusieurs outils open source sur l'ensemble de test Aishell1, et le nombre de paramètres est également marqué. On constate que celui basé sur CTC-CRF présente des avantages relatifs.
Avec l'algorithme, l'effet théorique est également très bon. Lorsqu'il est combiné avec le côté commercial, le côté commercial est toujours différent, mais tous les côtés commerciaux ont un désir commun, qui est d'atteindre une efficacité optimale. Afin de résoudre ce problème, il existe une solution intéressante. La solution des mots chauds peut parfaitement résoudre ce problème et identifier rapidement les mots que le côté commercial souhaite identifier.
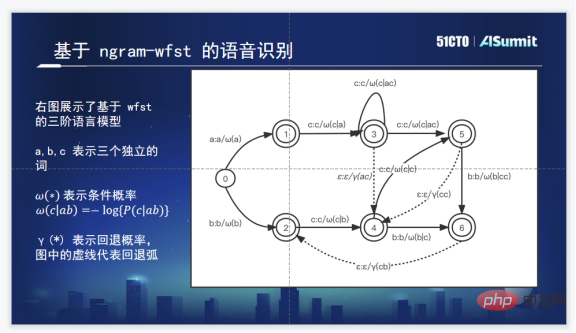
Une solution courante de mots chauds consiste à ajouter le graphique orienté étendu des mots chauds à TLG. L'image ci-dessus est le diagramme de décodage WFST d'un Ngram commun à trois niveaux. La ligne continue représente la probabilité conditionnelle et la ligne pointillée est la probabilité d'attente.
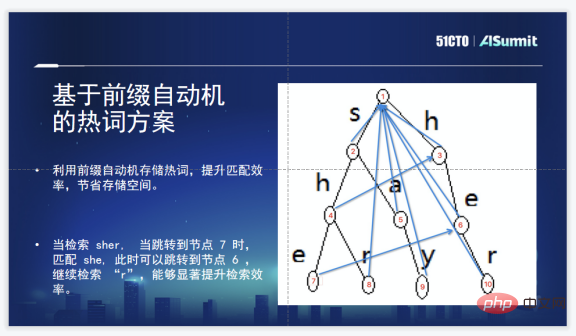
La solution de Zhuoyebang est une solution de mots chauds basée sur des automates de préfixe. En effet, l'échelle des mots chauds est si grande qu'elle créera un goulot d'étranglement en termes d'efficacité. Il est très approprié d'utiliser des automates de préfixe pour résoudre le problème de la correspondance de chaînes à motifs multiples, en particulier pour une chaîne qui frappe, couvre ou couvre un mot chaud dans la liste de mots chauds. Une séquence telle que sher couvre deux mots chauds, elle et elle. Dans ce schéma d'automate de préfixe, après avoir récupéré elle, vous pouvez accéder directement à elle et trouver rapidement plusieurs mots chauds contenus dans la chaîne. La conclusion est que cette solution est suffisamment rapide et permet d’économiser de l’espace de stockage.

Il y a aussi quelques problèmes lorsque cette solution est réellement utilisée. Construire une arborescence de préfixes nécessite toujours de parcourir l’intégralité de l’arborescence de préfixes, ce qui est relativement coûteux. Étant donné que les mots chauds doivent être ajoutés en temps réel, ils peuvent être ajoutés à tout moment et prendre effet à tout moment. Afin de résoudre ce problème, nous avons finalement créé un ou deux arbres, l'un est un arbre de préfixes ordinaire et l'autre est un automate de préfixes. C'est-à-dire que les mots chauds de l'utilisateur sont ajoutés à l'arbre de préfixes ordinaire. effet immédiat, ce qui équivaut à être en ligne à tout moment, les mots chauds peuvent être activés. Après avoir dépassé un seuil, l'automate de préfixe sera automatiquement construit, répondant ainsi essentiellement aux demandes d'un groupe d'utilisateurs.
4. Résumé
Ce qui précède passe principalement par trois directions, un à deux points dans chaque direction. Cette méthode de décryptage technique a réglé la mise en œuvre de la technologie vocale Zuoyebang et les problèmes rencontrés dans le processus de mise en œuvre, et comment finalement produire un ensemble. de solutions qui peuvent relativement répondre aux demandes du côté commercial.
Mais en plus de ces trois points, le groupe vocal a également accumulé beaucoup de capacités atomiques de la voix. Le niveau d'évaluation est très détaillé, et même la lecture accrue, la lecture manquante, la lecture continue, les voix, l'accent, les tons montants et descendants sont tous effectués. La reconnaissance ajoute également la reconnaissance mixte chinois et anglais, l'empreinte vocale, la réduction du bruit et la discrimination selon l'âge.
Avec ces capacités atomiques, le niveau algorithme sera plus pratique pour soutenir et servir le côté commercial.
Présentation de l'invité :
Wang Qiangqiang, chef de l'équipe de technologie vocale de Zuoyebang. Avant de rejoindre Zuoyebang, il a travaillé au laboratoire de traitement vocal et d'intelligence artificielle du département de génie électronique de l'université Tsinghua, où il était responsable de la mise en œuvre d'algorithmes de reconnaissance vocale et de la création de solutions de qualité industrielle. A rejoint Zuoyebang en 2018 et est responsable de la recherche et de la mise en œuvre d'algorithmes liés à la parole. Il a dirigé la mise en œuvre de la reconnaissance vocale, de l'évaluation, de la synthèse et d'autres algorithmes à Zuoyebang, fournissant à l'entreprise un ensemble complet de solutions technologiques vocales.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI