
Maison >développement back-end >Tutoriel Python >Dix astuces Python couvrent 90% des besoins en analyse de données !
Dix astuces Python couvrent 90% des besoins en analyse de données !

- 王林avant
- 2023-04-12 08:04:021095parcourir
Le travail quotidien des analystes de données implique diverses tâches, telles que le prétraitement des données, l'analyse des données, la création de modèles d'apprentissage automatique et le déploiement de modèles.
Dans cet article, je partagerai 10 opérations Python qui peuvent couvrir 90% des problèmes d'analyse de données. Gagnez des likes, des favoris et de l'attention.
1. Lecture d'ensembles de données
La lecture des données fait partie intégrante de l'analyse des données. Comprendre comment lire les données de différents formats de fichiers est la première étape pour un analyste de données. Voici un exemple d'utilisation de pandas pour lire un fichier csv contenant des données Covid-19.
import pandas as pd
# reading the countries_data file along with the location within read_csv function.
countries_df = pd.read_csv('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_data.csv')
# showing the first 5 rows of the dataframe
countries_df.head()
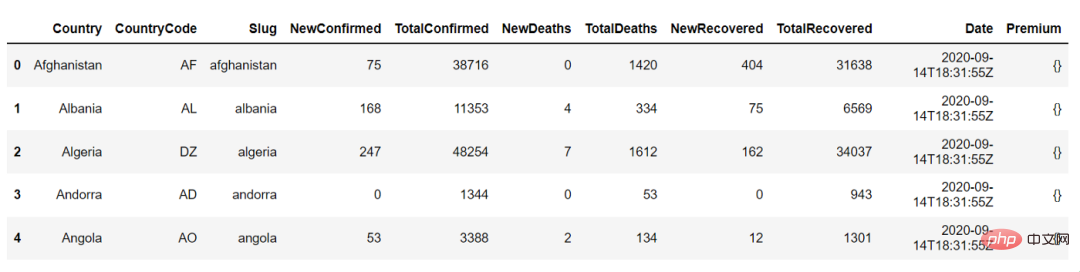
Ce qui suit est le résultat de country_df.head(), nous pouvons l'utiliser pour afficher les 5 premières lignes du bloc de données :
2. Statistiques récapitulatives
L'étape suivante consiste à comprendre les données en en affichant le résumé des données, telles que NewConfirmed, le nombre, la moyenne, l'écart type, le quantile des colonnes numériques telles que TotalConfirmed, ainsi que la fréquence et la valeur d'occurrence la plus élevée des colonnes catégorielles telles que le code du pays
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">countries_df</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">describe</span>()
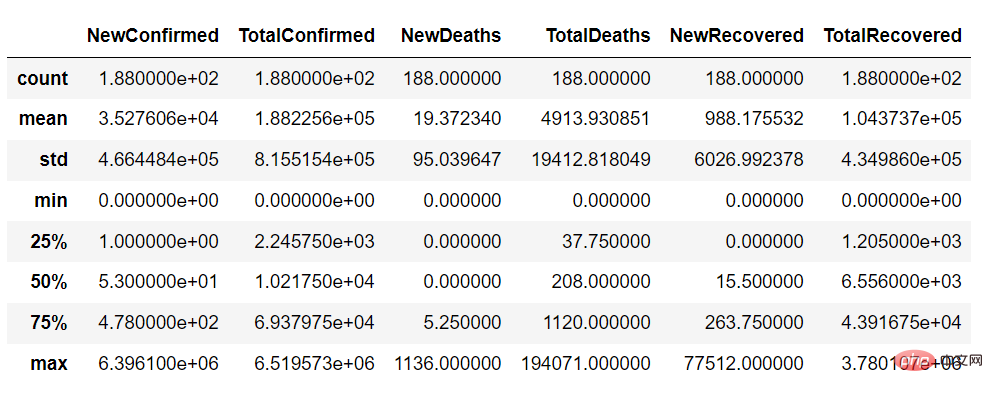
En utilisant la fonction de description, nous pouvons obtenir un résumé des variables continues de l'ensemble de données comme suit :
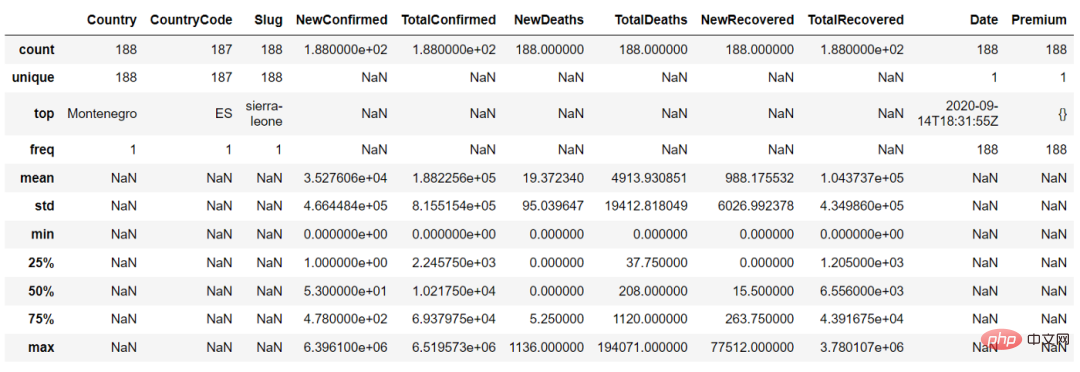
Dans la fonction décrire(), nous pouvons définir le paramètre "include = 'all'" pour obtenir le résumé des variables continues et des variables catégorielles
countries_df.describe(include = 'all')
3. Sélection et filtrage des données
L'analyse ne nécessite pas réellement un ensemble de données de toutes les lignes et colonnes, il suffit de sélectionner les colonnes qui vous intéressent et de filtrer certaines lignes en fonction de la question.
Par exemple, nous pouvons utiliser le code suivant pour sélectionner les colonnes Country et NewConfirmed :
countries_df[['Country','NewConfirmed']]
Nous pouvons également filtrer les données par Pays En utilisant loc, nous pouvons filtrer les colonnes en fonction de certaines valeurs comme suit :
countries_df.loc[countries_df['Country'] == 'United States of America'].

4. Agrégation
L'agrégation de données telles que les décomptes, les sommes et les moyennes est l'une des tâches les plus couramment effectuées dans l'analyse des données.
Nous pouvons trouver le nombre total de cas NewConfimed par pays en utilisant l'agrégation. Utilisez les fonctions groupby et agg pour effectuer l'agrégation.
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})5. Join
Utilisez l'opération Join pour combiner 2 ensembles de données en un seul ensemble de données.
Par exemple : un ensemble de données peut contenir le nombre de cas de Covid-19 dans différents pays, un autre ensemble de données peut contenir des informations de latitude et de longitude pour différents pays.
Maintenant, nous devons combiner ces deux informations, puis nous pouvons effectuer l'opération de connexion comme indiqué ci-dessous
countries_lat_lon = pd.read_excel('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_lat_lon.xlsx')
# joining the 2 dataframe : countries_df and countries_lat_lon
# syntax : pd.merge(left_df, right_df, on = 'on_column', how = 'type_of_join')
joined_df = pd.merge(countries_df, countries_lat_lon, on = 'CountryCode', how = 'inner')
joined_df6 Fonctions intégrées
Comprendre les fonctions mathématiques intégrées, telles que min(), max(), Mean(), sum() etc., sont très utiles pour effectuer différentes analyses.
Nous pouvons appliquer ces fonctions directement sur le dataframe en les appelant, ces fonctions peuvent être utilisées indépendamment sur des colonnes ou dans des fonctions d'agrégation, comme indiqué ci-dessous :
# finding sum of NewConfirmed cases of all the countries
countries_df['NewConfirmed'].sum()
# Output : 6,631,899
# finding the sum of NewConfirmed cases across different countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})
# Output
#NewConfirmed
#Country
#Afghanistan75
#Albania 168
#Algeria 247
#Andorra0
#Angola537. Fonctions définies par l'utilisateur
Fonction que nous avons écrite nous-mêmes. fonction définie par l'utilisateur. Nous pouvons exécuter le code de ces fonctions en cas de besoin en appelant la fonction. Par exemple, nous pouvons créer une fonction qui ajoute 2 nombres comme ceci :
# User defined function is created using 'def' keyword, followed by function definition - 'addition()' # and 2 arguments num1 and num2 def addition(num1, num2): return num1+num2 # calling the function using function name and providing the arguments print(addition(1,2)) #output : 3
8, Pivot
Pivot est une excellente technique de traitement de données qui convertit les valeurs uniques dans une ligne de colonne en plusieurs nouvelles colonnes.
En utilisant la fonction pivot_table() sur l'ensemble de données Covid-19, nous pouvons convertir les noms de pays en nouvelles colonnes distinctes :
# using pivot_table to convert values within the Country column into individual columns and # filling the values corresponding to these columns with numeric variable - NewConfimed pivot_df = pd.pivot_table(countries_df,columns = 'Country', values = 'NewConfirmed') pivot_df
9. Parcours du bloc de données
Souvent, nous devons parcourir les index et les lignes des données. frame, nous pouvons utiliser la fonction iterrows pour parcourir le bloc de données :
# iterating over the index and row of a dataframe using iterrows() function
for index, row in countries_df.iterrows():
print('Index is ' + str(index))
print('Country is '+ str(row['Country']))
# Output :
# Index is 0
# Country is Afghanistan
# Index is 1
# Country is Albania
# .......10. Opérations sur les chaînes
Souvent, nous traitons de colonnes de chaîne dans l'ensemble de données, dans ce cas, il est important de comprendre certaines opérations de base sur les chaînes.
Par exemple, comment convertir une chaîne en majuscules, minuscules et comment trouver la longueur d'une chaîne.
# country column to upper case countries_df['Country_upper'] = countries_df['Country'].str.upper() # country column to lower case countries_df['CountryCode_lower']=countries_df['CountryCode'].str.lower() # finding length of characters in the country column countries_df['len'] = countries_df['Country'].str.len() countries_df.head()
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!