
Maison >Périphériques technologiques >IA >Parlez de l'IA centrée sur les données derrière le modèle GPT
Parlez de l'IA centrée sur les données derrière le modèle GPT

- 王林avant
- 2023-04-11 23:55:011487parcourir
L'intelligence artificielle (IA) fait d'énormes progrès dans la façon dont nous vivons, travaillons et interagissons avec la technologie. Récemment, un domaine dans lequel des progrès significatifs ont été réalisés est le développement de grands modèles de langage (LLM) tels que GPT-3, ChatGPT et GPT-4. Ces modèles peuvent effectuer avec précision des tâches telles que la traduction linguistique, la synthèse de texte et la réponse aux questions.

Bien qu'il soit difficile d'ignorer la taille toujours croissante des modèles de LLM, il est également important de réaliser que leur succès est en grande partie dû aux grandes quantités de données de haute qualité utilisées pour les former.
Dans cet article, nous donnerons un aperçu des avancées récentes en matière de LLM du point de vue de l'IA centrée sur les données. Nous examinerons les modèles GPT à travers le prisme de l'IA centrée sur les données, un concept en pleine croissance dans la communauté de la science des données. Nous révélons les concepts d'IA centrés sur les données derrière le modèle GPT en abordant trois objectifs de l'IA centrés sur les données : le développement de données de formation, le développement de données d'inférence et la maintenance des données.
Large Language Model (LLM) et GPT Model
LLM est un modèle de traitement du langage naturel formé pour déduire des mots en contexte. Par exemple, la fonction la plus basique de LLM est de prédire les marqueurs manquants dans un contexte donné. Pour ce faire, les LLM sont formés pour prédire la probabilité de chaque mot candidat à partir d’énormes quantités de données. La figure ci-dessous est un exemple illustratif d’utilisation du LLM en contexte pour prédire la probabilité de marqueurs manquants.

Le modèle GPT fait référence à une série de LLM créés par OpenAI, tels que GPT-1, GPT-2, GPT-3, InstructGPT, ChatGPT/GPT-4, etc. Comme d'autres LLM, l'architecture du modèle GPT est principalement basée sur des Transformers, qui utilisent des intégrations de texte et d'emplacement comme entrées et utilisent des couches d'attention pour modéliser les relations des jetons.
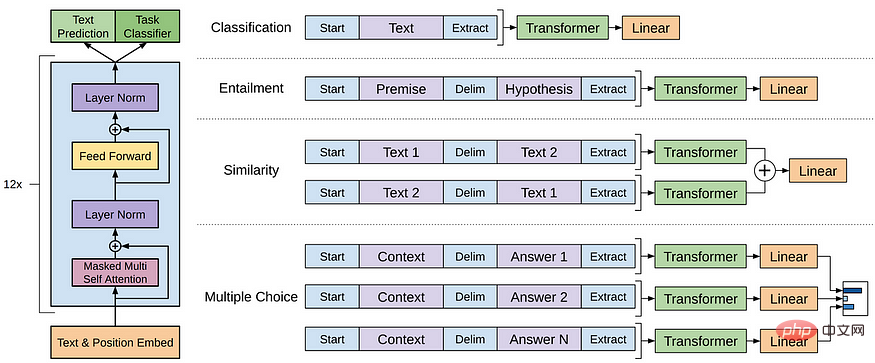
Architecture du modèle GPT-1
Les modèles GPT ultérieurs utilisent une architecture similaire à GPT-1, sauf qu'ils utilisent plus de paramètres de modèle et plus de couches, une longueur de contexte plus grande, une taille de couche cachée, etc.

Qu'est-ce que l'intelligence artificielle centrée sur les données
L'IA centrée sur les données est une nouvelle façon émergente de penser la façon de construire des systèmes d'IA. L'IA centrée sur les données est la discipline qui consiste à concevoir systématiquement les données utilisées pour créer des systèmes d'intelligence artificielle.
Dans le passé, nous nous sommes principalement concentrés sur la création de meilleurs modèles (IA centrée sur le modèle) lorsque les données sont fondamentalement inchangées. Cependant, cette approche peut poser des problèmes dans le monde réel car elle ne prend pas en compte différents problèmes pouvant survenir dans les données, tels que les inexactitudes des étiquettes, les duplications et les biais. Par conséquent, le « surajustement » d’un ensemble de données ne conduit pas nécessairement à un meilleur comportement du modèle.
En revanche, l’IA centrée sur les données se concentre sur l’amélioration de la qualité et de la quantité des données utilisées pour créer des systèmes d’IA. Cela signifie que l’attention est portée sur les données elles-mêmes et que le modèle est relativement plus fixe. L'utilisation d'une approche centrée sur les données pour développer des systèmes d'IA présente un plus grand potentiel dans des scénarios réels, car les données utilisées pour la formation déterminent en fin de compte les capacités maximales du modèle.
Il convient de noter qu'il existe une différence fondamentale entre « centré sur les données » et « piloté par les données ». Ce dernier met uniquement l'accent sur l'utilisation des données pour guider le développement de l'intelligence artificielle, et se concentre généralement encore sur le développement de modèles plutôt que de données.

Comparaison entre l'IA centrée sur les données et l'IA centrée sur le modèle
Le cadre d'IA centrée sur les données contient trois objectifs :
- Le développement de données de formation est la collecte et la production de données riches et de haute qualité pour prendre en charge la formation de modèles d'apprentissage automatique.
- Développement de données d'inférence consiste à créer de nouveaux ensembles d'évaluation qui peuvent fournir des informations plus précises sur le modèle ou déclencher des fonctionnalités spécifiques du modèle via la saisie de données.
- La maintenance des données consiste à assurer la qualité et la fiabilité des données dans un environnement dynamique. La maintenance des données est essentielle car les données du monde réel ne sont pas créées une seule fois mais nécessitent une maintenance continue.

Cadre d'IA centrée sur les données
Pourquoi l'IA centrée sur les données fait le succès du modèle GPT
Il y a quelques mois, Yann LeCun tweetait que ChatGPT n'est pas nouveau. En fait, toutes les techniques utilisées dans ChatGPT et GPT-4 (transformateurs, apprentissage par renforcement à partir du feedback humain, etc.) ne sont pas du tout nouvelles. Cependant, ils ont obtenu des résultats qui n’étaient pas possibles avec les modèles précédents. Alors, quelle est la raison de leur succès ?
Développement des données de formation. La quantité et la qualité des données utilisées pour entraîner les modèles GPT se sont considérablement améliorées grâce à de meilleures stratégies de collecte de données, d'étiquetage des données et de préparation des données.
-
GPT-1 : L'ensemble de données BooksCorpus est utilisé pour la formation. L'ensemble de données contient 4 629,00 Mo de texte brut couvrant divers genres de livres tels que l'aventure, la fantaisie et la romance.
-Stratégie d'IA centrée sur les données : Aucune.
- Résultats : L'utilisation de GPT-1 sur cet ensemble de données améliore les performances des tâches en aval grâce à un réglage fin. -
GPT-2 : Utiliser WebText en formation. Il s'agit d'un ensemble de données interne au sein d'OpenAI créé en supprimant les liens sortants de Reddit.
- Stratégie d'IA centrée sur les données : (1) Organisez/filtrez les données en utilisant uniquement les liens sortants de Reddit qui rapportent au moins 3 karma. (2) Utilisez les outils Dragnet et Newspaper pour extraire du contenu propre. (3) Utilisez la déduplication et d’autres nettoyages heuristiques.
-Résultat : Résultats en 40 Go de texte après filtrage. GPT-2 obtient des résultats robustes sans réglage fin. -
GPT-3 : La formation de GPT-3 est principalement basée sur Common Crawl.
-Stratégie d'IA centrée sur les données : (1) Former un classificateur pour filtrer les documents de mauvaise qualité en fonction de la similitude de chaque document avec WebText (documents de haute qualité). (2) Utilisez MinHashLSH de Spark pour flouter et dédupliquer des documents. (3) Augmentation des données à l'aide de WebText, du corpus de livres et de Wikipédia.
- Résultat : 45 To de texte brut filtrés pour obtenir 570 Go de texte (seulement 1,27% des données ont été sélectionnées pour ce filtrage de qualité). GPT-3 surpasse considérablement GPT-2 dans le cadre d’un échantillon nul. -
InstructGPT : Laissez l'évaluation humaine ajuster les réponses GPT-3 pour mieux répondre aux attentes humaines. Ils ont conçu un test pour les annotateurs, et seuls ceux qui ont réussi le test étaient éligibles pour l'annotation. Ils ont même conçu une enquête pour garantir que les annotateurs étaient pleinement impliqués dans le processus d'annotation.
-Stratégie d'IA centrée sur les données : (1) Ajustez le modèle grâce à un entraînement supervisé en utilisant les réponses aux invites fournies par les humains. (2) Collectez des données comparatives pour former un modèle de récompense, puis utilisez ce modèle de récompense pour régler GPT-3 grâce à l'apprentissage par renforcement avec rétroaction humaine (RLHF).
- Résultats : InstructGPT montre un meilleur réalisme et moins de biais, c'est-à-dire un meilleur alignement. - ChatGPT/GPT-4 : OpenAI n'a pas divulgué de détails. Mais comme nous le savons tous, ChatGPT/GPT-4 suit en grande partie la conception du modèle GPT précédent, et ils utilisent toujours RLHF pour affiner le modèle (éventuellement avec des données/étiquettes plus nombreuses et de meilleure qualité). Il est généralement admis que GPT-4 utilise des ensembles de données plus volumineux à mesure que les pondérations du modèle augmentent.
Développement de données d'inférence. Depuis que les modèles GPT récents sont devenus suffisamment puissants, nous pouvons atteindre divers objectifs en ajustant les indices ou en ajustant les données d'inférence pendant que le modèle est corrigé. Par exemple, nous pouvons effectuer un résumé de texte en fournissant le texte à résumer et des instructions telles que « résumer » ou « TL;DR » pour guider le processus de raisonnement.

Tune in time
Concevoir les bonnes invites de raisonnement est une tâche difficile. Cela s'appuie fortement sur l'heuristique. Une bonne enquête résume les différentes méthodes promotionnelles. Parfois, même des signaux sémantiquement similaires peuvent avoir des résultats très différents. Dans ce cas, un étalonnage basé sur des repères logiciels peut être nécessaire pour réduire la variance.

La recherche sur le développement de données d'inférence LLM en est encore à ses débuts. Dans un avenir proche, des techniques de développement de données plus inférentielles qui ont été utilisées pour d'autres tâches pourront être appliquées en LLM.
Maintenance des données. ChatGPT/GPT-4, en tant que produit commercial, est non seulement formé une seule fois, mais également mis à jour et maintenu en permanence. Évidemment, nous n’avons aucun moyen de savoir comment s’effectue la maintenance des données en dehors d’OpenAI. Par conséquent, nous discutons de certaines stratégies générales d'IA centrées sur les données qui ont été ou seront très probablement utilisées avec les modèles GPT :
- Collecte continue de données : Nos conseils lorsque nous utilisons ChatGPT/GPT-4/ Les commentaires peuvent à leur tour être utilisés par OpenAI pour faire progresser davantage leurs modèles. Des mesures de qualité et des stratégies d'assurance peuvent avoir été conçues et mises en œuvre pour collecter des données de haute qualité au cours du processus.
- Outils de compréhension des données : Divers outils peuvent être développés pour visualiser et comprendre les données des utilisateurs, favoriser une meilleure compréhension des besoins des utilisateurs et guider l'orientation des améliorations futures.
- Traitement efficace des données : Avec la croissance rapide du nombre d'utilisateurs de ChatGPT/GPT-4, un système de gestion de données efficace est nécessaire pour parvenir à une collecte rapide de données.

L'image ci-dessus est un exemple de ChatGPT/GPT-4 collectant les commentaires des utilisateurs via les « j'aime » et les « je n'aime pas ».
Ce que la communauté de la science des données peut apprendre de cette vague de succès de LLM
LLM a révolutionné l'intelligence artificielle. À l’avenir, le LLM peut révolutionner davantage le cycle de vie de la science des données. Nous faisons deux prédictions :
- L’intelligence artificielle centrée sur les données devient plus importante. Après des années de recherche, la conception de modèles est devenue très mature, surtout après Transformer. Les données deviennent un moyen clé pour améliorer les systèmes d’IA à l’avenir. De plus, lorsque le modèle devient suffisamment puissant, nous n'avons plus besoin de l'entraîner dans notre travail quotidien. Au lieu de cela, il nous suffit de concevoir des données d'inférence appropriées pour explorer les connaissances du modèle. Par conséquent, la recherche et le développement d’une IA centrée sur les données seront le moteur des progrès futurs.
- LLM permettra de meilleures solutions d'intelligence artificielle centrées sur les données
De nombreuses tâches fastidieuses de science des données peuvent être effectuées plus efficacement avec l'aide de LLM. Par exemple, ChaGPT/GPT-4 permet déjà d'écrire du code fonctionnel pour traiter et nettoyer les données. De plus, LLM peut même être utilisé pour créer des données de formation. Par exemple, l'utilisation de LLM pour générer des données synthétiques peut améliorer les performances du modèle dans l'exploration de texte.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI